Monday, March 12, 2012
Crawl errors is one of the most popular features in Webmaster Tools, and today we're rolling out some very significant enhancements that will make it even more useful.
We now detect and report many new types of errors. To help make sense of the new data, we've split the errors into two parts: site errors and URL errors.
Site Errors
Site errors are errors that aren't specific to a particular URL—they affect your entire site. These include DNS resolution failures, connectivity issues with your web server, and problems fetching your robots.txt file. We used to report these errors by URL, but that didn't make a lot of sense because they aren't specific to individual URLs—in fact, they prevent Googlebot from even requesting a URL! Instead, we now keep track of the failure rates for each type of site-wide error. We'll also try to send you alerts when these errors become frequent enough that they warrant attention.
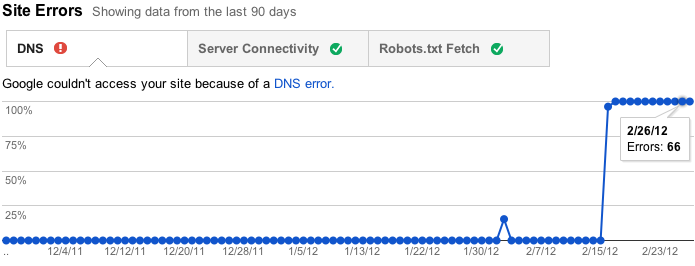
Furthermore, if you don't have (and haven't recently had) any problems in these areas, as is the case for many sites, we won't bother you with this section. Instead, we'll just show you some friendly check marks to let you know everything is hunky-dory.

URL errors
URL errors are errors that are specific to a particular page. This means that when Googlebot tried to crawl the URL, it was able to resolve your DNS, connect to your server, fetch and read your robots.txt file, and then request this URL, but something went wrong after that. We break the URL errors down into various categories based on what caused the error. If your site serves up Google News or mobile (CHTML/XHTML) data, we'll show separate categories for those errors.
Less is more
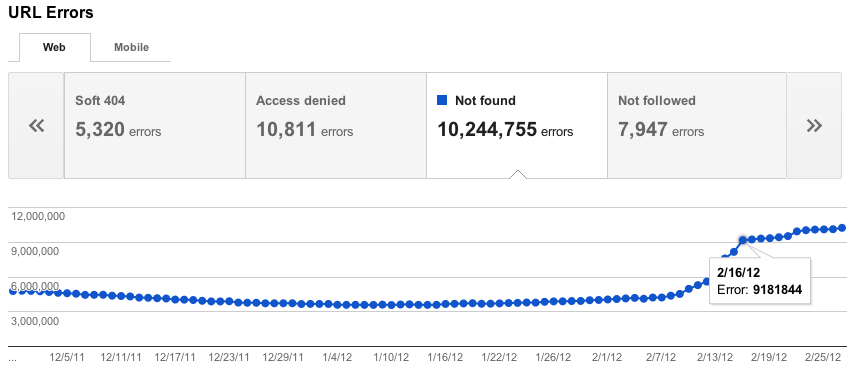
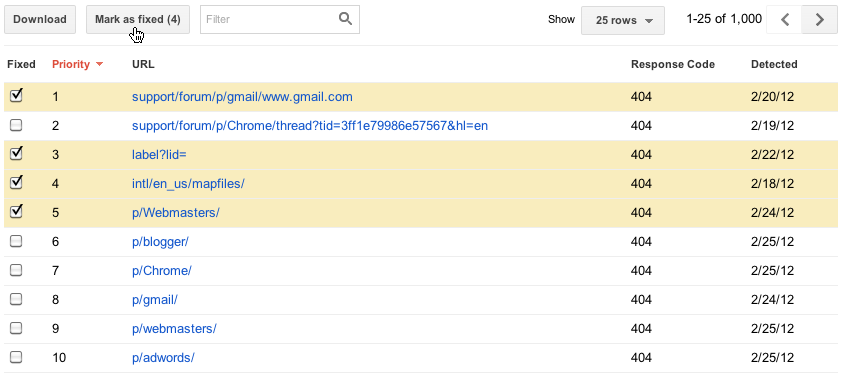
We used to show you at most 100,000 errors of each type. Trying to consume all this information was like drinking from a firehose, and you had no way of knowing which of those errors were important (your home page is down) or less important (someone's personal site made a typo in a link to your site). There was no realistic way to view all 100,000 errors—no way to sort, search, or mark your progress. In the new version of this feature, we've focused on trying to give you only the most important errors up front. For each category, we'll give you what we think are the 1000 most important and actionable errors. You can sort and filter these top 1000 errors, let us know when you think you've fixed them, and view details about them.
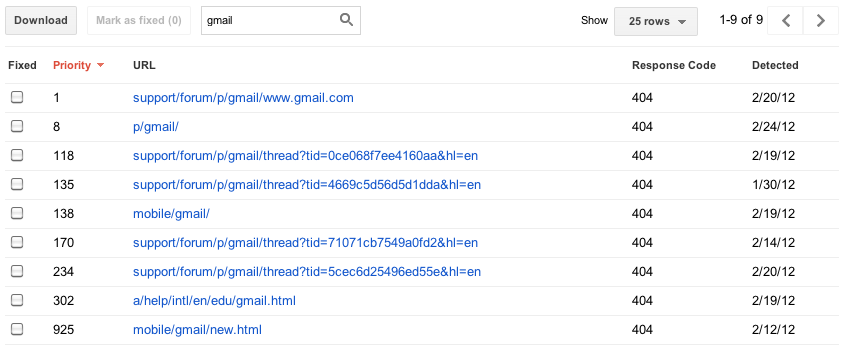
Some sites have more than 1000 errors of a given type, so you'll still be able to see the total number of errors you have of each type, as well as a graph showing historical data going back 90 days. For those who worry that 1000 error details plus a total aggregate count will not be enough, we're considering adding programmatic access (an API) to allow you to download every last error you have, so please give us feedback if you need more.
We've also removed the list of pages blocked by robots.txt, because while these can sometimes be useful for diagnosing a problem with your robots.txt file, they are frequently pages you intentionally blocked. We really wanted to focus on errors, so look for information about roboted URLs to show up soon in the "Crawler access" feature under "Site configuration".
Dive into the details
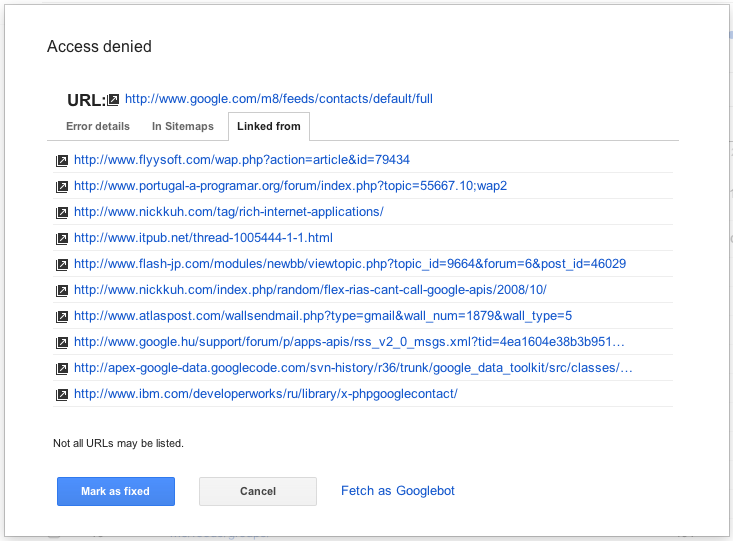
Clicking on an individual error URL from the main list brings up a detail pane with additional information, including when we last tried to crawl the URL, when we first noticed a problem, and a brief explanation of the error.
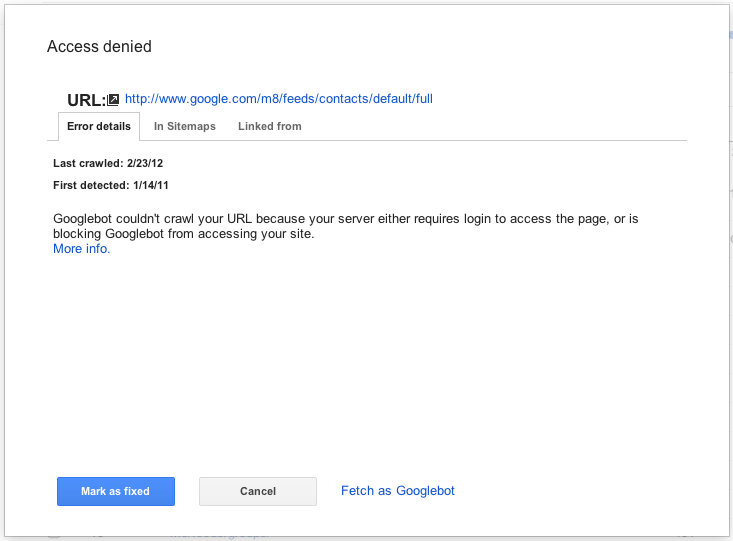
From the details pane you can click on the link for the URL that caused the error to see for yourself what happens when you try to visit it. You can also mark the error as "fixed" (more on that later!), view help content for the error type, list Sitemaps that contain the URL, see other pages that link to this URL, and even have Googlebot fetch the URL right now, either for more information or to double-check that your fix worked.
Take action!
One thing we're really excited about in this new version of the Crawl errors feature is that you
can really focus on fixing what's most important first. We've ranked the errors so that those at
the top of the priority list will be ones where there's something you can do, whether that's
fixing broken links on your own site, fixing bugs in your server software, updating your sitemaps
to prune dead URLs, or adding a 301 redirect to get users to the "real" page. We determine this
based on a multitude of factors, including whether or not you included the URL in a Sitemap, how
many places it's linked from (and if any of those are also on your site), and whether the URL has
gotten any traffic recently from search.
Once you think you've fixed the issue (you can test your fix by fetching the URL as Googlebot), you can let us know by marking the error as "fixed" if you are a user with full access permissions. This will remove the error from your list. In the future, the errors you've marked as fixed won't be included in the top errors list, unless we've encountered the same error when trying to re-crawl a URL.
We've put a lot of work into the new Crawl errors feature, so we hope that it will be very useful to you. Let us know what you think and if you have any suggestions, please visit our forum!