Вторник, 28 июня 2022 г.
За последние дни мы получили множество вопросов, которые связаны с недавними изменениями в документации, относящейся к роботу Googlebot. В ее обновленной версии мы указали, что при извлечении файлов определенных типов робот Googlebot может видеть только первые 15 мегабайт (МБ) данных. Это ограничение не новое: оно действует уже много лет без изменений. Мы просто добавили его в документацию, поскольку эта информация может быть актуальной при отладке.
Ограничение распространяется только на байты, то есть на объем контента, который робот Googlebot получает в ответ на первоначальный запрос. Объем ресурсов, на которые ссылается страница, не учитывается.
Допустим, вы открываете страницу https://example.com/puppies.html. Сначала ваш браузер скачивает данные из HTML-файла (объем которых выражен в байтах), обрабатывает их и отправляет запросы к стороннему коду JavaScript, изображениям и другим ресурсам, на которые есть ссылки в HTML-коде исходного URL.
Googlebot работает точно так же.
Как это ограничение в 15 МБ отразится на моей работе?
Скорее всего, никак. В интернете очень мало страниц, объем которых превышает 15 МБ. Средний размер HTML-файла примерно в 500 раз меньше и составляет 30 килобайт (КБ). Поэтому маловероятно, что это ограничение для вас актуально.
Если же объем вашей страницы все-таки превышает 15 МБ, мы рекомендуем перенести некоторые встроенные скрипты и CSS-элементы во внешние файлы.
Что происходит с контентом, который не относится к первым 15 МБ?
Робот Googlebot не будет обрабатывать данные, которые не укладываются в первые 15 МБ. Для индексирования передается только объем контента в пределах этого лимита.
На какие типы контента распространяется ограничение в 15 МБ?
Ограничение в 15 МБ действует при извлечении данных роботом Googlebot (как для смартфонов, так и для компьютеров). Оно распространяется на типы файлов, которые поддерживает Google Поиск.
Означает ли это, что робот Googlebot не будет выявлять мои видео и изображения?
Нет. Робот Googlebot извлекает видео и изображения, на которые есть ссылки в HTML-коде страницы (например, <img src="https://example.com/images/puppy.jpg" alt="cute puppy looking very disappointed" />). Для этого отправляются отдельные запросы.
Учитываются ли URI данных при определении объема HTML-файла?
Да. Использование data URIs влияет на размер HTML-файла, поскольку эти идентификаторы ресурсов указаны в коде.
Как узнать объем страницы?
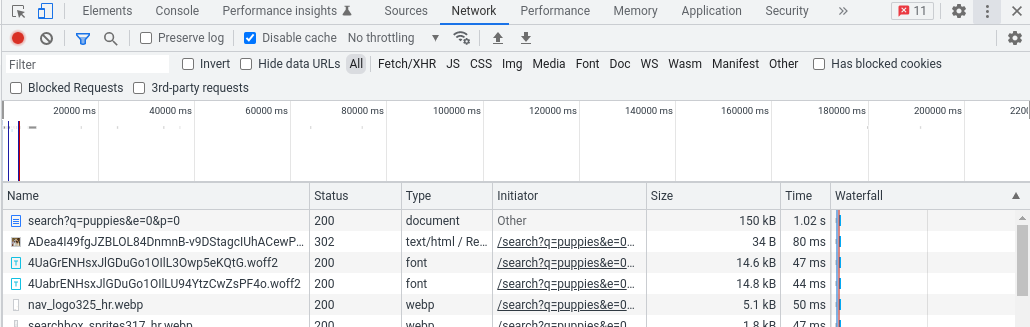
Это можно сделать разными способами, но проще всего воспользоваться инструментами разработчика в браузере. Загрузите страницу как обычно, а затем откройте инструменты разработчика и перейдите на вкладку "Сеть". Перезагрузите страницу, чтобы увидеть все запросы, которые браузер выполняет при ее обработке. Вам нужен самый верхний запрос. В столбце "Размер" вы увидите объем страницы в байтах.
Например, в Инструментах разработчика в Chrome мы видим значение 150 КБ.
Также можно воспользоваться запросом cURL в командной строке:
curl \
-A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" \
-so /dev/null https://example.com/puppies.html -w '%{size_download}'Задать нам вопросы вы можете в Твиттере и на форуме Центра Google Поиска, а также на самих страницах с документацией.