Mardi 28 juin 2022
Ces derniers jours, nous avons reçu de nombreuses questions concernant une mise à jour récente de notre documentation sur Googlebot. Plus précisément, nous avons indiqué que Googlebot ne prenait en compte que les 15 premiers mégaoctets (Mo) lors de l'extraction de certains types de fichiers. Il ne s'agit pas d'une nouveauté. Ce seuil est en place depuis de nombreuses années. Nous avons simplement ajouté cette information à notre documentation, car elle peut être utile lors d'opérations de débogage, et le seuil ne change que très rarement.
Cette limite ne s'applique qu'aux octets (contenu) reçus pour la requête initiale de Googlebot, et non aux ressources référencées sur la page.
Par exemple, lorsque vous ouvrez https://example.com/puppies.html, votre navigateur télécharge initialement les octets du fichier HTML. En fonction de ces octets, il peut envoyer des requêtes supplémentaires pour des éléments externes comme du code JavaScript, des images ou tout autre élément référencé avec une URL dans le code HTML.
Googlebot fonctionne de la même manière.
Qu'est-ce que cela signifie pour vous ?
Probablement rien. Il existe très peu de pages qui dépassent cette taille sur Internet. Il est peu probable que vous soyez le propriétaire d'une telle page Web, car la taille médiane d'un fichier HTML est environ 500 fois inférieure : 30 kilo-octets (ko).
Cependant, si vous êtes le propriétaire d'une page HTML de plus de 15 Mo, nous vous serions reconnaissants de déplacer au moins certains scripts intégrés et quelques lignes de CSS accessoires vers des fichiers externes.
Qu'advient-il du contenu au-delà de 15 Mo ?
Le contenu situé après les 15 premiers Mo est ignoré par Googlebot, et seuls les 15 premiers Mo sont transmis pour l'indexation.
À quels types de contenus la limite de 15 Mo s'applique-t-elle ?
La limite de 15 Mo s'applique aux explorations effectuées par Googlebot (Googlebot pour smartphone et Googlebot pour ordinateur) lors de la récupération des types de fichiers compatibles avec la recherche Google.
Cela signifie-t-il que Googlebot ne voit pas mon image ni ma vidéo ?
Non. Googlebot récupère les vidéos et les images référencées dans le code HTML avec une URL (par exemple, <img src="https://example.com/images/puppy.jpg" alt="cute puppy looking very disappointed" />) séparément et via des extractions consécutives.
Les URI de données augmentent-ils la taille du fichier HTML ?
Oui L'utilisation des data URIs contribue à augmenter la taille du fichier HTML, car ils se trouvent dans le fichier HTML.
Comment connaître la taille d'une page ?
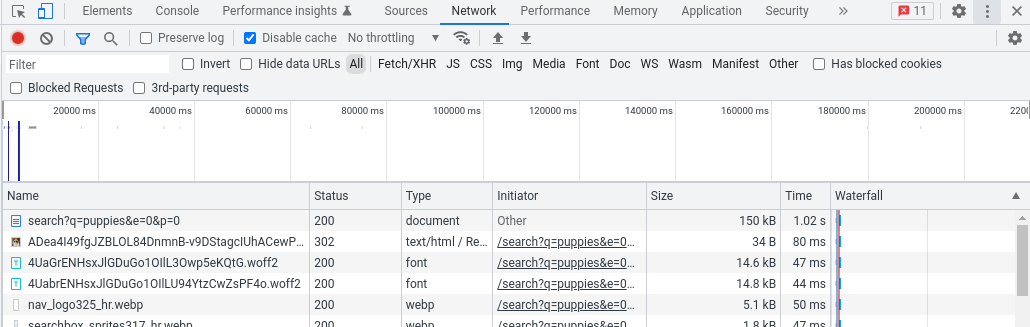
Il existe plusieurs façons d'y parvenir, mais le plus simple est sans doute d'utiliser votre propre navigateur et ses outils de développement. Chargez la page comme vous le faites d'habitude, puis lancez les outils pour les développeurs et accédez à l'onglet "Réseau". Actualisez la page. Vous devriez voir toutes les requêtes que votre navigateur a dû effectuer pour afficher la page. La requête affichée en haut correspond à la taille en octets de la page, indiquée dans la colonne "Size" (Taille).
Par exemple, avec les outils pour les développeurs Chrome cela peut ressembler à ceci, avec 150 Ko dans la colonne de taille :
Si vous êtes plus curieux, vous pouvez utiliser cURL à partir d'une ligne de commande :
curl \
-A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" \
-so /dev/null https://example.com/puppies.html -w '%{size_download}'Si vous avez d'autres questions, contactez-nous sur Twitter ou sur les forums Search Central. Pour plus de précisions sur notre documentation, laissez-nous des commentaires sur les pages concernées.