
Cel
Samouczek dotyczący weryfikacji adresów na dużą skalę przedstawia różne scenariusze, w których można użyć weryfikacji adresów na dużą skalę. W tym samouczku przedstawimy różne wzorce projektowe w Google Cloud Platform do przeprowadzania weryfikacji adresów na dużą skalę.
Zaczniemy od omówienia przeprowadzania weryfikacji adresów na dużą skalę w Google Cloud Platform za pomocą Cloud Run, Compute Engine lub Google Kubernetes Engine w przypadku jednorazowych wykonań. Następnie zobaczymy, jak można uwzględnić tę funkcję w potoku danych.
Po przeczytaniu tego artykułu powinnaś(-eś) dobrze rozumieć różne opcje przeprowadzania weryfikacji adresów na dużą skalę w środowisku Google Cloud.
Architektura referencyjna w Google Cloud Platform
W tej sekcji szczegółowo omówimy różne wzorce projektowe weryfikacji adresów na dużą skalę za pomocą Google Cloud Platform. Dzięki uruchamianiu w Google Cloud Platform możesz zintegrować się z istniejącymi procesami i potokami danych.
Jednorazowe uruchamianie weryfikacji adresów na dużą skalę w Google Cloud Platform
Poniżej przedstawiamy architekturę referencyjną dotyczącą tworzenia integracji w Google Cloud Platform, która lepiej nadaje się do jednorazowych operacji lub testowania.

W tym przypadku zalecamy przesłanie pliku CSV do zasobnika Cloud Storage. Skrypt weryfikacji adresów na dużą skalę można następnie uruchomić w środowisku Cloud Run. Możesz go jednak uruchomić w dowolnym innym środowisku wykonawczym, takim jak Compute Engine czy Google Kubernetes Engine. Wyjściowy plik CSV można też przesłać do zasobnika Cloud Storage.
Uruchamianie jako potok danych Google Cloud Platform
Wzorzec wdrożenia opisany w poprzedniej sekcji doskonale nadaje się do szybkiego testowania weryfikacji adresów na dużą skalę w przypadku jednorazowego użycia. Jeśli jednak musisz regularnie używać go w ramach potoku danych, możesz lepiej wykorzystać natywne funkcje Google Cloud Platform, aby zwiększyć jego niezawodność. Oto niektóre zmiany, które możesz wprowadzić:
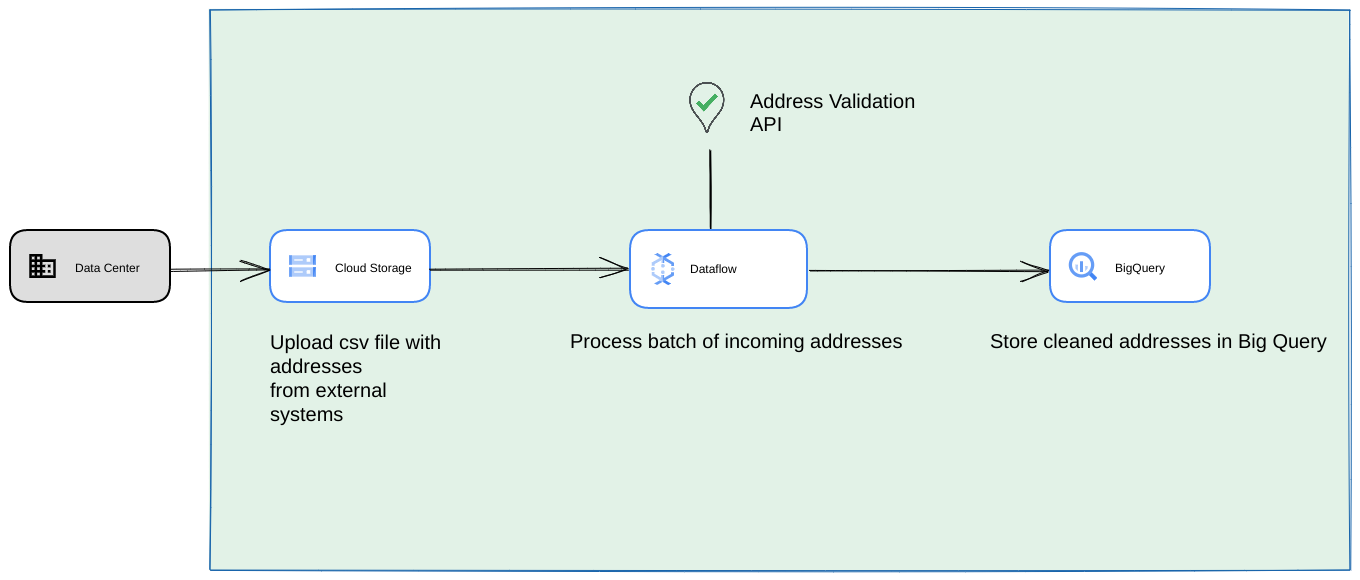
- W tym przypadku możesz zrzucać pliki CSV do zasobników Cloud Storage.
- Zadanie Dataflow może pobierać adresy do przetworzenia, a następnie zapisywać je w pamięci podręcznej w BigQuery.
- Bibliotekę Dataflow Python można rozszerzyć, aby zawierała logikę weryfikacji adresów na dużą skalę, która będzie weryfikować adresy z zadania Dataflow.
Uruchamianie skryptu z potoku danych jako długotrwałego procesu cyklicznego
Innym powszechnym podejściem jest weryfikowanie partii adresów w ramach potoku danych przesyłanych strumieniowo jako procesu cyklicznego. Adresy mogą też znajdować się w magazynie danych BigQuery. W tym podejściu zobaczymy, jak utworzyć cykliczny potok danych (który trzeba uruchamiać codziennie, co tydzień lub co miesiąc).
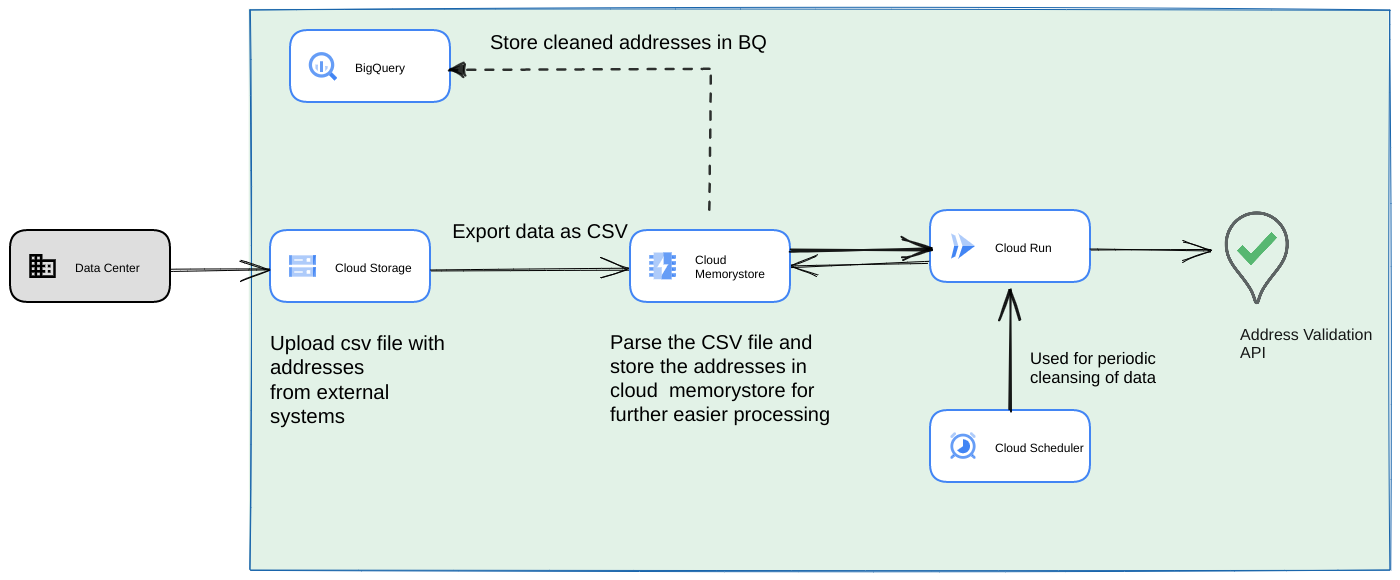
- Prześlij początkowy plik CSV do zasobnika Cloud Storage.
- Użyj Memorystore jako trwałego magazynu danych, aby zachować stan pośredni w przypadku długotrwałego procesu.
- Zapisz w pamięci podręcznej adresy końcowe w magazynie danych BigQuery.
- Skonfiguruj Cloud Scheduler, aby okresowo uruchamiać skrypt.
Ta architektura ma te zalety:
- Dzięki Cloud Scheduler weryfikację adresów można przeprowadzać okresowo. Możesz chcieć ponownie zweryfikować adresy co miesiąc lub zweryfikować nowe adresy co miesiąc lub co kwartał. Ta architektura pomaga rozwiązać ten problem.
Jeśli dane klientów znajdują się w BigQuery, zweryfikowane adresy lub flagi weryfikacji można zapisać bezpośrednio w pamięci podręcznej. Uwaga: co można zapisać w pamięci podręcznej i jak to zrobić, opisujemy szczegółowo w artykule Weryfikacja adresów na dużą skalę.
Korzystanie z Memorystore zapewnia większą odporność i możliwość przetwarzania większej liczby adresów. Ten krok dodaje stanowość do całego potoku przetwarzania, co jest potrzebne do obsługi bardzo dużych zbiorów danych adresowych. Można też używać innych technologii baz danych, takich jak Cloud SQL[https://cloud.google.com/sql] lub dowolna inna baza danych oferowana przez Google Cloud Platform. Uważamy jednak, że Memorystore doskonale równoważy potrzeby skalowania i prostoty, dlatego powinna być pierwszym wyborem.
Podsumowanie
Stosując opisane tu wzorce, możesz używać Address Validation API w różnych przypadkach i w różnych przypadkach użycia w Google Cloud Platform.
Aby ułatwić Ci rozpoczęcie pracy z opisanymi powyżej przypadkami użycia, napisaliśmy bibliotekę Python o otwartym kodzie źródłowym. Można ją wywołać z wiersza poleceń na komputerze lub z Google Cloud Platform albo innych dostawców usług w chmurze.
Więcej informacji o korzystaniu z biblioteki znajdziesz w tym artykule.
Następne kroki
Pobierz dokument „Improve checkout, delivery, and operations with reliable addresses” (Usprawnianie procesu płatności, dostawy i operacji dzięki wiarygodnym adresom) i obejrzyj webinar „Improving checkout, delivery, and operations with Address Validation” (Usprawnianie procesu płatności, dostawy i operacji dzięki weryfikacji adresów) .
Sugerowane dalsze lektury:
- Dokumentacja Address Validation API
- Geokodowanie i weryfikacja adresów
- Zapoznaj się z wersją demonstracyjną weryfikacji adresów
Współtwórcy
Ten artykuł jest utrzymywany przez Google. Pierwotnie napisali go ci współtwórcy:
Główni autorzy:
Henrik Valve | Inżynier ds. rozwiązań
Thomas Anglaret | Inżynier ds. rozwiązań
Sarthak Ganguly | Inżynier ds. rozwiązań