
地点数据分析可提供许多类别的场所的品牌信息。例如:
- 对于“自动取款机、银行和信用合作社”类别,品牌数据包含 PNC、UBS 和 Chase 银行这三个品牌的条目。
- 对于“汽车租赁”类别,数据包含 Budget、Hertz 和 Thrifty 这三个品牌的条目。
查询品牌数据集的典型应用场景是将其与地点数据查询联接,以回答以下问题:
- 某个区域内各品牌所有实体店的总数是多少?
- 我所在区域内排名前三的竞争对手品牌的数量是多少?
- 相应区域内特定类别(例如“健身”或“加油站”)的品牌数量是多少?
品牌数据集简介
美国境内的品牌数据集名为 places_insights___us.brands。
品牌数据集架构
品牌数据集的架构定义了三个字段:
id:品牌 ID。name:品牌名称,例如“Hertz”或“Chase”。category:品牌类型,例如“加油站”“食品和饮料”或“住宿”。如需查看可能值的列表,请参阅类别值。
在查询中使用品牌数据集
地点数据集架构定义了 brand_ids 字段。如果地点数据集中的某个地点与某个品牌相关联,则该地点的 brand_ids 字段包含相应的品牌 ID。
引用品牌数据集的典型查询会根据 brand_ids 字段对地点数据集执行 JOIN。
例如,如需查找纽约市帝国大厦 2, 000 米范围内的麦当劳餐厅数量,请执行以下操作:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) FROM PROJECT_NAME.places_insights___us.places places, UNNEST(brand_ids) AS brand_id LEFT JOIN PROJECT_NAME.places_insights___us.brands ON brand_id = brands.id WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 2000) AND brands.name = "McDonald's" AND business_status = "OPERATIONAL"
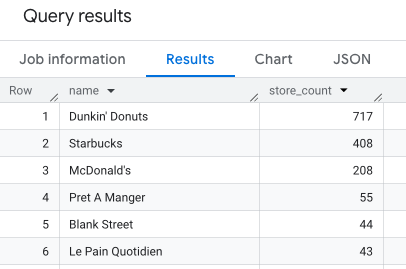
以下查询会返回纽约市属于某个品牌的所有银行的数量,并按品牌名称进行分组:
SELECT WITH AGGREGATION_THRESHOLD brands.name, COUNT(*) AS store_count FROM PROJECT_NAME.places_insights___us.places places, UNNEST(brand_ids) AS brand_id LEFT JOIN PROJECT_NAME.places_insights___us.brands ON brand_id = brands.id WHERE brands.category = "ATMs, Banks and Credit Unions" AND "bank" IN UNNEST(places.types) AND business_status = "OPERATIONAL" GROUP BY brands.name ORDER BY store_count DESC;
下图显示了按品牌划分的统计信息:
类别值
品牌的 category 字段可以包含以下值:
| 类别类型值 |
|---|
ATMs, Banks and Credit Unions |
Automotive and Parts Dealers |
Automotive Rentals |
Automotive Services |
Dental |
Electric Vehicle Charging Stations |
Electronics Retailers |
Fitness |
Food and Drink |
Gas Station |
Grocery and Liquor |
Health and Personal Care Retailers |
Hospital |
Lodging |
Merchandise Retail |
Movie Theater |
Parking |
Telecommunications |