この記事では、アカウントでメニュー API を有効にして統合するプロセスについて説明します。以下では、オンボーディング プロセスとリリースの前提条件の詳細な概要を説明します。統合作業を計画する際は、このページを参照してください。
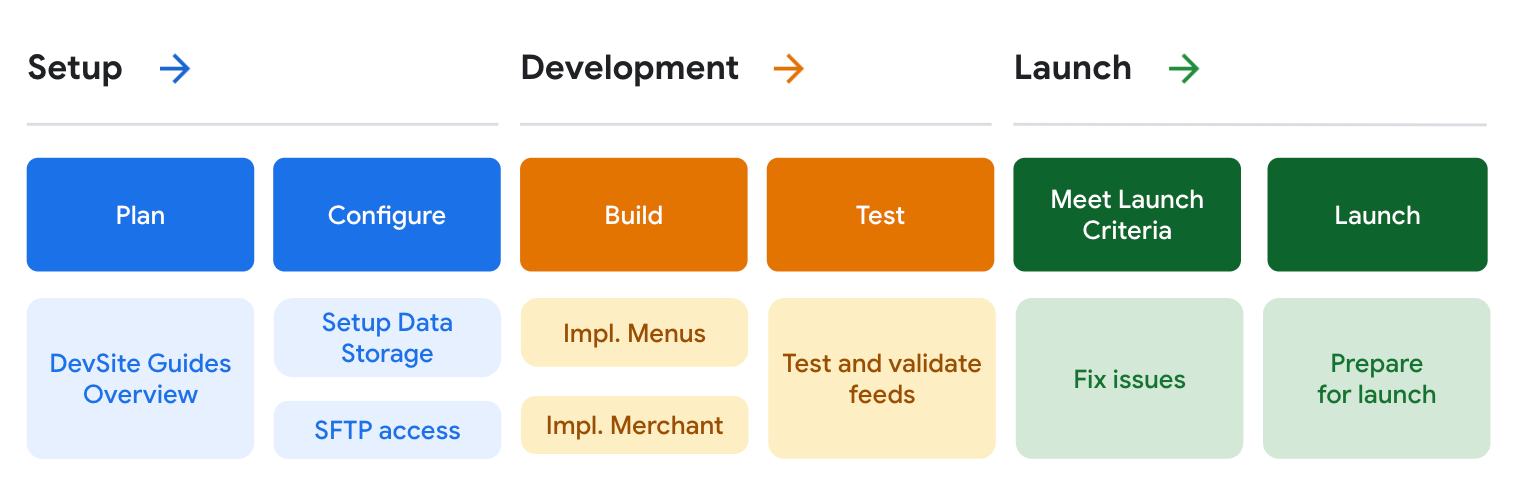
- 設定 - アカウントの構成と開発プロセスの計画。
- 開発 - データフィードの開発とテスト。
- リリース - リリース前のデータ評価。
セットアップ
この段階では、パートナー ポータルのアカウントが完全に設定され、静的メニューデータに関連するデータフィードを受け入れる準備ができていることを確認することが重要です。メニューのメタデータを追加する既存の有効な OwG リダイレクトまたは RwG 統合がある場合は、この統合に既存のアカウントが再利用されます。このプラットフォームで OwG Direct が統合されている場合や、統合がまったくない場合は、新しいアカウントが作成され、アクセス情報がメールで共有されます。
パートナー ポータルでアカウントにアクセスし、フィード設定ページ([設定] > [フィード])に移動します。メニューデータフィードの統合に関連する SFTP サーバーは、Generic と Merchants の 2 つです。両方の SFTP サーバーで SSH 公開鍵が構成されていることを確認してください。SSH 認証鍵の構成方法については、こちらのページをご覧ください。
汎用 SFTP サーバーは、さまざまなデータスキーマに従うさまざまなフィードを受け入れることができます。構造化メニューデータを受け入れるフィードタイプの名前は google.food_menu で、通常はオンボーディングの開始時にデフォルトでアカウントで有効になります。フィードを送信しようとすると、次のエラー メッセージが表示される場合 -
「フィード処理中にエラーが発生しました。フィードの解析中に内部的な問題が発生しました。「google.food_menu」が有効になっていません。修正してからもう一度お試しください。」と表示された場合は、Google の担当者にお問い合わせのうえ、このフィードタイプを有効にしてください。
最後に、[設定] > [連絡先情報] ページに移動し、連絡先情報がすべて最新であることを確認してください。
開発
開発段階には、実装作業の大部分であるデータフィードの生成とテストが含まれます。データフィードは、毎日作成してターゲット SFTP サーバーに送信する必要があります。送信されたフィードは、送信後 1 時間以内に処理が開始される予定です。フィードの生成を行う際は、データフィードの仕様とサンプルをご覧ください。仕様は protobuf 形式で提供されていますが、トラブルシューティングが容易なため、フィード ファイルを JSON 形式でアップロードすることをおすすめします。そのため、フィード サンプルも JSON 形式で提供されています。
1 つのデータフィード ファイルをすばやくテストするには、フィード検証ツールのオンライン ツールを使用して、そのファイルが仕様に準拠しているかどうかを確認します。このツールは、ファイルがデータスキーマと一致しているかどうかを示し、一致していない場合はエラーのリストを出力します。複数のファイルで構成されるデータフィードの全体をテストするには、そのフィードをサンドボックス環境にアップロードし、取り込みが完了したら、パートナー ポータルで結果を確認します。フィード取り込み中に、一部のビジネス ロジックとデータの品質をテストするために、追加の検証ルールが適用されます。
リリース
すべての統合作業が完了し、レストランのメニューの在庫全体が本番環境フィードに正しく反映されたら、リリース ステージを開始できます。
リリースの前提条件
統合を開始するには、次の条件を満たしている必要があります。
- データフィードが本番環境で処理され、エラーが 0 件。
- 本番環境データフィードには、この統合の開始時にこの統合の対象となるすべての広告枠が含まれます。
- 販売者データの大部分が Google マップの場所とマッチングする。
- 本番環境フィードがデータ品質評価に合格している。
- 統合は、フードメニューのポリシーと要件をすべて満たしています。
データ評価
本番環境データフィードがエラーなく取り込まれた後、メニューデータの品質を評価する内部プロセスがある場合があります。このプロセスは、料理の説明に食品以外のコンテンツが含まれている、料理名や価格が一致しないなど、データ品質の不整合を見つけることを目的としています。このような問題が見つかった場合は、フィードバックが開発チームと共有されます。