
Quando restituisci una risposta all'Assistente Google, puoi utilizzare un sottoinsieme dei Speech Synthesis Markup Language (SSML) nelle risposte. Di Utilizzando SSML, puoi rendere le risposte della conversazione più naturali e parlato. Di seguito viene mostrato un esempio di markup SSML e di come viene letto nuovamente Assistente Google.
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.ask(ssml); }
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Audio
SSML è supportato nel Simulatore di azioni, ma non in Dialogflow simulatore.
URL in SSML
Quando si definisce una risposta SSML che include solo un URL, la e commerciale in quell'URL
possono causare problemi a causa della formattazione XML. Per verificare che l'URL sia corretto
a cui viene fatto riferimento, sostituisci le istanze di & con &.
Anche se la tua risposta SSML include solo un URL, Actions on Google richiede
testo visualizzato per la risposta. Poiché il testo all'interno del tag <audio> non sarà
pronunciate dall'assistente, puoi inserire il testo di riempimento o una breve descrizione
<audio> per soddisfare questo requisito. Il testo all'interno del tag <audio> non verrà
parlata dall'assistente dopo la riproduzione dell'audio e soddisfa i requisiti di Action on Google
per una versione di testo visualizzato del tuo SSML.
Ecco un esempio di risposta SSML problematica:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
L'esempio precedente non esegue il escape & per una corretta formattazione XML.
Una versione corretta della stessa risposta SSML ha il seguente aspetto:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Supporto per gli elementi SSML
Le seguenti sezioni descrivono gli elementi e le opzioni SSML che possono essere utilizzati nelle azioni.
<speak>
L'elemento principale della risposta SSML.
Per scoprire di più sull'elemento speak, consulta la specifica di W3.
Esempio
<speak> my SSML content </speak>
<break>
Un elemento vuoto che controlla la messa in pausa o altri limiti prosodici tra le parole. L'utilizzo di <break> tra qualsiasi coppia di token è facoltativo. Se questo elemento non è presente tra una parola e l'altra, l'interruzione viene determinata automaticamente in base al contesto linguistico.
Per scoprire di più sull'elemento break, consulta la specifica di W3.
Attributi
| Attributo | Descrizione |
|---|---|
time |
Imposta la durata dell'interruzione in secondi o millisecondi (ad es. "3 s" o "250 ms"). |
strength |
Imposta la forza dell'interruzione prosodica dell'output in base a termini relativi. I valori validi sono: "x-weak", deboli", "medium", "strong" e "x-strong". Il valore "nessuno" indica che non deve essere emesso alcun limite di interruzione prosodica, che può essere utilizzato per evitare un'interruzione prosodica che altrimenti produrrebbe il processore. Gli altri valori indicano una forza di interruzione monotonica non decrescente (concettualmente crescente) tra i token. I limiti più forti sono in genere accompagnati da pause. |
Esempio
L'esempio seguente mostra come utilizzare l'elemento <break> per fare una pausa tra un passaggio e l'altro:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Questo elemento ti consente di indicare informazioni sul tipo di costrutto di testo contenuto all'interno dell'elemento. Inoltre, consente di specificare il livello di dettaglio per il rendering del testo contenuto.
L'elemento <say‑as> ha l'attributo obbligatorio interpret-as, che determina la modalità di pronuncia del valore. È possibile utilizzare gli attributi facoltativi format e detail a seconda del valore di interpret-as specifico.
Esempi
L'attributo interpret-as supporta i seguenti valori:
-
currencyL'esempio seguente è pronunciato come "quarantadue dollari e un centesimo". Se l'attributo della lingua viene omesso, utilizza le impostazioni internazionali correnti.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneConsulta la descrizione di
interpret-as='telephone'nella nota WG dei valori degli attributi di W3C SSML 1.0.L'esempio seguente è pronunciato come "uno otto zero zero due zero due uno due uno due". Se lo stile "google:style" omesso, viene enunciato lo zero con la lettera O.
"google:style='zero-as-zero'" attualmente funziona solo con le lingue EN.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimospell-outIl seguente esempio viene scritto lettera per lettera:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateL'attributo
formatè una sequenza di codici di caratteri dei campi data. I codici di carattere dei campi supportati informatsono {y,m,d} rispettivamente per anno, mese e giorno (del mese). Se il codice di campo viene visualizzato una volta per l'anno, il mese o il giorno, il numero previsto di cifre è rispettivamente 4, 2 e 2. Se il codice di campo viene ripetuto, il numero di cifre previste è il numero di volte in cui il codice viene ripetuto. I campi nel testo della data possono essere separati da punteggiatura e/o spazi.L'attributo
detailcontrolla la forma pronunciata della data. Perdetail='1'sono obbligatori solo i campi del giorno e uno del mese o dell'anno, sebbene possano essere forniti entrambi. Questa è l'impostazione predefinita quando vengono specificati meno di tutti e tre i campi. La forma pronunciata è "Il {ordinal day} del {month} {year}".Il seguente esempio è pronunciato "Il 1° settembre 1960":
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>Il seguente esempio viene pronunciato come "Il 10 settembre":
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Per
detail='2'i campi giorno, mese e anno sono obbligatori. Si tratta del valore predefinito quando vengono compilati tutti e tre i campi. La forma pronunciata è "{month} {ordinal day}, {year}".Il seguente esempio è pronunciato "10 settembre 1960":
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersIl seguente esempio è pronunciato come "C A N":
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalL'esempio seguente è pronunciato come "Dodicimilatrecentoquarantacinque" (per l'inglese americano) o "dodicimilatrecentoquarantacinque (per l'inglese britannico)":
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalIl seguente esempio viene pronunciato come "Primo":
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionIl seguente esempio è pronunciato come "cinque e mezzo":
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveobleepL'esempio seguente è un segnale acustico, come se fosse stato censurato:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitConverte le unità in singolare o plurale in base al numero. Il seguente esempio viene pronunciato come "10 piedi":
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeIl seguente esempio è pronunciato "Due e trenta del pomeriggio":
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>L'attributo
formatè una sequenza di codici caratteri nei campi temporali. I codici carattere dei campi supportati informatsono {h,m,s,Z,12,24} rispettivamente per ora, minuto (dell'ora), secondo (del minuto), fuso orario, formato 12 ore e formato 24 ore. Se il codice di campo viene visualizzato una volta per ora, minuti o secondi, il numero di cifre previsto è rispettivamente 1, 2 e 2. Se il codice di campo viene ripetuto, il numero di cifre previste è il numero di volte in cui il codice viene ripetuto. I campi nel testo dell'ora possono essere separati da punteggiatura e/o spazi. Se ora, minuto o secondo non sono specificati nel formato o non sono presenti cifre corrispondenti, il campo viene considerato come un valore zero. Il valore predefinito diformatè "hms12".L'attributo
detailconsente di stabilire se la forma pronunciata dell'ora è nel formato 12 o 24 ore. Il formato vocale è nel formato 24 ore se il valoredetail='1'odetailviene omesso e il formato dell'ora è nel formato 24 ore. Il formato pronunciato è nel formato di 12 ore se il valoredetail='2'odetailviene omesso e il formato dell'ora è nel formato 12 ore.
Per scoprire di più sull'elemento say-as, consulta la specifica di W3.
<audio>
Supporta l'inserimento di file audio registrati e l'inserimento di altri formati audio insieme all'output vocale sintetizzato.
Attributi
| Attributo | Obbligatorio | Predefinito | Valori |
|---|---|---|---|
src |
sì | n/d | Un URI che fa riferimento alla sorgente multimediale audio. Il protocollo supportato è https. |
clipBegin |
no | 0 | Una colonna TimeDesignation, ovvero l'offset dall'inizio della riproduzione della sorgente audio. Se questo valore è superiore o uguale alla durata effettiva della sorgente audio, non verrà inserito alcun audio. |
clipEnd |
no | infinito | Una colonna TimeDesignation, ovvero l'offset dall'inizio alla fine della riproduzione della sorgente audio. Se la durata effettiva della sorgente audio è inferiore a questo valore, la riproduzione termina in quel momento. Se clipBegin è superiore o uguale a clipEnd, l'audio non viene inserito. |
speed |
no | 100% | Il rapporto della velocità di riproduzione in uscita rispetto alla normale velocità di input espressa in percentuale. Il formato è un numero reale positivo seguito dalla percentuale. L'intervallo attualmente supportato è [50% (lenta - velocità dimezzata), 200% (veloce - velocità doppia)]. I valori al di fuori di questo intervallo possono (o non possono) essere modificati per rientrare nell'intervallo. |
repeatCount |
no | 1 o 10 se repeatDur è impostato |
Un numero reale che specifica quante volte inserire l'audio (dopo il clip, se presente, per clipBegin e/o clipEnd). Le ripetizioni frazionarie non sono supportate, pertanto il valore verrà arrotondato al numero intero più vicino. Zero non è un valore valido e viene pertanto considerato non specificato e presenta il valore predefinito in questo caso. |
repeatDur |
no | infinito | Un valore TimeDesignation che rappresenta un limite per la durata dell'audio inserito dopo l'elaborazione della sorgente per gli attributi clipBegin, clipEnd, repeatCount e speed (anziché la normale durata di riproduzione). Se la durata dell'audio elaborato è inferiore a questo valore, la riproduzione termina in quel momento. |
soundLevel |
no | +0dB | Regola il livello del suono dell'audio di soundLeveldecibel. La portata massima è +/-40 dB, ma l'intervallo effettivo potrebbe essere effettivamente inferiore e la qualità dell'output potrebbe non produrre risultati positivi su tutta la gamma. |
Di seguito sono riportate le impostazioni attualmente supportate per l'audio:
- Formato: MP3 (MPEG v2)
- 24.000 campioni al secondo
- 24K ~ 96.000 bit al secondo, velocità fissa
- Formato: Opus in Ogg
- 24.000 campioni al secondo (banda super larga)
- 24.000-96.000 bit al secondo, velocità fissa
- Formato (deprecato): WAV (RIFF)
- PCM a 16 bit firmato, small endian
- 24.000 campioni al secondo
- Per tutti i formati:
- È preferibile un canale singolo, ma lo stereo è accettabile.
- Durata massima di 240 secondi. Se vuoi riprodurre audio di durata maggiore, valuta l'implementazione di una risposta multimediale.
- La dimensione massima del file è 5 MB.
- L'URL di origine deve utilizzare il protocollo HTTPS.
- Il nostro user agent durante il recupero dell'audio è "Google-Speech- Actions".
I contenuti dell'elemento <audio> sono facoltativi e vengono utilizzati se il file audio non può essere riprodotto o se il dispositivo di output non supporta l'audio. I contenuti possono includere un elemento <desc>, nel qual caso i contenuti testuali di quell'elemento vengono utilizzati per la visualizzazione. Per ulteriori informazioni, consulta la sezione Audio registrato nell'elenco di controllo delle risposte.
L'URL src deve inoltre essere un URL HTTPS (Google Cloud Storage può ospitare i tuoi file audio su un URL https).
Per ulteriori informazioni sulle risposte multimediali, consulta la sezione sulle risposte multimediali nella guida Risposte.
Per scoprire di più sull'elemento audio, consulta la specifica di W3.
Esempio
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Elementi di frase e paragrafo.
Per scoprire di più sugli elementi p e s, consulta la specifica W3.
Esempio
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Best practice
- Usa <s>...</s> tag per aggregare frasi complete, soprattutto se contengono elementi SSML che cambiano prosodia (ovvero <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> e <sub>).
- Se una pausa nel discorso deve essere abbastanza lunga da poter essere udita, utilizza <s>...</s> e inserire l'interruzione tra le frasi.
<sub>
Indica che il testo nel valore dell'attributo alias sostituisce il testo contenuto per la pronuncia.
Puoi anche utilizzare l'elemento sub per fornire una pronuncia semplificata di una parola di difficile lettura. L'ultimo esempio riportato di seguito mostra questo caso d'uso in giapponese.
Per scoprire di più sull'elemento sub, consulta la specifica di W3.
Esempi
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Un elemento vuoto che inserisce un indicatore nella sequenza di testo o tag. Può essere utilizzato per fare riferimento a un una posizione specifica nella sequenza o per inserire un indicatore in uno stream di output per la notifica asincrona.
. di Gemini Advanced.Per scoprire di più sull'elemento mark, consulta la specifica di W3.
Esempio
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
Utilizzato per personalizzare la tonalità, la velocità del parlato e il volume del testo contenuto dall'elemento. Al momento sono supportati gli attributi rate, pitch e volume.
Gli attributi rate e volume possono essere impostati in base alle specifiche di W3. Esistono tre opzioni per impostare il valore dell'attributo pitch:
| Attributo | Descrizione |
|---|---|
name |
L'ID stringa per ogni contrassegno. |
| Opzione | Descrizione |
|---|---|
| Relativo | Specifica un valore relativo (ad es. "basso", "medio", "alto" e così via) dove "medio" è la tonalità predefinita. |
| Semitoni | Aumenta o diminuisci la proposta musicale di "N" semitoni con "+Nst" o "-Nst" rispettivamente. Tieni presente che "+/-" e "st" sono obbligatori. |
| Percentuale | Aumenta o diminuisci la proposta musicale di "N" percentuale utilizzando "+N%" o "-N%" rispettivamente. Tieni presente che "%" è obbligatorio ma "+/-" è facoltativo. |
Per scoprire di più sull'elemento prosody, consulta la specifica di W3.
Esempio
Nell'esempio seguente viene utilizzato l'elemento <prosody> per parlare lentamente a 2 semitoni più bassi del normale:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Utilizzato per aggiungere o rimuovere l'enfasi dal testo contenuto dall'elemento. L'elemento <emphasis> modifica la voce in modo simile a <prosody>, ma senza dover impostare attributi vocali individuali.
Questo elemento supporta un "livello" facoltativo con i seguenti valori validi:
strongmoderatenonereduced
Per scoprire di più sull'elemento emphasis, consulta la specifica di W3.
Esempio
Nell'esempio seguente viene utilizzato l'elemento <emphasis> per creare un annuncio:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Un contenitore multimediale parallelo che consente di riprodurre più elementi multimediali contemporaneamente. Gli unici contenuti consentiti sono un insieme di uno o più elementi <par>, <seq> e <media>. L'ordine degli elementi <media> non è significativo.
A meno che un elemento secondario non specifichi un'ora di inizio diversa, l'ora di inizio implicita per l'elemento corrisponde a quella del contenitore <par>. Se in un elemento secondario è impostato un valore di offset per l'attributo begin o end, l'offset dell'elemento sarà relativo all'ora di inizio del contenitore <par>. Per l'elemento <par> radice, l'attributo start viene ignorato, mentre l'ora di inizio corrisponde al momento in cui il processo di sintesi vocale SSML inizia a generare l'output per l'elemento <par> radice (ovvero l'ora di inizio effettiva è "zero").
Esempio
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Un contenitore multimediale sequenziale che consente di riprodurre gli elementi multimediali uno dopo l'altro. Gli unici contenuti consentiti sono un insieme di uno o più elementi <seq>, <par> e <media>. L'ordine degli elementi multimediali corrisponde all'ordine in cui vengono visualizzati.
Gli attributi begin ed end degli elementi secondari possono essere impostati su valori di offset (consulta la sezione Specifica temporale di seguito). Questi elementi secondari i valori di offset saranno relativi alla fine dell'elemento precedente nella sequenza o, nel caso del primo elemento della sequenza, all'inizio del relativo contenitore <seq>.
Esempio
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Rappresenta un livello multimediale all'interno di un elemento <par> o <seq>. I contenuti consentiti di un elemento <media> sono un elemento SSML <speak> o <audio>. La seguente tabella descrive gli attributi validi per un elemento <media>.
Attributi
| Attributo | Obbligatorio | Predefinito | Valori |
|---|---|---|---|
| xml:id | no | nessun valore | Un identificatore XML univoco per questo elemento. Le entità codificate non sono supportate. I valori dell'identificatore consentiti corrispondono all'espressione regolare "([-_#]|\p{L}|\p{D})+". Per ulteriori informazioni, consulta la sezione XML-ID. |
| inizio | no | 0 | L'ora di inizio per questo contenitore multimediale. Ignorato se si tratta dell'elemento contenitore multimediale principale (trattato come il valore predefinito "0"). Consulta la sezione Specifica temporale di seguito per conoscere i valori stringa validi. |
| fine | no | nessun valore | Una specifica per l'ora di fine del contenitore multimediale. Consulta la sezione Specifica temporale di seguito per conoscere i valori stringa validi. |
| repeatCount | no | 1 | Un numero reale che specifica quante volte inserire il contenuto multimediale. Le ripetizioni frazionarie non sono supportate, pertanto il valore verrà arrotondato al numero intero più vicino. Zero non è un valore valido e viene pertanto considerato non specificato e presenta il valore predefinito in questo caso. |
| repeatDur | no | nessun valore | Un valore TimeDesignation che rappresenta un limite per la durata dei contenuti multimediali inseriti. Se la durata dei contenuti multimediali è inferiore a questo valore, la riproduzione termina in quel momento. |
| soundLevel | no | +0dB | Regola il livello del suono dell'audio di soundLevel decibel. La portata massima è +/-40 dB, ma l'intervallo effettivo potrebbe essere effettivamente inferiore e la qualità dell'output potrebbe non produrre risultati positivi su tutta la gamma. |
| fadeInDur | no | 0 sec | Un elemento TimeDesignation durante il quale i contenuti multimediali passano dalla modalità silenziosa all'elemento soundLevel specificato facoltativamente. Se la durata dei contenuti multimediali è inferiore a questo valore, la dissolvenza in entrata verrà interrotta al termine della riproduzione e il livello dell'audio non raggiungerà il livello audio specificato. |
| fadeOutDur | no | 0 sec | Un valore TimeDesignation durante il quale i contenuti multimediali scompariranno dal valore soundLevel specificato facoltativamente quando non saranno silenziati. Se la durata dei contenuti multimediali è inferiore a questo valore, il livello dell'audio viene impostato su un valore inferiore per garantire che venga raggiunto il silenzio alla fine della riproduzione. |
Specifica temporale
Una specifica temporale, utilizzata per il valore degli attributi "begin" ed "end" degli elementi <media> e dei contenitori multimediali (elementi <par> e <seq>), può essere un valore di offset (ad esempio, +2.5s) o un valore di syncbase (ad esempio, foo_id.end-250ms).
- Valore di offset. Il valore di offset di tempo è un valore di Timecount SMIL che consente valori corrispondenti all'espressione regolare:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"La stringa della prima cifra è la parte intera del numero decimale, mentre la stringa della seconda cifra è la parte decimale decimale. Il segno predefinito (ad es. "(+|-)?") è "+". I valori delle unità corrispondono rispettivamente a ore, minuti, secondi e millisecondi. L'impostazione predefinita per le unità è "s". (secondi).
- Valore Syncbase: un valore syncbase è un valore syncbase SMIL che consente valori corrispondenti all'espressione regolare:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Le cifre e le unità vengono interpretate come un valore di offset.
Simulatore di TTS
La console di Actions include un simulatore di sintesi vocale che puoi utilizzare per testare SSML con uno qualsiasi degli elementi precedenti. Il simulatore della sintesi vocale è disponibile nella console in Simulatore > Audio. Digita il testo e l'SSML nel simulatore e fai clic Aggiorna e ascolta per ascoltare l'output della sintesi vocale.
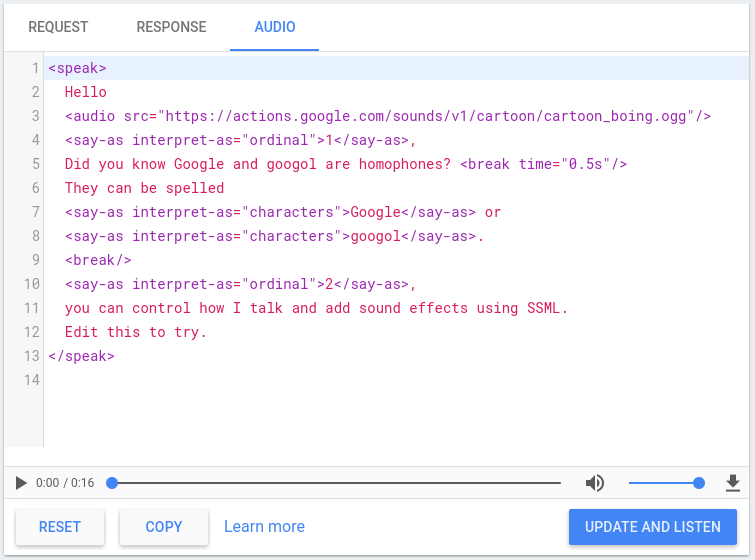
Puoi anche fare clic sul pulsante di download per salvare un file .mp3 della tua sintesi vocale
come output.