
Z tego dokumentu dowiesz się, jak korzystać z przykładowych danych identyfikatorów miejsc z Statystyk miejsc za pomocą funkcji zliczania miejsc oraz ukierunkowanych wyszukiwań informacji o miejscu, aby zwiększyć wiarygodność wyników.
Szczegółową implementację referencyjną tego wzorca znajdziesz w tym wyjaśniającym notatniku:
 Wyświetl źródło w GitHubie
Wyświetl źródło w GitHubie
Wzór architektoniczny
Ten wzorzec architektury zapewnia powtarzalny przepływ pracy, który pozwala wypełnić lukę między analizą statystyczną wysokiego poziomu a weryfikacją danych podstawowych. Łącząc skalę BigQuery z precyzją interfejsu Places API, możesz z pewnością weryfikować wyniki analiz. Jest to szczególnie przydatne w przypadku wyboru lokalizacji, analizy konkurencji i badań rynku, w których zaufanie do danych ma kluczowe znaczenie.
Podstawą tego wzorca są 4 kluczowe kroki:
- Przeprowadzanie analiz na dużą skalę: użyj funkcji zliczania miejsc z Statystyk miejsc w BigQuery, aby analizować dane o miejscach na dużym obszarze geograficznym, np. w całym mieście lub regionie.
- Izolowanie i wyodrębnianie próbek: zidentyfikuj obszary zainteresowania (np. „hotspoty” o dużej gęstości) na podstawie zagregowanych wyników i wyodrębnij
sample_place_idspodane przez funkcję. - Pobieranie danych podstawowych: użyj wyodrębnionych identyfikatorów miejsc, aby wykonywać ukierunkowane wywołania interfejsu Place Details API i pobierać szczegółowe informacje o każdym miejscu.
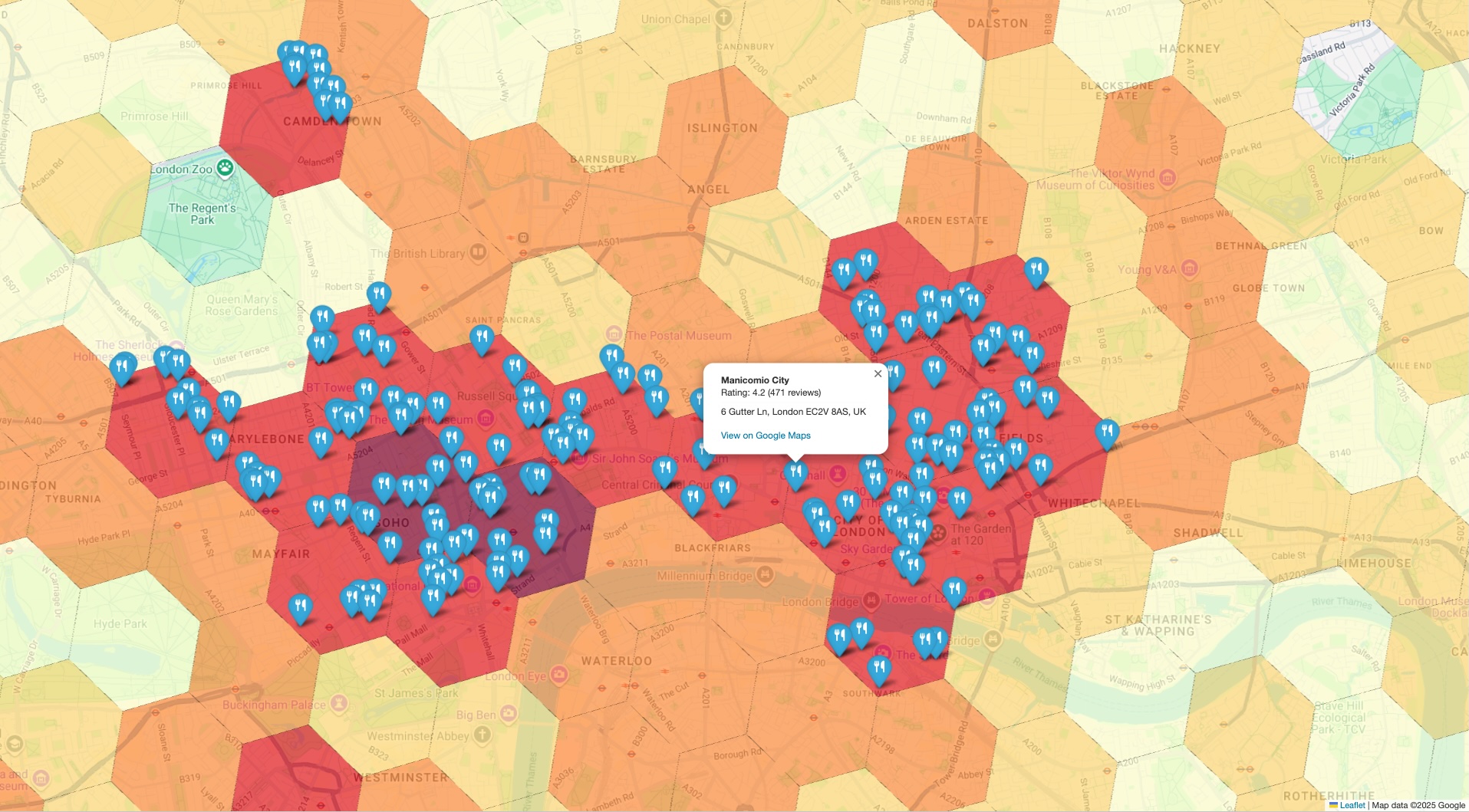
- Utwórz wizualizację łączoną: nałóż szczegółowe dane o miejscach na początkową mapę statystyczną wysokiego poziomu, aby wizualnie sprawdzić, czy zagregowane liczby odzwierciedlają rzeczywistość w terenie.
Przepływ pracy rozwiązania
Ten proces umożliwia połączenie trendów na poziomie makro z faktami na poziomie mikro. Zaczynasz od ogólnego widoku statystycznego, a następnie strategicznie przechodzisz do bardziej szczegółowego widoku, aby zweryfikować dane za pomocą konkretnych przykładów z życia.
Analizowanie gęstości miejsc na dużą skalę za pomocą Statystyk miejsc
Pierwszym krokiem jest ogólne zapoznanie się z sytuacją. Zamiast pobierać tysiące pojedynczych ciekawych miejsc (POI), możesz uruchomić jedno zapytanie, aby uzyskać podsumowanie statystyczne.
Idealnie nadaje się do tego PLACES_COUNT_PER_H3funkcja Statystyki miejsc. Agreguje liczbę punktów POI w systemie siatki sześciokątnej (H3), co pozwala szybko identyfikować obszary o wysokiej lub niskiej gęstości na podstawie określonych kryteriów (np. restauracje o wysokiej ocenie, które są otwarte).
Przykładowe zapytanie: Pamiętaj, że musisz podać obszar geograficzny wyszukiwania. Do pobierania danych o granicach geograficznych można używać otwartego zbioru danych, takiego jak Overture Maps Data, który jest publicznym zbiorem danych BigQuery.
W przypadku często używanych granic otwartych zbiorów danych zalecamy zapisanie ich w tabeli we własnym projekcie. Znacząco obniża to koszty BigQuery i zwiększa wydajność zapytań.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
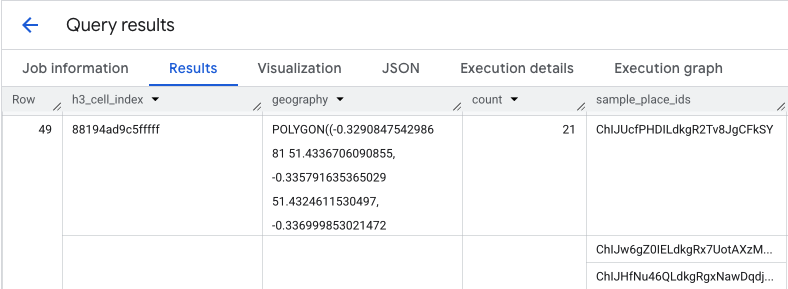
Wynikiem tego zapytania jest tabela komórek H3 i liczba Miejsc w każdej z nich, która stanowi podstawę mapy gęstości.
Izolowanie ognisk zakażeń i wyodrębnianie przykładowych identyfikatorów miejsc
Wynik funkcji PLACES_COUNT_PER_H3 zwraca też tablicę sample_place_ids, która zawiera maksymalnie 250 identyfikatorów miejsc w każdym elemencie odpowiedzi. Te identyfikatory są powiązane ze statystykami zbiorczymi i poszczególnymi miejscami, które się do nich przyczyniają.
System może najpierw zidentyfikować najbardziej trafne komórki z pierwszego zapytania.
Możesz na przykład wybrać 20 komórek o najwyższych wartościach. Następnie z tych hotspotów skonsoliduj sample_place_ids w jedną listę.
Ta lista zawiera wyselekcjonowane przykłady najciekawszych miejsc z najbardziej istotnych obszarów, które przygotują Cię do ukierunkowanej weryfikacji.
Jeśli przetwarzasz wyniki BigQuery w Pythonie za pomocą pandas DataFrame, logika wyodrębniania tych identyfikatorów jest prosta:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
Podobną logikę można zastosować w przypadku innych języków programowania.
Pobieranie szczegółów rzeczywistych za pomocą interfejsu Places API
Po utworzeniu skonsolidowanej listy identyfikatorów miejsc możesz przejść od analizy na dużą skalę do pobierania konkretnych danych. Użyjesz tych identyfikatorów do wysyłania zapytań do interfejsu Place Details API w celu uzyskania szczegółowych informacji o każdej przykładowej lokalizacji.
To jest kluczowy etap weryfikacji. Usługa Statystyki miejsc informowała o liczbie restauracji w danym obszarze, a interfejs Places API podaje które to restauracje, udostępniając ich nazwę, dokładny adres, szerokość i długość geograficzną, ocenę użytkowników, a nawet bezpośredni link do ich lokalizacji w Mapach Google. Wzbogaca to dane próbne, przekształcając abstrakcyjne identyfikatory w konkretne, weryfikowalne miejsca.
Pełną listę danych dostępnych w interfejsie Place Details API oraz kosztów związanych z ich pobieraniem znajdziesz w dokumentacji interfejsu API.
Żądanie do interfejsu Places API dotyczące konkretnego identyfikatora przy użyciu biblioteki klienta Python wyglądałoby tak: Więcej informacji znajdziesz w przykładach biblioteki klienta interfejsu Places API (nowego).
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
Pamiętaj, że pola w tym żądaniu pobierają dane z 2 różnych kodów SKU rozliczeń.
formattedAddressilocationsą częścią SKU Informacje o miejscu Essentials.displayNameigoogleMapsUrisą częścią SKU Informacje o miejscu Pro.
Jeśli jedno żądanie informacji o miejscu zawiera pola z wielu kodów SKU, całe żądanie jest rozliczane według stawki kodu SKU najwyższego poziomu. Dlatego to konkretne wywołanie zostanie rozliczone jako żądanie informacji o miejscu w wersji Pro.
Aby kontrolować koszty, zawsze używaj parametru FieldMask, aby żądać tylko pól wymaganych przez aplikację.
Tworzenie połączonej wizualizacji na potrzeby weryfikacji
Ostatni krok to połączenie obu zbiorów danych w jednym widoku. Dzięki temu możesz szybko i intuicyjnie sprawdzić wstępną analizę. Wizualizacja powinna mieć 2 warstwy:
- Warstwa podstawowa: mapa tematyczna lub mapa cieplna wygenerowana na podstawie wstępnych wyników
PLACES_COUNT_PER_H3, pokazująca ogólną gęstość miejsc w Twojej lokalizacji. - Najwyższa warstwa: zestaw pojedynczych znaczników dla każdego przykładowego punktu POI, wykreślonych na podstawie dokładnych współrzędnych pobranych z interfejsu Places API w poprzednim kroku.
Logika tworzenia tego widoku łączonego jest wyrażona w tym przykładzie pseudokodu:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
Nakładając konkretne markery rzeczywiste na mapę gęstości ogólnej, możesz od razu potwierdzić, że obszary zidentyfikowane jako hotspoty rzeczywiście zawierają dużą koncentrację analizowanych miejsc. Wizualne potwierdzenie zwiększa zaufanie do wniosków opartych na danych.
Podsumowanie
Ten wzorzec architektury zapewnia niezawodną i wydajną metodę weryfikacji wniosków geoprzestrzennych na dużą skalę. Korzystając ze Statystyk miejsc do przeprowadzania szerokiej, skalowalnej analizy oraz z interfejsu Place Details API do ukierunkowanej weryfikacji danych podstawowych, możesz stworzyć wydajną pętlę informacji zwrotnych. Dzięki temu Twoje decyzje strategiczne, niezależnie od tego, czy dotyczą wyboru lokalizacji sklepu, czy planowania logistyki, będą oparte na danych, które są nie tylko istotne statystycznie, ale też weryfikowalnie dokładne.
Dalsze kroki
- Poznaj inne funkcje zliczania miejsc, aby dowiedzieć się, jak mogą one odpowiadać na różne pytania analityczne.
- Więcej informacji o innych polach, o które możesz poprosić, aby wzbogacić analizę, znajdziesz w dokumentacji interfejsu Places API.
Współtwórcy
Henrik Valve | Inżynier DevX