Wednesday, April 25, 2012
Creativity is an important aspect of our lives and can enrich nearly everything we do. Say I'd like to make my teammate a cup of cool-looking coffee, but my creative batteries are empty; this would be (and is!) one of the many times when I look for inspiration on Google Images.
The images you see in our search results come from publishers of all sizes—bloggers, media outlets, stock photo sites—who have embedded these images in their HTML pages. Google can index image types formatted as BMP, GIF, JPEG, PNG and WebP, as well as SVG.
But how does Google know that the images are about coffee and not about tea? When our algorithms index images, they look at the textual content on the page the image was found on to learn more about the image. We also look at the page's title and its body; we might also learn more from the image's filename, anchor text that points to it, and its "alt text;" we may use computer vision to learn more about the image and may also use the caption provided in the Image Sitemap if that text also exists on the page.
To help us index your images, make sure that:
- we can crawl both the HTML page the image is embedded in, and the image itself;
- the image is in one of our supported formats: BMP, GIF, JPEG, PNG, WebP or SVG.
Additionally, we recommend:
- that the image filename is related to the image's content;
- that the alt attribute of the image describes the image in a human-friendly way;
- and finally, it also helps if the HTML page's textual contents as well as the text near the image are related to the image.
Now some answers to questions we've seen many times:
Q: Why do I sometimes see Googlebot crawling my images, rather than Googlebot-Image?
A: Generally this happens when it's not clear that a URL will lead to an image, so we crawl
the URL with Googlebot first. If we find the URL leads to an image, we'll usually revisit with
Googlebot-Image. Because of this, it's generally a good idea to allow crawling of your images and
pages by both Googlebot and Googlebot-Image.
Q: Is it true that there's a maximum file size for the images?
A: We're happy to index images of any size; there's no file size restriction.
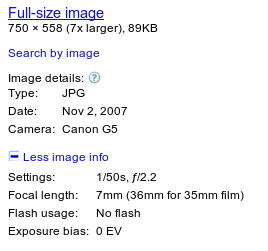
Q: What happens to the EXIF, XMP and other metadata my images contain?
A: We may use any information we find to help our users find what they're looking for more
easily. Additionally, information like EXIF data may be displayed in the right-hand sidebar of the
interstitial page that appears when you click on an image.
Q: Should I really submit an Image Sitemap? What are the benefits?
A: Yes! Image Sitemaps
help us learn about your new images and may also help us learn what the images are about.
Q: I'm using a CDN to host my images; how can I still use an Image Sitemap?
A:
Cross-domain restrictions
apply only to the Sitemaps' <loc> tag. In Image Sitemaps, the
<image:loc> tag is allowed to point to a URL on another domain, so using a CDN
for your images is fine. We also encourage you to verify the CDN's domain name in Webmaster Tools
so that we can inform you of any crawl errors that we might find.
Q: Is it a problem if my images can be found on multiple domains or subdomains I own
—for example, CDNs or related sites?
A: Generally, the best practice is to have only one copy of any type of content. If you're
duplicating your images across multiple hostnames, our algorithms may pick one copy as the
canonical copy of the image, which may not be your preferred version. This can also lead to slower
crawling and indexing of your images.
Q: We sometimes see the original source of an image ranked lower than other sources; why
is this?
A: Keep in mind that we use the textual content of a page when determining the context of
an image. For example, if the original source is a page from an image gallery that has very little
text, it can happen that a page with more textual context is chosen to be shown in search. If you
feel you've identified very bad search results for a particular query, you can use the feedback
link below the search results or to share your example in our
Webmaster Help Forum.
SafeSearch
Our algorithms use a great variety of signals to decide whether an image—or a whole page, if we're talking about Web Search—should be filtered from the results when the user's SafeSearch filter is turned on. In the case of images some of these signals are generated using computer vision, but the SafeSearch algorithms also look at simpler things such as where the image was used previously and the context in which the image was used.
One of the strongest signals, however, is self-marked adult pages. We recommend that webmasters
who publish adult content mark up their pages with one of the following meta tags:
<meta name="rating" content="adult" /> <meta name="rating" content="RTA-5042-1996-1400-1577-RTA" />
Many users prefer not to have adult content included in their search results (especially if kids
use the same computer). When a webmaster provides one of these meta tags, it helps to provide a
better user experience because users don't see results which they don't want to or expect to see.
As with all algorithms, sometimes it may happen that SafeSearch filters content inadvertently. If you think your images or pages are mistakenly being filtered by SafeSearch, please let us know in the Webmaster Help Forum.
If you need more information about how we index images, please check out the section of our Help Center dedicated to images, read our SEO Starter Guide which contains lots of useful information, and if you have more questions please post them in the Webmaster Help Forum.