
性能优化始于确定关键指标,通常与延迟时间和吞吐量相关。增加监控来捕获和跟踪这些指标会暴露该应用中的弱点。利用指标,可以执行优化来改善性能指标。
此外,许多监控工具还允许您为指标设置提醒,以便在达到特定阈值时收到通知。例如,您可以设置提醒,以便在失败请求的百分比增加超过正常水平的 x% 时通知您。监控工具可以帮助您确定正常性能,并识别延迟时间、错误数量和其他关键指标的异常峰值。在关键业务时间范围内或在新代码推送到生产环境后,监控这些指标的能力尤为重要。
确定延迟时间指标
确保界面尽可能响应迅速,同时需要注意的是,用户期望移动应用采用更高标准。您还应为后端服务测量和跟踪延迟时间,特别是因为如果不检查延迟时间,可能会导致吞吐量问题。
建议跟踪的指标包括:
- 请求时长
- 子系统粒度的请求持续时间(例如 API 调用)
- 作业时长
确定吞吐量指标
吞吐量是指在给定时间段内处理的请求总数。吞吐量可能会受子系统的延迟时间影响,因此您可能需要针对延迟时间进行优化以提高吞吐量。
以下是建议跟踪的一些指标:
- 每秒查询次数
- 每秒传输的数据大小
- 每秒 I/O 操作数
- 资源利用率,例如 CPU 或内存用量
- 处理积压量,例如 Pub/Sub 或线程数
不仅仅是平均
衡量性能的一个常见错误是只关注平均值的情况。虽然这很有用,但并不能让您深入了解延迟的分布情况。建议您跟踪性能百分位数,例如指标的第 50/75/90/99 百分位。
一般来说,优化可以分为两步。首先,针对第 90 百分位的延迟时间进行优化然后考虑第 99 百分位,也称为尾延迟时间:一小部分请求需要更长的时间才能完成。
服务器端监控以获取详细结果
通常首选服务器端分析来跟踪指标。服务器端通常更容易插桩,可以访问更精细的数据,并且不太可能因连接问题而受到干扰。
浏览器监控以实现端到端可见性
浏览器性能分析有助于深入了解最终用户体验。它可显示哪些页面的请求速度较慢,然后将这些请求与服务器端监控相关联,以进行进一步分析。
Google Analytics(分析)在“网页计时”报告中提供对网页加载时间的开箱即用监控。这提供了多个有用的视图,有助于您了解网站上的用户体验,尤其是:
- 网页加载时间
- 重定向加载时间
- 服务器响应时间
云端监控
您可以使用许多工具来捕获和监控应用的性能指标。例如,您可以使用 Google Cloud Logging 将性能指标记录到 Google Cloud 项目中,然后在 Google Cloud Monitoring 中设置信息中心,以监控和细分所记录的指标。
如需查看从 Python 客户端库中的自定义拦截器记录到 Google Cloud Logging 的示例,请参阅 Logging 指南。利用 Google Cloud 中提供的这些数据,您可以基于所记录的数据构建指标,通过 Google Cloud Monitoring 了解您的应用。按照针对用户定义的基于日志的指标的指南,使用发送到 Google Cloud Logging 的日志构建指标。
或者,您可以使用 Monitoring 客户端库在代码中定义指标,并将其与日志分开发送到 Monitoring。
基于日志的指标示例
假设您想要监控 is_fault 值,以便更好地了解应用中的错误率。您可以将日志中的 is_fault 值提取到新的计数器指标 ErrorCount。
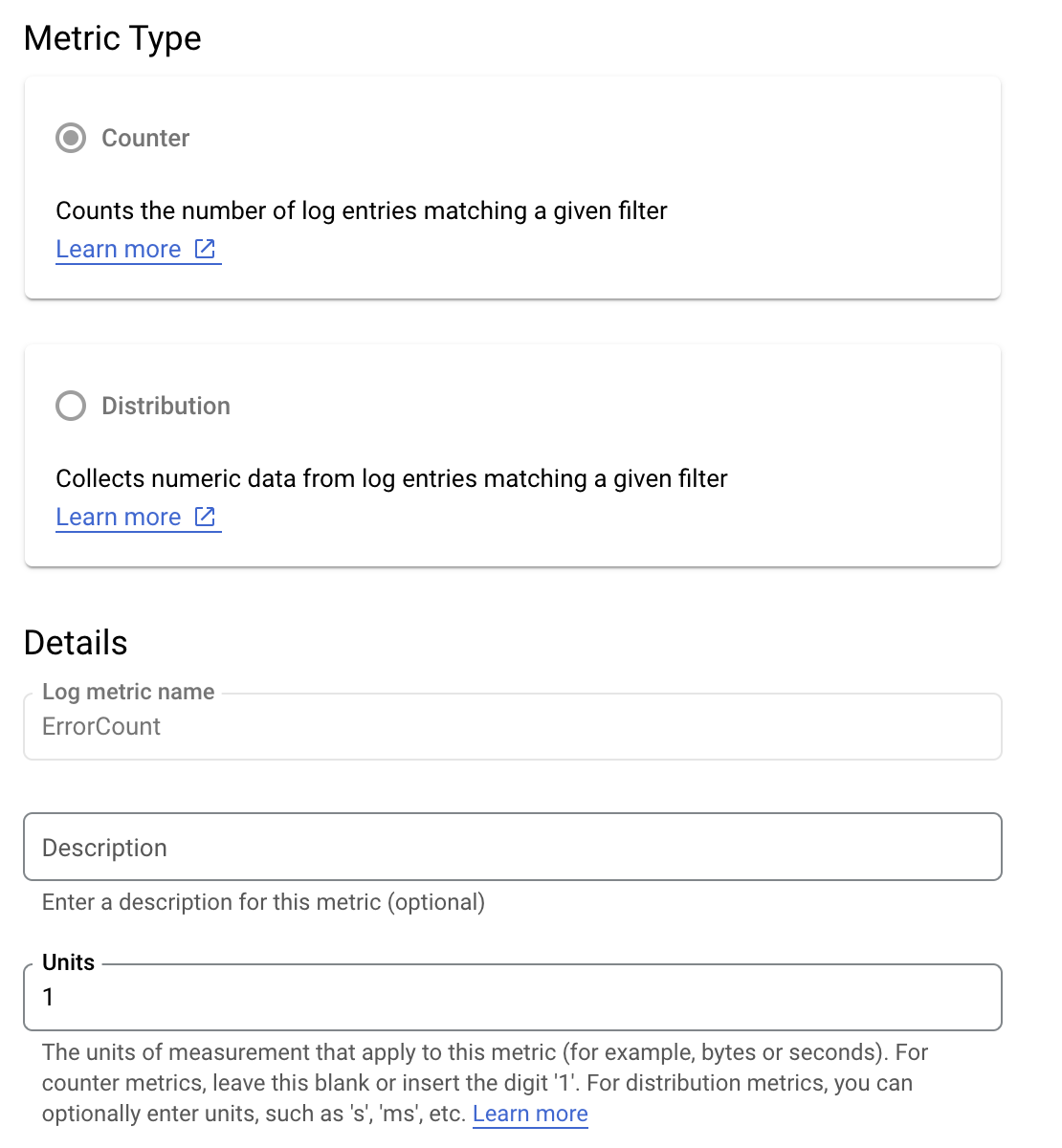

在 Cloud Logging 中,标签可让您根据日志中的其他数据将指标分组。您可以为发送到 Cloud Logging 的 method 字段配置标签,以查看按 Google Ads API 方法细分错误数的方式。
配置 ErrorCount 指标和 Method 标签后,您可以在 Monitoring 信息中心内创建新图表来监控 ErrorCount(按 Method 分组)。
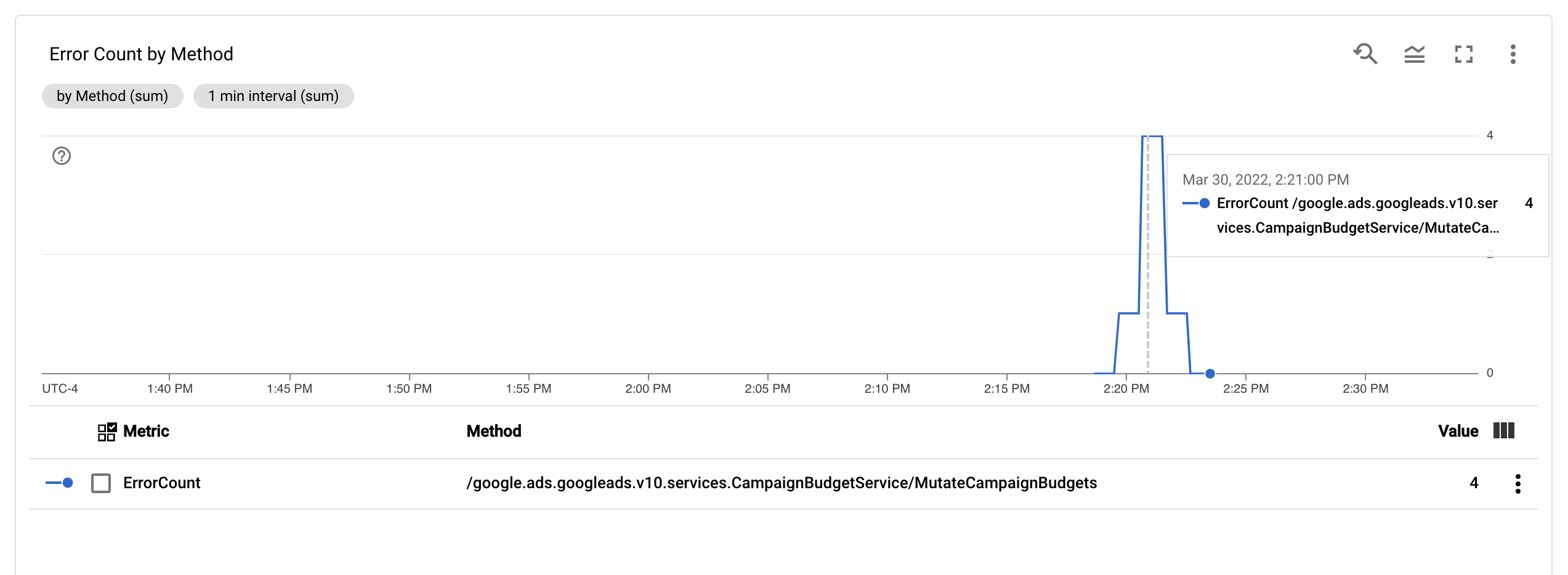
提醒
您可以在 Cloud Monitoring 和其他工具中配置提醒政策,以指定应在何时以及如何通过指标触发提醒。如需了解如何设置 Cloud Monitoring 提醒,请参阅提醒指南。