
Page Summary
-
This guide provides various design patterns for performing high volume address validation using Google Cloud Platform, integrating with existing processes and pipelines.
-
You can leverage Cloud Run, Compute Engine, or Google Kubernetes Engine for one-time address validation tasks, uploading data to Cloud Storage for processing.
-
For recurring data pipelines, use Cloud Storage, Dataflow, and BigQuery to efficiently process and validate large address datasets regularly.
-
To implement a long-lasting recurring address validation process, use Memorystore for persistent storage, Cloud Scheduler for periodic triggers, and BigQuery for caching results.
-
This approach allows for periodic revalidation of existing addresses and validation of new ones, offering higher resiliency and the ability to process large datasets.
Objective
The High Volume Address Validation tutorial guided you through different scenarios where high volume address validation can be used. In this tutorial, we will introduce you to different design patterns within Google Cloud Platform for running High Volume Address Validation.
We will start with an overview on running High Volume Address Validation in Google Cloud Platform with Cloud Run, Compute Engine or Google Kubernetes Engine for one time executions. We will then see how this capability can be included as part of a data pipeline.
By the end of this article you should have a good understanding of the different options for running Address Validation in high volume in your Google Cloud environment.
Reference architecture on Google Cloud Platform
This section dives deeper into different design patterns for High Volume Address Validation using Google Cloud Platform. By running on Google Cloud Platform, you can integrate with your existing processes and data pipelines.
Running High Volume Address Validation one time on Google Cloud Platform
Shown below is a reference architecture of how to build an integration on Google Cloud Platform which is more suitable for one off operations or testing.

In this case, we recommend uploading the CSV file to a Cloud Storage bucket. The High Volume Address Validation script can then be run from a Cloud Run environment. However you can execute it any other runtime environment like Compute Engine or Google Kubernetes Engine. The output CSV can also be uploaded to the Cloud Storage bucket.
Running as a Google Cloud Platform data pipeline
The deployment pattern shown in the previous section is great for quickly testing High Volume Address Validation for one time usage. However if you need to use it regularly as part of a data pipeline, then you can better leverage Google Cloud Platform native capabilities to make it more robust. Some of the changes which you can make include:
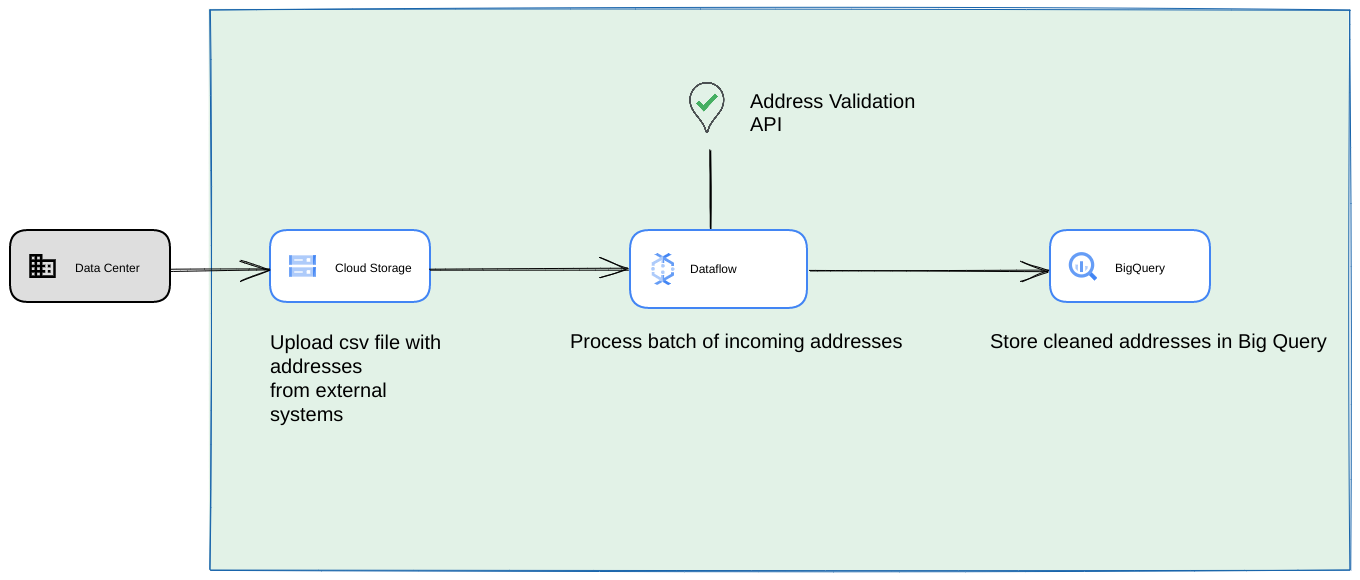
- In this case, you can dump CSV files in Cloud Storage buckets.
- A Dataflow job can pick up the addresses to be processed and then cache in BigQuery.
- The Dataflow Python library can be be extended to have logic for High Volume Address Validation to validate the addresses from the Dataflow job.
Running the script from a data pipeline as a long lasting recurring process
Another common approach is to validate a batch of addresses as part of a streaming data pipeline as a recurring process. You may also have the addresses in a bigquery datastore. In this approach we will see how to build out a recurring data pipeline (which needs to be triggered daily/weekly/monthly)
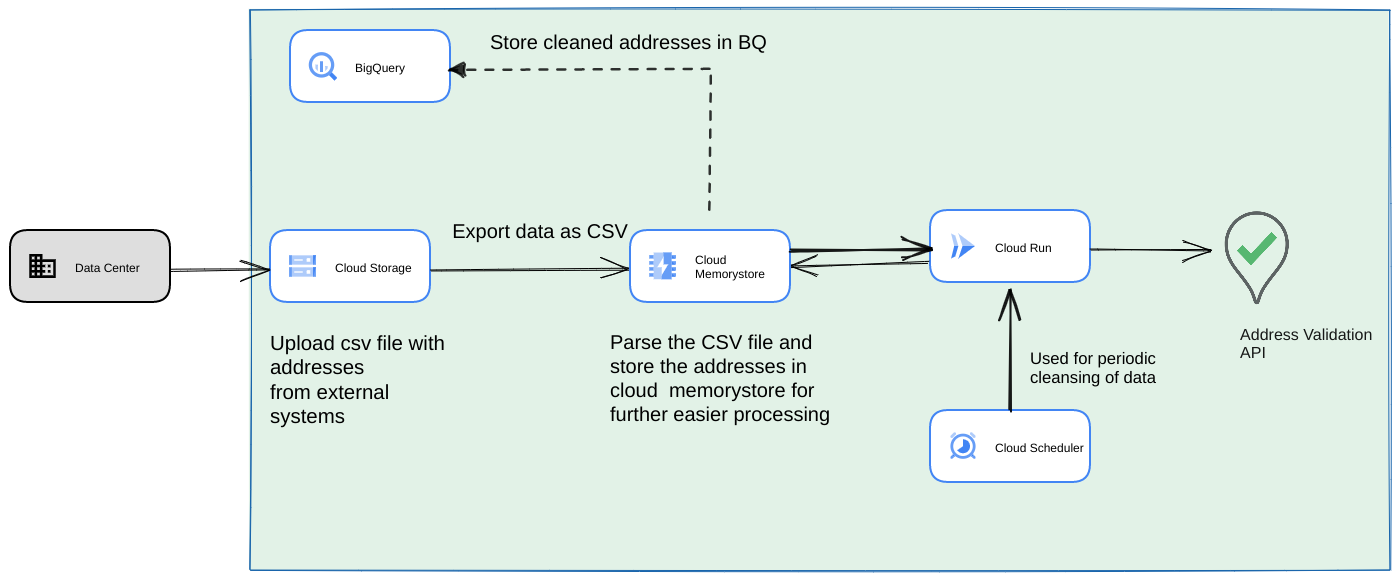
- Upload the initial CSV file to a Cloud Storage bucket.
- Use Memorystore as a persistent datastore to maintain intermediate state for the long running process.
- Cache the final addresses in a BigQuery datastore.
- Set up Cloud Scheduler to run the script periodically.
This architecture has the following advantages:
- Using Cloud Scheduler, address validation can be done periodically. You might want to revalidate the addresses on a monthly basis or validate any new addresses on a monthly/quarterly basis. This architecture helps solve that use case.
If customer data is in BigQuery, then the validated addresses or the validation Flags can be cached directly there. Note: What can be cached and how is described in details in the High Volume Address Validation article
Using Memorystore provides higher resiliency and ability to process more addresses. This steps adds a statefulness to the whole processing pipeline which is needed for handling very large address datasets. Other database technologies like cloud SQL[https://cloud.google.com/sql] or any other flavour of database which Google cloud Platform offers can be used here as well. However we believe memorystore perfectless balances the scaling and simplicity needs, thus should be the first choice.
Conclusion
By applying the patterns described here, you can use Address Validation API for different use cases and from different use cases on Google Cloud Platform.
We have written an open-source Python library to help you get started with the use cases described above. It can be invoked from a command line on your computer or it can be invoked from Google Cloud Platform or other cloud providers.
Learn more about how to use the library from this article.
Next Steps
Download the Improve checkout, delivery, and operations with reliable addresses Whitepaper and view the Improving checkout, delivery, and operations with Address Validation Webinar.
Suggested further reading:
- Address Validation API Documentation
- Geocoding and Address Validation
- Explore the Address Validation demo
Contributors
Google maintains this article. The following contributors originally wrote it.
Principal authors:
Henrik Valve | Solutions Engineer
Thomas Anglaret | Solutions Engineer
Sarthak Ganguly | Solutions Engineer