
ML Kit Pose Detection API הוא פתרון גמיש ורב-תכליתי שמאפשר למפתחי אפליקציות לזהות את תנוחת הגוף בזמן אמת מתוך סרטון רציף או תמונה סטטית. תנוחה מתארת את תנוחת הגוף בנקודה אחת בזמן בעזרת קבוצה של נקודות ציון דרך. ציוני הדרך תואמים לחלקי גוף שונים, כמו הכתפיים והירכיים. ניתן להשתמש במיקומים היחסיים של ציוני הדרך כדי להבחין בין תנוחה אחת לאחרת.
התכונה ML Kit Pose Detection יוצרת התאמת שלד של 33 נקודות על כל הגוף, שכוללת ציוני פנים (אוזניים, עיניים, פה ואף אף) ונקודות על הידיים והרגליים. באיור 1 שבהמשך מוצגים ציוני הדרך שמביטים במצלמה של המשתמש, כך שזו תמונת מראה. הצד הימני של המשתמש מופיע משמאל לתמונה:
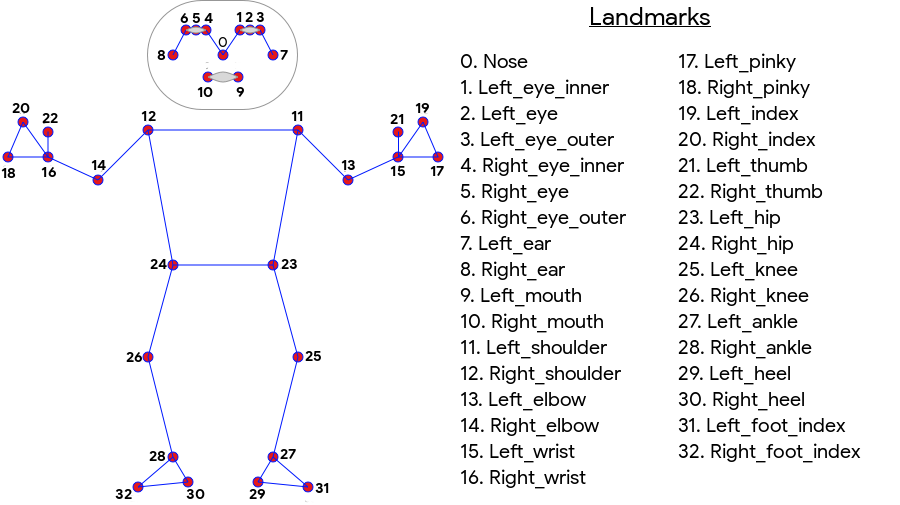
לא צריך להשתמש בציוד מיוחד או במומחיות בלמידת מכונה כדי להשיג תוצאות מעולות באמצעות מערכת ML Kit Pose. בעזרת הטכנולוגיה הזו המפתחים יכולים ליצור חוויה ייחודית למשתמשים שלהם, באמצעות כמה שורות קוד בלבד.
יש להציג את הפנים של המשתמש כדי לזהות תנוחה. זיהוי התנוחה פועל בצורה הטובה ביותר כשכל גופו של האדם גלוי במסגרת, אבל מתבצע גם זיהוי של תנוחת גוף חלקית. במקרה כזה, לציוני הדרך שאינם מזוהים מוקצות קואורדינטות מחוץ לתמונה.
יכולות עיקריות
- תמיכה בפלטפורמות שונות נהנים מאותה חוויית שימוש ב-Android וגם ב-iOS.
- מעקב מלא אחרי הגוף: המודל מחזיר 33 נקודות ציון חשובות בצורת שלד, כולל המיקום של הידיים והרגליים.
- ציון InFramelikelihood לכל ציון דרך, מדד שמראה את הסבירות שציון הדרך נמצא במסגרת התמונה. הציון נע בין 0.0 ל-1.0, כאשר 1.0 מציין רמת מהימנות גבוהה.
- שתי ערכות SDK שעברו אופטימיזציה: ה-SDK הבסיסי פועל בזמן אמת בטלפונים מודרניים כמו Pixel 4 ו-iPhone X. הוא מחזיר תוצאות בקצב של כ-30 פריימים לשנייה, או כ-45 פריימים לשנייה, בהתאמה. עם זאת, הדיוק של הקואורדינטות של ציון הדרך עשוי להשתנות. ה-SDK המדויק מחזיר תוצאות בקצב פריימים איטי יותר, אבל מפיק ערכי קואורדינטות מדויקים יותר.
- Z קואורדינטות לניתוח עומק הערך הזה יכול לעזור לקבוע אם חלקים מגוף המשתמשים נמצאים לפני או מאחורי הירכיים של המשתמשים. למידע נוסף, עיינו בקטע Z coordinate בהמשך.
ה-Pose Detection API דומה ל-Faceial Recognition API בכך שהוא מחזיר קבוצה של ציוני דרך ואת המיקום שלהם. עם זאת, בעזרת התכונה 'זיהוי פנים' אנחנו גם מנסים לזהות תכונות כמו פה מחייך או עיניים פקוחות, אבל התכונה 'זיהוי תנוחה' לא משייכת משמעות כלשהי לנקודות הציון בתנוחה או בתנוחה עצמה. תוכלו ליצור אלגוריתמים משלכם כדי לפרש תנוחה. תוכלו להיעזר בטיפים לסיווג תוכן כדי לראות כמה דוגמאות.
בכל תמונה אפשר לזהות רק אדם אחד באמצעות התכונה 'זיהוי פוזי'. אם מופיעים שני אנשים, המודל יקצה ציוני דרך לאדם שזוהה עם רמת המהימנות הגבוהה ביותר.
קואורדינטת Z
קואורדינטת Z היא ערך ניסיוני שמחושב לכל ציון דרך. הוא נמדד ב'פיקסלים של תמונה' כמו קואורדינטות ה-X וה-Y, אבל הוא לא ערך אמיתי. ציר ה-Z מאונך למצלמה ועובר בין המותניים של המושא. המקור של ציר ה-Z הוא בערך נקודת המרכז בין הירכיים (שמאל/ימין וקדמי/אחורי ביחס למצלמה). ערכי Z שליליים מופנים למצלמה, אבל הערכים החיוביים לא רחוקים ממנה. לקואורדינטת ה-Z אין גבול עליון או תחתון.
תוצאות לדוגמה
בטבלה הבאה מוצגות הקואורדינטות וה-InFramelikelihood של כמה ציוני דרך במיקום מימין. שימו לב שקואורדינטות ה-Z של יד שמאל של המשתמש הן שליליות, כי הן נמצאות מול מרכז הירכיים של המושא ומול המצלמה.

| ציון דרך | תיאור | מיקום | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704, 754.676, -219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956, 654.9725, -820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635, 609.6432, -956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006) | 0.9785348 |
אפשרויות מתקדמות
בפוסט בבלוג של Google AI תוכלו לקרוא פרטים נוספים על ההטמעה של המודלים הבסיסיים של למידת מכונה (ML) ב-API הזה.
מידע נוסף על הנהלים שלנו בנושא הוגנות בלמידת מכונה ועל אופן האימון של המודלים, מופיע בכרטיס המודל.