
Schemat Google Cloud Search to struktura JSON, która określa obiekty, właściwości i opcje używane do indeksowania danych i wysyłania zapytań o nie. Oprogramowanie sprzęgające treści odczytuje dane z repozytorium, a następnie na podstawie zarejestrowanego schematu strukturyzuje i indeksuje dane.
Schemat możesz utworzyć, przekazując do interfejsu API obiekt schematu JSON, a następnie go rejestrując. Aby indeksować dane, musisz zarejestrować obiekt schematu dla każdego repozytorium.
W tym dokumencie znajdziesz podstawowe informacje o tworzeniu schematów. Informacje o tym, jak dostroić schemat, aby poprawić jakość wyszukiwania, znajdziesz w artykule Poprawianie jakości wyszukiwania.
Tworzenie schematu
Oto lista czynności, które należy wykonać, aby utworzyć schemat Cloud Search:
- Określanie oczekiwanych zachowań użytkowników
- Inicjowanie źródła danych
- Tworzenie schematu
- Pełny przykładowy schemat
- Rejestrowanie schematu
- Indeksowanie danych
- Testowanie schematu
- Dostrajanie schematu
Określanie oczekiwanych zachowań użytkowników
Przewidywanie typów zapytań, które mogą zadawać użytkownicy, pomaga ukierunkować strategię tworzenia schematu.
Na przykład podczas wysyłania zapytań do bazy danych filmów możesz przewidywać, że użytkownik zada zapytanie typu „Pokaż wszystkie filmy z Robertem Redfordem”. Dlatego Twój schemat musi obsługiwać wyniki zapytań na podstawie kryterium „wszystkie filmy z określonym aktorem”.
Aby zdefiniować schemat odzwierciedlający wzorce zachowań użytkowników, wykonaj te czynności:
- Oceniaj różnorodne zapytania od różnych użytkowników.
- określać obiekty, które mogą być używane w zapytaniach; Obiekty to logiczne zbiory powiązanych danych, np. film w bazie danych filmów.
- Określ właściwości i wartości, które składają się na obiekt i mogą być używane w zapytaniach. Właściwości to indeksowane atrybuty obiektu. Mogą one zawierać wartości pierwotne lub inne obiekty. Na przykład obiekt filmu może mieć właściwości takie jak tytuł filmu i data premiery jako wartości pierwotne. Obiekt filmu może też zawierać inne obiekty, np. aktorów, którzy mają własne właściwości, takie jak imię i nazwisko czy rola.
- Określ przykładowe prawidłowe wartości właściwości. Wartości to rzeczywiste dane indeksowane dla właściwości. Na przykład tytuł filmu w bazie danych może brzmieć „Poszukiwacze zaginionej arki”.
- Określ opcje sortowania i rankingu, które są przydatne dla użytkowników. Na przykład podczas wyszukiwania filmów użytkownicy mogą chcieć sortować je chronologicznie i według oceny widzów, a nie alfabetycznie według tytułu.
- (opcjonalnie) Zastanów się, czy któraś z Twoich usług nie reprezentuje bardziej konkretnego kontekstu, w którym mogą być wykonywane wyszukiwania, np. stanowiska lub działu użytkowników, aby można było wyświetlać sugestie autouzupełniania na podstawie kontekstu. Na przykład osoby, które przeszukują bazę danych filmów, mogą być zainteresowane tylko określonym gatunkiem. Użytkownicy określają, jakie gatunki mają być uwzględniane w wynikach wyszukiwania, prawdopodobnie w ramach profilu użytkownika. Gdy użytkownik zacznie wpisywać zapytanie dotyczące filmów, w ramach sugestii autouzupełniania będą mu się wyświetlać tylko filmy z jego ulubionego gatunku, np. „filmy akcji”.
- Utwórz listę tych obiektów, właściwości i przykładowych wartości, których można używać w wyszukiwaniach. (Szczegółowe informacje o tym, jak jest używana ta lista, znajdziesz w sekcji Definiowanie opcji operatora).
Inicjowanie źródła danych
Źródło danych reprezentuje dane z repozytorium, które zostały zindeksowane i zapisane w Google Cloud. Instrukcje inicjowania źródła danych znajdziesz w artykule Zarządzanie zewnętrznymi źródłami danych.
Wyniki wyszukiwania użytkownika są zwracane ze źródła danych. Gdy użytkownik kliknie wynik wyszukiwania, Cloud Search przekieruje go do rzeczywistego elementu, używając adresu URL podanego w żądaniu indeksowania.
Określ obiekty
Podstawową jednostką danych w schemacie jest obiekt, zwany też „obiektem schematu”, który jest logiczną strukturą danych. W bazie danych filmów jedną z logicznych struktur danych jest „film”. Innym obiektem może być „osoba”, która reprezentuje obsadę i ekipę filmową.
Każdy obiekt w schemacie ma szereg właściwości lub atrybutów, które opisują obiekt, np. tytuł i czas trwania filmu lub imię i nazwisko oraz datę urodzenia osoby. Właściwości obiektu mogą obejmować wartości pierwotne lub inne obiekty.
Ilustracja 1 przedstawia obiekty film i osoba oraz powiązane z nimi właściwości.
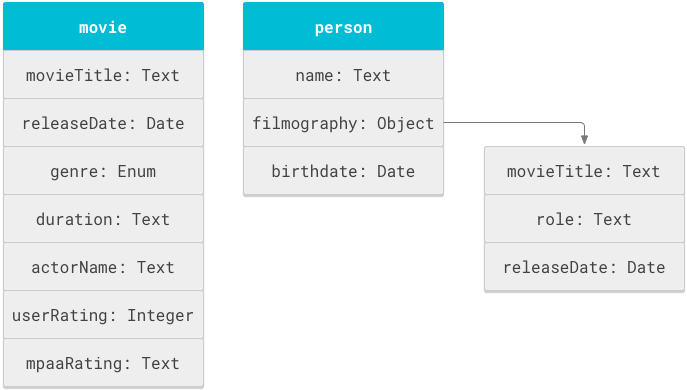
Schemat Cloud Search to w zasadzie lista instrukcji definicji obiektów zdefiniowanych w tagu objectDefinitions. Poniższy fragment schematu pokazuje instrukcje objectDefinitions dla obiektów schematu filmu i osoby.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
Podczas definiowania obiektu schematu podajesz name dla obiektu, który musi być unikalny wśród wszystkich innych obiektów w schemacie. Zwykle używasz namewartości, która opisuje obiekt, np. movie w przypadku obiektu filmu. Usługa schematu używa pola name jako kluczowego identyfikatora obiektów, które można indeksować. Więcej informacji o polu name znajdziesz w definicji obiektu.
Określanie właściwości obiektu
Zgodnie z informacjami w sekcji ObjectDefinition po nazwie obiektu następuje zbiór options i lista propertyDefinitions.
options może dodatkowo składać się z freshnessOptions i displayOptions.
Wartości
freshnessOptions
służą do dostosowywania rankingu wyszukiwania na podstawie aktualności produktu. Elementy displayOptions służą do określania, czy w wynikach wyszukiwania obiektu mają być wyświetlane określone etykiety i właściwości.
W sekcji
propertyDefinitions
określasz właściwości obiektu, np. tytuł filmu i datę premiery.
Poniższy fragment kodu przedstawia obiekt movie z 2 właściwościami: movieTitle i releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition składa się z tych elementów:
- ciąg tekstowy
name. - Lista opcji niezależnych od typu, np.
isReturnablew poprzednim fragmencie kodu. - Typ i powiązane z nim opcje specyficzne dla danego typu, takie jak
textPropertyOptionsiretrievalImportancew poprzednim fragmencie kodu. operatorOptionsopisujący sposób użycia właściwości jako operatora wyszukiwania.- Co najmniej jeden znak
displayOptions, np.displayLabelw poprzednim przykładzie.
name właściwości musi być unikalna w obrębie obiektu zawierającego, ale ta sama nazwa może być używana w innych obiektach i podobiektach.
Na rysunku 1 tytuł filmu i data premiery zostały zdefiniowane 2 razy: raz w obiekcie movie i ponownie w obiekcie podrzędnym filmography obiektu person. Ten schemat ponownie wykorzystuje pole movieTitle, dzięki czemu może obsługiwać 2 rodzaje wyszukiwania:
- Wyświetlanie wyników dotyczących filmów, gdy użytkownicy wyszukują tytuł filmu.
- Wyświetlanie wyników dotyczących osób, gdy użytkownicy szukają tytułu filmu, w którym wystąpił dany aktor.
Podobnie schemat ponownie wykorzystuje pole releaseDate, ponieważ ma ono takie samo znaczenie w przypadku obu pól movieTitle.
Podczas tworzenia własnego schematu zastanów się, czy w repozytorium znajdują się powiązane pola zawierające dane, które chcesz zadeklarować w schemacie więcej niż raz.
Dodawanie opcji niezależnych od typu
W sekcji PropertyDefinition znajdziesz ogólne opcje funkcji wyszukiwania wspólne dla wszystkich usług niezależnie od typu danych.
isReturnable– wskazuje, czy usługa identyfikuje dane, które powinny być zwracane w wynikach wyszukiwania za pomocą interfejsu Query API. Wszystkie właściwości przykładowego filmu można zwrócić. Właściwości, których nie można zwrócić, mogą być używane do wyszukiwania lub ustalania rankingu wyników bez zwracania ich użytkownikowi.isRepeatable– wskazuje, czy dla właściwości dozwolonych jest wiele wartości. Na przykład film ma tylko jedną datę premiery, ale może mieć wielu aktorów.isSortable– wskazuje, że właściwość może być używana do sortowania. Nie może to być prawdą w przypadku właściwości, które można powtarzać. Na przykład wyniki wyszukiwania filmów mogą być sortowane według daty premiery lub oceny użytkowników.isFacetable– oznacza, że właściwość może być używana do generowania aspektów. Aspekt służy do zawężania wyników wyszukiwania. Użytkownik widzi początkowe wyniki, a następnie dodaje kryteria lub aspekty, aby jeszcze bardziej je zawęzić. Ta opcja nie może mieć wartości „prawda” w przypadku usług, których typ to obiekt. Aby ustawić tę opcję, musisz mieć włączoną funkcjęisReturnable. Ta opcja jest dostępna tylko w przypadku właściwości typu wyliczeniowego, logicznego i tekstowego. Na przykład w naszym przykładowym schemacie możemy ustawić atrybutygenre,actorName,userRatingimpaaRatingjako podlegające filtrowaniu, aby można było ich używać do interaktywnego zawężania wyników wyszukiwania.isWildcardSearchableoznacza, że użytkownicy mogą przeprowadzać wyszukiwanie z użyciem symboli wieloznacznych w przypadku tej usługi. Ta opcja jest dostępna tylko w przypadku usług tekstowych. Sposób działania wyszukiwania z użyciem symbolu wieloznacznego w polu tekstowym zależy od wartości ustawionej w polu exactMatchWithOperator. Jeśli wartośćexactMatchWithOperatorjest ustawiona natrue, wartość tekstowa jest tokenizowana jako jedna wartość atomowa i wyszukiwanie z użyciem symbolu wieloznacznego jest przeprowadzane na jej podstawie. Jeśli na przykład wartość tekstowa toscience-fiction, pasuje do niej zapytanie z symbolem wieloznacznymscience-*. Jeśli parametrexactMatchWithOperatorma wartośćfalse, wartość tekstowa jest tokenizowana, a w odniesieniu do każdego tokena przeprowadzane jest wyszukiwanie z użyciem symboli wieloznacznych. Jeśli np. wartość tekstowa to „science-fiction”, zapytania z wieloznacznymi znakamisci*lubfi*pasują do produktu, ale zapytaniescience-*nie pasuje.
Wszystkie te parametry ogólnej funkcji wyszukiwania mają wartość logiczną. Wszystkie mają wartość domyślną false i muszą mieć wartość true, aby można było ich używać.
W tabeli poniżej znajdziesz parametry logiczne, które są ustawione na true
we wszystkich usługach obiektu movie:
| Właściwość | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
prawda | prawda | |||
releaseDate |
prawda | prawda | |||
genre |
prawda | prawda | prawda | ||
duration |
prawda | ||||
actorName |
prawda | prawda | prawda | prawda | |
userRating |
prawda | prawda | |||
mpaaRating |
prawda | prawda |
Zarówno genre, jak i actorName mają wartość isRepeatable ustawioną na true, ponieważ film może należeć do więcej niż jednego gatunku i zwykle ma więcej niż jednego aktora. Właściwość nie może być sortowalna, jeśli jest powtarzalna lub znajduje się w powtarzalnym obiekcie podrzędnym.
Określ typ
W sekcji referencyjnej PropertyDefinition znajdziesz kilka xxPropertyOptions, gdzie xx jest określonym typem, np. boolean. Aby ustawić typ danych właściwości, musisz zdefiniować odpowiedni obiekt typu danych. Zdefiniowanie obiektu typu danych dla właściwości określa typ danych tej właściwości. Na przykład zdefiniowanie textPropertyOptions dla właściwości movieTitle oznacza, że tytuł filmu jest typu tekstowego. Poniższy fragment kodu pokazuje właściwość movieTitle, w której textPropertyOptions określa typ danych.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
Usługa może mieć tylko jeden powiązany typ danych. Na przykład w schemacie filmu releaseDate może być tylko datą (np. 2016-01-13) lub ciąg znaków (np. January 13, 2016), ale nie oba.
Oto obiekty typu danych używane do określania typów danych właściwości w przykładowym schemacie filmu:
| Właściwość | Obiekt typu danych |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
Typ danych, który wybierzesz dla usługi, zależy od oczekiwanych przypadków użycia.
W tym hipotetycznym scenariuszu schematu filmu użytkownicy będą chcieli sortować wyniki chronologicznie, więc releaseDate jest obiektem daty.
Jeśli na przykład chcesz porównać premiery z grudnia w różnych latach z premierami ze stycznia, format ciągu tekstowego może być przydatny.
Konfigurowanie opcji specyficznych dla typu
W sekcji referencyjnej PropertyDefinition znajdziesz linki do opcji każdego typu. Większość opcji specyficznych dla typu jest opcjonalna, z wyjątkiem listy possibleValues w enumPropertyOptions. Dodatkowo opcja orderedRanking umożliwia
określanie względnej kolejności wartości. Poniższy fragment kodu pokazuje właściwość movieTitle z ustawieniem textPropertyOptions typu danych i opcją retrievalImportance specyficzną dla typu.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Oto dodatkowe opcje związane z typem użyte w przykładowym schemacie:
| Właściwość | Typ | Opcje specyficzne dla typu |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
Definiowanie opcji operatora
Oprócz opcji specyficznych dla danego typu każdy typ ma zestaw opcjonalnychoperatorOptions Opcje te opisują, jak właściwość jest używana jako operator wyszukiwania. Poniższy fragment kodu pokazuje właściwość movieTitle z ustawieniem typu danychtextPropertyOptions oraz opcjami specyficznymi dla typów retrievalImportance i operatorOptions.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Każdy operatorOptions ma operatorName, np. title w przypadku movieTitle. Nazwa operatora to operator wyszukiwania dla usługi. Operator wyszukiwania to parametr, którego użytkownicy powinni używać, aby zawęzić wyszukiwanie. Jeśli na przykład chcesz wyszukać filmy na podstawie ich tytułu, wpisz title:movieName, gdzie movieName to nazwa filmu.
Nazwy operatorów nie muszą być takie same jak nazwa obiektu. Zamiast tego używaj nazw operatorów, które odzwierciedlają najczęściej używane słowa przez użytkowników w Twojej organizacji. Jeśli na przykład użytkownicy wolą termin „name” zamiast „title” w przypadku tytułu filmu, nazwę operatora należy ustawić na „name”.
Możesz użyć tej samej nazwy operatora w przypadku wielu właściwości, o ile wszystkie właściwości mają ten sam typ. Jeśli w zapytaniu użyjesz wspólnej nazwy operatora, zostaną pobrane wszystkie usługi, które jej używają. Załóżmy na przykład, że obiekt filmu ma właściwości plotSummary i plotSynopsis, a każda z nich ma wartość operatorName równą plot. Jeśli oba te pola są tekstowe (textPropertyOptions), jedno zapytanie z operatorem wyszukiwania plot pobierze oba te pola.
Oprócz właściwości operatorName właściwości, które można sortować, mogą mieć pola lessThanOperatorName i greaterThanOperatorName w operatorOptions.
Użytkownicy mogą używać tych opcji do tworzenia zapytań na podstawie porównań z przesłaną wartością.
Pole textOperatorOptions zawiera pole exactMatchWithOperator w operatorOptions. Jeśli ustawisz wartość exactMatchWithOperator na true, ciąg zapytania musi być zgodny z całą wartością właściwości, a nie tylko znajdować się w tekście.
Wartość tekstowa jest traktowana jako jedna wartość atomowa w wyszukiwaniach operatorów i dopasowaniach aspektów.
Na przykład rozważ zindeksowanie obiektów Book lub Movie z właściwościami gatunku.
Gatunki mogą obejmować „Science-Fiction”, „Science” i „Fiction”. Jeśli parametr
exactMatchWithOperator ma wartość false lub jest pominięty,
wyszukiwanie gatunku lub
wybranie aspektu „Science” lub „Fiction” również
zwróci wyniki dla „Science-Fiction”, ponieważ tekst jest tokenizowany, a
tokeny „Science” i „Fiction” występują w „Science-Fiction”.
Gdy exactMatchWithOperator ma wartość true, tekst jest traktowany jako pojedynczy token, więc ani „Science”, ani „Fiction” nie pasuje do „Science-Fiction”.
(Opcjonalnie) Dodaj sekcję displayOptions.
Na końcu każdej sekcji znajduje się opcjonalna sekcja displayOptionspropertyDefinition. Ta sekcja zawiera 1 ciąg znaków displayLabel.
displayLabel to zalecana, przyjazna dla użytkownika etykieta tekstowa
właściwości. Jeśli właściwość jest skonfigurowana do wyświetlania za pomocą parametru ObjectDisplayOptions, ta etykieta jest wyświetlana przed właściwością. Jeśli właściwość jest skonfigurowana do wyświetlania, a element displayLabel nie jest zdefiniowany, wyświetlana jest tylko wartość właściwości.
Poniższy fragment kodu pokazuje właściwość movieTitle z wartością displayLabel
ustawioną na „Title”.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Oto wartości displayLabel wszystkich właściwości obiektu movie w przykładowym schemacie:
| Właściwość | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(Opcjonalnie) Dodaj sekcję suggestionFilteringOperators[].
Na końcu każdej sekcji propertyDefinition znajduje się opcjonalna sekcja
suggestionFilteringOperators[]. W tej sekcji możesz zdefiniować właściwość używaną do filtrowania sugestii autouzupełniania. Możesz na przykład zdefiniować operatora genre, aby filtrować sugestie na podstawie preferowanego gatunku filmu użytkownika. Gdy użytkownik wpisze zapytanie, w sugestiach autouzupełniania wyświetlą się tylko te filmy, które pasują do jego ulubionego gatunku.
Rejestrowanie schematu
Aby zapytania Cloud Search zwracały dane strukturalne, musisz zarejestrować schemat w usłudze schematów Cloud Search. Rejestracja schematu wymaga identyfikatora źródła danych uzyskanego podczas kroku Inicjowanie źródła danych.
Za pomocą identyfikatora źródła danych wyślij żądanie UpdateSchema, aby zarejestrować schemat.
Zgodnie z informacjami na stronie referencyjnej UpdateSchema wyślij to żądanie HTTP, aby zarejestrować schemat:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Treść żądania powinna zawierać:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
Użyj opcji validateOnly, aby sprawdzić poprawność schematu bez jego rejestrowania.
Indeksowanie danych
Po zarejestrowaniu schematu wypełnij źródło danych za pomocą wywołań indeksu. Indeksowanie odbywa się zwykle w łączniku treści.
W przypadku schematu filmu żądanie indeksowania interfejsu API REST dla jednego filmu wyglądałoby tak:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Zwróć uwagę, że wartość movie w polu objectType jest zgodna z nazwą definicji obiektu w schemacie. Dzięki dopasowaniu tych 2 wartości Cloud Search wie, którego obiektu schematu użyć podczas indeksowania.
Zwróć też uwagę, jak indeksowanie właściwości schematu releaseDate wykorzystuje właściwości podrzędne year, month i day, które dziedziczy, ponieważ jest zdefiniowane jako typ danych date za pomocą datePropertyOptions.
Jednak ponieważ właściwości year, month i day nie są zdefiniowane w schemacie, nie możesz wysyłać zapytań dotyczących jednej z tych właściwości (np. year) osobno.
Zwróć też uwagę, jak powtarzalna właściwość actorName jest indeksowana za pomocą listy wartości.
Identyfikowanie potencjalnych problemów z indeksowaniem
Oto 2 najczęstsze problemy związane ze schematami i indeksowaniem:
Twoja prośba o indeksowanie zawiera obiekt schematu lub nazwę właściwości, które nie zostały zarejestrowane w usłudze schematów. Ten problem powoduje, że właściwość lub obiekt są ignorowane.
Żądanie indeksowania zawiera właściwość o wartości typu innej niż typ zarejestrowany w schemacie. Ten problem powoduje, że Cloud Search zwraca błąd podczas indeksowania.
Testowanie schematu za pomocą kilku typów zapytań
Zanim zarejestrujesz schemat w dużym repozytorium danych produkcyjnych, rozważ przeprowadzenie testów w mniejszym repozytorium danych testowych. Testowanie z mniejszym repozytorium testowym umożliwia szybkie wprowadzanie zmian w schemacie i usuwanie indeksowanych danych bez wpływu na większy indeks lub istniejący indeks produkcyjny. W przypadku repozytorium danych testowych utwórz listę ACL, która autoryzuje tylko użytkownika testowego, aby inni użytkownicy nie widzieli tych danych w wynikach wyszukiwania.
Aby utworzyć interfejs wyszukiwania do weryfikowania zapytań, zapoznaj się z sekcją Interfejs wyszukiwania.
W tej sekcji znajdziesz kilka przykładowych zapytań, których możesz użyć do testowania schematu filmu.
Testowanie za pomocą ogólnego zapytania
Zapytanie ogólne zwraca wszystkie elementy w źródle danych zawierające określony ciąg znaków. Korzystając z interfejsu wyszukiwania, możesz uruchomić ogólne zapytanie dotyczące źródła danych o filmach, wpisując słowo „titanic” i naciskając Enter. W wynikach wyszukiwania powinny się pojawić wszystkie filmy zawierające słowo „titanic”.
Testowanie z operatorem
Dodanie operatora do zapytania ogranicza wyniki do elementów, które pasują do wartości operatora. Możesz na przykład użyć operatora actor, aby znaleźć wszystkie filmy, w których występuje konkretny aktor. Za pomocą interfejsu wyszukiwania możesz wykonać to zapytanie operatora, wpisując parę operator=wartość, np. „aktor:Zane”, i naciskając Enter. W wynikach wyszukiwania powinny się pojawić wszystkie filmy, w których występuje Zane.
Dostosowywanie schematu
Gdy schemat i dane będą już używane, nadal monitoruj, co działa, a co nie działa w przypadku użytkowników. Warto rozważyć dostosowanie schematu w tych sytuacjach:
- Indeksowanie pola, które nie było wcześniej indeksowane. Użytkownicy mogą na przykład wielokrotnie wyszukiwać filmy na podstawie nazwiska reżysera, więc możesz dostosować schemat, aby obsługiwał nazwisko reżysera jako operatora.
- Zmiana nazw operatorów wyszukiwania na podstawie opinii użytkowników. Nazwy operatorów mają być przyjazne dla użytkownika. Jeśli użytkownicy stale „zapamiętują” nieprawidłową nazwę operatora, możesz ją zmienić.
Ponowne indeksowanie po zmianie schematu
Zmiana dowolnej z tych wartości w schemacie nie wymaga ponownego indeksowania danych. Wystarczy przesłać nową prośbę UpdateSchema, a indeks będzie nadal działać:
- Nazwy operatorów.
- Minimalne i maksymalne wartości całkowite.
- Ranking uporządkowany liczb całkowitych i wartości wyliczeniowych.
- Opcje aktualności.
- Opcje wyświetlania.
W przypadku tych zmian wcześniej zindeksowane dane będą nadal działać zgodnie z wcześniej zarejestrowanym schematem. Jeśli jednak zaktualizowany schemat zawiera te zmiany, musisz ponownie zindeksować istniejące wpisy, aby zobaczyć zmiany na ich podstawie:
- Dodawanie lub usuwanie nowej usługi lub nowego obiektu
- Zmiana wartości
isReturnable,isFacetablelubisSortablezfalsenatrue.
Wartość isFacetable lub isSortable ustaw na true tylko wtedy, gdy masz jasny przypadek użycia i potrzebę.
Gdy zaktualizujesz schemat, oznaczając właściwość symbolem isSuggestable, musisz ponownie zaindeksować dane, co spowoduje opóźnienie w używaniu autouzupełniania w przypadku tej właściwości.
Niedozwolone zmiany właściwości
Niektóre zmiany schematu są niedozwolone, nawet jeśli ponownie zaindeksujesz dane, ponieważ spowodują uszkodzenie indeksu lub będą generować słabe lub niespójne wyniki wyszukiwania. Obejmują one zmiany w:
- Typ danych usługi.
- Nazwa usługi.
- Ustawienie
exactMatchWithOperator. - Ustawienie
retrievalImportance.
Istnieje jednak sposób na obejście tego ograniczenia.
Wprowadzanie złożonych zmian w schemacie
Aby uniknąć zmian, które mogłyby spowodować uzyskanie słabych wyników wyszukiwania lub uszkodzenie indeksu wyszukiwania, Cloud Search uniemożliwia wprowadzanie określonych rodzajów zmian w żądaniach UpdateSchema po zindeksowaniu repozytorium. Na przykład po ustawieniu typu danych lub nazwy właściwości nie można ich zmienić. Tych zmian nie można wprowadzić za pomocą prostego żądania UpdateSchema, nawet jeśli ponownie zindeksujesz dane.
W sytuacjach, w których musisz wprowadzić niedozwoloną zmianę w schemacie, często możesz wprowadzić serię dozwolonych zmian, które dadzą ten sam efekt. Zwykle polega to na przeniesieniu najpierw indeksowanych właściwości ze starszej definicji obiektu do nowszej, a następnie wysłaniu żądania indeksowania, które używa tylko nowszej właściwości.
Aby zmienić typ danych lub nazwę usługi:
- Dodaj nową właściwość do definicji obiektu w schemacie. Użyj innej nazwy niż nazwa właściwości, którą chcesz zmienić.
- Wyślij żądanie UpdateSchema z nową definicją. Pamiętaj, aby w prośbie przesłać cały schemat, w tym zarówno nową, jak i starą właściwość.
Uzupełnij indeks z repozytorium danych. Aby uzupełnić indeks, wyślij wszystkie żądania indeksowania za pomocą nowej usługi, ale nie za pomocą starej usługi, ponieważ spowoduje to podwójne zliczanie dopasowań zapytań.
- Podczas uzupełniania indeksowania sprawdzaj nową właściwość i domyślnie używaj starej właściwości, aby uniknąć niespójnego działania.
- Po zakończeniu wypełniania wstecznego uruchom zapytania testowe, aby sprawdzić, czy wszystko działa prawidłowo.
Usuń starą usługę. Wyślij kolejne żądanie UpdateSchema bez starej nazwy właściwości i zaprzestań używania starej nazwy właściwości w przyszłych żądaniach indeksowania.
Przenieś wszystkie dane ze starej usługi do nowej. Jeśli na przykład zmienisz nazwę właściwości z „twórca” na „autor”, musisz zaktualizować kod zapytania, aby zamiast „twórca” używać „autor”.
Cloud Search przechowuje rekordy usuniętych właściwości lub obiektów przez 30 dni, aby zapobiec ponownemu użyciu, które mogłoby spowodować nieoczekiwane wyniki indeksowania. W ciągu tych 30 dni musisz zaprzestać używania usuniętego obiektu lub usługi, w tym pominąć je w przyszłych żądaniach indeksowania. Dzięki temu, jeśli później zdecydujesz się przywrócić tę usługę lub obiekt, możesz to zrobić w sposób, który zachowa poprawność indeksu.
Poznaj ograniczenia rozmiaru
Cloud Search nakłada limity na rozmiar obiektów i schematów danych strukturalnych. Limity te to:
- Maksymalna liczba obiektów najwyższego poziomu to 10.
- Maksymalna głębokość hierarchii danych strukturalnych to 10 poziomów.
- Łączna liczba pól w obiekcie jest ograniczona do 1000, co obejmuje liczbę pól pierwotnych oraz sumę liczby pól w każdym zagnieżdżonym obiekcie.
Następne kroki
Oto kilka kolejnych kroków, które możesz podjąć:
Utwórz interfejs wyszukiwania, aby przetestować schemat.
Dostosuj schemat, aby poprawić jakość wyszukiwania.
Strukturyzuj schemat, aby zapewnić optymalną interpretację zapytań.
Dowiedz się, jak używać schematu
_dictionaryEntrydo definiowania synonimów terminów powszechnie używanych w Twojej firmie. Aby użyć schematu_dictionaryEntry, zapoznaj się z sekcją Definiowanie synonimów.Utwórz oprogramowanie sprzęgające.