
Google Cloud Search 스키마는 데이터 색인 생성 및 쿼리를 위한 객체, 속성, 옵션을 정의하는 JSON 구조입니다. 콘텐츠 커넥터는 등록된 스키마를 사용하여 저장소 데이터를 구조화하고 색인을 생성합니다.
JSON 스키마 객체를 API에 제공하여 스키마를 만듭니다. 데이터를 색인 생성하기 전에 각 저장소의 스키마를 등록해야 합니다.
이 문서에서는 스키마 생성의 기본사항을 다룹니다. 검색 환경을 최적화하려면 검색 품질 개선을 참고하세요.
스키마 만들기
Cloud Search 스키마를 만들려면 다음 단계를 따르세요.
예상되는 사용자 동작 식별
사용자가 검색하는 방식을 예상하면 스키마 전략을 정의하는 데 도움이 됩니다. 영화 데이터베이스의 경우 사용자가 '로버트 레드포드가 주연으로 출연한 영화'를 검색할 수 있습니다. 스키마는 특정 배우가 출연하는 영화에 대한 쿼리를 지원해야 합니다.
스키마를 사용자 행동에 맞추려면 다음 단계를 따르세요.
- 다양한 사용자의 다양한 쿼리를 평가합니다.
- '영화'와 같은 논리적 데이터 세트 또는 객체를 식별합니다.
- 제품명 또는 출시일과 같은 속성 (특성)을 식별합니다.
- '인디아나 존스: 레이더스'와 같은 속성의 유효한 값 을 식별합니다.
- 시간순 또는 관객 평점과 같은 정렬 및 순위 요구사항을 결정합니다.
- 자동 완성 추천을 개선하기 위해 직무와 같은 컨텍스트 속성을 식별합니다.
- 이러한 객체, 속성, 예시 값을 나열합니다. 이 목록을 사용하여 연산자 옵션을 정의합니다.
데이터 소스 초기화
데이터 소스 는 Google Cloud에 저장된 색인 생성된 저장소 데이터를 나타냅니다. 타사 데이터 소스 관리를 참고하세요. 사용자가 결과를 클릭하면 Cloud Search는 색인 생성 요청의 URL을 사용하여 사용자에게 항목을 안내합니다.
객체 정의
객체 는 스키마의 기본 단위입니다. '영화' 또는 '사람'과 같은 논리적 구조는 객체입니다. 각 객체에는 제품명, 재생 시간 또는 이름과 같은 속성 이 있습니다.
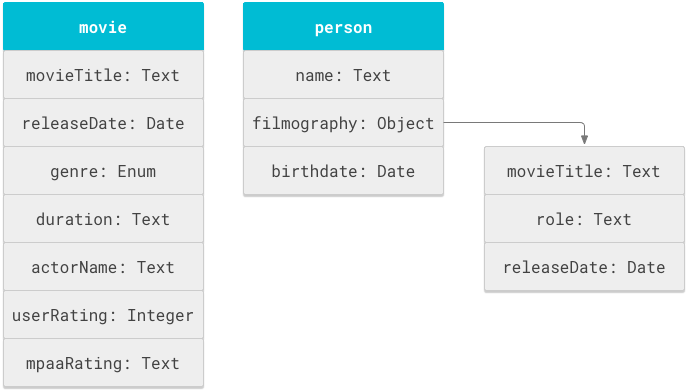
스키마는
객체 정의 목록입니다. objectDefinitions 태그에 있습니다.
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
각 객체에 고유한 이름(예: movie)을 사용합니다. 스키마 서비스는 이러한 이름을 키로 사용합니다.
ObjectDefinition을 참고하세요.
객체 속성 정의
propertyDefinitions 섹션에서 제품명 및 출시일과 같은 속성을 정의합니다.
options
를
freshnessOptions
(순위) 및
displayOptions
(UI 라벨)에 사용합니다.
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
name문자열- 유형에 구애받지 않는 옵션 (예:
isReturnable) - 유형 및 유형 관련 옵션 (예:
textPropertyOptions) - 검색 연산자의
operatorOptions - UI 라벨의
displayOptions
여러 객체에서 속성 이름을 재사용할 수 있습니다. 예를 들어 movieTitle
은 movie 객체와 person 객체의 필모그래피에 모두 표시될 수 있습니다.
유형에 구애받지 않는 옵션 추가
PropertyDefinition
에는 유형과 관계없이 속성의 검색 기능을 구성하는 부울 옵션이 포함되어 있습니다. 이러한 옵션은 기본적으로 false로 설정되며 사용하려면 true로 설정해야 합니다.
isReturnable: Query API를 사용하여 검색결과에 속성 데이터를 반환해야 하는 경우true로 설정합니다. 반환이 불가능한 속성은 결과에 표시되지 않고 검색 또는 순위 지정에 사용될 수 있습니다.isRepeatable: 속성에 여러 값이 있을 수 있는 경우true로 설정합니다. 예를 들어 영화의 개봉일은 하나이지만 배우는 여러 명 있을 수 있습니다.isSortable: 속성을 정렬에 사용할 수 있는 경우true로 설정합니다.isRepeatable이true이거나 속성이 반복 가능한 하위 객체 내에 있는 경우true일 수 없습니다.isFacetable: 속성을 패싯 (검색결과를 구체화하는 데 사용되는 속성)을 생성하는 데 사용할 수 있는 경우true로 설정합니다.isReturnable이true여야 합니다.- 열거형, 부울, 텍스트 속성에 대해서만 지원됩니다.
isWildcardSearchable: 사용자가 이 속성에 와일드 카드 검색을 실행하도록 허용하려면true로 설정합니다. 이 옵션은 텍스트 속성에서만 사용할 수 있으며 동작은exactMatchWithOperator설정에 따라 다릅니다.exactMatchWithOperator가true인 경우: 텍스트 값이 단일 토큰으로 처리됩니다.science-*와 같은 쿼리는science-fiction값과 일치합니다.exactMatchWithOperator가false인 경우: 텍스트 값이 토큰화됩니다.sci*또는fi*와 같은 쿼리는science-fiction과 일치하지만science-*는 일치하지 않습니다.
유형 정의
적절한 속성 옵션 객체 (예: textPropertyOptions)를 정의하여 데이터 유형을 설정합니다. 가능한 모든 값을 알고 있는 경우 열거형 (enumPropertyOptions)을 사용합니다. 속성에는 데이터 유형이 하나만 있을 수 있습니다.
연산자 옵션 정의
operatorOptions는 속성이 검색 연산자로 작동하는 방식을 설명합니다.
모든 operatorOptions에는 operatorName (예: title)이 필요합니다. 이는 사용자가 쿼리에 입력하는 매개변수입니다 (예: title:titanic). 직관적인 이름을 사용하고 사용자에게 노출합니다.
동일한 유형의 속성 간에 operatorName을 공유할 수 있습니다. 해당 이름을 사용하는 쿼리는 일치하는 모든 속성에서 결과를 검색합니다.
정렬 가능한 속성에는 비교 쿼리를 위한 lessThanOperatorName 및 greaterThanOperatorName이 포함될 수 있습니다. 텍스트 속성은 exactMatchWithOperator를 사용하여 전체 값을 단일 토큰으로 처리할 수 있습니다.
표시 옵션 추가
선택사항인 displayOptions 섹션에는 displayLabel이 포함되어 있습니다. 이는 검색결과에 표시되는 사용자 친화적인 라벨입니다.
추천 필터링 연산자 추가
suggestionFilteringOperators[]를 사용하여 자동 완성 추천을 필터링하는 속성을 정의합니다 (예: 사용자가 선호하는 장르별로 영화 추천 필터링). 추천 필터는 하나만 정의할 수 있습니다.
스키마 등록
데이터 소스 ID를 사용하여 스키마 서비스에 스키마를 등록합니다. UpdateSchema 요청을 실행합니다.
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
스키마를 등록하지 않고 테스트하려면 validateOnly: true를 사용합니다.
데이터 색인 생성
등록 후 일반적으로 커넥터를 사용하여 색인 호출을 통해 데이터 소스를 채웁니다.
색인 생성 요청 예시:
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
스키마 테스트
프로덕션 전에 작은 저장소로 테스트합니다. 결과를 테스트 사용자로 제한하는 ACL을 만듭니다.
- 일반 검색: 문자열 (예: '타이타닉')을 검색하여 일치하는 모든 항목을 확인합니다.
- 연산자 쿼리: 연산자 (예:
actor:Zane)를 사용하여 결과를 제한합니다.
스키마 미세 조정
사용자 의견을 모니터링하고 스키마를 조정합니다. 새 필드를 색인 생성하거나 연산자 이름을 더 직관적으로 바꿀 수 있습니다.
스키마 변경 후 색인 재생성
다음 변경사항에 대해서는 색인을 재생성할 필요가 없습니다.
- 연산자 이름
- 숫자 제한
- 순위 지정
- 최신 상태 또는 표시 옵션
다음과 같은 경우 색인을 재생성해야 합니다.
- 속성 또는 객체 추가 또는 삭제
isReturnable,isFacetable또는isSortable을true로 변경- 속성
isSuggestable표시
허용되지 않는 속성 변경
색인을 손상시키거나 일관성 없는 결과를 초래하는 변경사항은 허용되지 않습니다. 여기에는 다음이 포함됩니다.
- 속성 데이터 유형 또는 이름
exactMatchWithOperator또는retrievalImportance설정
복잡한 스키마 변경 수행
허용되지 않는 변경사항을 적용하려면 이전 정의에서 새 정의로 속성을 마이그레이션합니다.
- 스키마에 이름이 다른 새 속성을 추가합니다.
- 새 속성과 이전 속성을 모두 사용하여 스키마를 등록합니다.
- 새 속성만 사용하여 색인을 백필합니다.
- 스키마에서 이전 속성을 삭제합니다.
- 새 속성 이름을 사용하도록 쿼리 코드를 업데이트합니다.
Cloud Search는 재사용 문제를 방지하기 위해 삭제된 항목을 30일 동안 기록합니다.
크기 제한사항
- 최대 10개의 최상위 객체
- 최대 깊이 10개 수준
- 객체당 최대 1,000개의 필드 (중첩된 필드 포함)