Tìm hiểu kiến thức cơ bản về SEO cho JavaScript
JavaScript là một phần quan trọng của nền tảng web vì ngôn ngữ lập trình này cung cấp nhiều tính năng để đưa web trở thành một nền tảng ứng dụng mạnh mẽ. Việc tạo điều kiện cho người dùng tìm ra các ứng dụng web dùng JavaScript thông qua Google Tìm kiếm có thể giúp bạn tìm được người dùng mới và tiếp tục thu hút người dùng hiện hữu khi họ tìm kiếm nội dung mà ứng dụng web của bạn cung cấp. Mặc dù Google Tìm kiếm chạy JavaScript bằng một phiên bản Chromium tự động cập nhật, nhưng bạn vẫn có thể tối ưu hoá một số yếu tố.
Hướng dẫn này mô tả cách Google Tìm kiếm xử lý JavaScript và các phương pháp hay nhất để cải thiện các ứng dụng web dùng JavaScript cho Google Tìm kiếm.
Cách Google xử lý JavaScript
Google xử lý các ứng dụng web dùng JavaScript theo ba giai đoạn chính:
- Thu thập dữ liệu
- Kết xuất
- Lập chỉ mục
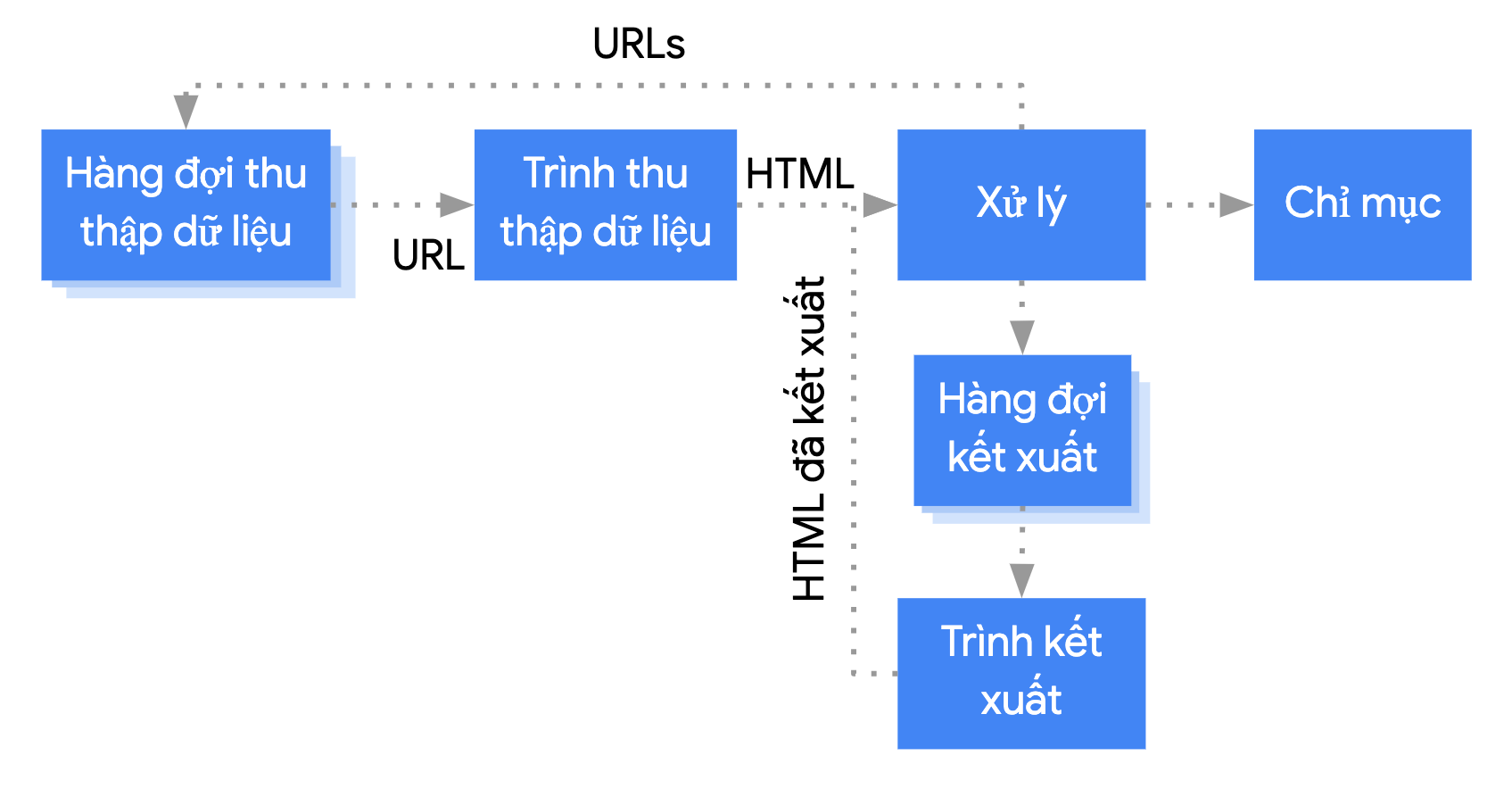
Googlebot xếp hàng các trang để thu thập thông tin và kết xuất. Sẽ khó phân biệt được ngay xem là một trang đang chờ thu thập dữ liệu hay đang chờ kết xuất. Khi Googlebot tìm nạp URL từ hàng đợi thu thập dữ liệu bằng cách đưa ra yêu cầu HTTP, thì trước tiên, Googlebot sẽ kiểm tra xem bạn có cho phép thu thập dữ liệu hay không. Googlebot có đọc tệp robots.txt. Nếu tệp này đánh dấu URL là không được phép thu thập dữ liệu, thì Googlebot sẽ bỏ qua yêu cầu HTTP cũng như bỏ qua URL này. Google Tìm kiếm sẽ không kết xuất JavaScript từ các tệp bị chặn hoặc trên các trang bị chặn.
Sau đó, Googlebot phân tích cú pháp nội dung phản hồi cho các URL khác trong thuộc tính href của các đường liên kết HTML và thêm các URL đó vào hàng đợi thu thập dữ liệu. Để ngăn chặn việc tìm ra đường liên kết, hãy dùng cơ chế nofollow.
Phương pháp thu thập dữ liệu URL và phân tích cú pháp nội dung phản hồi HTML hoạt động hiệu quả đối với các trang web kiểu cũ hoặc các trang kết xuất phía máy chủ, là những trang mà HTML trong phản hồi HTTP chứa toàn bộ nội dung. Một số trang web JavaScript có thể sử dụng mô hình giao diện ứng dụng, trong đó HTML ban đầu không chứa nội dung thực tế và Google cần thực thi JavaScript trước thì mới xem được nội dung trang thực tế mà JavaScript tạo ra.
Googlebot đưa tất cả các trang vào hàng đợi để kết xuất, trừ phi tiêu đề hoặc thẻ meta robots yêu cầu Google không lập chỉ mục trang.
Trang có thể ở trong hàng đợi này trong vài giây, nhưng có thể sẽ lâu hơn. Khi tài nguyên của Google cho phép, một phiên bản Chromium không có giao diện người dùng sẽ kết xuất trang và thực thi JavaScript.
Googlebot phân tích cú pháp HTML đã kết xuất cho các đường liên kết một lần nữa và đưa các URL đã tìm thấy vào hàng đợi để thu thập dữ liệu. Google cũng sử dụng HTML đã kết xuất để lập chỉ mục trang.
Hãy nhớ rằng kết xuất phía máy chủ hoặc kết xuất trước vẫn là cách hay vì giúp trang web của bạn chạy nhanh hơn đối với người dùng và trình thu thập dữ liệu. Hơn nữa, không phải bot nào cũng có thể chạy JavaScript.
Mô tả trang bằng tiêu đề và đoạn trích độc nhất
Các phần tử <title> cùng những đoạn mô tả meta độc đáo và sinh động sẽ giúp người dùng nhanh chóng xác định kết quả phù hợp nhất với mục tiêu của họ.
Bạn có thể dùng JavaScript để thiết lập hoặc thay đổi nội dung mô tả meta cũng như phần tử <title>.
Viết mã tương thích
Các trình duyệt cung cấp nhiều API và JavaScript là ngôn ngữ có tốc độ phát triển nhanh. Google có một số hạn chế về các API và tính năng JavaScript được hỗ trợ. Để đảm bảo mã của bạn tương thích với Google, hãy làm theo các nguyên tắc của chúng tôi để khắc phục sự cố liên quan đến JavaScript.
Bạn nên sử dụng tính năng phân phát biệt lập và đoạn mã polyfill nếu phát hiện thấy API trình duyệt mà bạn cần không có trong danh sách API được hỗ trợ. Vì một số tính năng của trình duyệt không thể sử dụng đoạn mã polyfill, bạn nên kiểm tra tài liệu polyfill để biết các hạn chế tiềm ẩn.
Sử dụng mã trạng thái HTTP có nghĩa
Googlebot sử dụng mã trạng thái HTTP để phát hiện vấn đề khi thu thập dữ liệu trang.
Để thông báo cho Googlebot về một trang không thu thập dữ liệu hoặc lập chỉ mục được, hãy sử dụng mã trạng thái có nghĩa, như 404 cho một trang không thể tìm thấy hoặc 401 cho trang yêu cầu đăng nhập.
Bạn có thể sử dụng mã trạng thái HTTP để thông báo cho Googlebot khi một trang đã chuyển sang URL mới, để Googlebot có thể cập nhật chỉ mục tương ứng.
Sau đây là danh sách mã trạng thái HTTP và tác động của chúng đối với Google Tìm kiếm.
Tránh các lỗi soft 404 trong các ứng dụng trang đơn
Trong các ứng dụng trang đơn kết xuất ở phía máy khách, việc định tuyến thường được triển khai dưới dạng định tuyến phía máy khách.
Trong trường hợp này, việc sử dụng mã trạng thái HTTP có nghĩa có thể sẽ không khả thi hoặc không thiết thực.
Để tránh lỗi soft 404 khi sử dụng chức năng kết xuất và định tuyến phía máy khách, hãy sử dụng một trong các chiến lược sau:
- Sử dụng lệnh chuyển hướng JavaScript đến một URL mà máy chủ phản hồi bằng mã trạng thái HTTP
404(ví dụ:/not-found). - Thêm
<meta name="robots" content="noindex">vào các trang lỗi bằng JavaScript.
Sau đây là mã mẫu cho phương pháp sử dụng lệnh chuyển hướng:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Sau đây là mã mẫu cho phương pháp sử dụng thẻ noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Sử dụng API Nhật ký (History API) thay vì các phân mảnh
Google chỉ phát hiện được đường liên kết của bạn nếu đó là phần tử HTML <a> có thuộc tính href.
Đối với các ứng dụng trang đơn định tuyến phía máy khách, hãy dùng History API để triển khai định tuyến giữa các chế độ xem của ứng dụng web. Để đảm bảo Googlebot có thể phân tích cú pháp và trích xuất các URL, đừng dùng các phân mảnh để tải những nội dung trang khác biệt. Ví dụ sau đây là một phương pháp không hay vì Googlebot không thể giải quyết các URL một cách đáng tin cậy:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Thay vào đó, bạn có thể triển khai API Nhật ký để đảm bảo Googlebot có thể truy cập các URL:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Chèn thẻ rel="canonical" cho đường liên kết theo đúng cách
Tuy không nên dùng JavaScript trong trường hợp này, nhưng bạn có thể chèn thẻ rel="canonical" cho đường liên kết bằng JavaScript.
Google Tìm kiếm sẽ chọn URL chính tắc được chèn khi hiển thị trang. Sau đây là một ví dụ về cách chèn thẻ liên kết rel="canonical" bằng JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Thận trọng khi dùng robots thẻ meta
Thông qua thẻ meta robots, bạn có thể ngăn Google lập chỉ mục một trang hoặc đi theo các đường liên kết.
Ví dụ: việc thêm thẻ meta sau đây vào đầu trang sẽ chặn Google lập chỉ mục trang đó:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Bạn có thể dùng JavaScript để thêm thẻ meta robots vào một trang hoặc thay đổi nội dung của trang đó.
Đoạn mã ví dụ sau đây cho thấy cách thay đổi thẻ meta robots bằng JavaScript để ngăn Google lập chỉ mục trang hiện tại nếu lệnh gọi API không trả về nội dung.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Khi gặp noindex trong thẻ meta robots trước khi chạy JavaScript, Google sẽ không kết xuất hoặc lập chỉ mục trang.
Sử dụng phương pháp lưu vào bộ nhớ đệm trong thời gian dài
Googlebot thường xuyên lưu nội dung vào bộ nhớ đệm để giảm số yêu cầu gửi đến các mạng cũng như giảm mức sử dụng tài nguyên. WRS có thể bỏ qua tiêu đề bộ nhớ đệm. Việc này có thể khiến WRS sử dụng các tài nguyên JavaScript hoặc CSS đã cũ.
Vân tay số nội dung có thể giúp bạn tránh vấn đề này bằng cách tạo vân tay số cho phần nội dung trong tên tệp, ví dụ như main.2bb85551.js.
Vân tay số này sẽ phụ thuộc vào nội dung của tệp, vì vậy tên tệp sẽ thay đổi mỗi lần bạn cập nhật.
Để tìm hiểu thêm, hãy xem hướng dẫn trên web.dev về các chiến lược lưu vào bộ nhớ đệm trong thời gian dài.
Sử dụng dữ liệu có cấu trúc
Khi dùng dữ liệu có cấu trúc trên các trang của mình, bạn có thể dùng JavaScript để tạo nội dung JSON-LD cần thiết rồi đưa nội dung đó vào trang. Hãy nhớ kiểm tra kết quả triển khai để tránh các sự cố.
Làm theo các phương pháp hay nhất đối với thành phần web
Google hỗ trợ các thành phần web. Khi kết xuất một trang, Google sẽ gộp nội dung trong DOM tối (shadow DOM) và DOM sáng (light DOM) lại thành một. Tức là Google chỉ nhìn thấy phần nội dung xuất hiện trong HTML đã kết xuất. Nhằm đảm bảo rằng Googlebot vẫn có thể thấy nội dung của bạn sau khi kết xuất, hãy sử dụng Công cụ kiểm tra kết quả nhiều định dạng hoặc Công cụ kiểm tra URL để xem mã HTML được kết xuất.
Nếu nội dung không xuất hiện trong HTML đã kết xuất, Google sẽ không lập chỉ mục được những nội dung đó.
Trong ví dụ sau đây, một thành phần web được tạo ra và cho thấy nội dung DOM sáng bên trong DOM tối tương ứng. Một cách để đảm bảo cả nội dung DOM sáng và DOM tối đều xuất hiện trong HTML đã kết xuất là sử dụng phần tử Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Sau khi kết xuất, Google có thể lập chỉ mục nội dung này:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Khắc phục hình ảnh và nội dung tải từng phần
Hình ảnh có thể chiếm nhiều băng thông và làm giảm đáng kể hiệu suất. Một chiến lược hay là sử dụng phương pháp tải từng phần để chỉ tải hình ảnh khi người dùng sắp nhìn thấy hình ảnh đó. Để đảm bảo triển khai tải từng phần theo cách phù hợp cho hoạt động tìm kiếm, hãy làm theo các nguyên tắc của chúng tôi đối với cơ chế tải từng phần.
Thiết kế nhằm hỗ trợ khả năng tiếp cận
Hãy tạo trang không chỉ cho các công cụ tìm kiếm mà còn cho người dùng. Khi bạn thiết kế trang web, hãy nghĩ đến nhu cầu của người dùng, trong đó có cả những người không sử dụng trình duyệt hỗ trợ JavaScript (ví dụ: những người sử dụng trình đọc màn hình hoặc thiết bị di động thế hệ cũ). Một trong những cách dễ dàng nhất để kiểm tra khả năng tiếp cận của trang web của bạn là xem trước trang web đó bằng trình duyệt đã tắt JavaScript, hoặc xem bằng một trình duyệt chỉ hỗ trợ văn bản như Lynx. Bằng cách xem một trang web dưới dạng văn bản đơn thuần, bạn cũng có thể xác định được những nội dung khác mà có thể Googlebot khó nhận thấy, chẳng hạn như văn bản được nhúng trong hình ảnh.