
傳回 Google 助理的回覆時,您可以使用 回應中的語音合成標記語言 (SSML)。變更者: 您可以運用 SSML 讓對話回應看起來更自然 分別為形式,例如語言、視覺和語音下例是 SSML 標記和來自不同音訊的對應音訊 Google 助理:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
音訊
SSML 中的網址
定義只包含網址的 SSML 回應時,網址中的連字號
可能會因為 XML 格式而發生問題確保網址正確無誤
則會將 & 的執行個體替換為 &。
即使 SSML 回應只包含網址,Actions on Google 也會要求
顯示回應文字。因為 <audio> 標記中的文字不會
這時,您可以在
<audio> 標記以符合這項規定。<audio> 標記內的文字不會
並在音訊播放後向 Google 助理說話,並透過 Google 的 Action 進行操作
SSML 顯示文字版本的需求
以下是問題 SSML 回應的範例:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
上述範例並未逸出 & 為正確的 XML 格式。
修正相同 SSML 回應的固定版本如下所示:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
可使用的 SSML 元素
以下各節將說明可在動作中使用的 SSML 元素和選項。
<speak>
SSML 回應的根元素。
如要進一步瞭解 speak 元素,請參閱 W3 規格。
範例
<speak> my SSML content </speak>
<break>
控製字詞之間的停頓或其他韻律界限的空白元素。您可以選擇在任何符記組合之間使用 <break>。如果字詞之間沒有這個元素,系統會自動根據語言內容決定斷行。
如要進一步瞭解 break 元素,請參閱 W3 規格。
屬性
| 屬性 | 說明 |
|---|---|
time |
設定廣告插播長度,以秒或毫秒為單位 (例如「3 秒」或「250 毫秒」)。 |
strength |
根據相關字詞設定輸出內容的韻律休息強度。有效值為「x-weak」、「weak」、「medium」、「strong」和「x-strong」。值「無」表示不應輸出任何助力停頓邊界,可用於避免處理器會產生脈搏中斷。其他值則代表符記之間的單調非遞減 (在概念上遞增) 破壞強度。強度越高的邊界通常伴隨著停頓。 |
範例
以下範例說明如何使用 <break> 元素在步驟之間暫停:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
這個元素可讓您指出元素所含的文字建構類型相關資訊。也可協助指定轉譯包含文字時所需的細節等級。
<say‑as> 元素包含必要屬性 interpret-as,可以決定系統要如何朗讀值。你可以依據特定的 interpret-as 值,使用選用屬性 format 和 detail。
範例
interpret-as 屬性支援下列值:
-
currency以下範例的語音讀法是「40 two USD and cent」。如果省略語言屬性,則會使用目前的語言代碼。
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephone請參閱 W3C SSML 1.0 Say-as 屬性值 WG 附註中的
interpret-as='telephone'說明。以下範例的語音讀法是「one800 two new two one two two two.」。如果結果為「google:style」屬性卻省略了 0,所以會說出字母 O。
「google:style='zero-as-zero」屬性目前只適用於英文語言代碼。
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatim或spell-out以下範例會將每個字母分別讀出來:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateformat屬性是一系列日期欄位字元碼。format中支援的欄位字元代碼分別為 {y、m、d},代表年、月和日。如果代表年、月或日的欄位代碼只出現一次,則預期的位數分別為 4、2 和 2。如果欄位代碼有重複,則預期位數是代碼重複的次數。日期文字中的欄位可用標點符號和/或空格分隔。detail屬性控制日期的口說形式。如果detail='1'只有日期欄位,以及「月」或「年」欄位,兩者皆為必要欄位。在未指定全部三個欄位時,這是預設值。口說形式是「The {ordinal day} of {month}, {year}」。以下範例的語音讀法是「The tenth of9, 十 9ty:」
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>以下範例的語音讀法是「The tenth of September」:
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>detail='2'的「日」、「月」、「年」欄位為必填。當提供所有三個欄位時,這是預設值。口說形式是「{month} {ordinal day}, {year}」。以下範例的語音讀法是「9 10th, 19ty:」
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
characters以下範例的語音讀法是「C A N」:
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinal以下範例的語音讀法是「十二千三百四十五」(美式英文適用) 或「12,3000405 (英國英文)」:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinal以下範例的語音讀法是「First」:
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fraction以下範例的語音讀法是「five and a half」:
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletive或bleep以下範例呈現的嗶聲,就像經過審查後就是經過遮蔽:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unit依據數字將單位轉換為單數或複數。以下範例的語音讀法是「10 英尺」:
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
time以下範例的語音讀法是「Two thirty P.M.」:
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>format屬性是一系列時間欄位字元碼。format中支援的欄位字元碼分別為 {h、m、s、Z、12、24},代表小時、分鐘、秒 (分鐘)、時區、12 小時時間和 24 小時。如果代表小時、分鐘或秒的欄位代碼只出現一次,則預期的位數分別為 1、2 和 2。如果欄位代碼有重複,則預期位數是代碼重複的次數。時間文字中的欄位可用標點符號和/或空格分隔。如未以上述格式指定時、分或秒,或者沒有相符的數字,則系統會將該欄位視為零。format的預設值為「hms12」。detail屬性可控制口說時間是 12 小時製或 24 小時制。如果省略detail='1'或detail且時間格式是 24 小時,則口說形式是 24 小時制。如果detail='2'或省略detail且時間格式為 12 小時,則口說形式是 12 小時。
如要進一步瞭解 say-as 元素,請參閱 W3 規格。
<audio>
支援插入錄製的音訊檔案,以及插入其他音訊格式與合成語音輸出。
屬性
| 屬性 | 必填 | 預設 | 值 |
|---|---|---|---|
src |
是 | 不適用 | 參照音訊媒體來源的 URI。支援的通訊協定為 https。 |
clipBegin |
否 | 0 | TimeDesignation,從音訊來源的開頭到開始播放音訊之間的偏移值。如果這個值大於或等於音訊來源的實際長度,則不會插入任何音訊。 |
clipEnd |
否 | 無限 | TimeDesignation,從音訊來源的開頭到結束播放之間的偏移值。如果音訊來源的實際時間長度少於這個值,系統就會在該時間點結束播放。如果 clipBegin 大於或等於 clipEnd,則不會插入任何音訊。 |
speed |
否 | 100% | 輸出播放率相對於正常輸入速率的比率,以百分比表示。格式為正實數,後面接 %。目前支援的範圍為 [50% (慢 - 半速)、200% (快 - 兩倍速)]。超出該範圍的值可能會 (或可能不會) 調整到落在該範圍之內。 |
repeatCount |
否 | 1,如果設定 repeatDur,則為 10 |
是一個實數,指定要插入多少次音訊 (剪輯之後,會以 clipBegin 和/或 clipEnd 表示)。不支援非小數的重複次數,因此系統會將該值四捨五入至最接近的整數。零不是有效值,因此會視為未指定,而使用預設值。 |
repeatDur |
否 | 無限 | TimeDesignation,限制在為 clipBegin、clipEnd、repeatCount 和 speed 屬性處理來源後 (而不是一般播放時間長度) 後,插入的音訊的時間長度限制。如果處理後的音訊長度少於此值,則播放會在值所在的時間點結束。 |
soundLevel |
否 | +0dB | 請依soundLevel分貝調整音訊的音量。範圍上限是 +/-40dB,但實際範圍可能更低,而且輸出品質可能無法在整個範圍內產生良好的結果。 |
下方是目前支援的音訊設定:
- 格式:MP3 (MPEG v2)
- 每秒取樣 24K
- 每秒 24K ~ 96K 位元,固定速率
- 格式:Ogg 中的 Opus
- 每秒取樣 24K (超寬頻)
- 每秒 24K - 96K 位元,固定速率
- 格式 (已淘汰):WAV (RIFF)
- PCM 16 符號位元,little endian 位元組順序
- 每秒取樣 24K
- 適用於所有格式:
- 建議使用單聲道,但也可以接受立體聲。
- 長度上限為 240 秒。如要播放較長的音訊,建議您導入媒體回應。
- 檔案大小上限 5 MB。
- 來源網址必須使用 HTTPS 通訊協定。
- 擷取音訊時,我們的 UserAgent 是「Google-Speech-Actions」。
<audio> 元素的內容為選用項目,如果無法播放音訊檔案或輸出裝置不支援音訊,就會使用這些內容。內容可能包含 <desc> 元素,在此情況下,系統會顯示該元素的文字內容。詳情請參閱回應檢查清單中的「錄製的音訊」一節。
src 網址也必須為 HTTPS 網址。Google Cloud Storage 可以透過 HTTPS 網址代管您的音訊檔案。
如要進一步瞭解媒體回應,請參閱《回應》指南中的媒體回應一節。
如要進一步瞭解 audio 元素,請參閱 W3 規格。
範例
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
句子和段落元素。
如要進一步瞭解 p 和 s 元素,請參閱 W3 規格。
範例
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
最佳做法
- 使用 <s>...</s>標記來包覆完整句子,特別是如果 SSML 元素會改變發音的話 (即 <audio>、<break>、<emphasis>、<par>、<prosody>、<say-as>、<seq> 和 <sub>)。
- 如果口語中斷有很長一段時間,可聽到內容,請使用 <s>...</s>標記,並在句子之間加上換行符號
<sub>
指出別名屬性值中的文字將取代原有文字,方便發音。
您也可以使用 sub 元素,為難以閱讀的字詞提供簡化發音。在下面的最後一個範例中,我們以日文示範這個用法。
如要進一步瞭解 sub 元素,請參閱 W3 規格。
範例
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
這個空白元素會將標記放在文字或標記序列中。可用來參照 或在輸出串流中插入標記時,顯示序列中特定位置 非同步通知。
,瞭解如何調查及移除這項存取權。如要進一步瞭解 mark 元素,請參閱 W3 規格。
範例
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
用於自訂元素所含文字的音調、說話速度和音量。目前支援 rate、pitch 和 volume 屬性。
您可以依據 W3 規格設定 rate 和 volume 屬性。有三種方式可以設定 pitch 屬性的值:
| 屬性 | 說明 |
|---|---|
name |
各個標記的字串 ID。 |
| 選項 | 說明 |
|---|---|
| 相對時間 | 指定一個相對值 (例如「低」、「中」、「高」等),其中「medium」是為預設音調 |
| 半調色 | 將音調調高或調低「N」使用「+Nst」做為半音調或「-Nst」。請注意,「+/-」和「st」必填。 |
| 百分比 | 將音調調高或調低「N」按「+N%」計算百分比或「-N%」。請注意,「%」須為必填,但「+/-」為選用項目。 |
如要進一步瞭解 prosody 元素,請參閱 W3 規格。
範例
以下範例使用 <prosody> 元素,以低於正常音調 2 個半音的音慢說話:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
用來在元素內含的文字中新增或移除強調語氣。<emphasis> 元素修改語音的方式與 <prosody> 類似,但不必設定個別語音屬性。
此元素支援選用的「level」屬性,其有效值如下:
strongmoderatenonereduced
如要進一步瞭解 emphasis 元素,請參閱 W3 規格。
範例
下列範例使用 <emphasis> 元素發布公告:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
平行媒體容器,可讓您一次播放多個媒體元素。唯一允許的內容是由一或多個 <par>、<seq> 和 <media> 元素所組成。<media> 元素的順序並不重要。
除非子元素指定了不同的開始時間,否則元素隱含的開始時間會與 <par> 容器的開始時間相同。如果子元素的「begin」或「end」屬性設定了偏移值,則元素的偏移時間會與 <par> 容器的開始時間有關。如果是根層級 <par> 元素,系統會忽略 start 屬性,開始時間則是指 SSML 語音合成程序開始為根 <par> 元素產生輸出內容的時間 (亦即實際上將時間設為「零」)。
範例
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
序列媒體容器,可讓您逐一播放媒體元素。唯一允許的內容是由一或多個 <seq>、<par> 和 <media> 元素所組成。媒體元素的顯示順序就是媒體元素的顯示順序。
子元素的「begin」和「end」屬性可以設為偏移值 (請參閱下方的時間規格)。這些子元素偏移值與序列中前一個元素的結尾相關,若是序列中的第一個元素,則相對於其 <seq> 容器的開頭。
範例
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
代表 <par> 或 <seq> 元素中的媒體圖層。允許的 <media> 元素內容是 SSML <speak> 或 <audio> 元素。下表說明 <media> 元素的有效屬性。
屬性
| 屬性 | 必填 | 預設 | 值 |
|---|---|---|---|
| xml:id | 否 | 沒有數值 | 這個元素的專屬 XML ID。不支援經過編碼的實體。允許的 ID 值與規則運算式 "([-_#]|\p{L}|\p{D})+" 相符。詳情請參閱 XML-ID。 |
| 開始 | 否 | 0 | 此媒體容器的開始時間。如果這是根媒體容器元素,則忽略此值 (視為預設值「0」)。如要瞭解有效的字串值,請參閱下方的時間規格一節。 |
| end | 否 | 沒有數值 | 此媒體容器的結束時間規格。如要瞭解有效的字串值,請參閱下方的時間規格一節。 |
| repeatCount | 否 | 1 | 是一個實數,指定要插入多少次媒體。不支援非小數的重複次數,因此系統會將該值四捨五入至最接近的整數。零不是有效值,因此會視為未指定,而使用預設值。 |
| repeatDur | 否 | 沒有數值 | TimeDesignation,限制插入媒體的時間長度。如果媒體的長度低於此值,則播放會在值所在的時間點結束。 |
| soundLevel | 否 | +0dB | 用 soundLevel 分貝調整音訊的音量。範圍上限是 +/-40dB,但實際範圍可能更低,而且輸出品質可能無法在整個範圍內產生良好的結果。 |
| fadeInDur | 否 | 0 秒 | TimeDesignation,超過此值,媒體會從無聲漸入到選擇性指定的 soundLevel。如果媒體的時間長度低於此值,播放結束時就會停止淡入,不會達到指定的音量。 |
| fadeOutDur | 否 | 0 秒 | TimeDesignation,超過此值,媒體會從選擇性指定的 soundLevel 淡出,直到無聲為止。如果媒體的時間長度小於這個值,系統就會將聲音水平設為較低的值,確保播放結束時不會設為靜音。 |
時間規格
時間規格用於 <media> 元素和媒體容器 (<par> 和 <seq> 元素) 的「begin」和「end」屬性值,可以是偏移值 (例如 +2.5s) 或同步處理基數 (例如 foo_id.end-250ms)。
- 偏移值 - 時間偏移值是一種 SMIL 時間計數值,允許符合規則運算式的值:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"第一個數字字串是十進位數字的全部部分,第二個數字字串是小數的小數部分。預設符號 (即「(+|-)?」) 是「+」。單位值分別對應時、分、秒和毫秒。單位的預設值是「s」(秒)。
- 同步基準值 - 同步處理基準值是 SMIL 同步處理基準值,允許符合規則運算式的值:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"數字和單位的解釋方式與偏移值相同。
TTS 模擬工具
動作控制台提供 TTS 模擬工具,可用來測試 SSML 不支援以上任何元素您可以在控制台中找到 TTS 模擬工具 前往「模擬工具」>「音訊:在模擬工具中輸入文字和 SSML,然後按一下 更新並聆聽即可聽取 TTS 輸出內容。
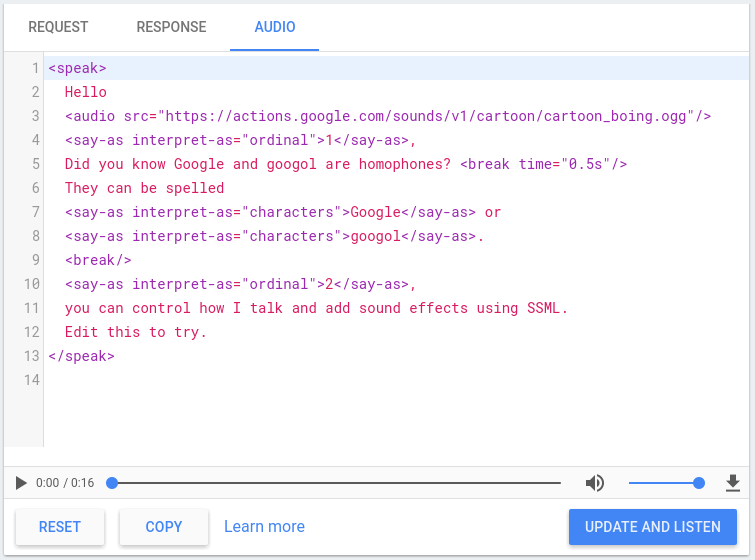
你也可以點選下載按鈕,將 TTS 的 .mp3 檔案儲存下來
輸出內容