구조화된 데이터 세트(Dataset, DataCatalog, DataDownload) 데이터
이름, 설명, 작성자, 배포 형식 등의 지원 정보를 구조화된 데이터로 제공하면 데이터 세트 검색 도구에서 데이터 세트를 더 쉽게 찾을 수 있습니다. Google의 데이터 세트 탐색 접근방식은 schema.org와 데이터 세트를 설명하는 페이지에 추가할 수 있는 기타 메타데이터 표준을 활용하는 것입니다. 이 마크업의 목적은 생명과학, 사회과학, 머신러닝, 시민 및 정부 데이터와 같은 분야의 데이터 세트 탐색을 개선하는 데 있습니다.
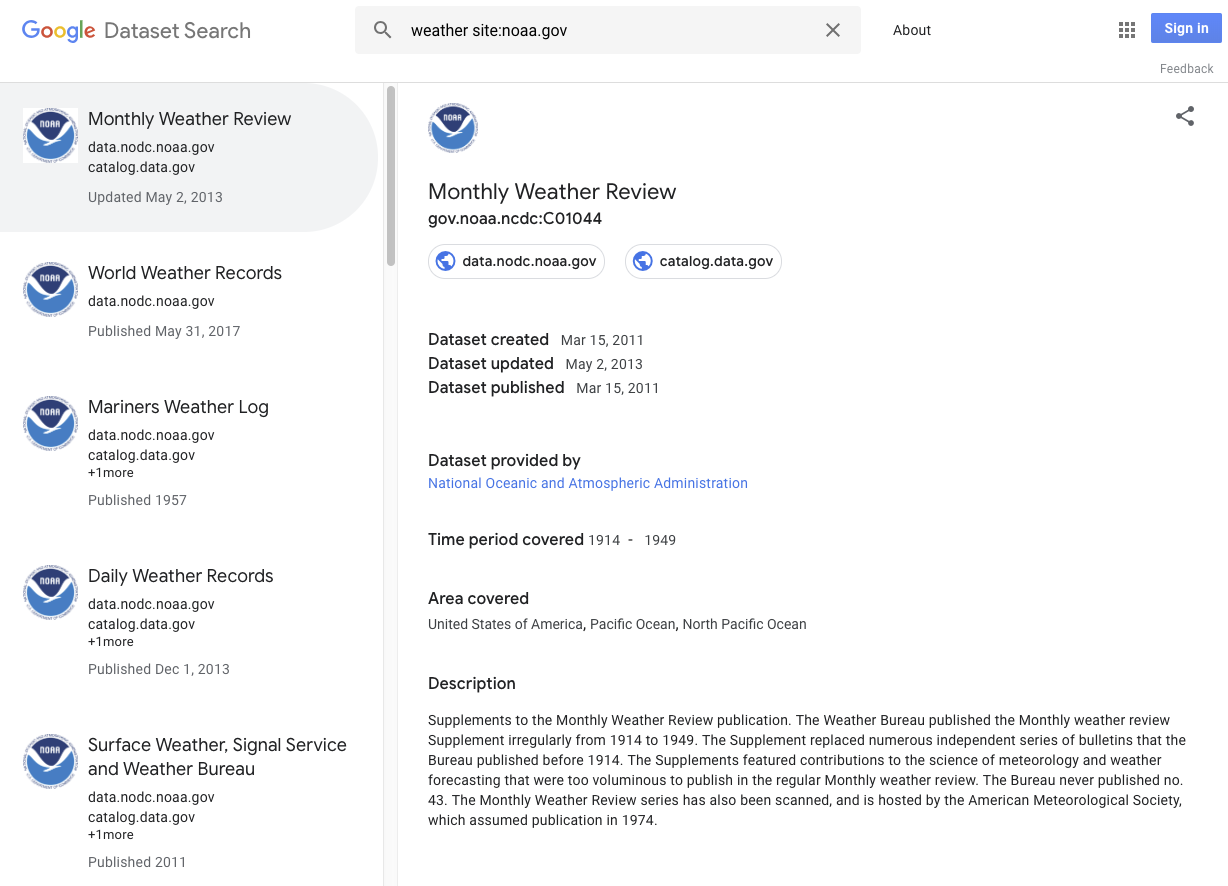
다음은 데이터 세트의 조건을 충족할 수 있는 몇 가지 예입니다.
- 일부 데이터가 포함된 표 또는 CSV 파일
- 정리된 표 모음
- 데이터가 포함된 고유한 형식의 파일
- 함께 의미 있는 데이터 세트를 구성하는 파일 모음
- 처리를 위해 특별한 도구로 로드해야 하는 다른 형식의 데이터가 포함된 구조화된 객체
- 데이터를 캡처한 이미지
- 학습된 매개변수나 신경망 구조 정의 등 머신러닝과 관련된 파일
구조화된 데이터를 추가하는 방법
구조화된 데이터는 페이지 정보를 제공하고 페이지 콘텐츠를 분류하기 위한 표준화된 형식입니다. 구조화된 데이터를 처음 사용한다면 구조화된 데이터의 작동 방식을 자세히 알아보세요.
다음은 구조화된 데이터를 빌드, 테스트 및 출시하는 방법의 개요입니다.
- 필수 속성을 추가합니다. 사용 중인 형식에 따라 페이지에 구조화된 데이터를 삽입하는 위치를 알아보세요.
- 가이드라인을 따릅니다.
- 리치 결과 테스트를 사용하여 코드의 유효성을 검사하고 심각한 오류를 해결하세요. 또한 도구에서 신고될 수 있는 심각하지 않은 문제는 구조화된 데이터의 품질을 개선하는 데 도움이 될 수 있으므로 해결하는 것이 좋습니다. 그러나 리치 결과를 사용하기 위한 필수사항은 아닙니다.
- 구조화된 데이터를 포함하는 일부 페이지를 배포하고 URL 검사 도구를 사용하여 Google에서 페이지를 표시하는 방법을 테스트합니다. Google이 페이지에 액세스할 수 있으며
robots.txt 파일,
noindex태그 또는 로그인 요구사항에 의해 차단되지 않는지 확인합니다. 페이지가 정상적으로 표시되면 Google에 URL을 재크롤링하도록 요청할 수 있습니다. - Google에 향후 변경사항을 계속 알리려면 사이트맵을 제출하는 것이 좋습니다. 이는 Search Console Sitemap API를 사용하여 자동화할 수 있습니다.
데이터 세트 검색결과에서 데이터 세트 삭제
데이터 세트 검색결과에 데이터 세트가 표시되지 않게 하려면 robots meta 태그를 사용하여 데이터 세트의 색인이 생성되는 방식을 제어합니다. 변경사항이 데이터 세트 검색에 반영되기까지는 다소 시간이 걸릴 수 있습니다(크롤링 일정에 따라 며칠 또는 몇 주).
Google의 데이터 세트 탐색 접근방식
Google에서는 schema.org Dataset 마크업 또는 W3C의 DCAT(Data Catalog Vocabulary) 형식으로 표시된 것과 동등한 구조를 사용하여 데이터 세트에 관한 웹페이지의 구조화된 데이터를 파악할 수 있습니다. 또한 W3C CSVW 기반의 구조화된 데이터를 실험적으로 지원할 방법을 검토하고 있으며, 데이터 세트 설명을 위한 권장사항이 생겨나면서 Google의 접근방식은 더 발전하고 조정될 것입니다. 데이터 세트 탐색에 관한 Google의 접근방식을 자세히 알아보려면 더 쉽게 데이터 세트 탐색을 참조하세요.
예
다음은 리치 결과 테스트에서 JSON-LD 및 schema.org 구문(권장)을 사용하는 데이터 세트의 예입니다. RDFa 1.1 또는 마이크로데이터 구문에도 동일한 schema.org 용어를 사용할 수 있습니다. W3C DCAT 용어를 사용하여 메타데이터를 설명할 수도 있습니다. 아래 예는 실제 데이터 세트 설명을 기반으로 합니다.
다음은 JSON-LD의 데이터 세트 예입니다.
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>다음은 DCAT 용어를 사용하는 RDFa 데이터 세트의 예입니다 (리치 결과 테스트에서 지원되지 않음).
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>가이드라인
사이트는 구조화된 데이터 가이드라인을 준수해야 합니다. 구조화된 데이터 가이드라인 외에도 사이트맵 권장사항과 소스 및 출처 권장사항을 따르는 것이 좋습니다.
사이트맵 권장사항
Google에서 URL을 찾을 수 있도록 사이트맵 파일을 사용하세요. 사이트맵 파일과 sameAs 마크업을 사용하면 데이터 세트 설명이 사이트 전체에 게시되는 방식을 기록하는 데 도움이 됩니다.
데이터 세트 저장소가 있는 경우 각 데이터 세트의 표준('방문') 페이지와 여러 데이트 세트(예: 검색결과 또는 데이터 세트의 일부 하위 세트)가 나열된 페이지 등 최소 두 가지 유형의 페이지가 있을 수 있습니다. 데이터 세트에 관한 구조화된 데이터는 표준 페이지에 추가하는 것이 좋습니다. 검색결과 페이지의 목록과 같이 여러 개의 데이터 세트 사본에 구조화된 데이터를 추가하는 경우 sameAs 속성을 사용하여 표준 페이지에 연결하세요.
소스 및 출처 권장사항
공개 데이터 세트가 다시 게시되고, 집계되며, 다른 데이터 세트를 기반으로 하는 것은 일반적인 것입니다. 이는 데이터 세트가 다른 데이터 세트의 사본이거나 다른 데이터 세트를 기반으로 하는 상황을 나타내는 Google의 기본 접근방식과 일치합니다.
- 다른 곳에 게시된 자료를 단순히 데이터 세트 또는 설명으로 다시 게시하는 경우
sameAs속성을 사용하여 원본에 가장 가까운 표준 URL을 지정합니다.sameAs값은 데이터 세트의 ID를 명확하게 나타내야 합니다. 즉, 서로 다른 두 데이터 세트에 같은sameAs값을 사용하지 마세요. - 다시 게시된 데이터 세트(메타데이터 포함)가 크게 변경된 경우
isBasedOn속성을 사용합니다. - 데이터 세트가 여러 원본에서 파생되거나 여러 원본을 집계하는 경우
isBasedOn속성을 사용합니다. - 적절한 디지털 객체 식별자(DOI) 또는 컴팩트 식별자를 연결하려면
identifier속성을 사용합니다. 데이터 세트에 식별자가 둘 이상 있는 경우identifier속성을 반복합니다. JSON-LD를 사용하는 경우 JSON 목록 구문을 사용하여 표현됩니다.
Google에서는 다양한 의견을 바탕으로 권장사항을 개선하고자 하며, 특히 출처의 설명과 버전 관리 및 시계열 게시와 관련된 날짜에 관한 의견을 기다리고 있습니다. 커뮤니티 토론에 참여해 주세요.
텍스트 속성 권장사항
모든 텍스트 속성은 5,000자(영문 기준) 이하로 제한하는 것이 좋습니다. Google 데이터 세트 검색에서는 텍스트 속성의 첫 5,000자만 사용합니다. 이름과 제목은 일반적으로 단어 몇 개 또는 짧은 문장으로 이루어집니다.
알려진 오류 및 경고
Google의 리치 결과 테스트 및 기타 유효성 검사 시스템에 오류 또는 경고가 표시될 수 있습니다. 특히 유효성 검사 시스템에서 조직에 contactType을 포함한 연락처 정보가 있어야 한다고 제안할 수 있습니다. 유용한 값으로는 customer service, emergency, journalist, newsroom, public engagement가 있습니다.
mainEntity 속성의 예기치 않은 값으로 발생하는 csvw:Table 오류를 무시해도 됩니다.
구조화된 데이터 유형 정의
리치 결과에 콘텐츠를 표시하려면 필수 속성이 있어야 합니다. 권장 속성을 통해 콘텐츠에 관한 정보를 추가하여 더 만족스러운 사용자 환경을 제공할 수 있습니다.
리치 결과 테스트를 사용하면 마크업을 검사할 수 있습니다.
핵심은 데이터 세트(메타데이터 포함)에 관한 정보를 설명하고 콘텐츠를 나타내는 것입니다. 예를 들어 데이터 세트 메타데이터는 무엇에 관한 데이터 세트인지, 어떤 변수를 측정하는지, 누가 작성했는지 등을 기술하며 변수에 관한 특정 값 등은 포함하지 않습니다.
Dataset
Dataset의 전체 정의는 schema.org/Dataset에서 확인하세요.
데이터 세트의 게시에 관한 추가 정보를 기술할 수 있습니다. 예를 들어 라이선스, 게시 시점, DOI, 다른 저장소에 있는 데이터 세트의 표준 버전을 가리키는 sameAs와 같은 정보를 포함하세요. 데이터 세트의 출처 및 라이선스 정보를 제공하는 identifier, license, sameAs를 추가하세요.
Google에서 지원하는 속성은 다음과 같습니다.
| 필수 속성 | |
|---|---|
description
|
Text
데이터 세트에 관한 간단한 요약 설명 가이드라인
|
name
|
Text
데이터 세트를 설명하는 이름 예: 'Snow depth in the Northern Hemisphere' 가이드라인
권장: 서로 다른 두 데이터 세트에 권장하지 않음: 서로 다른 두 데이터 세트에 |
| 권장 속성 | |
|---|---|
alternateName
|
Text
별칭이나 약어와 같이 이 데이터 세트를 나타내는 다른 이름 예를 들면 다음과 같습니다(JSON-LD 형식). "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person 또는
Organization
데이터 세트의 작성자 또는 저자입니다. 개인을 고유하게 식별하려면 "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text 또는 CreativeWork데이터 제공자가 데이터 세트에 추가하여 인용을 권장하는 학술 자료를 나타냅니다. "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" 추가 가이드라인
|
funder
|
Person 또는
Organization
이 데이터 세트와 관련된 재정적 지원을 제공하는 사람 또는 조직입니다. 개인을 고유하게 식별하려면 "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart 또는 isPartOf
|
URL 또는 Dataset데이터 세트가 작은 데이터 세트의 모음인 경우 "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text 또는 PropertyValueDOI 또는 컴팩트 식별자와 같은 식별자: 데이터 세트에 식별자가 둘 이상인 경우 |
isAccessibleForFree
|
Boolean
데이터 세트의 무료 액세스 여부입니다. |
keywords
|
Text
데이터 세트를 요약하는 키워드입니다. |
license
|
URL 또는 CreativeWork데이터 세트 배포에 적용되는 라이선스입니다. 예: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } 추가 가이드라인
|
measurementTechnique
|
Text 또는 URL
|
sameAs
|
URL
데이터 세트의 ID를 명확하게 나타내는 참조 웹페이지의 URL입니다. |
spatialCoverage |
Text 또는 Place데이터 세트의 공간적 측면을 나타내는 하나의 지점을 제공할 수 있습니다. 데이터 세트에 공간 차원이 있는 경우에만 이 속성을 포함합니다. 예를 들면 모든 측정값이 수집된 위치 또는 영역의 경계 상자 좌표를 나타내는 단일 지점입니다. 지점 "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } 도형
"spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } }
이름이 지정된 위치 "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
데이터 세트의 데이터가 특정 시간 간격을 나타냅니다. 데이터 세트에 시간 차원이 있는 경우에만 이 속성을 포함합니다. Schema.org에서는 ISO 8601 표준을 사용하여 시간 간격 및 시점을 나타냅니다. 데이터 세트 간격에 따라 날짜를 다르게 기술할 수 있습니다. 두 개의 소수점( 단일 날짜 "temporalCoverage" : "2008" 기간 "temporalCoverage" : "1950-01-01/2013-12-18" 종료 시점이 없는 기간 "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text 또는 PropertyValue데이터 세트가 측정하는 변수입니다. 예: 온도 또는 압력 |
version
|
Text 또는 Number데이터 세트의 버전 번호입니다. |
url
|
URL
데이터 세트를 설명하는 페이지의 위치입니다. |
DataCatalog
DataCatalog의 전체 정의는 schema.org/DataCatalog에서 확인하세요.
여러 개의 다른 데이터 세트가 포함된 저장소에 데이터 세트가 게시되는 경우가 종종 있습니다. 동일한 데이터 세트가 두 개 이상의 저장소에 포함될 수도 있습니다. 다음 속성을 사용해 데이터 세트를 직접 참조하여 데이터 세트가 속한 데이터 카탈로그를 참조할 수 있습니다.
| 권장 속성 | |
|---|---|
includedInDataCatalog
|
DataCatalog
데이터 세트가 속한 카탈로그
|
DataDownload
DataDownload의 전체 정의는 schema.org/DataDownload에서 확인하세요. 다운로드 옵션을 제공하는 데이터 세트에는 데이터 세트 속성 외에 다음 속성도 추가하세요.
URL이 데이터 세트를 설명하는 방문 페이지로 연결되는 경우가 많으므로 distribution 속성은 데이터 세트 자체를 가져오는 방법을 설명합니다. distribution 속성은 데이터를 가져올 위치와 형식을 설명합니다. 이 속성은 여러 값을 가질 수 있습니다. 예를 들면 CSV 버전에 하나의 URL이 있고 Excel 버전에 다른 URL을 사용할 수 있습니다.
| 필수 속성 | |
|---|---|
distribution.contentUrl
|
URL
다운로드 링크 |
| 권장 속성 | |
|---|---|
distribution
|
DataDownload
데이터 세트의 다운로드 위치 및 다운로드 파일 형식에 관한 설명입니다.
|
distribution.encodingFormat
|
Text 또는 URL배포 파일 형식입니다.
|
표 형식 데이터 세트
표 형식 데이터 세트는 주로 행과 열의 격자 모양 형태로 구성된 데이터 세트입니다. 표 형식 데이터 세트를 삽입하는 페이지의 경우 기본 방법에 따라 더욱 명확한 마크업을 만들 수도 있습니다. 현재 HTML 페이지에서 사용자 중심의 표 형식 콘텐츠와 함께 제공되는 CSVW('CSV on the Web', W3C 참조)의 변형이 인식됩니다.
다음 예는 CSVW JSON-LD 형식으로 인코딩된 작은 표를 보여줍니다. 리치 결과 테스트에 몇 가지 알려진 오류가 있습니다.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Search Console로 리치 결과 모니터링하기
Search Console은 Google 검색에서의 페이지 실적을 모니터링하는 데 도움이 되는 도구입니다. Search Console에 가입해야만 페이지가 Google 검색결과에 포함되는 것은 아니지만, 가입하면 Google에서 사이트를 인식하는 방식을 이해하고 개선하는 데 도움이 될 수 있습니다. 다음과 같은 경우 Search Console을 확인하는 것이 좋습니다.
구조화된 데이터를 처음 배포한 후
Google에서 페이지의 색인을 생성하고 나면 관련 리치 결과 상태 보고서를 사용하여 문제를 확인합니다. 유효한 항목 수가 증가하고 잘못된 항목 수는 증가하지 않는 것이 가장 좋습니다. 구조화된 데이터에 문제가 있는 경우 다음과 같이 해결하세요.
- 잘못된 항목을 수정하세요.
- 실제 URL을 검사하여 문제가 지속되는지 확인합니다.
- 상태 보고서를 사용하여 유효성 검사를 요청합니다.
새 템플릿을 출시하거나 코드를 업데이트한 후
웹사이트를 대폭 변경한 후 구조화된 데이터의 잘못된 항목이 증가하는지 모니터링하세요.- 잘못된 항목이 증가했다면 새로 출시한 템플릿이 제대로 작동하지 않거나 사이트가 기존의 템플릿과 좋지 않은 방식으로 상호작용하게 된 것일 수 있습니다.
- 유효한 항목이 감소했다면(잘못된 항목 증가와 일치하지 않음) 페이지에 구조화된 데이터를 더 이상 삽입하지 않는 것일 수 있습니다. URL 검사 도구를 사용하여 문제를 일으키는 원인을 알아보세요.
주기적으로 트래픽 분석
실적 보고서를 사용하여 Google 검색 트래픽을 분석합니다. 데이터를 통해 페이지가 Google 검색의 리치 결과로 표시되는 빈도, 사용자가 검색결과를 클릭하는 빈도, 검색결과에 표시되는 평균 게재순위를 확인할 수 있습니다. Search Console API를 사용하여 이러한 결과를 자동으로 가져오는 방법도 있습니다.문제 해결
구조화된 데이터를 구현하거나 디버깅하는 데 문제가 있다면 다음 리소스를 참고하세요.
- 콘텐츠 관리 시스템(CMS)을 사용하거나 다른 사람이 내 사이트를 관리한다면 도움을 요청하세요. 문제를 자세히 설명하는 모든 Search Console 메시지를 CMS나 관리자에게 전달해야 합니다.
- Google은 구조화된 데이터를 사용하는 기능이라고 해서 검색결과에 표시된다고 보장하지 않습니다. Google에서 콘텐츠를 리치 결과로 표시할 수 없는 일반적인 이유 목록은 구조화된 데이터 일반 가이드라인을 참고하세요.
- 구조화된 데이터에 오류가 있을 수 있습니다. 구조화된 데이터 오류 목록 및 파싱할 수 없는 구조화된 데이터 보고서를 확인하세요.
- 페이지에 구조화된 데이터 직접 조치를 취하는 경우 페이지에 있는 구조화된 데이터는 무시됩니다. 하지만 페이지는 계속 Google 검색결과에 표시될 수 있습니다. 구조화된 데이터 문제를 해결하려면 직접 조치 보고서를 사용하세요.
- 가이드라인을 다시 검토하여 콘텐츠가 가이드라인을 준수하지 않는지 확인합니다. 스팸성 콘텐츠 또는 스팸성 마크업의 사용으로 인해 문제가 발생할 수 있습니다. 하지만 해당 문제가 구문 문제가 아닐 수도 있고, 이 경우 리치 결과 테스트에서는 이 문제를 식별할 수 없습니다.
- 누락된 리치 결과/전체 리치 결과 수 감소 문제 해결
- 다시 크롤링이 이루어지고 색인이 생성될 때까지 기다리세요. 페이지가 게시된 후 Google에서 페이지를 찾고 크롤링하기까지 며칠 정도 걸릴 수 있습니다. 크롤링 및 색인 생성에 관한 일반적인 질문은 Google 검색 크롤링 및 색인 생성 FAQ를 참고하세요.
- Google 검색 센터 포럼에 질문을 올려보세요.
특정 데이터 세트가 데이터 세트 검색결과에 표시되지 않음
error 문제를 일으킨 원인: 사이트의 페이지에 데이터 세트를 설명하는 구조화된 데이터가 없거나 페이지가 아직 크롤링되지 않았습니다.
done 문제 해결
- 데이터 세트 검색결과에 표시될 것으로 예상하는 페이지의 링크를 복사하여 리치 결과 테스트에 넣습니다. '이 테스트에서 페이지가 리치 결과 기능에 적합하지 않은 것으로 확인됨' 또는 '일부 마크업이 리치 결과 기능에 적합하지 않음'이라는 메시지가 표시되면 페이지에 데이터 세트 마크업이 없거나 잘못된 것입니다. 구조화된 데이터를 추가하는 방법 섹션을 참고하여 문제를 해결하세요.
- 페이지에 마크업이 있으면 아직 크롤링되지 않았을 수 있습니다. Search Console을 사용하여 크롤링 상태를 확인하세요.
회사 로고가 결과에 없거나 올바르게 표시되지 않음
error 문제를 일으킨 원인: 페이지에 조직 로고의 schema.org 마크업이 없거나 비즈니스가 Google에 등록되지 않았습니다.
done 문제 해결
- 페이지에 구조화된 로고 데이터를 추가합니다.
- Google에서 비즈니스 세부정보를 등록합니다.