Wednesday, August 15, 2007
We've improved Webmaster Central's robots.txt analysis tool to recognize Sitemap declarations and
relative URLs. Earlier versions weren't aware of Sitemaps at all, and understood only absolute
URLs; anything else was reported as Syntax not understood. The improved version now
tells you whether your Sitemap's URL and scope are valid. You can also test against relative
URLs with a lot less typing.
Reporting is better, too. You'll now be told of multiple problems per line if they exist, unlike earlier versions which only reported the first problem encountered. And we've made other general improvements to analysis and validation.
Imagine that you're responsible for the domain www.example.com and you want search engines
to index everything on your site, except for your /images folder. You also want to
make sure your Sitemap gets noticed, so you save the following as your robots.txt file:
disalow images user-agent: * Disallow: sitemap: https://www.example.com/sitemap.xml
You visit Webmaster Central to test your site against the robots.txt analysis tool using these two test URLs:
https://www.example.com /archives
Earlier versions of the tool would have reported this:
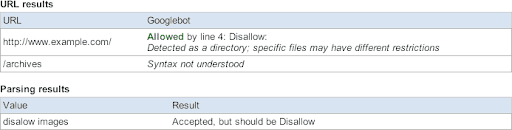
The improved version tells you more about that robots.txt file:
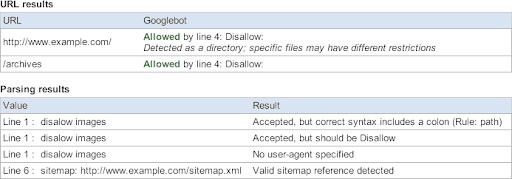
See for yourself at https://www.google.com/webmasters/tools.
We also want to make sure you've heard about the new unavailable_after meta tag
announced by Dan Crow on the
Official Google Blog
a few weeks ago. This allows for a more dynamic relationship between your site and Googlebot. Just
think, with www.example.com, any time you have a temporarily available news story or
limited offer sale or promotion page, you can specify the exact date and time you want specific
pages to stop being crawled and indexed.
Let's assume you're running a promotion that expires at the end of 2007. In the headers of page www.example.com/2007promotion.html, you would use the following:
<meta name="GOOGLEBOT" content="unavailable_after: 31-Dec-2007 23:59:59 EST" />
The second exciting news: the new X-Robots-Tag rule, which adds
Robots Exclusion Protocol
(REP) meta tag support for non-HTML pages! Finally, you can have the same control
over your videos, spreadsheets, and other indexed file types. Using the example above, let's say
your promotion page is in PDF format. For www.example.com/2007promotion.pdf, you would use
the following:
X-Robots-Tag: unavailable_after: 31 Dec 2007 23:59:59 EST
Remember, REP meta tags can be useful for implementing noarchive, nosnippet, and now
unavailable_after tags for page-level instruction, as opposed to robots.txt, which
is controlled at the domain root. We get requests from bloggers and webmasters for these features,
so enjoy. If you have other suggestions, keep them coming. Any questions? Please ask them in the
Webmaster Help Group.