Uporządkowane dane zbioru danych (Dataset, DataCatalog, DataDownload)
Zbiory danych są łatwiejsze do znalezienia w narzędziu Wyszukiwanie zbiorów danych, jeśli informacje pomocnicze o nich, np. nazwę, opis, twórcę i formaty dystrybucyjne, podasz w formie uporządkowanych danych. Stosowana przez Google metoda rozpoznawania zbiorów danych polega na korzystaniu ze znaczników schema.org i innych metadanych, które można dodawać do stron opisujących zbiory danych. Celem stosowania tych znaczników jest ułatwienie rozpoznawania zbiorów danych z takich dziedzin jak nauki przyrodnicze, nauki społeczne, systemy uczące się, dane o obywatelach, dane rządowe itp.
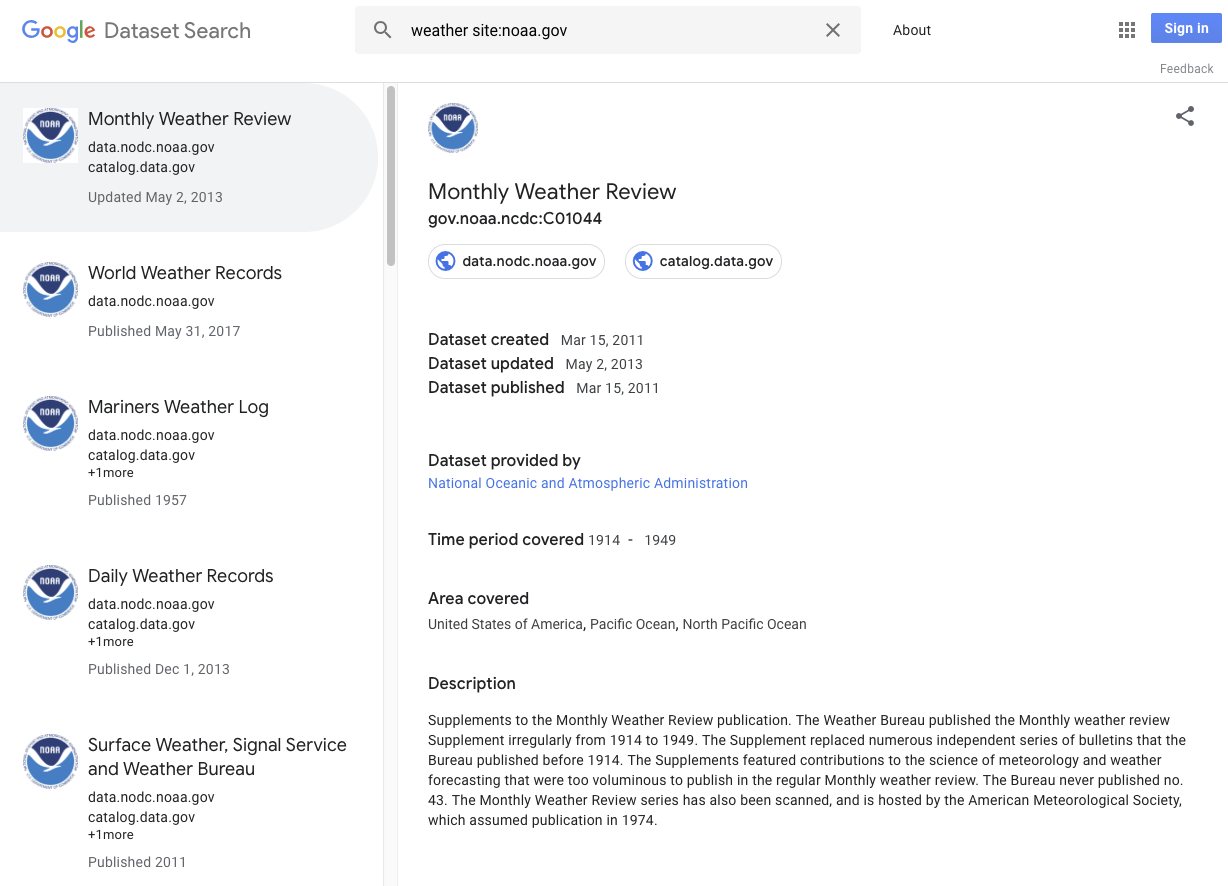
Oto kilka przykładów zbiorów danych:
- tablica lub plik CSV z jakimiś danymi;
- uporządkowany zbiór tablic;
- plik w zastrzeżonym formacie zawierający dane;
- zbiór plików, które stanowią razem sensowny zbiór danych;
- uporządkowany obiekt z danymi w jakimś innym formacie, które chcesz wczytać do specjalnego narzędzia służącego do ich przetwarzania;
- obrazy zawierające dane;
- pliki związane z systemami uczącymi się, np. wyuczone parametry lub definicje struktur sieci neuronowych.
Dodawanie uporządkowanych danych
Uporządkowane dane to standardowy format udostępniania informacji o stronie i klasyfikowania jej zawartości. Jeśli dopiero zaczynasz, dowiedz się, jak działają uporządkowane dane.
Poniżej omawiamy sposób tworzenia, testowania i udostępniania uporządkowanych danych.
- Dodaj wymagane właściwości. Dowiedz się, w którym miejscu na stronie umieścić uporządkowane dane w zależności od używanego formatu.
- Przestrzegaj wskazówek.
- Zweryfikuj kod za pomocą testu wyników z elementami rozszerzonymi i napraw błędy krytyczne. Rozważ też usunięcie niekrytycznych problemów, które mogą zostać zgłoszone w narzędziu – to może poprawić jakość uporządkowanych danych (ale nie jest to konieczne, aby witryna kwalifikowała się do wyników z elementami rozszerzonymi).
- Możesz wdrożyć kilka stron z uporządkowanymi danymi i dzięki narzędziu do sprawdzania adresów URL zobaczyć, jak Google je odczytuje. Upewnij się, że Twoja strona jest dostępna dla Google i nie jest blokowana przez plik robots.txt lub tag
noindexani nie wymaga logowania. Jeśli strona wygląda dobrze, możesz poprosić Google o ponowne zindeksowanie adresów URL. - Aby na bieżąco informować Google o przyszłych zmianach, prześlij mapę witryny. Możesz zautomatyzować ten proces za pomocą interfejsu Search Console Sitemap API.
Usuwanie zbioru danych z wyników wyszukiwania zbiorów danych
Jeśli nie chcesz, żeby zbiór danych pojawiał się w wynikach wyszukiwania zbiorów danych, określ za pomocą tagu meta robots, w jaki sposób ma on być indeksowany. Pamiętaj, że zanim zmiany pojawią się w Wyszukiwaniu zbiorów danych, może minąć trochę czasu (dni lub tygodni, w zależności od harmonogramu indeksowania).
Nasza metoda rozpoznawania zbiorów danych
Na stronach internetowych możemy rozpoznawać uporządkowane dane o zbiorach danych na podstawie znaczników Dataset schema.org lub odpowiadających im struktur występujących w formacie Data Catalog Vocabulary (DCAT) opracowanym przez organizację W3C. Badamy też eksperymentalną obsługę uporządkowanych danych opartych na formacie CSVW organizacji W3C. Planujemy rozwijanie i modyfikowanie naszej metody w miarę pojawiania się nowych, lepszych sposobów opisywania zbiorów danych. Więcej informacji o naszej metodzie rozpoznawania zbiorów danych znajdziesz w artykule Making it easier to discover datasets (Ułatwianie odkrywania zbiorów danych).
Przykłady
Oto przykład zbiorów danych zapisanych zgodnie ze składnią JSON-LD i schema.org (preferowaną) w teście wyników z elementami rozszerzonymi. Tego samego słownika schema.org można też używać w przypadku składni mikrodanych i RDFa 1.1. Do opisu metadanych można też używać słownika W3C DCAT. Poniższy przykład oparto na opisie rzeczywistego zbioru danych.
Oto przykład zbioru danych zapisanego w postaci kodu JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Oto przykład zbioru danych zapisanego w postaci kodu RDFa za pomocą słownika DCAT (nie jest obsługiwany w teście wyników z elementami rozszerzonymi):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Wytyczne
Witryny powinny być zgodne z wytycznymi dotyczącymi uporządkowanych danych. Oprócz tego zalecamy stosowanie podanych poniżej sprawdzonych metod związanych z mapą witryny oraz ze źródłem i pochodzeniem zbiorów danych.
Sprawdzone metody związane z mapą witryny
Używaj pliku mapy witryny, by pomagać Google w znajdowaniu Twoich adresów URL. Dzięki tym plikom oraz znacznikom sameAs można łatwiej udokumentować sposób publikowania w Twojej witrynie opisów zbiorów danych.
Jeśli masz repozytorium zbiorów danych, zawiera ono pewnie co najmniej 2 rodzaje stron: strony kanoniczne („docelowe”) każdego zbioru danych i strony z listą wielu zbiorów danych (np. z wynikami wyszukiwania lub z podzbiorami zbiorów danych). Zalecamy dodawanie uporządkowanych danych o zbiorach danych do stron kanonicznych. Jeśli dodasz uporządkowane dane do kilku kopii zbioru danych, np. do informacji o nim na stronach z wynikami wyszukiwania, użyj właściwości sameAs, aby wskazać stronę kanoniczną.
Sprawdzone metody związane ze źródłem i pochodzeniem zbiorów danych
Zbiory danych o otwartym dostępie często bywają ponownie publikowane i agregowane oraz oparte na innych zbiorach danych. Oto nasza wstępna propozycja sposobu uporządkowania sytuacji, w których zbiór danych jest kopią innego zbioru danych lub został utworzony na jego podstawie.
- Używaj właściwości
sameAsdo wskazywania najbardziej kanonicznych adresów URL oryginałów w przypadkach, gdy zbiór danych lub opis jest prostym powieleniem materiałów opublikowanych gdzie indziej. Wartość właściwościsameAsmusi jednoznacznie identyfikować zbiór danych. Oznacza to, że 2 różne zbiory danych nie powinny korzystać z tej samej wartościsameAs. - Używaj właściwości
isBasedOnw przypadkach, gdy ponownie opublikowany zbiór danych (łącznie z jego metadanymi) uległ istotnym zmianom. - Jeśli zbiór danych czerpie informacje z wielu oryginalnych zbiorów lub jest ich zestawieniem, używaj właściwości
isBasedOn. - Do dołączania wszelkich niezbędnych identyfikatorów cyfrowych (DOI) lub kompaktowych używaj właściwości
identifier. Jeśli zbiór danych ma kilka identyfikatorów, powtórz właściwośćidentifier. Jeśli używasz kodu JSON-LD, reprezentuje to składnia listy JSON.
Mamy nadzieję, że polepszymy nasze zalecenia dzięki otrzymanym opiniom, szczególnie w przypadku opisu pochodzenia, obsługi wersji i dat związanych z publikowaniem ciągów czasowych. Dołącz do dyskusji w ramach społeczności.
Zalecenia związane z właściwościami tekstowymi
Zalecamy ograniczenie wszystkich pól tekstowych do maksymalnie 5000 znaków. Usługa Wyszukiwanie zbiorów danych Google używa tylko pierwszych 5000 znaków z każdej właściwości tekstowej. Nazwy i tytuły mają zwykle postać kilku słów lub krótkich zdań.
Znane błędy i ostrzeżenia
W naszym narzędziu do testowania wyników z elementami rozszerzonymi i w innych systemach weryfikacyjnych mogą Ci się wyświetlać błędy lub ostrzeżenia. Systemy weryfikacyjne mogą podpowiadać, że w danych kontaktowych organizacji musi się znaleźć właściwość contactType. Do jej przydatnych wartości należą customer service, emergency, journalist, newsroom i public engagement.
Możesz też ignorować błędy sygnalizujące, że ciąg csvw:Table jest nieoczekiwaną wartością właściwości mainEntity.
Definicje typów uporządkowanych danych
Aby treści mogły się wyświetlać w wynikach z elementami rozszerzonymi, musisz w nich stosować właściwości wymagane. Możesz też dodawać do nich właściwości zalecane, aby wzbogacać informacje o treściach i zwiększać w ten sposób komfort użytkowników.
Znaczniki możesz sprawdzać za pomocą testu wyników z elementami rozszerzonymi.
Najważniejsze jest podanie informacji o zbiorze danych (czyli jego metadanych) i przedstawienie jego zawartości. Metadane zbioru danych wskazują np., czego on dotyczy, jakie zmienne podlegają w nim pomiarom, kto go utworzył itd. Metadane nie zawierają jednak np. konkretnych wartości zmiennych.
Dataset
Pełną definicję znaczników Dataset znajdziesz na schema.org/Dataset.
Możesz podać dodatkowe informacje o publikacji zbioru danych, np. licencję, termin jego opublikowania, jego identyfikator DOI lub właściwość sameAs wskazującą wersję kanoniczną zbioru danych w innym repozytorium. Właściwości identifier, license i sameAs dodawaj w przypadku zbiorów danych, które udostępniają informacje o pochodzeniu i licencji.
Właściwości obsługiwane przez Google:
| Właściwości wymagane | |
|---|---|
description
|
Text
Krótkie podsumowanie zawartości zbioru danych. Wytyczne
|
name
|
Text
Nazwa opisowa zbioru danych, np. „Grubość pokrywy śnieżnej na półkuli północnej”. Wytyczne
Zalecane: Niezalecane: |
| Właściwości zalecane | |
|---|---|
alternateName
|
Text
Nazwy alternatywne, które były używane jako odnośniki do tego zbioru danych, np. aliasy i skróty. Przykład w formacie JSON-LD: "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person lub OrganizationTwórca lub autor tego zbioru danych. Aby zidentyfikować w sposób unikalny osoby, użyj wartości ORCID ID właściwości "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text lub CreativeWorkWskazuje artykuły akademickie, które dostawca danych zaleca cytować wraz z samym zbiorem danych. Podaj cytat dla zbioru danych i dodaj informacje dotyczące innych właściwości, np. "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Dodatkowe wytyczne
|
funder
|
Person lub OrganizationOsoba lub organizacja zapewniająca wsparcie finansowe tego zbioru danych. Aby zidentyfikować w sposób unikalny osoby, użyj wartości ORCID ID właściwości "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart lub isPartOf
|
URL lub DatasetJeśli zbiór danych składa się z mniejszych zbiorów danych, oznacz tę relację za pomocą właściwości "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text lub PropertyValue
Identyfikator, np. DOI lub kompaktowy. Jeśli zbiór danych ma kilka identyfikatorów, powtórz właściwość |
isAccessibleForFree
|
Boolean
Określa, czy zbiór danych jest dostępny bez opłat. |
keywords
|
Text
Słowa kluczowe opisujące zawartość zbioru danych. |
license
|
URL lub CreativeWorkLicencja, w ramach której zbiór danych jest rozpowszechniany, np.: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Dodatkowe wytyczne
|
measurementTechnique
|
Text lub URLTechnika, technologia lub metodologia stosowana w zbiorze danych, która może odpowiadać zmiennym opisanym we właściwości |
sameAs
|
URL
Adres URL referencyjnej strony internetowej, która jednoznacznie identyfikuje zbioru danych. |
spatialCoverage |
Text lub PlaceMożesz wskazać pojedynczy punkt, który oddaje aspekt przestrzenny zbioru danych. Używaj tej właściwości tylko wtedy, gdy zbiór danych ma jakiś wymiar przestrzenny. Może chodzić np. o pojedynczy punkt, w którym przeprowadzono wszystkie pomiary, lub o współrzędne pola ograniczenia obszaru. Punkty "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Kształty Używaj mikrodanych "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Punkty we właściwościach Miejsca mające swoje nazwy "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Informacje zawarte w zbiorze danych odnoszą się do określonego przedziału czasu. Używaj tej właściwości tylko wtedy, gdy zbiór danych ma jakiś wymiar czasowy. Opisy przedziałów czasu i punktów w czasie w mikrodanych schema.org muszą być zgodne ze standardem ISO 8601. Możesz różnie podawać daty zależnie od przedziału czasu zbioru danych. Przedziały czasu o nieokreślonym końcu należy oznaczać dwiema kropkami ( Pojedyncza data "temporalCoverage" : "2008" Przedział czasu "temporalCoverage" : "1950-01-01/2013-12-18" Przedział czasu o nieokreślonym końcu "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text lub PropertyValueZmienna, której pomiary zawiera ten zbiór danych, np. temperatura lub ciśnienie. |
version
|
Text lub Number
Numer wersji zbioru danych. |
url
|
URL
Lokalizacja strony z opisem zbioru danych. |
DataCatalog
Pełną definicję znaczników DataCatalog znajdziesz na schema.org/DataCatalog.
Zbiory danych są często publikowane w repozytoriach, które zawierają też wiele innych zbiorów danych. Ten sam zbiór danych może występować w więcej niż jednym z takich repozytoriów. Do katalogu danych, do którego należy ten zbiór danych, możesz się odwoływać, odwołując się bezpośrednio do niego za pomocą tych właściwości:
| Właściwości zalecane | |
|---|---|
includedInDataCatalog
|
DataCatalog
Katalog, do którego należy zbiór danych.
|
DataDownload
Pełną definicję znaczników DataDownload znajdziesz na schema.org/DataDownload. Oprócz właściwości Dataset dodawaj poniższe właściwości do zbiorów danych, które udostępniają opcje pobierania.
Właściwość distribution podaje, jak można pozyskać zawartość zbioru danych, ponieważ adres URL wskazuje często stronę docelową zawierającą tylko jego opis. Właściwość distribution podaje, skąd i w jakim formacie można pobrać dane. Może ona mieć kilka wartości, np. wersja w formacie CSV może występować pod jednym adresem URL, a wersja w formacie programu Excel – pod innym.
| Właściwości wymagane | |
|---|---|
distribution.contentUrl
|
URL
Link do pobrania zbioru danych. |
| Właściwości zalecane | |
|---|---|
distribution
|
DataDownload
Opis miejsca, z którego można pobrać zbiór danych, i formatu pliku, w jakim jest dostępny.
|
distribution.encodingFormat
|
Text lub URL
Format pliku z wersją dystrybucyjną.
|
Tabelaryczne zbiory danych
Tabelaryczny zbiór danych ma ogólnie strukturę siatki złożonej z wierszy i kolumn. W przypadku stron, które zawierają tabelaryczne zbiory danych, możesz też utworzyć bardziej jawne znaczniki, korzystając z metody podstawowej. Aktualnie nasze systemy rozpoznają odmianę formatu CSVW („CSV on the Web”, patrz witryna organizacji W3C) stosowaną równolegle z przeznaczonymi dla użytkowników treściami w tabelach na stronie HTML.
Oto przykład niewielkiej tabeli zakodowanej w formacie JSON-LD CSVW. Test wyników z elementami rozszerzonymi zgłasza w tym przypadku znane błędy.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Monitorowanie wyników z elementami rozszerzonymi w Search Console
Search Console to narzędzie, które pomaga monitorować skuteczność stron w wyszukiwarce Google. Aby Twoja witryna mogła pojawiać się w wynikach wyszukiwania Google, nie musisz rejestrować jej w Search Console. Jeśli jednak to zrobisz, lepiej zrozumiesz, jak robot Google widzi Twoją witrynę i jak możesz mu ułatwić jej skanowanie. Zalecamy sprawdzenie danych w Search Console w tych przypadkach:
- po pierwszym wdrożeniu uporządkowanych danych,
- po opublikowaniu nowych szablonów lub zaktualizowaniu kodu,
- podczas okresowego analizowania ruchu.
Po pierwszym wdrożeniu uporządkowanych danych
Gdy Google zindeksuje Twoje strony, poszukaj problemów w odpowiednim raporcie o stanie wyników z elementami rozszerzonymi. W idealnej sytuacji powinno się pojawić więcej elementów prawidłowych, a liczba elementów nieprawidłowych nie powinna się zwiększyć. Jeśli zauważysz problemy w uporządkowanych danych:
- Napraw nieprawidłowe elementy
- Sprawdź opublikowany adres URL, by zobaczyć, czy problem nadal występuje.
- Poproś o weryfikację, korzystając z raportu o stanie.
Po opublikowaniu nowych szablonów lub zaktualizowaniu kodu
Po wprowadzeniu istotnych zmian w witrynie monitoruj wzrost liczby nieprawidłowych elementów w uporządkowanych danych.- Możesz zauważyć większą liczbę elementów nieprawidłowych, jeśli wprowadzisz nowy szablon, który nie działa, lub jeśli Twoja witryna wykorzystuje istniejący szablon w nowy i nieprawidłowy sposób.
- Jeśli okaże się, że jest mniej prawidłowych elementów (ale liczba nieprawidłowych elementów się nie zwiększyła), być może na swoich stronach nie umieszczasz już uporządkowanych danych. Użyj narzędzia do sprawdzania adresów URL, by dowiedzieć się, co jest przyczyną problemu.
Okresowe analizowanie ruchu
Analizuj ruch w wyszukiwarce Google za pomocą raportu skuteczności. Zawarte w nim dane pokazują, jak często Twoja strona wyświetla się w wyszukiwarce jako wynik z elementami rozszerzonymi, jak często użytkownicy ją klikają i jaka jest jej średnia pozycja w wynikach wyszukiwania. Możesz też pobrać te wyniki automatycznie za pomocą interfejsu Search Console API.Rozwiązywanie problemów
Jeśli masz problem z zastosowaniem lub debugowaniem uporządkowanych danych, skorzystaj z tych rozwiązań:
- Jeśli korzystasz z systemu zarządzania treścią (CMS) lub ktoś inny zajmuje się Twoją witryną, poproś odpowiednią osobę o pomoc. Pamiętaj, aby przekazać tej osobie wszystkie wiadomości z Search Console, które zawierają szczegółowe informacje o problemie.
- Google nie gwarantuje, że funkcje wykorzystujące uporządkowane dane pojawią się w wynikach wyszukiwania. Listę typowych powodów, dla których Google może nie wyświetlać Twoich treści w wyniku z elementami rozszerzonymi, znajdziesz w Ogólnych wytycznych dotyczących uporządkowanych danych.
- Możliwe, że w uporządkowanych danych wystąpił błąd. Sprawdź listę błędów uporządkowanych danych i raport dotyczący uporządkowanych danych, których nie można przeanalizować.
- Jeśli wobec Twojej strony zostały podjęte ręczne działania dotyczące uporządkowanych danych, dane te zostaną zignorowane (mimo że strona nadal może się pojawiać w wynikach wyszukiwania Google). Aby rozwiązać problemy z uporządkowanymi danymi, użyj raportu Ręczne działania.
- Przejrzyj jeszcze raz wytyczne, aby sprawdzić, czy Twoje treści ich nie naruszają. Przyczyną problemu mogą być treści spamerskie lub użycie spamerskich znaczników. Jeśli jednak problem nie jest związany ze składnią, test wyników z elementami rozszerzonymi go nie wykryje.
- Rozwiązywanie problemów z brakującymi wynikami z elementami rozszerzonymi lub ze spadkiem całkowitej liczby wyników z elementami rozszerzonymi
- Poczekaj na ponowne zindeksowanie strony. Pamiętaj, że gdy opublikujesz stronę, Google może potrzebować kilku dni na jej znalezienie i zindeksowanie. Odpowiedzi na ogólne pytania dotyczące skanowania i indeksowania znajdziesz w artykule Najczęstsze pytania o indeksowanie i skanowanie w wyszukiwarce Google.
- Zadaj pytanie na forum Centrum wyszukiwarki Google.
Określony zbiór danych nie jest wyświetlany w wynikach wyszukiwania zbiorów danych
error Przyczyna problemu: w Twojej witrynie nie ma uporządkowanych danych na stronie opisującej zbiory danych lub strona nie została jeszcze zindeksowana.
done Rozwiąż problem
- Skopiuj link do strony, która ma być widoczna w wynikach wyszukiwania zbiorów danych, i umieść go w teście wyników z elementami rozszerzonymi. Jeśli pojawi się komunikat „Strona nie obsługuje wyników z elementami rozszerzonymi, które są dostępne w tym teście” lub „Nie wszystkie znaczniki są obsługiwane w wynikach z elementami rozszerzonymi”, oznacza to, że na stronie nie ma znaczników zbioru danych lub jest ona nieprawidłowa. Aby rozwiązać ten problem, zapoznaj się z sekcją Dodawanie uporządkowanych danych.
- Jeśli na stronie znajdują się znaczniki, być może nie została ona jeszcze zindeksowana. Stan indeksowania możesz sprawdzić w Search Console.
Brakuje logo firmy lub nie wyświetla się ono prawidłowo w wynikach
error Przyczyna problemu: na Twojej stronie może brakować znaczników schema.org dla logo organizacji lub informacje o Twojej firmie nie zostały dodane do usług Google.
done Rozwiąż problem
- Dodaj do swojej strony uporządkowane dane logo.
- Dodaj informacje o firmie do usług Google.