
Performans optimizasyonu, genellikle gecikme ve işleme hızıyla ilgili temel metriklerin belirlenmesiyle başlar. Bu metrikleri yakalamak ve takip etmek için izleme özelliğinin eklenmesi, uygulamadaki zayıf noktaları ortaya çıkarır. Metrikler sayesinde, performans metriklerini iyileştirmek için optimizasyon yapılabilir.
Ayrıca birçok izleme aracı, metrikleriniz için uyarılar oluşturmanıza olanak tanır. Böylece, belirli bir eşiğe ulaşıldığında bildirim alırsınız. Örneğin, başarısız istek yüzdesi normal seviyelerin% x kadarında arttığında size bildirim gönderilmesi için bir uyarı ayarlayabilirsiniz. İzleme araçları, normal performansın nasıl göründüğünü belirlemenize ve gecikme, hata miktarları ve diğer önemli metriklerdeki olağan dışı artışları tespit etmenize yardımcı olabilir. Bu metrikleri izleyebilmek özellikle iş açısından kritik zaman aralıkları sırasında veya yeni kod üretime aktarıldıktan sonra önemlidir.
Gecikme metriklerini tanımlama
Kullanıcı arayüzünüzün mümkün olduğunca duyarlı olduğundan emin olun. Kullanıcıların mobil uygulamalardan daha da yüksek standartlar beklediğini unutmayın. Özellikle işaretlenmediği takdirde işleme hızı sorunlarına yol açabileceğinden, gecikme arka uç hizmetleri için de ölçülmeli ve takip edilmelidir.
Takip edilmesi önerilen metrikler şunlardır:
- İstek süresi
- Alt sistem ayrıntı düzeyinde (API çağrıları gibi) istek süresi
- İş süresi
İşleme hızı metriklerini tanımlama
İşleme hızı, belirli bir süre boyunca sunulan toplam istek sayısının ölçümüdür. İşleme hızı, alt sistemlerin gecikmesinden etkilenebilir. Bu nedenle, işleme hızını iyileştirmek için gecikmeyi optimize etmeniz gerekebilir.
Aşağıda, izlenmesi önerilen bazı metrikler belirtilmiştir:
- Saniyedeki sorgu sayısı
- Saniyede aktarılan veri boyutu
- Saniye başına G/Ç işlemi sayısı
- CPU veya bellek kullanımı gibi kaynak kullanımı
- İşleme iş listesinin boyutu (ör. pub/sub veya iş parçacığı sayısı)
Sadece ortalama
Performans ölçümünde yaygın olarak yapılan bir hata, yalnızca ortalama (ortalama) duruma bakmadır. Bu veri, faydalı olsa da gecikmenin dağılımı hakkında bilgi vermez. Takip edilmesi gereken daha iyi bir metrik, performans yüzdelik dilimleridir (ör. bir metriğin 50./75./90./99. yüzdelik dilim).
Genel olarak, optimizasyon iki adımda yapılabilir. İlk olarak, 90. yüzdelik gecikme için optimizasyon yapın. Ardından, kuyruk gecikmesi olarak da bilinen 99. yüzdelik dilimi, yani isteklerin tamamlanması çok daha uzun süren küçük kısmı düşünün.
Ayrıntılı sonuçlar için sunucu tarafı izleme
Sunucu tarafı profil oluşturma, metrikleri izlemek için genellikle tercih edilir. Sunucu tarafının ayarlanması genellikle çok daha kolaydır, daha ayrıntılı verilere erişim sunar ve bağlantı sorunlarından kaynaklanan sapmalara daha az maruz kalır.
Uçtan uca görünürlük için tarayıcı izleme
Tarayıcı profili çıkarma, son kullanıcı deneyimi hakkında ek bilgiler sağlayabilir. Hangi sayfaların yavaş istekleri olduğunu gösterebilir. Daha sonra bunları daha ayrıntılı analiz için sunucu tarafı izlemeyle ilişkilendirebilirsiniz.
Google Analytics, sayfa zamanlamaları raporunda sayfa yükleme süreleri için kullanıma hazır izleme sağlar. Bu, sitenizdeki kullanıcı deneyimini anlamanızı sağlayacak birkaç yararlı görünüm sunar. Özellikle:
- Sayfa yüklenme süreleri
- Yükleme sürelerini yönlendir
- Sunucu yanıt süreleri
Bulutta izleme
Uygulamanızın performans metriklerini yakalamak ve izlemek için kullanabileceğiniz birçok araç vardır. Örneğin, Google Cloud Logging'i kullanarak performans metriklerini Google Cloud Projenize kaydedebilir, ardından günlüğe kaydedilen metrikleri izlemek ve segmentlere ayırmak için Google Cloud Monitoring'de kontrol panelleri oluşturabilirsiniz.
Python istemci kitaplığındaki özel bir müdahaleciden Google Cloud Logging'e giriş yapmayla ilgili bir örnek için Günlük Kaydı kılavuzuna göz atın. Bu veriler Google Cloud'da kullanıma sunulduğunda Google Cloud Monitoring aracılığıyla uygulamanızla ilgili görünürlük elde etmek için günlüğe kaydedilen verilerin üzerinde metrikler oluşturabilirsiniz. Google Cloud Logging'e gönderilen günlükleri kullanarak metrik oluşturmak için kullanıcı tanımlı günlük tabanlı metriklerle ilgili kılavuzu inceleyin.
Alternatif olarak, kodunuzda metrikler tanımlamak ve bunları günlüklerden ayrı olarak doğrudan Monitoring'e göndermek için Monitoring istemci kitaplıklarını kullanabilirsiniz.
Günlük tabanlı metrik örneği
Uygulamanızdaki hata oranlarını daha iyi anlamak için is_fault değerini izlemek istediğinizi varsayalım. is_fault değerini günlüklerdeki yeni bir sayaç metriğine (ErrorCount) çıkarabilirsiniz.
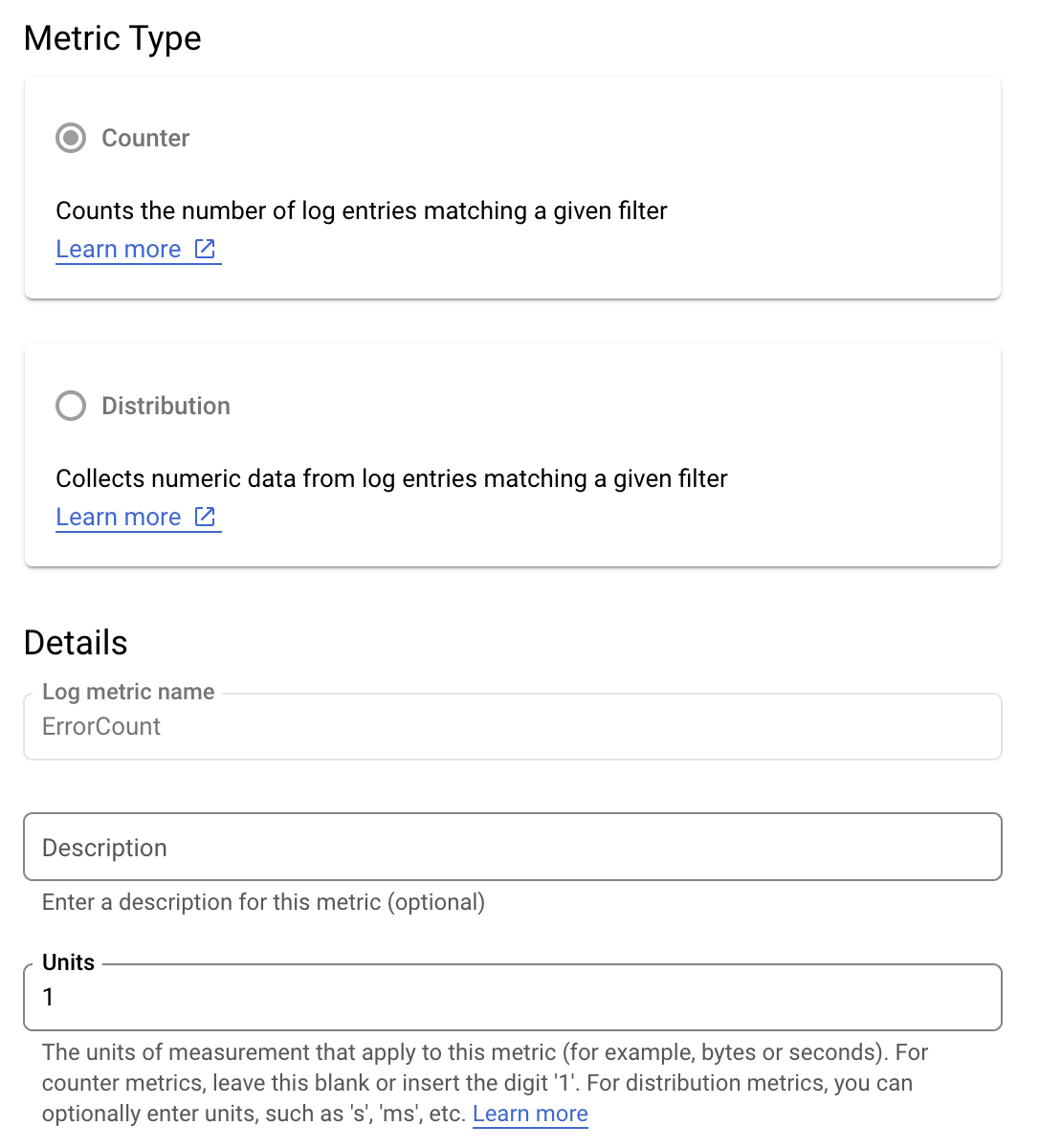

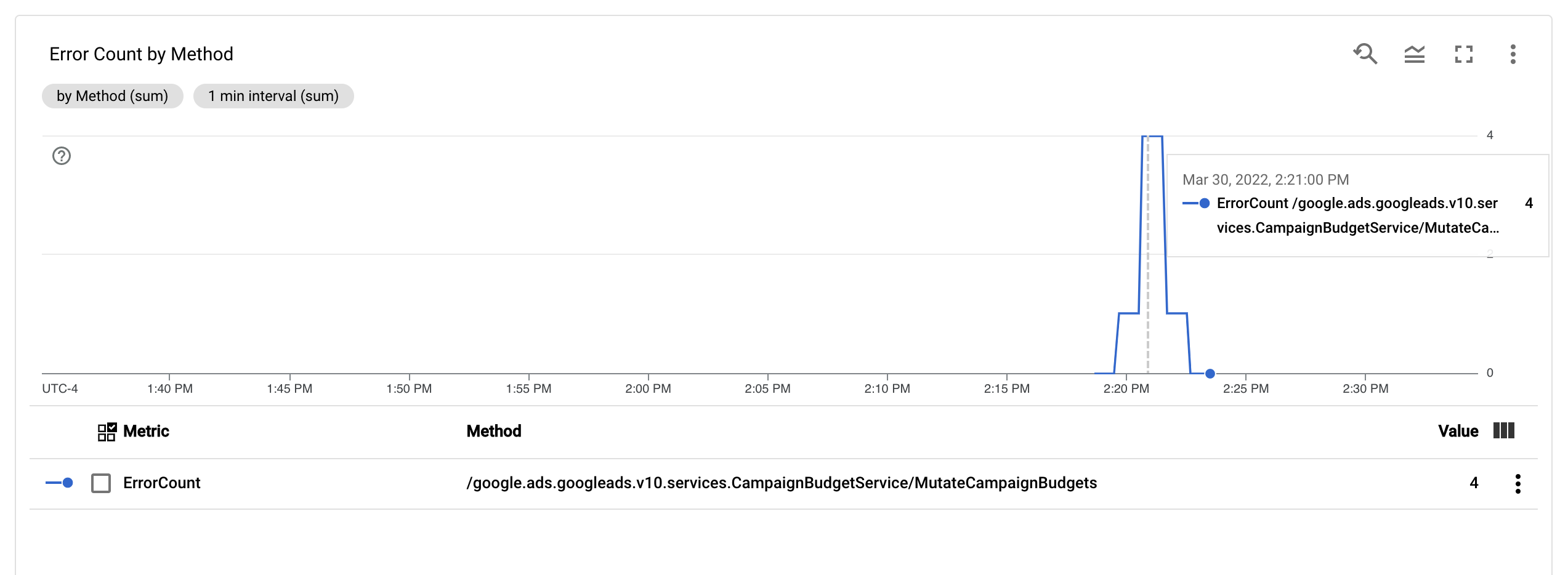
Cloud Logging'de etiketler, metriklerinizi günlüklerdeki diğer verilere göre kategorilere ayırmanızı sağlar. Hata sayısının Google Ads API yöntemine göre nasıl ayrıldığını görmek için Cloud Logging'e gönderilen method alanı için bir etiket yapılandırabilirsiniz.
ErrorCount metriği ve Method etiketi yapılandırıldığında, ErrorCount metriğini Method bazında izlemek için Monitoring kontrol panelinde yeni bir grafik oluşturabilirsiniz.
Uyarılar
Cloud Monitoring ve diğer araçlarda, metriklerin metrikleriniz tarafından ne zaman ve nasıl tetikleneceğini belirten uyarı politikalarını yapılandırmak mümkündür. Cloud Monitoring uyarılarını ayarlama talimatları için uyarılar kılavuzunu takip edin.