
ML Kit Pose Detection API 是多功能的輕量化解決方案,可讓應用程式開發人員透過連續影片或靜態圖片,即時偵測主體的身體姿勢。姿勢圖用一組骨架地標點,描述身體在某個時刻的位置。這些地標對應至不同的身體部位,例如肩膀和臀部。地標的相對位置可用來區分其中一種姿勢。
ML Kit 姿勢偵測功能可產生全身的 33 點骨骼相符程度,包括臉部地標 (耳朵、眼睛、嘴巴和鼻子) 以及雙手和腳上的位置。下方圖 1 顯示透過使用者相機觀看的地標,這是鏡像圖片。使用者的右側會顯示於圖片左側:
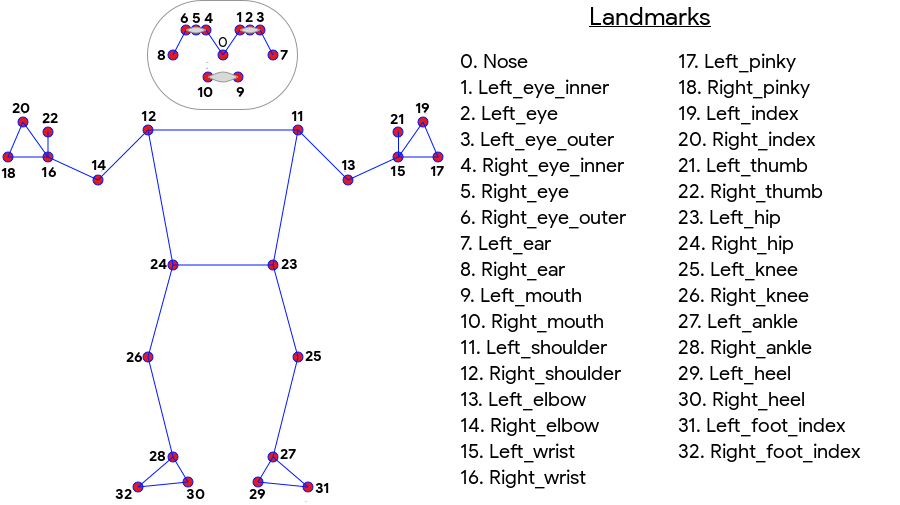
使用 ML Kit 姿勢偵測不需要特殊設備或機器學習專業知識,即可產生絕佳結果。有了這項技術開發人員,只要編寫幾行程式碼,就能為使用者打造獨一無二的體驗。
必須出現使用者的臉孔才能偵測姿勢。當主體的整個身體在影格內時,姿勢偵測效果最佳,但同時也會偵測到部分身體姿勢。在這種情況下,如果無法辨識的地標,就會是在圖片外指定的座標。
主要功能
- 跨平台支援:在 Android 和 iOS 上都能享有相同的體驗。
- 完整身體追蹤:模型會傳回 33 個主要骨架的地標點,包括雙手和腳下的位置。
- InFrameLikelihood 分數:針對每個地標,指出地標位於圖片頁框中的可能性。分數的範圍介於 0.0 至 1.0 之間,1.0 表示可信度高。
- 兩個最佳化的 SDK:基本 SDK 在 Pixel 4 和 iPhone X 等新型手機上即時執行。這個方法會以約 30 至 45 fps 的速率傳回結果。不過,地標座標的精確度可能會有所不同。準確的 SDK 會以較慢的影格速率傳回結果,但會產生更準確的座標值。
- 用於深入分析的 Z 座標:這個值有助於判定使用者的身體部位是否位於使用者臀部的前方或後方。詳情請參閱下方的「Z 座標」一節。
Pose Detection API 與 Facial Recognition API 類似,前者會傳回一組地標及其位置。不過,雖然臉部偵測也會嘗試辨識各種特徵,例如笑著或張開眼睛,但姿勢偵測功能不會對姿勢或姿勢本身的地標附加任何意義。您可以建立專屬演算法來解讀姿勢如需相關範例,請參閱排名分類提示。
姿勢偵測功能只能偵測影像中的一個人。如果圖片中有兩個人,模型會將地標指派給可信度最高的人物。
Z 座標
Z 座標是針對每個地標計算的實驗性值。以「圖片像素」表示 (例如 X 和 Y 座標),但不是真正的 3D 值。Z 軸與相機垂直,會在拍攝主體的臀部之間傳遞。Z 軸的起點大約是臀部的中心點 (相對於攝影機的左側/右側和前置/背面)。負 Z 值朝向相機;正值以外的值。 Z 座標沒有上限或下限。
範例結果
下表顯示右圖中幾個地標的座標和 InFrameLikelihood 的座標。請注意,使用者左手的 Z 座標為負值,因為它們位於主體的臀部前方並朝向相機。

| 地標 | 類型 | 位置 | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671、550.7924、-118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032、583.2485、-321.15836) | $0.9999894 美元 |
| 13 | LEFT_ELBOW | (903.83704、754.676、-219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152、842.5973、-179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956、654.9725、-820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956、1015.70435、-683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635、609.6432、-956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755、1065.838、-776.5006) | 0.9785348 |
深入解析
如要進一步瞭解這個 API 的基礎機器學習模型實作詳細資料,請參閱 Google AI 網誌文章。
如要進一步瞭解我們的機器學習公平性做法和模型的訓練方式,請參閱模型資訊卡