Comprende los aspectos básicos de SEO en JavaScript
JavaScript es una parte importante de la plataforma web porque proporciona muchas funciones que convierten a la Web en una potente plataforma de aplicaciones. Permitir que tus aplicaciones web con tecnología JavaScript sean detectables por medio de la Búsqueda de Google puede ayudarte a encontrar usuarios nuevos y volver a captar el interés de los existentes cuando buscan el contenido que proporciona tu aplicación web. Si bien la Búsqueda de Google ejecuta JavaScript con una versión de Chromium perdurable, hay algunas funciones que puedes optimizar.
En esta guía, se explica cómo la Búsqueda de Google procesa JavaScript y se describen las prácticas recomendadas de optimización de aplicaciones web con JavaScript para la Búsqueda de Google.
Cómo Google procesa JavaScript
Google procesa las aplicaciones web con JavaScript en tres fases principales:
- Rastreo
- Procesamiento
- Indexación
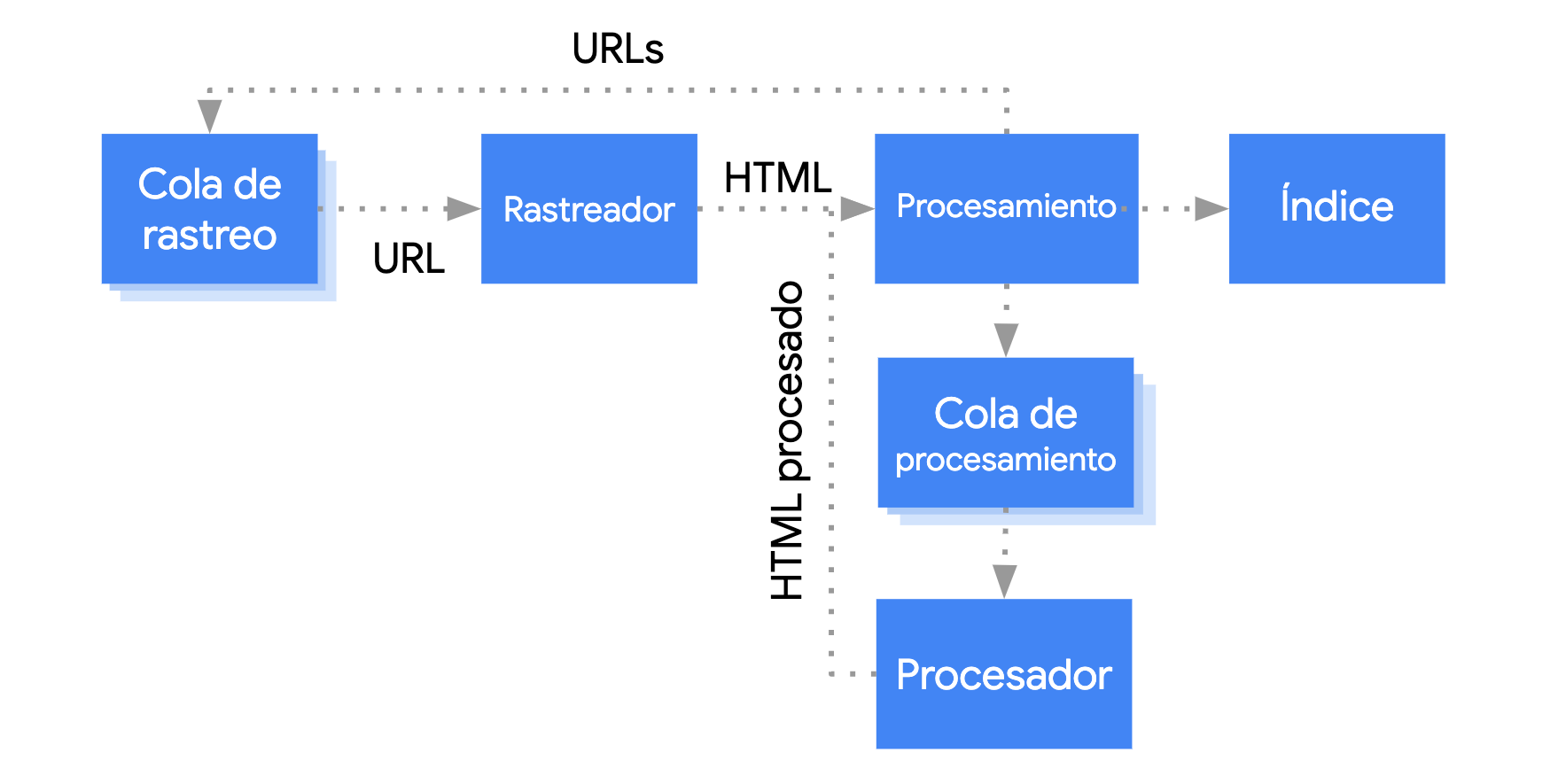
Este pone páginas en la cola para rastrearlas y procesarlas. No se puede ver de forma inmediata cuándo una página está esperando su rastreo y cuándo su renderización. Cuando Googlebot recupera una URL desde la cola de rastreo con una solicitud HTTP, primero verifica si permites el rastreo. Para ello, lee el archivo robots.txt. Si la URL se marcó como no permitida, entonces Googlebot no envía la solicitud HTTP para esta URL y la omite. La Búsqueda de Google no renderizará JavaScript de archivos bloqueados ni en páginas bloqueadas.
Luego, Googlebot analiza la respuesta de las otras URLs en el atributo href de los vínculos HTML y agrega las URLs a la cola de rastreo. Para evitar la detección de vínculos, usa el mecanismo nofollow.
El rastreo de una URL y el análisis de la respuesta HTML funcionan bien para los sitios web clásicos o las páginas procesadas por el servidor, en las que el HTML de la respuesta HTTP incluye todo el contenido. Algunos sitios de JavaScript pueden usar el modelo de shell de la app en el que el HTML inicial no incluye el contenido real y Google necesita ejecutar JavaScript para poder ver el contenido real de la página generado por JavaScript.
Googlebot pone en cola todas las páginas para su renderización, a menos que un encabezado o una etiqueta robots meta indique a Google que no indexe la página.
La página puede permanecer en esta cola durante unos segundos, pero podría tardar más. Una vez que los recursos de Google lo permiten, una versión de Chromium sin interfaz gráfica procesa la página y ejecuta JavaScript.
Googlebot vuelve a analizar el HTML procesado para los vínculos y pone en cola las URLs que encuentra para rastrear. Google también usa el HTML procesado para indexar la página.
Ten en cuenta que la renderización previa o la del servidor siguen siendo una buena opción, ya que hace que el sitio web funcione más rápido para los usuarios y los rastreadores, y no todos los bots pueden ejecutar JavaScript.
Describe tu página con títulos y fragmentos únicos
Los elementos <title> y las metadescripciones únicos y descriptivos ayudan a los usuarios a identificar rápidamente el mejor resultado para su propósito.
Puedes usar JavaScript para establecer o cambiar la metadescripción y el elemento <title>.
Escribe código compatible
Los navegadores ofrecen muchas API y JavaScript es un lenguaje que evoluciona rápidamente. Google tiene algunas limitaciones con respecto a las APIs y las funciones de JavaScript que admite. Para asegurarte de que tu código sea compatible con Google, sigue nuestros lineamientos de solución de problemas de JavaScript.
Te recomendamos que uses la publicación diferencial y polyfills si detectas que falta la API de una función en el navegador que necesitas. Como algunas funciones del navegador no pueden incluirse mediante polyfill, te recomendamos verificar la documentación sobre polyfill para conocer las limitaciones potenciales.
Usa códigos de estado HTTP significativos
Googlebot usa códigos de estado HTTP para detectar si se produjo algún error cuando se hizo el rastreo de la página.
Para indicarle a Googlebot si una página no se puede rastrear o indexar, usa un código de estado significativo, como 404 para una página que no se pudo encontrar o 401 para páginas que están atrasadas un acceso.
Puedes usar los códigos de estado HTTP para indicarle a Googlebot si una página se movió a una nueva URL, de manera que el índice pueda actualizarse correctamente.
En esta lista, se describen los códigos de estado HTTP y el modo en que afectan a la Búsqueda de Google.
Evita errores soft 404 en apps de una sola página
En las apps de una sola página renderizadas por el cliente, el enrutamiento se suele implementar como enrutamiento del cliente.
En este caso, el uso de códigos de estado HTTP significativos puede ser imposible o poco práctico.
Para evitar los errores soft 404 cuando usas la renderización y el enrutamiento del cliente, utiliza una de las siguientes estrategias:
- Usa un redireccionamiento de JavaScript a una URL a la que el servidor responde con un código de estado HTTP
404(por ejemplo,/not-found). - Agrega un elemento
<meta name="robots" content="noindex">a las páginas de error con JavaScript.
Este es un código de muestra para el enfoque de redireccionamiento:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Este es un código de muestra para el enfoque de la etiqueta noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Usa la API de History en lugar de fragmentos
Google solo puede descubrir tus vínculos si son elementos HTML <a> con un atributo href.
En el caso de aplicaciones de una sola página con enrutamiento del cliente, usa la API de History para implementar el enrutamiento entre diferentes vistas de tu app web. Evita utilizar fragmentos para cargar contenido de páginas diferentes si quieres asegurarte de que Googlebot pueda analizar y extraer tus URLs. En el siguiente ejemplo, se muestra una práctica no recomendada, ya que Googlebot no puede resolver de manera confiable las URLs:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
En su lugar, puedes asegurarte de que Googlebot pueda acceder a tus URLs mediante la implementación de la API de Historial:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Inserta la etiqueta de vínculo rel="canonical" correctamente
Si bien no recomendamos usar JavaScript para este fin, es posible incorporar una etiqueta de vínculo rel="canonical" con dicho lenguaje de programación.
La Búsqueda de Google detectará la URL canónica que se insertó durante la renderizacion de la página. A continuación, se muestra un ejemplo para insertar una etiqueta de vínculo rel="canonical" con JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Usa las etiquetas robots meta cuidadosamente
Puedes evitar que Google indexe una página o siga vínculos con la etiqueta robots meta.
Por ejemplo, si agregas la siguiente etiqueta meta en la parte superior de tu página, impedirás que Google la indexe:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Puedes usar JavaScript para agregar una etiqueta robots meta a una página o cambiar su contenido.
El siguiente código de ejemplo muestra cómo cambiar la etiqueta robots meta con JavaScript para evitar la indexación de la página actual si una llamada a la API no muestra contenido.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Cuando Google encuentra noindex en la etiqueta robots meta antes de ejecutar JavaScript, no renderiza ni indexa la página.
Usa el almacenamiento en caché de larga duración
Googlebot almacena en caché de forma resolutiva para reducir las solicitudes de red y el uso de recursos. WRS puede ignorar los encabezados de almacenamiento en caché. Como consecuencia, es posible que WRS use recursos JavaScript o CSS desactualizados.
El reconocimiento de huellas digitales de contenido evita este problema porque incluye una huella digital de contenido como parte del nombre del archivo, por ejemplo, main.2bb85551.js.
La huella digital depende del contenido del archivo, por lo que cada vez que se lanza una actualización se genera un nombre de archivo diferente.
Consulta la guía de web.dev sobre estrategias de almacenamiento en caché de larga duración para obtener más información.
Usa datos estructurados
Si usas datos estructurados en tus páginas, puedes utilizar JavaScript para generar el archivo JSON-LD necesario e insertarlo en la página. Asegúrate de probar la implementación para evitar problemas.
Sigue las prácticas recomendadas para componentes web
Google admite componentes web. Cuando Google procesa una página, acopla el contenido del shadow DOM y del light DOM. Eso significa que Google solo puede ver el contenido que está visible en el HTML procesado. Para asegurarte de que Google pueda ver tu contenido después de procesarlo, usa la prueba de resultados enriquecidos o la Herramienta de inspección de URL y observa el HTML procesado.
Si el contenido no es visible en el HTML procesado, Google no podrá indexarlo.
En el siguiente ejemplo, se crea un componente web que muestra su contenido de light DOM dentro de su shadow DOM. Una forma de asegurarse de que tanto el contenido del light DOM como del shadow DOM se muestre en el HTML procesado es utilizar un elemento slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Después del procesamiento, Google puede indexar este contenido:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Soluciona los problemas con las imágenes y el contenido de carga diferida
Las imágenes pueden consumir mucho ancho de banda y rendimiento. Una buena estrategia es utilizar la carga diferida para cargar imágenes solo cuando el usuario esté a punto de verlas. Para asegurarte de estar implementando una carga diferida que sea fácil de buscar, sigue nuestros lineamientos de carga diferida.
Crea diseños accesibles
Crea páginas para los usuarios, no solo los motores de búsqueda. Cuando diseñes tu sitio, piensa en las necesidades de tus usuarios, incluso de aquellos que no usan un navegador JavaScript (por ejemplo, los que utilizan lectores de pantalla o dispositivos móviles menos avanzados). Una de las formas más fáciles de probar la accesibilidad de tu sitio es generar una vista previa de este en tu navegador con JavaScript desactivado, o bien verlo en un navegador de solo texto como Lynx. La visualización de un sitio como solo de texto también puede ayudarte a identificar otro contenido que podría ser difícil de ver para Google, como el texto incorporado en imágenes.