
Para mostrar una respuesta al Asistente de Google, puedes usar un subconjunto de las lenguaje de marcación de síntesis de voz (SSML) en tus respuestas. De con SSML, puedes hacer que las respuestas de la conversación parezcan más naturales voz. A continuación, se muestra un ejemplo de lenguaje de marcado de SSML y cómo se lee Asistente de Google
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.ask(ssml); }
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Audio
El SSML es compatible con el simulador de acciones, pero no con Dialogflow. simulador.
URLs en SSML
Cuando se define una respuesta de SSML que solo incluye una URL, el signo de unión en esa URL
pueden causar problemas debido al formato XML. Para asegurarte de que la URL sea
referencia, reemplaza las instancias de & por &.
Incluso si tu respuesta de SSML solo incluye una URL, Actions on Google requiere
mostrar el texto de la respuesta. Debido a que el texto dentro de la etiqueta <audio> no se
pronunciada por Asistente, puedes insertar texto de relleno o una breve descripción en tu
<audio> para cumplir con este requisito. El texto dentro de la etiqueta <audio> no se
pronunciada por Asistente después de que se reproduce el audio y cumple con la función Action on Google
para tener una versión en texto visible de tu SSML.
Este es un ejemplo de una respuesta de SSML problemática:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
En el ejemplo anterior, no se escapa el & para el formato XML adecuado.
Una versión corregida de la misma respuesta de SSML se ve de la siguiente manera:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Compatibilidad con los elementos de SSML
En las siguientes secciones, se describen los elementos y las opciones de SSML que se pueden usar en tus Acciones.
<speak>
El elemento raíz de la respuesta de SSML.
Para obtener más información sobre el elemento speak, consulta la especificación de W3.
Ejemplo
<speak> my SSML content </speak>
<break>
Un elemento vacío que controla las pausas, o bien otros límites prosódicos entre las palabras. Usar <break> entre cualquier par de tokens es opcional. Si este elemento no está presente entre las palabras, la pausa se determina automáticamente según el contexto lingüístico.
Para obtener más información sobre el elemento break, consulta la especificación de W3.
Atributos
| Atributo | Descripción |
|---|---|
time |
Establece la duración de la pausa en segundos o milisegundos (p. ej., “3 s” o “250 ms”). |
strength |
Establece la intensidad de la pausa prosódica del resultado según términos relativos. Los valores válidos son “x-weak”, “weak”, “medium”, “strong” y “x-strong”. El valor “none” (ninguna) indica que no se debe incluir ningún límite de pausa prosódica en el resultado; se puede usar para evitar una pausa prosódica que, de lo contrario, el procesador produciría. Los demás valores indican una intensidad de pausa no descendente y monótona (conceptualmente ascendente) entre los tokens. Los límites más intensos generalmente están acompañados de una pausa. |
Ejemplo
En el siguiente ejemplo, se muestra cómo usar el elemento <break> para hacer pausas entre pasos:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Con este elemento, puedes indicar información sobre el tipo de construcción de texto que contiene el elemento. También te ayuda a especificar el nivel de detalle para el procesamiento del texto contenido.
El elemento <say‑as> tiene el atributo obligatorio interpret-as, que determina cómo se pronuncia el valor. Se pueden usar los atributos opcionales format y detail según el valor interpret-as determinado.
Ejemplos
El atributo interpret-as admite los siguientes valores:
-
currencyEn el siguiente ejemplo, se expresa como “forty two dollars and one cent”. Si se omite el atributo de idioma, se usa la configuración regional actual.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneConsulta la descripción de
interpret-as='telephone'en la nota de WG sobre los valores del atributo say-as de SSML 1.0 de W3C.En el siguiente ejemplo, se expresa como “one eight zero zero two zero two one two one two”. Si se omite el atributo “google:style”, habla cero como la letra O.
En la actualidad, el atributo “google:style='zero-as-zero'” solo funciona la configuración regional en inglés.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimospell-outEn el siguiente ejemplo, se deletrea letra por letra:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateEl atributo
formates una secuencia de códigos de caracteres del campo de fecha. Los códigos de caracteres de campo admitidos enformatson {y,m,d} para el año, el mes y el día (del mes), respectivamente. Si el código del campo aparece una vez para el año, mes o día, entonces la cantidad de dígitos que se espera es 4, 2 y 2, respectivamente. Si el código del campo se repite, entonces la cantidad de dígitos que se espera es la cantidad de veces que se repite el código. Los campos en el texto de la fecha pueden separarse con puntuación o espacios.El atributo
detailcontrola el formato con el que se expresa la forma hablada de la fecha. Paradetail='1', solo son obligatorios los campos de día y uno de los campos de mes o año, aunque se pueden ingresar ambos. Esta es la configuración predeterminada cuando no se proporcionan los tres campos. Se expresa como "El {número ordinal del día} de {mes}, {año}".El siguiente ejemplo se expresa como "The tenth of September, nineteen sixty" (el diez de septiembre, mil novecientos sesenta):
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>En el siguiente ejemplo, la forma hablada se expresa como "The tenth of September" (el diez de septiembre):
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Para
detail='2', son obligatorios los campos de día, mes y año, y esta es la configuración predeterminada cuando se proporcionan los tres campos. Se expresa como “{mes} {número ordinal del día}, {año}”.En el siguiente ejemplo, se expresa como "September tenth, nineteen sixty" (septiembre diez, mil novecientos sesenta):
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersEn el siguiente ejemplo, la forma hablada se expresa como "C A N":
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalLa forma hablada del número del siguiente ejemplo es “twelve thousand three hundred forty five”, en el caso del inglés estadounidense, o “twelve thousand three hundred and forty five”, en el caso del inglés británico:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalEn el siguiente ejemplo, la forma hablada es "First" (primero):
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionEn el siguiente ejemplo, la forma hablada se expresa como "five and a half" (cinco y medio):
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveobleepEn el siguiente ejemplo, se escucha un “pip”, como si la palabra estuviera censurada:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitConvierte las unidades en singular o plural según el número. En el siguiente ejemplo, la forma hablada se expresa como "10 feet" (10 pies):
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeEn el siguiente ejemplo, se expresa como "Two thirty P.M." (dos treinta p.m.):
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>El atributo
formates una secuencia de códigos de caracteres de campo de hora. Los códigos de caracteres de campo admitidos enformatson {h,m,s,Z,12,24} para la hora, los minutos (de la hora), los segundos (del minuto), la zona horaria, el formato de 12 horas y de 24 horas, respectivamente. Si el código del campo aparece una vez para la hora, los minutos o los segundos, la cantidad de dígitos que se espera es 1, 2 y 2, respectivamente. Si el código del campo se repite, entonces la cantidad de dígitos que se espera es la cantidad de veces que se repite el código. Los campos en el texto de la hora pueden separarse con puntuación o espacios. Si no se especifican la hora, los minutos o los segundos en el formato o si los dígitos no coinciden, el campo se trata como si tuviera valor cero. El valor predeterminado paraformates “hms12”.El atributo
detailcontrola si se usa el formato de 12 o 24 horas para la forma hablada de la hora. El formato hablado será de 24 horas si se usadetail='1'o si se omitedetaily el formato de la hora es de 24 horas. El formato hablado será de 12 horas si se usadetail='2'o si se omitedetaily el formato de la hora es de 12 horas.
Para obtener más información sobre el elemento say-as, consulta la especificación de W3.
<audio>
Admite la inserción de archivos de audio grabado y la inserción de otros formatos de audio junto con el resultado de voz sintetizada.
Atributos
| Atributo | Obligatorio | Valor predeterminado | Valores |
|---|---|---|---|
src |
Sí | No corresponde | Un URI que hace referencia a la fuente de audio multimedia. El protocolo admitido es https. |
clipBegin |
No | 0 | Una designación de tiempo que es el desplazamiento desde el inicio del audio de origen en el cual se debe iniciar la reproducción. Si este valor es mayor o igual que la duración real del audio de origen, entonces no se inserta ningún audio. |
clipEnd |
No | infinito | Una designación de tiempo que es el desplazamiento desde el inicio del audio de origen en el cual se debe finalizar la reproducción. Si la duración real del audio de origen es menor que este valor, entonces la reproducción finalizará en ese momento. Si clipBegin es mayor o igual que clipEnd, entonces no se inserta ningún audio. |
speed |
No | 100% | La tasa proporcional de velocidad de reproducción del resultado en relación con la velocidad de entrada normal expresada como un porcentaje. El formato es un número real positivo seguido de %. El rango admitido actualmente es [50% (lento - velocidad media), 200% (rápido - doble de velocidad)]. Los valores que se encuentren fuera de este intervalo se podrán ajustar (o no) para que se incluyan en él. |
repeatCount |
No | 1 o 10 si se configura repeatDur |
Un número real que especifica cuántas veces se debe insertar el audio (después del recorte, si corresponde, con clipBegin o clipEnd). Las repeticiones fraccionarias no son compatibles, por lo que el valor se redondeará al número entero más cercano. Cero no es un valor válido y, por consiguiente, se trata como sin especificar y se usa el valor predeterminado en ese caso. |
repeatDur |
No | infinito | Una designación de tiempo que es un límite de la duración del audio insertado después de procesar la fuente para los atributos clipBegin, clipEnd, repeatCount y speed (en lugar de la duración normal de la reproducción). Si la duración del audio procesado es menor que este valor, entonces la reproducción finalizará en ese momento. |
soundLevel |
No | +0dB | Ajusta el nivel de sonido del audio en decibeles de soundLevel. El intervalo máximo es de +/-40dB, pero el real puede ser, en efecto, menor, y la calidad del resultado puede no ser buena en el intervalo total. |
A continuación, se definen las opciones de configuración que se admiten para el audio en la actualidad:
- Formato: MP3 (MPEG v2)
- 24,000 muestras por segundo
- Entre 24,000 y 96,000 bits por segundo, tasa fija
- Formato: Opus en Ogg
- 24,000 muestras por segundo (súper banda ancha)
- De 24,000 a 96,000 bits por segundo, tasa fija
- Formato (obsoleto): WAV (RIFF)
- PCM de 16 bits con signo y de tipo "little endian"
- 24,000 muestras por segundo
- Para todos los formatos:
- Se prefiere el uso de un solo canal, pero se acepta el formato estéreo.
- La duración máxima es de 240 segundos. Si deseas reproducir audio con una duración más prolongada, evalúa implementar una respuesta multimedia.
- El límite de tamaño de los archivos es de 5 megabytes.
- La URL de origen debe usar el protocolo HTTPS.
- Nuestro UserAgent cuando se obtiene el audio es "Google-Speech-Actions".
El contenido del elemento <audio> es opcional y se usa si el archivo de audio no se puede reproducir o si el dispositivo de salida no admite audio. Puede incluir un elemento <desc>, en cuyo caso el contenido de texto de ese elemento se utiliza para mostrarse. Consulta la sección de audio grabado de la lista de tareas para las respuestas a fin de obtener más información.
La URL src también debe ser una URL HTTPS (Google Cloud Storage puede alojar tus archivos de audio en una URL HTTPS).
Para obtener más información acerca de las respuestas multimedia, consulta la sección correspondiente de la guía de respuestas.
Para obtener más información sobre el elemento audio, consulta la especificación de W3.
Ejemplo
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Elementos de la oración y el párrafo.
Para obtener más información sobre los elementos p y s, consulta la especificación W3.
Ejemplo
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Prácticas recomendadas
- Usa etiquetas <s>...</s> para unir oraciones completas, especialmente si contienen elementos de SSML que cambian la prosodia (es decir, <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> y <sub>).
- Si se pretende que una pausa en el discurso sea lo suficientemente larga para percibirla, usa las etiquetas <s>...</s> y coloca esa pausa entre oraciones.
<sub>
Indica que el texto en el valor de atributo alias reemplaza al texto contenido para la pronunciación.
También puedes usar el elemento sub para proporcionar una pronunciación simplificada de una palabra difícil de leer. Con el último ejemplo que aparece a continuación, se demuestra este caso práctico en japonés.
Para obtener más información sobre el elemento sub, consulta la especificación de W3.
Ejemplos
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Un elemento vacío que coloca un marcador en la secuencia de texto o etiquetas. Se puede usar para hacer referencia a una ubicación específica en la secuencia o para insertar un marcador en una transmisión de salida para notificaciones asíncronas.
Para obtener más información sobre el elemento mark, consulta la especificación de W3.
Ejemplo
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
.
<prosody>
Se usa para personalizar el tono de la voz, la velocidad del habla y el volumen del texto que contiene el elemento. Actualmente, se admiten los atributos rate, pitch y volume.
Los atributos rate y volume se pueden configurar de acuerdo con las especificaciones de W3. Existen tres opciones para configurar el valor del atributo pitch, que se indican a continuación:
| Atributo | Descripción |
|---|---|
name |
El ID de la string de cada marca. |
| Opción | Descripción |
|---|---|
| Relativo | Especifica un valor relativo (p. ej., “bajo”, “medio”, “alto”, etc.), en el que “medio” es el tono predeterminado. |
| Semitonos | Aumenta o disminuye la afinación en “N” semitonos con “+Nst” o “-Nst”, respectivamente. Ten en cuenta que “+/-” y “st” son obligatorios. |
| Porcentaje | Aumenta o disminuye el tono en porcentaje de “N” con “+N%” o “-N%”, respectivamente. Ten en cuenta que el signo “%” es obligatorio, pero “+/-” es opcional. |
Para obtener más información sobre el elemento prosody, consulta la especificación de W3.
Ejemplo
En el siguiente ejemplo, se usa el elemento <prosody> para hablar lentamente a 2 semitonos por debajo de lo normal:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Se usa para agregar o quitar énfasis al texto que contiene el elemento. El elemento <emphasis> modifica el discurso de manera similar a <prosody>, pero sin la necesidad de establecer atributos de voz individuales.
Este elemento acepta un atributo de “nivel” opcional con los siguientes valores válidos:
strongmoderatenonereduced
Para obtener más información sobre el elemento emphasis, consulta la especificación de W3.
Ejemplo
En el siguiente ejemplo, se usa el elemento <emphasis> para hacer un anuncio:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Un contenedor multimedia paralelo que te permite reproducir varios elementos multimedia a la vez. El único contenido permitido es un conjunto de uno o más elementos <par>, <seq> y <media>. El orden de los elementos <media> no es importante.
A menos que un elemento secundario especifique un tiempo de inicio diferente, el tiempo de inicio implícito del elemento es el mismo que el del contenedor <par>. Si un elemento secundario tiene un valor de desplazamiento configurado para su atributo begin o end, el desplazamiento del elemento estará relacionado con el tiempo de inicio del contenedor <par>. Para el elemento raíz <par>, el atributo begin se ignora y el tiempo de inicio será cuando el proceso de síntesis de voz SSML comience a generar resultados para el elemento raíz <par> (es decir, en efecto, tiempo “cero”).
Ejemplo
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Un contenedor multimedia secuencial con el que puedes reproducir elementos multimedia uno detrás de otro. El único contenido permitido es un conjunto de uno o más elementos <seq>, <par> y <media>. El orden de los elementos multimedia será el orden en el que se procesen.
Los atributos begin y end de los elementos secundarios se pueden configurar como valores de desplazamiento (consulta la sección de Especificación de tiempos, a continuación). Los valores de desplazamiento de esos elementos secundarios estarán relacionados con el final del elemento anterior en la secuencia o, en el caso del primer elemento de la secuencia, con el comienzo de su contenedor <seq>.
Ejemplo
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Representa una capa multimedia en un elemento <par> o <seq>. El contenido permitido de un elemento <media> es un elemento de SSML <speak> o <audio>. La siguiente tabla describe los atributos válidos de un elemento <media>.
Atributos
| Atributo | Obligatorio | Valor predeterminado | Valores |
|---|---|---|---|
| xml:id | No | ningún valor | Un identificador XML único para este elemento. Las entidades codificadas no son compatibles. Los valores de identificador permitidos coinciden con la expresión regular "([-_#]|\p{L}|\p{D})+". Consulta XML-ID para obtener más información. |
| begin | No | 0 | El tiempo de inicio de este contenedor multimedia. Se ignora si es un elemento de contenedor multimedia raíz (y se trata igual que el valor predeterminado “0”). Consulta la sección de Especificación de tiempos que se encuentra a continuación para ver los valores de string válidos. |
| end | No | ningún valor | Una especificación para el tiempo de finalización de este contenedor multimedia. Consulta la sección de Especificación de tiempos que se encuentra a continuación para ver los valores de string válidos. |
| repeatCount | No | 1 | Un número real que especifica cuántas veces se debe insertar el elemento multimedia. No se admiten fracciones en las repeticiones, de manera que el valor se redondeará al número entero más cercano. Cero no es un valor válido y, por consiguiente, se trata como sin especificar y se usa el valor predeterminado en ese caso. |
| repeatDur | No | ningún valor | Una designación de tiempo que es el límite de duración del elemento multimedia insertado. Si la duración del elemento multimedia es menor que este valor, entonces la reproducción finalizará en ese momento. |
| soundLevel | No | +0dB | Ajusta el nivel de sonido del audio en decibeles de soundLevel. El intervalo máximo es de +/-40dB, pero el real puede ser, en efecto, menor, y la calidad del resultado puede no ser buena en el intervalo total. |
| fadeInDur | No | 0s | Una designación de tiempo durante la cual el elemento multimedia aparecerá gradualmente desde el silencio hasta el soundLevel especificado de forma opcional. Si la duración del elemento multimedia es menor que este valor, la aparición gradual se detendrá al final de la reproducción y el nivel de sonido no alcanzará el nivel de sonido especificado. |
| fadeOutDur | No | 0s | Una designación de tiempo durante la cual el elemento multimedia desaparecerá gradualmente del soundLevel especificado de forma opcional, hasta el silencio. Si la duración del elemento multimedia es menor que este valor, el nivel de sonido se establece en un valor más bajo para garantizar que se alcance el silencio al final de la reproducción. |
Especificación de tiempo
Una especificación de tiempo, que se usa para el valor de los atributos “begin” y “end” de elementos <media> y contenedores multimedia (elementos <par> y <seq>), es un valor de desplazamiento (por ejemplo, +2.5s) o un valor syncbase (por ejemplo, foo_id.end-250ms).
- Valor de desplazamiento: El valor de desplazamiento de tiempo (offset) es un “Timecount-value” de SMIL (lenguaje de integración multimedia sincronizada) que acepta valores que coinciden con la expresión regular:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"La primera string de dígitos es la parte entera del número decimal y la segunda string de dígitos es la fracción del decimal. El signo predeterminado (es decir, “(+|-)?”) es “+”. Los valores unitarios corresponden a horas, minutos, segundos y milisegundos, respectivamente. La configuración predeterminada para las unidades es "s" (segundos).
- Valor syncbase: Un valor syncbase es un valor de syncbase de SMIL que permite valores que coinciden con la expresión regular:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Los dígitos y las unidades se interpretan de la misma manera que con un valor de desplazamiento.
Simulador de TTS
La Consola de Actions incluye un simulador de TTS que puedes usar para probar el SSML. con cualquiera de los elementos anteriores. El simulador de TTS se encuentra en la consola en Simulador > Audio. Ingresa el texto y el SSML en el simulador, y haz clic en Actualizar y escuchar para escuchar la salida de TTS.
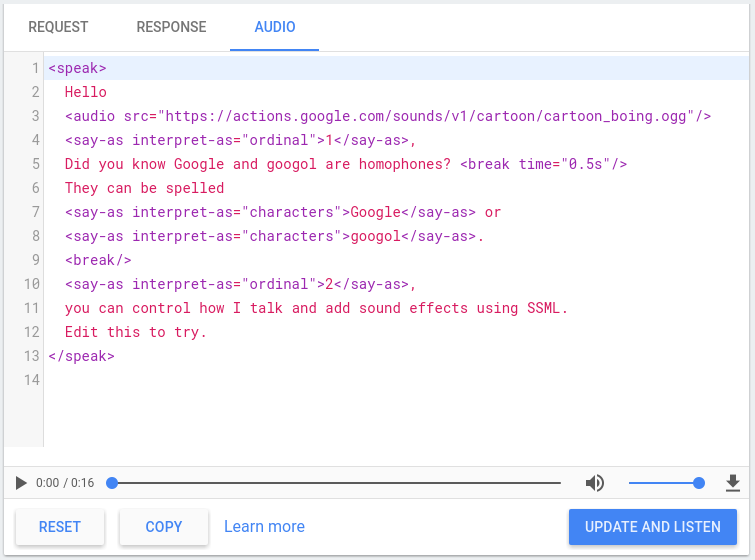
También puedes hacer clic en el botón de descarga para guardar un archivo .mp3 de tu TTS.
salida.