
PLACES_COUNT_V2 फ़ंक्शन, BigQuery की एक टेबल दिखाता है. इसमें, तय किए गए फ़िल्टर के आधार पर, एक से ज़्यादा इनपुट वाले भौगोलिक इलाकों के लिए, जगहों की संख्या और Place ID के सैंपल शामिल होते हैं.
इस फ़ंक्शन को बैच प्रोसेसिंग के लिए डिज़ाइन किया गया है. यह भौगोलिक इलाकों के इनपुट
टेबल
पैरामीटर
को स्वीकार करता है. इससे, इनपुट टेबल के ज़रिए भौगोलिक इलाके की जानकारी देकर, एक ही क्वेरी में दिलचस्पी के कई इलाकों का विश्लेषण किया जा सकता है.
सिंटैक्स
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_V2`( TABLE input_geographies, filters )
पैरामीटर
PROJECT_NAME: आपके Google Cloud प्रोजेक्ट का नाम.LINKED_DATASET_NAME: BigQuery डेटासेट का नाम.इसमें, Places Insights के फ़ंक्शन शामिल होते हैं. जैसे,places_insights___us.input_geographies: BigQuery की एक टेबल. इसमें, विश्लेषण किए जाने वाले भौगोलिक इलाके शामिल होते हैं. इस टेबल में, ये कॉलम ज़रूर शामिल होने चाहिए:filters(JSON): JSON ऑब्जेक्ट. इसमें, जगहों को फ़िल्टर करने के लिए, कुंजी-वैल्यू पेयर शामिल होते हैं. फ़िल्टर के पैरामीटर देखें.
आउटपुट टेबल का स्कीमा
PLACES_COUNT_V2 फ़ंक्शन, इन कॉलम वाली टेबल दिखाता है:
| कॉलम का नाम | डेटा टाइप | ब्यौरा |
|---|---|---|
geo_id |
STRING | इनपुट वाले भौगोलिक इलाके के लिए यूनीक आइडेंटिफ़ायर. यह input_geographies टेबल से लिया जाता है. |
input_geography |
GEOGRAPHY | input_geographies टेबल से लिया गया ओरिजनल GEOGRAPHY ऑब्जेक्ट. |
place_count |
INTEGER | फ़िल्टर से मेल खाने वाली जगहों की कुल संख्या. |
sample_place_ids |
ARRAY<STRING> | प्लेस आईडी का एक कलेक्शन. इसमें, ज़्यादा से ज़्यादा 250 प्लेस आईडी शामिल हो सकते हैं. ये आईडी, तय किए गए मानदंड से मेल खाते हैं. |
यह कैसे काम करता है
यह फ़ंक्शन, input_geographies टेबल की हर लाइन को प्रोसेस करता है. हर geo
ऑब्जेक्ट के लिए, यह उन जगहों की संख्या की गिनती करता है जो भौगोलिक इलाके में मौजूद हैं. अगर geo एक पॉइंट है और filters में रेडियस तय किया गया है, तो यह geography_radius में मौजूद जगहों की संख्या की गिनती करता है. गिनती में सिर्फ़ वे जगहें शामिल होती हैं जो filters JSON ऑब्जेक्ट में तय की गई सभी शर्तों को पूरा करती हैं.
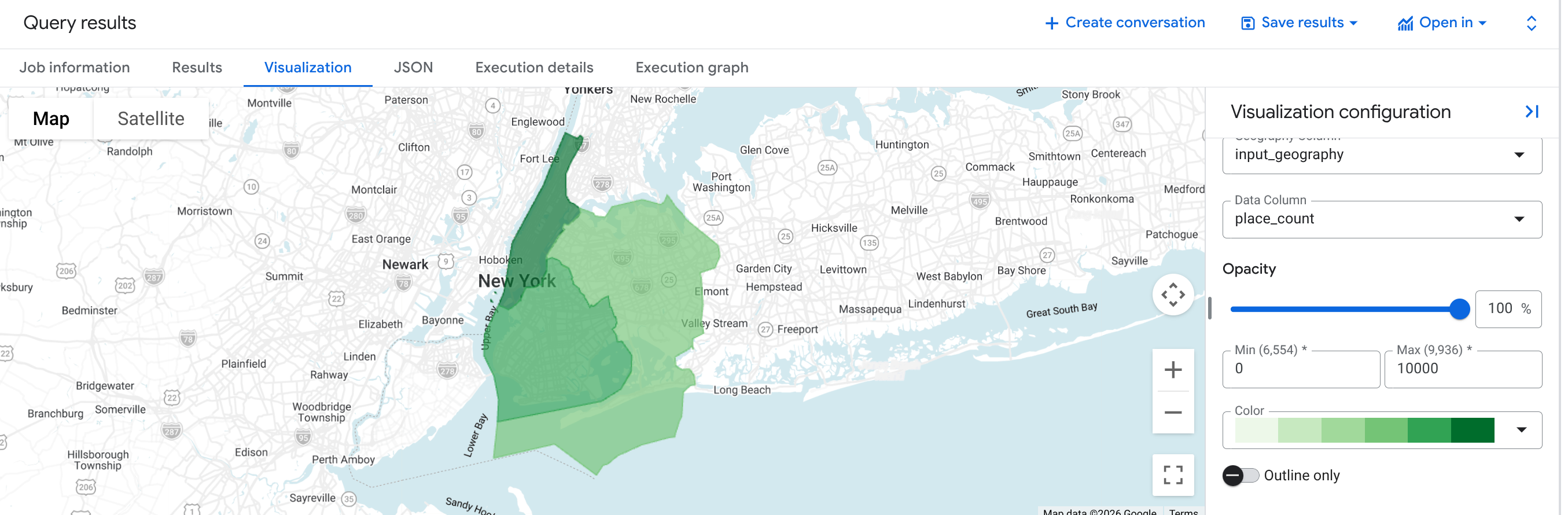
उदाहरण: न्यूयॉर्क सिटी के तीन काउंटी में मौजूद रेस्टोरेंट की संख्या का पता लगाना
इस उदाहरण में, न्यूयॉर्क सिटी के तीन काउंटी में चालू रेस्टोरेंट की संख्या वाली एक टेबल जनरेट की गई है.
इस उदाहरण में, अमेरिका के जनगणना ब्यूरो
डेटा
BigQuery सार्वजनिक डेटासेट का इस्तेमाल किया गया है. इससे न्यूयॉर्क सिटी के तीन काउंटी की सीमाएं मिलती हैं: "क्वींस", "किंग्स" और "न्यू
यॉर्क". हर काउंटी की सीमाएं, county_geom कॉलम में शामिल होती हैं.
सबसे पहले, हम एक अस्थायी टेबल new_york_counties बनाते हैं. इसमें, हर काउंटी के लिए geo_id और आसान बनाया गया GEOGRAPHY शामिल होता है.
SELECT * FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), JSON_OBJECT( 'types', ["restaurant"], 'business_status', ['OPERATIONAL'] ) );
जवाब वाली टेबल में तीन लाइनें होंगी. हर लाइन में एक काउंटी की जानकारी दिखेगी. इसमें, चालू रेस्टोरेंट के geo_id, input_geography, place_count और sample_place_ids शामिल होंगे.
PLACES_COUNT_V2 का इस्तेमाल करने के फ़ायदे
PLACES_COUNT_V2 PLACES_COUNT और
PLACES_COUNT_PER_GEO के मुकाबले कई अहम फ़ायदे देता है:
- बैच प्रोसेसिंग: टेबल में एक से ज़्यादा भौगोलिक इलाकों के इनपुट देकर, एक ही क्वेरी में हज़ारों कस्टम भौगोलिक इलाकों का विश्लेषण किया जा सकता है.
- परफ़ॉर्मेंस: इसमें, BigQuery के ऑप्टिमाइज़ किए गए जियोस्पेशल जॉइन का इस्तेमाल किया जाता है. इससे बड़े डेटासेट के लिए, क्वेरी की स्पीड बढ़ जाती है.
- स्केलेबिलिटी: इसे, JSON के एक पैरामीटर के साइज़ की सीमाओं के बिना, बड़ी संख्या में इनपुट वाले भौगोलिक इलाकों को हैंडल करने के लिए डिज़ाइन किया गया है.
- शून्य संख्याएं शामिल हैं:
PLACES_COUNT_V2, इनपुट टेबल में दिए गए हरgeo_idके लिए एक लाइन दिखाता है. अगर किसी भौगोलिक इलाके के लिए, तय किए गए मानदंड से मेल खाने वाली कोई जगह नहीं है, तोplace_countकी वैल्यू 0 होगी. इससे आपको हर इनपुट वाले इलाके के लिए नतीजे मिलते हैं. इसलिए, यह देखा जा सकता है कि किन इलाकों में कोई जगह मौजूद नहीं है.