JavaScript एसईओ से जुड़ी बुनियादी बातें समझना
JavaScript को वेब प्लैटफ़ॉर्म का एक अहम हिस्सा माना जाता है. इसकी सुविधाओं का इस्तेमाल करके, वेब को ऐप्लिकेशन के लिए बेहद कारगर प्लैटफ़ॉर्म बनाया जा सकता है. JavaScript पर बनाए गए अपने वेब ऐप्लिकेशन को Google Search पर दिखाए जाने की अनुमति देकर, नए उपयोगकर्ताओं से जुड़ा जा सकता है. साथ ही, आपके वेब ऐप्लिकेशन पर कॉन्टेंट खोजने वाले मौजूदा उपयोगकर्ताओं को जोड़े रखना मुमकिन है. हालांकि, Google Search पर JavaScript चलाने के लिए Chromium के हमेशा उपलब्ध रहने वाले वर्शन का इस्तेमाल किया जाता है. फिर भी कुछ ऐसी चीज़ें हैं जिन्हें बेहतर बनाना आपके हाथ में है.
इस गाइड में बताया गया है कि Google Search किस तरह JavaScript को प्रोसेस करता है. इसमें Google Search के लिए JavaScript वेब ऐप्लिकेशन को बेहतर बनाने के सबसे सही तरीके भी दिए गए हैं.
Google, JavaScript को किस तरह प्रोसेस करता है
Google, JavaScript वाले वेब ऐप्लिकेशन को मुख्य तौर पर तीन चरणों में प्रोसेस करता है:
- क्रॉल करना
- रेंडर करना
- इंडेक्स करना
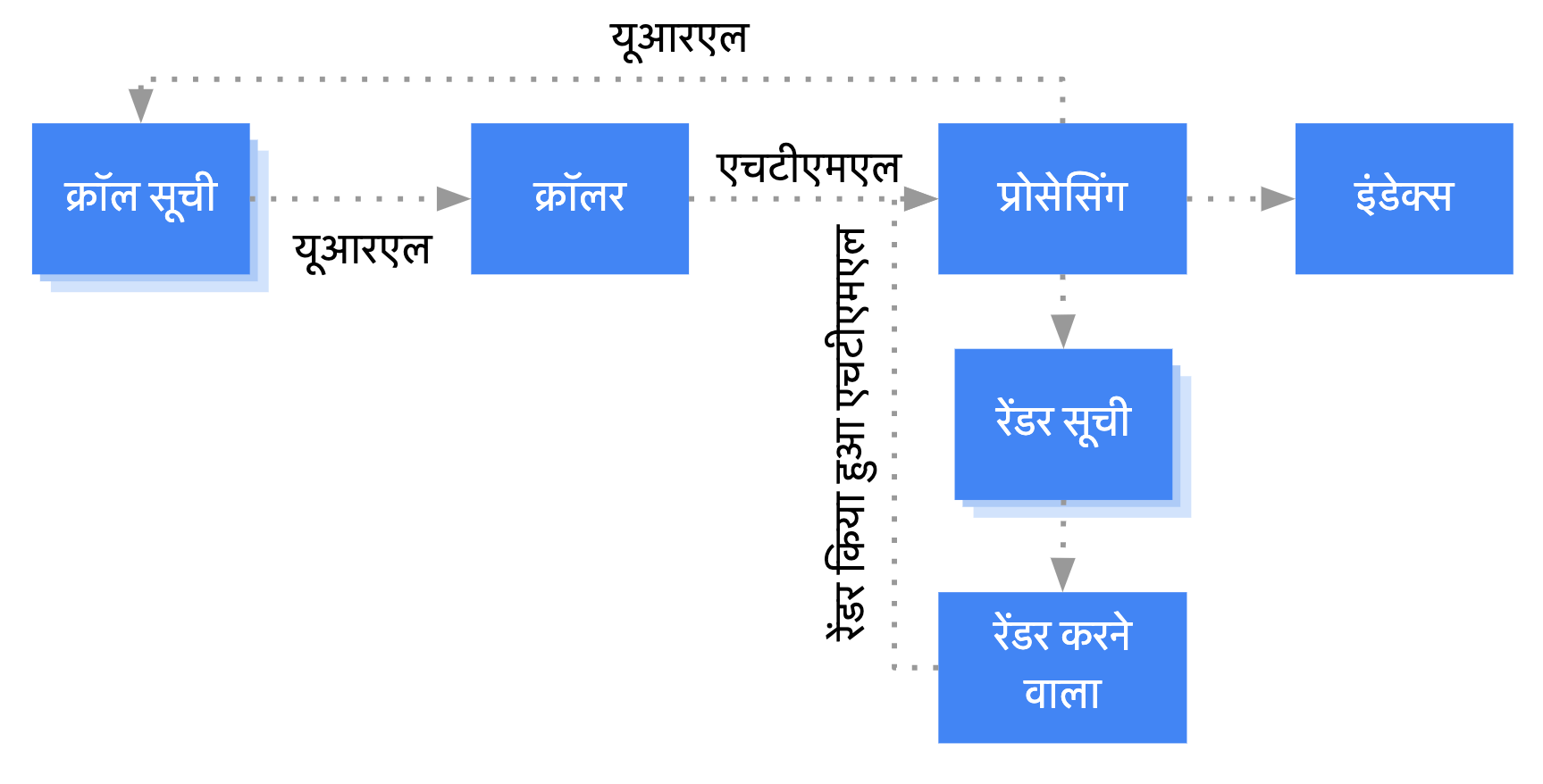
Googlebot, पेजों को क्रॉल और रेंडर करने के लिए, उन्हें सूची में डाल देता है. यह पता करना थोड़ा मुश्किल होता है कि किसी पेज के क्रॉल करने या रेंडर करने की बारी कब है.
जब एचटीटीपी अनुरोध करके Googlebot, क्रॉल वाली सूची में से कोई यूआरएल खोजता है, तो सबसे पहले यह पता लगाता है कि आपने क्रॉल करने की अनुमति दी है या नहीं. इसके बाद, Googlebot robots.txt फ़ाइल पढ़ता है. अगर इस यूआरएल को क्रॉल करने की अनुमति नहीं है, तो Googlebot इस यूआरएल के लिए एचटीटीपी अनुरोध नहीं करता है और अगले यूआरएल पर बढ़ जाता है.
इसके बाद Googlebot, एचटीएमएल लिंक के href एट्रिब्यूट में मौजूद अन्य यूआरएल के अनुरोध के जवाब को पार्स करता है. साथ ही, यूआरएल को क्रॉल वाली सूची में जोड़ देता है. Googlebot लिंक को न खोज सके, इसके लिए nofollow तरीके का इस्तेमाल करें.
पुराने तरीके से बनाई गई वेबसाइटों या सर्वर साइड से रेंडर किए गए पेजों पर, यूआरएल क्रॉल करना और एचटीएमएल के रिस्पॉन्स को पार्स करना आसान होता है. ऐसा इसलिए, क्योंकि इसमें एचटीटीपी के रिस्पॉन्स वाले एचटीएमएल में सारा कॉन्टेंट मौजूद होता है. JavaScript वाली कुछ साइटें, ऐप शेल मॉडल का इस्तेमाल कर सकती हैं. इसके शुरुआती एचटीएमएल में कोई असल कॉन्टेंट नहीं होता है. साथ ही, तैयार किया गया असल कॉन्टेंट देखने के लिए, Google को JavaScript का इस्तेमाल करना होता है.
रेंडर करने के लिए, Googlebot सभी पेजों को सूची में जोड़ देता है. हालांकि, robots meta टैग या हेडर की मदद से रोक लगे होने पर ऐसा नहीं होता. यह पेज इस सूची में कुछ सेकंड तक रह सकता है. हालांकि, यह इससे ज़्यादा समय तक भी सूची में रह सकता है. जब Google अपने रिसॉर्स के इस्तेमाल की अनुमति देता है, तो बिना ग्राफ़िक यूज़र इंटरफ़ेस वाला Chromium ब्राउज़र, पेज को रेंडर करता है और JavaScript को लागू करता है. Googlebot, पेज के लिंक पाने के लिए रेंडर किए गए एचटीएमएल को दोबारा पार्स करता है और मिलने वाले यूआरएल को क्रॉल करने के लिए, सूची में जोड़ देता है. Google, पेज को इंडेक्स करने के लिए रेंडर किए गए एचटीएमएल का इस्तेमाल करता है.
यह ध्यान रखें कि सर्वर साइड या प्री-रेंडरिंग अब भी एक बेहतरीन सुविधा है. इसकी मदद से, उपयोगकर्ता और क्रॉलर आपकी साइट पर तेज़ी से काम कर पाते हैं. यह भी ध्यान रखें कि सभी बॉट, JavaScript का इस्तेमाल नहीं कर सकते.
खास टाइटल और स्निपेट का इस्तेमाल करके, अपने पेज की जानकारी देना
जानकारी देने वाले खास <title> एलिमेंट और उपयोगी मुख्य जानकारी से
उपयोगकर्ताओं को अपने लक्ष्य के लिए सबसे बेहतर नतीजा पहचानने में मदद मिलती है. हमने अपने दिशा-निर्देशों में
अच्छे <title> एलिमेंट और
मुख्य जानकारी के बारे में बताया है.
JavaScript का इस्तेमाल, मुख्य जानकारी और <title> एलिमेंट सेट करने या उनमें बदलाव करने के लिए किया जा सकता है.
उपयोगकर्ता की सर्च क्वेरी के हिसाब से, Google Search अलग-अलग टाइटल का लिंक दिखा सकता है.
ऐसा तब होता है, जब पेज का शीर्षक और जानकारी उसके कॉन्टेंट से ज़्यादा मेल नहीं खाती है या जब हमें पेज में, सर्च क्वेरी से काफ़ी हद तक मेल खाने वाला कॉन्टेंट मिल जाता है. इस बारे में ज़्यादा जानें कि खोज के नतीजे में दिखने वाला टाइटल, पेज के <title> एलिमेंट से अलग क्यों हो सकता है.
इस्तेमाल किया जा सकने वाला कोड लिखना
ब्राउज़र कई एपीआई की सुविधा देते हैं. साथ ही, JavaScript का इस्तेमाल बहुत तेज़ी से बढ़ रहा है. Google पर एपीआई और JavaScript की चुनिंदा सुविधाएं ही इस्तेमाल की जा सकती हैं. यह पक्का करने के लिए कि Google पर आपका कोड इस्तेमाल किया जा सके, JavaScript की समस्याओं को ठीक करने से जुड़े हमारे दिशा-निर्देशों का पालन करें.
अगर आपको कोई ऐसा ब्राउज़र एपीआई चाहिए जो आपके कोड में मौजूद नहीं है, तो हमारा सुझाव है कि आप अलग-अलग सर्विंग और polyfills का इस्तेमाल करें. ब्राउज़र की कुछ सुविधाएं polyfill नहीं हो सकतीं, इसलिए हमारी सलाह है कि आप संभावित खामियों के बारे में जानने के लिए, polyfill के दस्तावेज़ देखें.
सही एचटीटीपी स्टेटस कोड का इस्तेमाल करना
पेज को क्रॉल करने के दौरान हुई गड़बड़ियों का पता लगाने के लिए Googlebot, एचटीटीपी स्टेटस कोड का इस्तेमाल करता है.
अगर किसी पेज को क्रॉल या इंडेक्स नहीं कराना है, तो Googlebot को इसकी जानकारी देने के लिए सही स्टेटस कोड का इस्तेमाल करना चाहिए. उदाहरण के लिए, जो पेज मौजूद नहीं है उसके लिए 404 का इस्तेमाल करना चाहिए या ऐसे पेजों के लिए 401 का इस्तेमाल करना चाहिए जिन पर जाने के लिए लॉगिन करने की ज़रूरत होती है. एचटीटीपी स्टेटस कोड की मदद से Googlebot को यह बताया जा सकता है कि पेज को नए यूआरएल पर ले जाया गया है, ताकि इंडेक्स को उसी हिसाब से अपडेट किया जा सके.
कुछ एचटीटीपी स्टेटस कोड और वे Google Search पर कैसे असर डालते हैं, इस बारे में आगे बताया गया है.
एक पेज वाले ऐप्लिकेशन में soft 404 गड़बड़ियों से बचना
क्लाइंट-साइड पर रेंडर किए गए एक पेज वाले ऐप्लिकेशन में, रूटिंग को अक्सर क्लाइंट-साइड रूटिंग के रूप में लागू किया जाता है.
इस मामले में, सही एचटीटीपी स्टेटस कोड का इस्तेमाल करना नामुमकिन या गलत हो सकता है.
क्लाइंट-साइड रेंडरिंग और रूटिंग का इस्तेमाल करते समय, soft 404 की गड़बड़ियों से बचने के लिए, इन तरीकों में से किसी एक तरीके का इस्तेमाल करें:
- JavaScript रीडायरेक्ट का इस्तेमाल उस यूआरएल के लिए करें जिसके लिए सर्वर जवाब के रूप में
404एचटीटीपी स्टेटस कोड (उदाहरण के लिए,/not-found) दिखाता है. - JavaScript का इस्तेमाल करके, गड़बड़ियों वाले पेज में
<meta name="robots" content="noindex">जोड़ें.
रीडायरेक्ट करने के लिए सैंपल कोड, यहां दिया गया है:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/not-found'; // redirect to 404 page on the server.
}
})
noindex टैग का इस्तेमाल करने के लिए सैंपल कोड, यहां दिया गया है:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
फ़्रैगमेंट के बजाय History API का इस्तेमाल करना
Google आपके लिंक को सिर्फ़ तब क्रॉल कर सकता है, जब वह
<a> एचटीएमएल एलिमेंट के साथ href एट्रिब्यूट हो.
अपने वेब ऐप्लिकेशन के अलग-अलग व्यू के बीच रूटिंग लागू करने के लिए, History API का इस्तेमाल करें. ऐसा क्लाइंट-साइड रूटिंग वाले एक पेज के ऐप्लिकेशन के लिए किया जाता है. अगर आपको पक्का करना के लिए कि Googlebot आपके यूआरएल को पार्स करके निकाल सके, तो आप अलग-अलग पेज का कॉन्टेंट लोड करने के लिए फ़्रैगमेंट का इस्तेमाल करने से बचें. यहां दिया गया उदाहरण गलत तरीका है. इससे Googlebot, यूआरएल को ठीक से हल नहीं कर सकता:
<nav>
<ul>
<li><a href="#/products">Our products</a></li>
<li><a href="#/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p>
</div>
<script>
window.addEventListener('hashchange', function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById('placeholder').innerHTML = load(pageToLoad);
});
</script>
इसके बजाय, History API लागू करके यह पक्का करें कि Googlebot, आपके यूआरएल को ऐक्सेस कर पाए:
<nav>
<ul>
<li><a href="/products">Our products</a></li>
<li><a href="/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute('href');
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById('placeholder').innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage));
</script>
rel="canonical" लिंक टैग को सही तरीके से इंजेक्ट करना
हम इसके लिए JavaScript का इस्तेमाल करने का सुझाव नहीं देते हैं. हालांकि, JavaScript की मदद से, rel="canonical" लिंक टैग इंजेक्ट किया जा सकता है.
पेज को रेंडर करते समय Google Search, इंजेक्ट किए गए कैननिकल यूआरएल को इंडेक्स करेगा.
JavaScript का इस्तेमाल करके, rel="canonical" लिंक टैग को इंजेक्ट करने का उदाहरण:
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
robots meta टैग का इस्तेमाल ध्यान से करें
robots meta टैग का इस्तेमाल करके, Google को पेज इंडेक्स करने या किसी लिंक पर जाने से रोका जा सकता है.
उदाहरण के लिए, अपने पेज के सबसे ऊपरी हिस्से में इस meta टैग को जोड़ने से Google, पेज को इंडेक्स नहीं कर पाएगा:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
आप चाहें, तो पेज पर robots meta टैग जोड़ने या उसके कॉन्टेंट में बदलाव करने के लिए JavaScript का इस्तेमाल करें. कोड के इस उदाहरण से यह पता चलता है कि कैसे JavaScript का इस्तेमाल करके, robots meta टैग में बदलाव किया जा सकता है. साथ ही, एपीआई कॉल का जवाब न आने पर, यह किस तरह मौजूदा पेज को इंडेक्स होने से रोकता है.
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
JavaScript के इस्तेमाल से पहले, जब Google को robots meta टैग में noindex दिखता है, तो वह उस पेज को रेंडर या इंडेक्स नहीं करता है.
लंबे समय तक कैश मेमोरी में सेव रखने का तरीका इस्तेमाल करना
नेटवर्क के अनुरोधों और रिसॉर्स के इस्तेमाल को कम करने के लिए, Googlebot
कॉन्टेंट को कैश मेमोरी में सेव करता है. ऐसा हो सकता है कि WRS, कैश मेमोरी में सेव किए जाने वाले हेडर अनदेखा कर दे. इसकी वजह से, WRS पुराने
JavaScript या सीएसएस रिसॉर्स का इस्तेमाल कर सकता है. कॉन्टेंट फ़िंगरप्रिंटिंग की सुविधा, main.2bb85551.js जैसे फ़ाइल नाम के कॉन्टेंट वाले हिस्से का
फ़िंगरप्रिंट तैयार करके, इस समस्या से बचाती है.
फ़िंगरप्रिंट, फ़ाइल के कॉन्टेंट पर निर्भर करता है. इसलिए, अपडेट में हर बार एक अलग फ़ाइल नाम
जनरेट किया जाता है. ज़्यादा जानकारी के लिए, लंबे समय तक कैश मेमोरी में सेव रखने से जुड़े हमारे निर्देशों की web.dev गाइड देखें.
स्ट्रक्चर्ड डेटा का इस्तेमाल करना
अपने पेजों पर स्ट्रक्चर्ड डेटा का इस्तेमाल करते समय, ज़रूरी JSON-LD जनरेट करने और इसे पेज में इंजेक्ट करने के लिए, JavaScript इस्तेमाल किया जा सकता है. किसी तरह की समस्या से बचने के लिए, अपनी कार्रवाई के नतीजे की जांच करना न भूलें.
वेब कॉम्पोनेंट के लिए सबसे सही तरीके अपनाना
Google, वेब कॉम्पोनेंट के साथ काम करता है. जब Google किसी पेज को रेंडर करता है, तब वह शैडो और लाइट DOM कॉन्टेंट को एक जैसा कर देता है. इसका मतलब है कि Google, सिर्फ़ ऐसे कॉन्टेंट को देख सकता है जो रेंडर किए गए एचटीएमएल में दिखता है. यह पक्का करने के लिए कि पेज रेंडर होने के बाद Google आपका कॉन्टेंट देख पाए, मोबाइल-फ़्रेंडली जांच या यूआरएल जांचने वाला टूल का इस्तेमाल करें और रेंडर किए गए एचटीएमएल को देखें.
अगर रेंडर किए गए एचटीएमएल में कॉन्टेंट नहीं दिखता है, तो Google उसे इंडेक्स नहीं कर पाएगा.
इस उदाहरण में, ऐसा वेब कॉम्पोनेंट बनाने के बारे में बताया गया है जिसमें शैडो DOM में, लाइट DOM कॉन्टेंट दिखता है. रेंडर किए गए एचटीएमएल में लाइट DOM और शैडो DOM कॉन्टेंट दोनों दिखें, यह पक्का करने के लिए स्लॉट एलिमेंट का इस्तेमाल करें.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
रेंडर करने के बाद, Google इस कॉन्टेंट को इंडेक्स कर सकता है:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
इमेज और धीमी रफ़्तार से लोड होने वाले कॉन्टेंट की समस्या ठीक करना
इमेज बैंडविथ और परफ़ार्मेंस पर काफ़ी गहरा असर डाल सकती हैं. ऐसे में, लेज़ी लोडिंग तरीके का इस्तेमाल करना अच्छी रणनीति तब मानी जाती है, जब इसके इस्तेमाल से इमेज तब ही लोड हो, जब उपयोगकर्ता उन्हें देखने वाला होगा. यह पक्का करने के लिए कि लेज़ी लोडिंग तरीके का इस्तेमाल, खोज के लिहाज़ से सही तरह से किया जा रहा है, लेज़ी लोडिंग से जुड़े हमारे दिशा-निर्देशों का पालन करें.
सुलभता के लिए डिज़ाइन
सिर्फ़ सर्च इंजन को ही नहीं, उपयोगकर्ताओं को भी ध्यान में रखकर पेज बनाएं. अपनी साइट को डिज़ाइन करते समय, अपने उपयोगकर्ताओं की ज़रूरतों के बारे में सोचें. साथ ही, ऐसे उपयोगकर्ताओं के बारे में भी सोचें जो JavaScript की सुविधा वाले ब्राउज़र का इस्तेमाल नहीं करते हों. उदाहरण के लिए, ऐसे उपयोगकर्ता जो स्क्रीन रीडर या कम सुविधा वाले मोबाइल डिवाइस का इस्तेमाल करते हों. अपनी साइट की सुलभता को जांचने का सबसे आसान तरीका यह है कि आप अपने ब्राउज़र में उसकी झलक देखें. साथ ही, ऐसा करते समय JavaScript को बंद रखें या फिर उसे सिर्फ़ टेक्स्ट वाले ब्राउज़र, जैसे कि Lynx में देखें. किसी साइट को सिर्फ़ टेक्स्ट के रूप में देखने से, आपको ऐसा कॉन्टेंट पहचानने में भी मदद मिल सकती है जिसे Google आसानी से नहीं देख सकता. जैसे, इमेज में एम्बेड किया गया टेक्स्ट.