כדי לגשת לנתוני 'תובנות לגבי מקומות', צריך לכתוב שאילתות SQL ב-BigQuery שמחזירות תובנות מצטברות לגבי מקומות. התוצאות מוחזרות ממערך הנתונים לפי קריטריוני החיפוש שצוינו בשאילתה.
יסודות השאילתה
בתמונה הבאה מוצג הפורמט הבסיסי של שאילתה:

בהמשך מפורט כל חלק בשאילתה.
דרישות השאילתה
ההצהרה SELECT בשאילתה חייבת לכלול את WITH AGGREGATION_THRESHOLD ולציין את מערך הנתונים. לדוגמה:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
בדוגמה הזו, משתמשים ב-FROM כדי לציין את מערך הנתונים places_insights___us.places לארצות הברית.
ציון שם לפרויקט (אופציונלי)
אפשר גם לכלול את שם הפרויקט בשאילתה. אם לא מציינים שם פרויקט, השאילתה תוגדר כברירת מחדל לפרויקט הפעיל.
כדאי לכלול את שם הפרויקט אם קישרתם מערכי נתונים עם אותו שם בפרויקטים שונים, או אם אתם שולחים שאילתה לטבלה מחוץ לפרויקט הפעיל.
לדוגמה, [project name].[dataset name].places.
ציון פונקציית צבירה
בדוגמה שלמטה מוצגות פונקציות הצבירה הנתמכות ב-BigQuery. השאילתה הזו צוברת את הדירוגים של כל המקומות שנמצאים ברדיוס של 1,000 מטרים מבניין האמפייר סטייט בניו יורק, כדי ליצור נתונים סטטיסטיים של דירוגים:
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
ציון הגבלה על מיקום
אם לא מציינים הגבלת מיקום, צבירת הנתונים חלה על כל מערך הנתונים. בדרך כלל מציינים הגבלת מיקום כדי לחפש באזור מסוים, כמו בדוגמה הבאה:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
בדוגמה הזו, השאילתה מציינת הגבלת טירגוט שממוקדת בבניין האמפייר סטייט בניו יורק, ברדיוס של 1,000 מטרים.
אפשר להשתמש במצולע כדי לציין את אזור החיפוש. כשמשתמשים בפוליגון, הנקודות של הפוליגון צריכות להגדיר לולאה סגורה שבה הנקודה הראשונה בפוליגון זהה לנקודה האחרונה:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
בדוגמה הבאה, אזור החיפוש מוגדר באמצעות קו של נקודות מחוברות. הקו דומה למסלול נסיעה שמחושב על ידי Routes API. המסלול יכול להיות לרכב, לאופניים או להולך רגל:
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
בדוגמה הזו, הרדיוס של החיפוש מוגדר ל-100 מטרים מסביב לקו.
סינון לפי שדות של מערך נתונים של מקומות
מצמצמים את החיפוש על סמך השדות שמוגדרים בסכימת מערך הנתונים. סינון התוצאות לפי שדות של מערך נתונים, כמו מקום regular_opening_hours, price_level ולקוח rating.
אפשר להפנות לשדות כלשהם במערך הנתונים שמוגדר על ידי סכימת מערך הנתונים עבור המדינה שמעניינת אתכם. סכימת מערך הנתונים לכל מדינה מורכבת משני חלקים:
- סכימת הליבה שמשותפת למערכי הנתונים של כל המדינות.
- סכימה ספציפית למדינה שמגדירה רכיבי סכימה שספציפיים למדינה הזו.
לדוגמה, השאילתה יכולה לכלול סעיף WHERE שמגדיר קריטריונים לסינון השאילתה. בדוגמה הבאה, מחזירים נתוני צבירה של מקומות מסוג tourist_attraction עם business_status של OPERATIONAL, שערך rating שלהם גדול מ-4.0 או שווה לו, ועם allows_dogs שמוגדר ל-true:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
השאילתה הבאה מחזירה תוצאות של מקומות שיש בהם לפחות שמונה תחנות טעינה לרכב חשמלי:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
סינון לפי סוג ראשי של מקום וסוג מקום
כל מקום במערך הנתונים יכול לכלול:
סוג ראשי יחיד שמשויך אליו מתוך הסוגים שמוגדרים על ידי סוגי מקומות. לדוגמה, הסוג הראשי יכול להיות
mexican_restaurantאוsteak_house. אפשר להשתמש ב-primary_typeבשאילתה כדי לסנן את התוצאות לפי הסוג הראשי של המקום.ערכים מרובים של סוגים שמשויכים אליו מתוך הסוגים שמוגדרים על ידי סוגי מקומות. לדוגמה, יכול להיות שלמסעדה יהיו הסוגים הבאים:
seafood_restaurant, restaurant, food, point_of_interest, establishment. אפשר להשתמש ב-typesבשאילתה כדי לסנן את התוצאות ברשימת הסוגים שמשויכים למקום.
השאילתה הבאה מחזירה תוצאות לכל המקומות עם סוג ראשי של skin_care_clinic שמשמשים גם כspa:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
סינון לפי מזהה מקום
בדוגמה שלמטה מחושב הדירוג הממוצע של 5 מקומות. המקומות מזוהים לפי place_id.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
סינון לפי ערכי נתונים מוגדרים מראש
להרבה שדות של מערכי נתונים יש ערכים מוגדרים מראש. לדוגמה
בשדה
price_levelיש תמיכה בערכים המוגדרים מראש הבאים:PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
בשדה
business_statusיש תמיכה בערכים המוגדרים מראש הבאים:OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLY
בדוגמה הזו, השאילתה מחזירה את מספר חנויות הפרחים עם business_status של OPERATIONAL ברדיוס של 1,000 מטר מבניין האמפייר סטייט בניו יורק:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
סינון לפי שעות פעילות
בדוגמה הזו, השאילתה מחזירה את מספר המקומות באזור גיאוגרפי מסוים שבהם יש מבצעים על משקאות ביום שישי:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
סינון לפי אזור (רכיבי כתובת)
מערך הנתונים של המקומות שלנו מכיל גם קבוצה של רכיבי כתובת שימושיים לסינון תוצאות על סמך גבולות פוליטיים. כל רכיב בכתובת מזוהה באמצעות שם הקוד שלו (10002 למיקוד בניו יורק) או מזהה המקום (ChIJm5NfgIBZwokR6jLqucW0ipg) למיקוד המקביל.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
סינון לפי טעינת רכב חשמלי
בדוגמה הזו מוצג מספר המקומות עם לפחות 8 עמדות טעינה לרכבים חשמליים:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
בדוגמה הזו נספר כמה מקומות כוללים לפחות 10 עמדות טעינה של טסלה שתומכות בטעינה מהירה:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
החזרת קבוצות תוצאות
השאילתות שמוצגות עד עכשיו מחזירות שורה אחת בתוצאה שמכילה את ספירת הצבירה של השאילתה. אפשר גם להשתמש באופרטור GROUP BY כדי להחזיר כמה שורות בתשובה על סמך קריטריוני הקיבוץ.
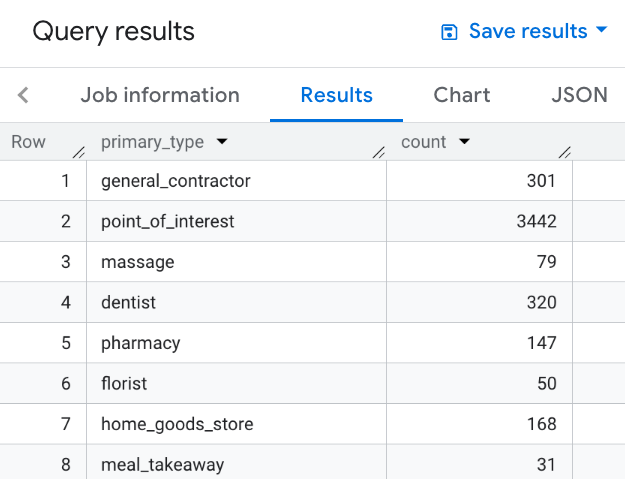
לדוגמה, השאילתה הבאה מחזירה תוצאות שמקובצות לפי הסוג הראשי של כל מקום באזור החיפוש:
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
התמונה הבאה מציגה פלט לדוגמה של השאילתה הזו:
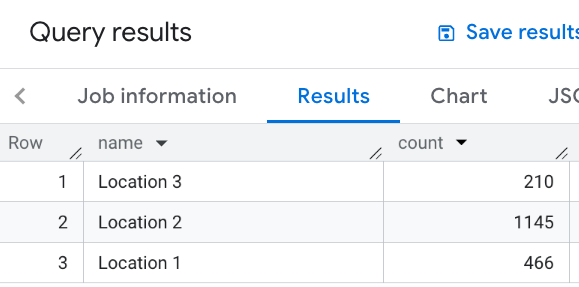
בדוגמה הזו מוגדרת טבלת מיקומים. לגבי כל מיקום, מחשבים את מספר המסעדות הסמוכות, כלומר המסעדות שנמצאות במרחק של עד 1,000 מטרים:
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
התמונה הבאה מציגה פלט לדוגמה של השאילתה הזו: