本頁面介紹 Custom Search JSON API 的 XML 版本,僅供 Google 站內搜尋客戶使用。
總覽
Google 網路搜尋服務可讓 Google 站內搜尋客戶在自家網站上顯示 Google 搜尋結果。WebSearch 服務使用簡單的 HTTP 型通訊協定來提供搜尋結果。搜尋管理員可全權控管搜尋結果的請求方式,以及向使用者呈現這些結果的方式。這份文件說明 Google 搜尋要求和結果格式的技術細節。
如要擷取 Google 網頁搜尋結果,應用程式會傳送簡單的 HTTP 要求給 Google,Google 接著會以 XML 格式傳回搜尋結果。XML 格式的結果可讓您自訂搜尋結果的顯示方式。
WebSearch 請求格式
請求總覽
Google 搜尋要求是標準的 HTTP GET 指令,其中包含與查詢相關的一組參數。這些參數會以 name=value 組合的形式加入要求網址,並以連字號 (&) 字元分隔。參數包括搜尋查詢等資料,以及可識別發出 HTTP 要求的引擎的專屬引擎 ID (cx)。WebSearch 或圖片搜尋服務會傳回 XML 結果,做為 HTTP 要求的回應。
查詢字詞
大多數搜尋要求都包含一或多個查詢字詞。查詢字詞會顯示為搜尋要求中參數的值。
查詢字詞可以指定多種資訊,用來篩選及整理 Google 傳回的搜尋結果。查詢可以指定:
- 要納入或排除的字詞或片語
- 搜尋查詢中的所有字詞 (預設)
- 搜尋查詢中的確切詞組
- 搜尋查詢中的任何字詞或詞組
- 文件中的哪個位置會顯示搜尋字詞
- 文件中的任何位置 (預設)
- 僅限文件中的連結
- 文件本身的限制
- 包含或排除特定檔案類型 (例如 PDF 檔案或 Word 文件) 的文件
- 特殊網址查詢,可傳回特定網址的相關資訊,而非執行搜尋。
- 查詢網址的一般資訊,例如開放目錄類別、摘要或語言
- 查詢會傳回一組連結至網址的網頁
- 查詢:傳回與指定網址相似的一組網頁
預設搜尋
搜尋查詢參數值必須經過網址逸出處理。請注意,您會將搜尋查詢中的任何空白字元序列替換為加號「+」。本文的「網址逸出」一節會進一步說明這點。
搜尋查詢字詞會透過 q 參數提交至 WebSearch 服務。搜尋查詢字詞範例:
q=horses+cows+pigs
根據預設,Google WebSearch 服務只會傳回包含搜尋查詢中所有字詞的文件。
要求參數
本節列出發出搜尋要求時可使用的參數。這些參數分為兩份清單。第一份清單包含與所有搜尋要求相關的參數。第二份清單包含僅與進階搜尋要求相關的參數。
您必須提供三個要求參數:
- client 參數必須設為
google-csbe - output 參數會指定傳回的 XML 結果格式;結果可以傳回 (xml),也可以不傳回 (
xml_no_dtd) Google DTD 的參照。建議將這個值設為xml_no_dtd。注意:如果未指定這個參數,系統會以 HTML 格式傳回結果,而非 XML。
- 代表引擎專屬 ID 的 cx 參數。
除了上述參數外,最常用的要求參數如下:
WebSearch 查詢範例
以下範例顯示幾項 WebSearch HTTP 要求,說明如何使用不同的查詢參數。本文的「網頁搜尋查詢參數定義」和「進階搜尋查詢參數」章節,提供不同查詢參數的定義。
這項要求會針對查詢字詞「red sox」q=red+sox,要求前 10 項結果 start=0&num=10。查詢也會指定結果應來自加拿大網站 cr=countryCA,且應以法文撰寫 lr=lang_fr。最後,查詢會指定 client、output 和 cx 參數的值,這三項參數都是必要參數。
http://www.google.com/search?
start=0
&num=10
&q=red+sox
&cr=countryCA
&lr=lang_fr
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
這個範例使用部分進階搜尋查詢參數,進一步自訂搜尋查詢。這項要求使用 as_q 參數 (as_q=red+sox) 而非 q 參數。此外,這項要求也使用 as_eq 參數,從搜尋結果中排除任何含有「Yankees」一詞的文件 (as_eq=yankees)。
http://www.google.com/search?
start=0
&num=10
&as_q=red+sox
&as_eq=Yankees
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
WebSearch 查詢參數定義
| c2coff | |||||||
|---|---|---|---|---|---|---|---|
| 說明 | (選用) c2coff 參數可啟用或停用「簡體和繁體中文搜尋」功能。 這個參數的預設值為
|
||||||
| 範例 | q=google&c2coff=1 |
||||||
| 用戶端 | |
|---|---|
| 說明 | 必填。 |
| 範例 | q=google&client=google-csbe |
| cr | |
|---|---|
| 說明 | (選用) Google WebSearch 會分析以下項目,判斷文件國家/地區:
如需這個參數的有效值清單,請參閱「國家/地區 (cr) 參數值」一節。 |
| 範例 | q=Frodo&cr=countryNZ |
| cx | |
|---|---|
| 說明 | 必填。 |
| 範例 | q=Frodo&cx=00255077836266642015:u-scht7a-8i |
| 篩選 | |||||||
|---|---|---|---|---|---|---|---|
| 說明 | (選用) filter 參數會啟用或停用 Google 搜尋結果的自動篩選功能。如要進一步瞭解 Google 搜尋結果篩選器,請參閱這份文件的「自動篩選」一節。
注意:根據預設,Google 會對所有搜尋結果套用篩選條件,以提升搜尋結果品質。 |
||||||
| 範例 | q=google&filter=0 |
||||||
| gl | |
|---|---|
| 說明 | (選用) 在 WebSearch 要求中指定 |
| 範例 | 這項要求會提升英國撰寫的文件在網頁搜尋結果中的排名: |
| hl | |
|---|---|
| 說明 | (選用) 如要瞭解詳情,請參閱「查詢和結果呈現方式國際化」一文的「介面語言」部分,如需支援的語言清單,請參閱「支援的介面語言」。 |
| 範例 | 這項要求指定以法文顯示葡萄酒廣告。(Vin 是法文的葡萄酒。) q=vin&ip=10.10.10.10&ad=w5&hl=fr |
| hq | |
|---|---|
| 說明 | (選用) |
| 範例 | 這項要求會搜尋「pizza」和「cheese」。這個運算式與
|
| ie | |
|---|---|
| 說明 | (選用) 如要瞭解何時可能需要使用這個參數,請參閱「字元編碼」一節。 如需可能的 |
| 範例 | q=google&ie=utf8&oe=utf8 |
| lr | |
|---|---|
| 說明 | (選用) Google WebSearch 會分析以下項目,判斷文件語言:
|
| 範例 | q=Frodo&lr=lang_en |
| num | |
|---|---|
| 說明 | (選用) 預設 注意:如果搜尋結果總數少於要求的結果數,系統會傳回所有可用的搜尋結果。 |
| 範例 | q=google&num=10 |
| oe | |
|---|---|
| 說明 | (選用) 如要瞭解何時可能需要使用這個參數,請參閱「字元編碼」一節。 如需可能的 |
| 範例 | q=google&ie=utf8&oe=utf8 |
| output | |||||||
|---|---|---|---|---|---|---|---|
| 說明 | 必填。
|
||||||
| 範例 | output=xml_no_dtd |
||||||
| q | |
|---|---|
| 說明 | (選用) 此外,您也可以使用多個特殊查詢字詞,做為 Google 搜尋控制面板會提供報表,列出使用 注意:為 q 參數指定的值必須經過網址逸出。 |
| 範例 | q=vacation&as_oq=london+paris |
| 安全 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 說明 | (選用)
如要進一步瞭解這項功能,請參閱「使用安全搜尋篩選成人內容」一節。 |
||||||||
| 範例 | q=adult&safe=high |
||||||||
| start | |
|---|---|
| 說明 | (選用)
|
| 範例 | start=10 |
| 排序 | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
| ud | |
|---|---|
| 說明 | (選用) http://www.花井鮨.com 這個參數的有效值為 如果 http://www.xn--elq438j.com. 注意:這項功能目前為 Beta 版。 |
| 範例 | q=google&ud=1 |
進階搜尋
圖片下方列出的額外查詢參數與進階搜尋查詢相關。 提交進階搜尋時,系統會將多個參數 (例如 as_eq、as_epq、as_oq 等) 的值納入該搜尋的查詢字詞。圖片:顯示 Google 進階搜尋頁面。在圖片中,每個進階搜尋參數的名稱都以紅色文字標示在網頁上對應的欄位內或旁邊。
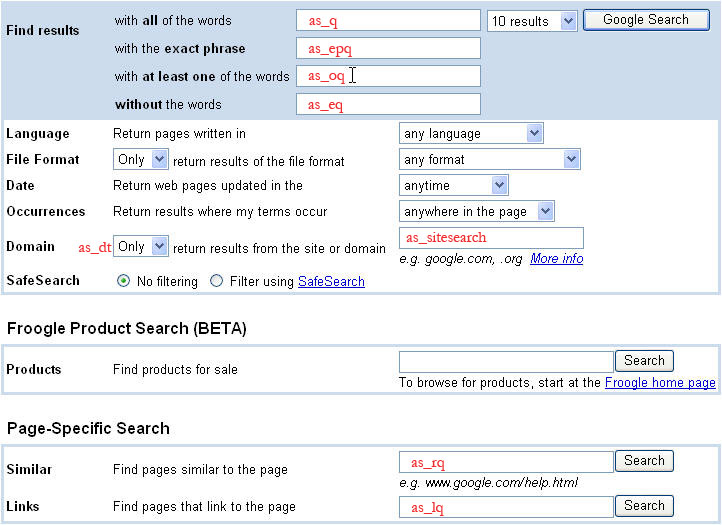
進階搜尋查詢參數
| as_dt | |
|---|---|
| 說明 | (選用) |
| 範例 | as_dt=i,as_dt=e |
| as_epq | |
|---|---|
| 說明 | (選用) |
| 範例 | as_epq=abraham+lincoln |
| as_eq | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
| as_lq | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
| as_nlo | |
|---|---|
| 說明 | (選用) |
| 範例 | 以下範例會將搜尋範圍設為 5 到 10 (含首尾):
|
| as_nhi | |
|---|---|
| 說明 | (選用) |
| 範例 | 以下範例會將搜尋範圍設為 5 到 10 (含首尾):
|
| as_oq | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
| as_q | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
| as_qdr | |
|---|---|
| 說明 | (選用)
|
| 範例 |
這個範例會要求過去一年的結果:
這個範例會要求過去 10 天的結果:
|
| as_sitesearch | |
|---|---|
| 說明 | (選用) |
| 範例 |
|
特殊查詢字詞
Google 網頁搜尋支援多種特殊查詢字詞,可存取 Google 搜尋引擎的額外功能。這些特殊查詢字詞應包含在 q 要求參數的值中。與其他查詢字詞一樣,特殊查詢字詞必須經過 URL 逸出。許多特殊查詢字詞都含有半形冒號 (:)。這個字元也必須經過網址逸出,逸出值為 %3A。
| 反向連結 [link:] | |
|---|---|
| 說明 |
您也可以使用 as_lq 要求參數提交 注意:使用 |
| 範例 |
|
| 布林值 OR 搜尋 [ OR ] | |
|---|---|
| 說明 |
您也可以使用 as_oq 要求參數,針對一組字詞中的任何字詞提交搜尋要求。 注意:如果搜尋要求指定查詢「London+OR+Paris」,搜尋結果會包含至少含有這兩個字詞之一的文件。在某些情況下,搜尋結果中的文件可能同時含有這兩個字詞。 |
| 範例 | 搜尋倫敦或巴黎: 使用者輸入內容:
london OR
paris 查詢字詞:q=london+OR+paris搜尋「度假」和「倫敦」或「巴黎」: 查詢字詞:
q=vacation+london+OR+paris搜尋「度假」和「倫敦」、「巴黎」或「巧克力」其中一項: 查詢字詞:
q=vacation+london+OR+paris+OR+chocolates搜尋「vacation」和「chocolates」,以及「london」或「paris」,並將「chocolates」的權重設為最低: 查詢字詞:
q=vacation+london+OR+paris+chocolates在同時包含「倫敦」或「巴黎」的文件中,搜尋「度假」、「巧克力」和「花朵」: 查詢字詞:
q=vacation+london+OR+paris+chocolates+flowers搜尋「度假」和「倫敦」或「巴黎」,以及「巧克力」或「鮮花」: 查詢字詞: q=vacation+london+OR+paris+chocolates+OR+flowers |
| 排除查詢字詞 [-] | |
|---|---|
| 說明 | 排除 (
如果搜尋字詞有多種含意,排除查詢字詞就非常實用。舉例來說,搜尋「bass」一字可能會傳回魚類或音樂的結果。如果您要尋找魚類相關文件,可以使用排除查詢字詞,從搜尋結果中排除音樂相關文件。 您也可以使用 as_eq 要求參數,從搜尋結果中排除與特定字詞或詞組相符的文件。 |
| 範例 | 使用者輸入內容: bass -music查詢字詞: q=bass+%2Dmusic |
| 排除檔案類型 [ -filetype: ] | |
|---|---|
| 說明 |
注意:如要從搜尋結果中排除多個檔案類型,請在查詢中加入更多 Google 支援的檔案類型包括:
日後或許會開放支援更多檔案類型。如需最新清單,請參閱 Google 的檔案類型常見問題。 |
| 範例 | 這個範例會傳回提及「Google」但不是 PDF 文件的文件: 這個範例會傳回提及「Google」的文件,但排除 PDF 和 Word 文件: |
| 檔案類型篩選 [ filetype: ] | |
|---|---|
| 說明 |
如要將搜尋結果限制為符合特定副檔名的文件,請在查詢中加入更多 根據預設,搜尋結果會包含任何副檔名的文件。 Google 支援的檔案類型包括:
日後或許會開放支援更多檔案類型。如需最新清單,請參閱 Google 的檔案類型常見問題。 |
| 範例 | 這個範例會傳回提及「Google」的 PDF 文件: 這個範例會傳回提及「Google」的 PDF 和 Word 文件: |
| 包含查詢字詞 [+] | |
|---|---|
| 說明 | 如果查詢字詞包含加號 (+),表示搜尋結果中的所有文件都必須包含該字詞或詞組。如要使用必要查詢字詞,請在所有搜尋結果中必須包含的字詞或詞組前面加上「+」號。
在 Google 通常會捨棄的常見字詞前使用 |
| 範例 | 使用者輸入內容: Star Wars Episode +I查詢字詞: q=Star+Wars+Episode+%2BI |
| 只搜尋連結,所有字詞 [ allinlinks: ] | |
|---|---|
| 說明 |
如果搜尋查詢包含
|
| 範例 | 使用者輸入內容:allinlinks: Google search查詢字詞: q=allinlinks%3A+Google+search |
| 詞組搜尋 | |
|---|---|
| 說明 | 詞組搜尋 (") 查詢字詞可讓您搜尋完整詞組,方法是在詞組前後加上引號,或以連字號連結詞組。
如果您要搜尋名言或專有名詞,詞組搜尋就特別有用。 您也可以使用 as_epq 要求參數提交片語搜尋。 |
| 範例 | 使用者輸入內容:"Abraham Lincoln"查詢字詞: q=%22Abraham+Lincoln%22 |
| 網頁文件資訊 [info:] | |
|---|---|
| 說明 | 只要網址已編入 Google 搜尋索引,
注意:使用 |
| 範例 | 使用者輸入內容: info:www.google.com查詢字詞: q=info%3Awww.google.com |
圖片查詢範例
以下範例顯示幾項圖片 HTTP 要求,說明如何使用不同的查詢參數。如要瞭解不同查詢參數的定義,請參閱本文的「圖片查詢參數定義」一節。
這項要求會針對查詢字詞「monkey」(q=monkey) 索取前 5 個結果 (start=0&num=5),檔案類型為 .png。最後,查詢會為 client、output 和 cx 參數指定值,這三個參數都是必要參數。
http://www.google.com/cse? searchtype=image start=0 &num=5 &q=monkey &as_filetype=png &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
圖片搜尋查詢參數
| as_filetype | |
|---|---|
| 說明 | (選用) 傳回指定類型的圖片。允許的值為: |
| 範例 | q=google&as_filetype=png |
| imgsz | |
|---|---|
| 說明 | (選用) 傳回指定大小的圖片,大小可以是下列其中一種:
|
| 範例 | q=google&as_filetype=png&imgsz=icon |
| imgtype | |
|---|---|
| 說明 | (選用) 傳回某類型的圖片,可以是下列其中一種:
|
| 範例 | q=google&as_filetype=png&imgtype=photo |
| imgc | |
|---|---|
| 說明 | (選用) 傳回黑白、灰階或彩色圖片:
|
| 範例 | q=google&as_filetype=png&imgc=gray |
| imgcolor | |
|---|---|
| 說明 | (選用) 傳回特定主色的圖片:
|
| 範例 | q=google&as_filetype=png&imgcolor=yellow |
| as_rights | |
|---|---|
| 說明 | (選用) 依授權篩選。支援的值包括:
|
| 範例 | q=cats&as_filetype=png&as_rights=cc_attribute |
要求限制
下表列出傳送至 Google 的搜尋要求限制:
| 元件 | 限制 | 註解 |
|---|---|---|
| 搜尋要求長度 | 2048 個位元組 | |
| 查詢字詞數量 | 10 | 包括下列參數中的字詞:q、as_epq、as_eq、as_lq、as_oq、as_q |
| 結果數量 | 20 | 如果將 num 參數設為大於 20 的數字,系統只會傳回 20 個結果。如要取得更多結果,您需要傳送多個要求,並在每個要求中遞增 start 參數的值。 |
查詢和結果呈現方式的國際化
Google 網頁搜尋服務可讓您搜尋多種語言的文件。您可以指定用於解讀 HTTP 要求和編碼 XML 回應的字元編碼 (使用 ie 和 oe 搜尋參數)。您也可以篩選結果,只顯示以特定語言撰寫的文件。
以下章節將討論與多種語言搜尋相關的問題:
字元編碼
伺服器會以編碼位元組序列的形式,將網頁等資料傳送至使用者代理程式 (例如瀏覽器)。使用者代理程式接著會將位元組解碼為一連串字元。將要求傳送至 WebSearch 服務時,您可以為搜尋查詢和收到的 XML 回應指定編碼配置。
您可以使用 ie 要求參數,指定 HTTP 要求中字元的編碼機制。您也可以使用 oe 參數,指定 Google 應使用的 XML 回應編碼配置。如果您使用的編碼配置不是 ISO-8859-1 (或 latin1),請務必為 ie 和 oe 參數指定正確的值。
注意:如果您提供多種語言的搜尋功能,建議您為 ie 和 oe 參數使用 utf8 (UTF-8) 編碼值。
如需 ie 和 oe 參數可用的完整值清單,請參閱「字元編碼配置」附錄。
如要進一步瞭解字元編碼,請參閱 http://www.w3.org/TR/REC-html40/charset.html。
介面語言
您可以使用 hl 要求參數,識別圖形介面的語言。hl 參數值可能會影響 XML 搜尋結果,尤其是在未明確指定語言限制 (使用 lr 參數) 的國際查詢中。在這種情況下,hl 參數可能會提升與使用者輸入語言相同的搜尋結果。
建議您在搜尋結果中明確設定 hl 參數,確保 Google 為每個查詢選取最高品質的搜尋結果。
如需 hl 參數的有效值完整清單,請參閱「支援的介面語言」一節。
搜尋以特定語言撰寫的文件
您可以使用 lr 要求參數,將搜尋結果限制為以特定語言或一組語言撰寫的文件。
lr 參數支援布林運算子,可供您指定要納入 (或排除) 搜尋結果的多種語言。
下列範例說明如何使用布林運算子,以不同語言要求文件。
日文文件:
lr=lang_jp
如果文件是以義大利文或德文撰寫:
lr=lang_it|lang_de
如果文件不是以匈牙利文或捷克文撰寫:
lr=(-lang_hu).(-lang_cs)
如需 lr 參數的可能值完整清單,請參閱「語言集合值」一節;如要完整瞭解如何使用這些運算子,請參閱「布林運算子」一節。
簡體中文和繁體中文搜尋
簡體中文和繁體中文是中文的兩種書寫變體。同一概念在這兩種變體中可能會有不同的寫法。如果查詢使用其中一種變體,Google 網路搜尋服務可能會傳回包含兩種變體網頁的結果。
如何使用這項功能:
以下範例顯示您在要求結果時,應加入簡體中文和正體中文的查詢參數。(請注意,範例中未包含其他必要資訊,例如 client)。
search?hl=zh-CN
&lr=lang_zh-TW|lang_zh-CN
&c2coff=0篩選結果
Google 網頁搜尋提供多種方式來篩選搜尋結果:
自動篩選搜尋結果
為盡可能提供最準確的搜尋結果,Google 會使用以下兩種技術,將一般視為不適當的搜尋結果自動濾除:
-
重複的內容:如有多份文件內含相同的資訊,則搜尋結果只會納入其中最相關的文件。
-
主機密集占位:如果多筆搜尋結果來自同一個網站,Google 可能不會顯示該網站的所有結果,或顯示的結果排名會比原本低。
建議您針對一般搜尋要求啟用這些篩選器,因為篩選器可大幅提升大多數搜尋結果的品質。不過,您可以在搜尋要求中將 filter 查詢參數設為 0,略過這些自動篩選器。
語言和國家/地區篩選
Google WebSearch 服務會傳回所有網頁文件的主索引結果。主索引收錄的文件會依語言和國家/地區等特定屬性分組。
您可以使用 lr 和 cr 要求參數,將搜尋結果分別限制在以特定語言撰寫或來自特定國家/地區的文件子集合。
Google WebSearch 會分析以下項目,判斷文件語言:
- 文件網址的頂層網域 (TLD)
- 文件內的語言中繼標記
- 文件內文使用的主要語言
如要進一步瞭解如何根據語言限制結果,請參閱 lr 參數的定義、搜尋以特定語言撰寫的文件一節,以及可用做 lr 參數值的語言集合值。
Google WebSearch 會分析以下項目,判斷文件國家/地區:
- 文件網址的頂層網域 (TLD)
- 網路伺服器 IP 位址的地理位置
如要進一步瞭解如何依來源國家/地區限制結果,請參閱 cr 參數的定義,以及可做為 cr 參數值的國家/地區集合值。
注意:您可以結合語言值和國家/地區值,自訂搜尋結果。舉例來說,您可以要求系統提供以法文撰寫且來自法國或加拿大的文件,也可以要求系統提供來自荷蘭但不是以英文撰寫的文件。lr 和 cr 參數都支援布林運算子。
使用安全搜尋功能過濾成人內容
許多 Google 客戶不希望顯示含有成人內容的網站搜尋結果。使用安全搜尋篩選器,即可過濾並移除含有成人內容的搜尋結果。Google 的篩選器會使用專有技術檢查關鍵字、詞組和網址。雖然篩選器無法做到 100% 準確,但安全搜尋功能會從搜尋結果中移除絕大多數的成人內容。
Google 會持續檢索網路,並根據使用者建議進行更新,盡可能確保安全搜尋功能提供最新且最全面的資訊。
安全搜尋支援下列語言:
| 荷蘭文 英文 法文 德文 |
義大利文 葡萄牙文 (巴西) 西班牙文 繁體中文 |
您可以使用 safe 查詢參數,調整 Google 過濾成人內容的程度。下表說明 Google 的安全搜尋設定,以及這些設定對搜尋結果的影響:
| 安全搜尋等級 | 說明 |
|---|---|
| 高 | 啟用更嚴格的安全搜尋版本。 |
| 中 | 封鎖含有色情內容和其他煽情露骨內容的網頁。 |
| 關閉 | 不會從搜尋結果中濾除成人內容。 |
* 安全搜尋的預設設定為關閉。
如果啟用安全搜尋功能後,在搜尋結果中發現含有不雅內容的網站,請將該網站的網址傳送電子郵件至 safesearch@google.com,我們會調查該網站。
XML 結果
Google XML 結果 DTD
Google 會使用相同的 DTD 描述所有類型搜尋結果的 XML 格式。許多標記和屬性都適用於所有搜尋類型,但有些標記只適用於特定搜尋類型。因此,DTD 中的定義可能比本文提供的定義寬鬆。
本文說明與 WebSearch 相關的 DTD 方面。查看 DTD 時,如果您處理的是 WebSearch,可以放心忽略未在此處記錄的標記和屬性。如果 DTD 和文件中的定義不同,這份文件會註明。
Google 可以傳回 XML 結果,並視需要參照最新的 DTD。搜尋管理員和 XML 剖析器可參考 DTD,瞭解 Google 的 XML 結果。由於 Google 的 XML 文法可能會不時變更,因此您不應將剖析器設定為使用 DTD 驗證每個 XML 結果。
此外,您不應將 XML 剖析器設為每次提交搜尋要求時都擷取 DTD。Google 不常更新 DTD,這些要求會造成不必要的延遲和頻寬需求。
Google 建議使用 xml_no_dtd 輸出格式,取得 XML 結果。 如果在搜尋要求中指定 xml output 格式, XML 結果只會多出下列這行:
<!DOCTYPE GSP SYSTEM "google.dtd">如要存取最新 DTD,請前往 http://www.google.com/google.dtd。
請注意,DTD 中的部分功能目前可能無法使用或不支援。
關於 XML 回應
- 除非 XML 標記定義中另有註明,否則所有元素值都是適合顯示的有效 HTML。
- 部分元素值是網址,必須先經過 HTML 編碼,才會顯示。
- XML 剖析器應忽略未記錄的屬性和標記。這樣一來,如果 Google 在 XML 輸出中新增更多功能,應用程式就能繼續運作,不需修改。
- 在 XML 標記中加入值時,必須逸出特定字元。XML 處理器應將這些實體轉換回適當的字元。如果未正確轉換實體,瀏覽器可能會將 & 字元轉譯為「&」。XML 標準文件會說明這些字元,下表也列出這些字元:
角色 逸出形式 實體 字元代碼 連接符號 和 & & 單引號 ' ' ' 雙引號 " " " 大於 > > > 小於 < < <
一般和進階搜尋查詢的 XML 結果
一般/進階搜尋:查詢和 XML 結果範例
這個 WebSearch 要求的範例會要求提供 10 項結果 (num=10),搜尋字詞為「socer」(q=socer),也就是「soccer」(足球),這個範例故意拼錯字)。
http://www.google.com/search?
q=socer
&hl=en
&start=10
&num=10
&output=xml
&client=google-csbe
&cx=00255077836266642015:u-scht7a-8i
這項要求會產生下列 XML 結果。請注意,XML 結果中有多個註解,指出結果中未納入的特定標記會顯示在何處。
<?xml version="1.0" encoding="ISO-8859-1" standalone="no" ?>
<GSP VER="3.2">
<TM>0.452923</TM>
<Q>socer</Q>
<PARAM name="cx" value="00255077836266642015:u-scht7a-8i" original_value="00255077836266642015%3Au-scht7a-8i"/>
<PARAM name="hl" value="en" original_value="en"/>
<PARAM name="q" value="socer" original_value="socer"/>
<PARAM name="output" value="xml" original_value="xml"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe"/>
<PARAM name="num" value="10" original_value="10"/>
<Spelling>
<Suggestion q="soccer"><b><i>soccer</i></b></Suggestion>
</Spelling>
<Context>
<title>Sample Vacation CSE</title>
<Facet>
<FacetItem>
<label>restaurants</label>
<anchor_text>restaurants</anchor_text>
</FacetItem>
<FacetItem>
<label>wineries</label>
<anchor_text>wineries</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>golf_courses</label>
<anchor_text>golf courses</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>hotels</label>
<anchor_text>hotels</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>nightlife</label>
<anchor_text>nightlife</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>soccer_sites</label>
<anchor_text>soccer sites</anchor_text>
</FacetItem>
</Facet>
</Context>
<RES SN="1" EN="10">
<M>6080</M>
/*
* The FI tag after the comment indicates that the result
* set has been filtered. If the number of results were exact, the
* FI tag would be replaced by an XT tag in the same format.
*/
<FI />
<NB>
/*
* Since the request is for the first page of results, the PU tag,
* which contains a link to the previous page of search results,
* is not included in this XML result. If the sample result did include
* a previous page of results, it would be listed here, in the same format
* as the NU tag on the following line
*/
<NU>/search?q=socer&hl=en&lr=&ie=UTF-8&output=xml&client=test&start=10&sa=N</NU>
</NB>
<R N="1">
<U>http://www.soccerconnection.net/</U>
<UE>http://www.soccerconnection.net/</UE>
<T>SoccerConnection.net</T>
<CRAWLDATE>May 21, 2007</CRAWLDATE>
<S><b>soccer</b>; players; coaches; ball; world cup;<b>...</b></S>
<Label>transcodable_pages</Label>
<Label>accessible</Label>
<Label>soccer_sites</Label>
<LANG>en</LANG>
<HAS>
<DI>
<DT>SoccerConnection.net</DT>
<DS>Post your <b>soccer</b> resume directly on the Internet.</DS>
</DI>
<L/>
<C SZ="8k" CID="kWAPoYw1xIUJ"/>
<RT/>
</HAS>
</R>
/*
* The result includes nine more results, each enclosed by an R tag.
*/
</RES>
</GSP>
一般/進階搜尋:XML 標記
一般搜尋要求和進階搜尋要求的 XML 回應都使用同一組 XML 標記。這些 XML 標記顯示在上述 XML 範例中,並說明於下表。
以下 XML 標記依標記名稱的字母順序排列,每個標記定義都包含標記說明、顯示標記在 XML 結果中樣貌的範例,以及標記內容的格式。如果標記是另一個 XML 標記的子標記,或標記本身有子標記或屬性,這些資訊也會提供在標記的定義表格中。
在下列定義中,部分子標記旁可能會顯示特定符號。這些符號和它們的意義分別是:
* = 零或多個子標記執行個體
+ = 一或多個子標記執行個體
| A | B | C | D 鍵 | 週五 | G | H | I | L | M | N | P | Q | R 鍵 | S | 望遠 | U | X |
| anchor_text | |
|---|---|
| 定義 | <anchor_text> 標記會指定要向使用者顯示的文字,用來識別與搜尋結果集相關聯的精選標籤。由於精選標籤會以底線取代非英數字元,因此您不應在使用者介面中顯示 <label> 標記的值,而應顯示 <anchor_text> 標記的值。 |
| 範例 | <anchor_text>高爾夫球場</anchor_text> |
| 子標記主體 | FacetItem |
| 內容格式 | 文字 |
| 封鎖 | |
|---|---|
| 定義 | 這個標記會將宣傳結果主體行中的區塊內容封裝起來。每個區塊都有子標記 T、U 和 L。非空白的 T 標記表示區塊含有文字;非空白的 U 和 L 標記表示區塊含有連結 (網址位於 U 子標記中,錨定文字位於 L 子標記中)。 |
| 子標記 | T、U、L |
| 子標記主體 | BODY_LINE |
| 內容格式 | 空白 |
| BODY_LINE | |
|---|---|
| 定義 | 這個標記會封裝宣傳結果內文中的一行內容。每個主體行都包含數個 BLOCK 標記,其中包含一些文字或含有網址和錨點文字的連結。 |
| 子標記 | BLOCK* |
| 子標記主體 | SL_MAIN |
| 內容格式 | 空白 |
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定義 | <C> 標記表示 WebSearch 服務可以擷取這個搜尋結果網址的快取版本。您無法透過 XML API 擷取快取頁面,但可以將使用者重新導向至 www.google.com,查看這項內容。 |
|||||||||
| 屬性 |
|
|||||||||
| 範例 | <C SZ="6k" CID="kvOXK_cYSSgJ" /> | |||||||||
| 子標記主體 | HAS | |||||||||
| 內容格式 | 空白 | |||||||||
| C2C | |
|---|---|
| 定義 | <C2C> 標記表示結果是指繁體中文網頁。只有在啟用「簡體和繁體中文搜尋」時,才會顯示這個標記。如要進一步瞭解如何啟用及停用這項功能,請參閱 c2coff 查詢參數定義。 |
| 內容格式 | 文字 |
| 背景資訊 | |
|---|---|
| 定義 | <Context> 標記會封裝與一組搜尋結果相關聯的精選標籤清單。 |
| 範例 | <Context> |
| 子標記 | title、Facet+ |
| 內容格式 | 容器 |
| CRAWLDATE | |
|---|---|
| 定義 | <CRAWLDATE> 標記會指出網頁上次檢索的日期。並非每個搜尋結果頁面都會傳回 |
| 範例 | <CRAWLDATE>2005 年 5 月 21 日</CRAWLDATE> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 |
| DI | |
|---|---|
| 定義 | <DI> 標記會封裝單一搜尋結果的開放式目錄專案 (ODP) 類別資訊。 |
| 範例 | <DI> |
| 子標記 | DT?DS? |
| 子標記主體 | HAS |
| 內容格式 | 空白 |
| DS | |
|---|---|
| 定義 | <DS> 標記會提供 ODP 目錄中單一類別的摘要。 |
| 範例 | <DS>直接在網路上發布你的<b>足球</b>履歷。</DS> |
| 子標記主體 | DI |
| 內容格式 | 文字 (可能含有 HTML) |
| DT | |
|---|---|
| 定義 | <DT> 標記會提供 ODP 目錄中列出的單一類別標題。 |
| 範例 | <DT>SoccerConnection.net</DT> |
| 子標記主體 | DI |
| 內容格式 | 文字 (可能含有 HTML) |
| facet | |
|---|---|
| 定義 | <Facet> 標記包含 <FacetItem> 標記的邏輯分組。您可以使用可程式化搜尋引擎引擎 XML 規格格式建立這些分組。如果未建立這些分組,results_xml_tag_Context><Context> 標記最多會包含四個 <Facet> 標記。每個 <Facet> 標記中的項目會分組顯示,但可能沒有邏輯關係。 |
| 範例 | <Facet> |
| 子標記 | FacetItem+、title+ |
| 子標記主體 | 背景資訊 |
| 內容格式 | 容器 |
| FacetItem | |
|---|---|
| 定義 | <FacetItem> 標記內含與一組搜尋結果相關聯的精選標籤資訊。 |
| 範例 | <FacetItem> |
| 子標記 | label、anchor_text+ |
| 子標記主體 | Facet |
| 內容格式 | FacetItem |
| FI | |
|---|---|
| 定義 | <FI> 標記會做為旗標,指出搜尋是否已執行文件篩選作業。如要進一步瞭解 Google 搜尋結果篩選器,請參閱本文的「自動篩選」一節。 |
| 範例 | <FI /> |
| 子標記主體 | RES |
| 內容格式 | 空白 |
| GSP | |||||||
|---|---|---|---|---|---|---|---|
| 定義 | <GSP> 標記會封裝 Google XML 搜尋結果中傳回的所有資料。「GSP」是「Google 搜尋通訊協定」的縮寫。 |
||||||
| 屬性 |
|
||||||
| 範例 | <GSP VER="3.2"> | ||||||
| 子標記 | PARAM+, Q, RES?, TM | ||||||
| 內容格式 | 空白 | ||||||
| HAS | |
|---|---|
| 定義 | <HAS> 標記會封裝特定網址支援的任何特殊搜尋要求參數相關資訊。 注意:WebSearch 的 <HAS> 定義比 DTD 更嚴格。 |
| 子標記 | DI?L?C?RT? |
| 子標記主體 | R 鍵 |
| ISURL | |
|---|---|
| 定義 | 如果相關聯的搜尋查詢是網址,Google 會傳回 <ISURL> 標記。 |
| 子標記主體 | GSP |
| 內容格式 | 空白 |
| L | |
|---|---|
| 定義 | 如果出現 <L> 標記,表示 WebSearch 服務可以找到連結至這項搜尋結果網址的其他網站。如要尋找這類網站,請使用 link: 特殊查詢字詞。 |
| 子標記主體 | HAS |
| 內容格式 | 空白 |
| 標籤 | |
|---|---|
| 定義 | <label> 標記會指定精選標籤,可用於篩選收到的搜尋結果。如要使用精選標籤,請將字串 more:[[label tag value]] 新增至 Google HTTP 要求中的 q 參數值,如下例所示。請注意,將查詢傳送至 Google 前,必須先對這個值進行網址逸出處理。 This example uses the refinement label golf_courses to 注意:<label> 標記與 <Label> 標記不同,後者會識別與搜尋結果中特定網址相關聯的精選標籤。 |
| 範例 | <label>golf_courses</label> |
| 子標記主體 | FacetItem |
| 內容格式 | 文字 |
| LANG | |
|---|---|
| 定義 | <LANG> 標記包含 Google 對搜尋結果語言的最佳猜測。 |
| 範例 | <LANG>en</LANG> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 |
| M | |
|---|---|
| 定義 | <M> 標記會指出搜尋的預估結果總數。 注意: 這項預估值可能不準確。 |
| 範例 | <M>16200000</M> |
| 子標記主體 | RES |
| 內容格式 | 文字 |
| 新生兒 | |
|---|---|
| 定義 | <NB> 代碼會封裝結果集的導覽資訊,包括搜尋結果的下一頁或上一頁連結。 注意:只有在有更多結果時,系統才會顯示這個標記。 |
| 範例 | <NB> |
| 子標記 | NU?PU? |
| 子標記主體 | RES |
| 內容格式 | 空白 |
| NU | |
|---|---|
| 定義 | <NU> 代碼包含下一頁搜尋結果的相對連結。 |
| 範例 | <NU>/search?q=flowers&num=10&hl=en&ie=UTF-8 &output=xml&client=test&start=10</NU> |
| 子標記主體 | NB |
| 內容格式 | 文字 (相對網址) |
| PARAM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 定義 | <PARAM> 標記會識別與 XML 結果相關聯的 HTTP 要求中提交的輸入參數。參數的相關資訊會包含在標記屬性 (名稱、值、原始值) 中,且 HTTP 要求中提交的每個參數都會有一個 PARAM 標記。 |
||||||||||||
| 屬性 |
|
||||||||||||
| 範例 | <PARAM name="cr" value="countryNZ" original_value="countryNZ" /> | ||||||||||||
| 子標記主體 | GSP | ||||||||||||
| 內容格式 | 複雜 | ||||||||||||
| PU | |
|---|---|
| 定義 | <PU> 標記提供上一頁搜尋結果的相對連結。 |
| 範例 | <PU>/search?q=flowers&num=10&hl=en&output=xml &client=test&start=10</PU> |
| 子標記主體 | NB |
| 內容格式 | 文字 (相對網址) |
| Q | |
|---|---|
| 定義 | <Q> 標記會識別與 XML 結果相關聯的 HTTP 要求中提交的搜尋查詢。 |
| 範例 | <Q>pizza</Q> |
| 子標記主體 | GSP |
| 內容格式 | 文字 |
| R | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定義 | <R> 標記會封裝個別搜尋結果的詳細資料。 注意:WebSearch 的 <R> 標記定義比 DTD 更嚴格。 |
|||||||||
| 屬性 |
|
|||||||||
| 子標記 | U、UE、T?CRAWLDATE、S?LANG? HAS | |||||||||
| 子標記主體 | RES | |||||||||
| 反抗軍 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定義 | <RES> 標記會封裝一組個別搜尋結果,以及這些結果的詳細資料。 |
|||||||||
| 屬性 |
|
|||||||||
| 範例 | <RES SN="1" EN="10"> | |||||||||
| 子標記 | M、FI?、XT?、NB?、R* | |||||||||
| 子標記主體 | GSP | |||||||||
| 內容格式 | 空白 | |||||||||
| 日 | |
|---|---|
| 定義 | <S> 標記包含搜尋結果的摘要,其中查詢字詞會以粗體醒目顯示。摘要中會加入換行符,確保文字正確換行。 |
| 範例 | <S>華盛頓 (CNN) -- 為結束布希總統的司法任命案在參議院的僵局,一項提案將允許五位被提名人進入最終投票,同時保留<b>...<b>...</b><S> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 (HTML) |
| SL_MAIN | |
|---|---|
| 定義 | 這個標記會封裝宣傳結果的內容,用於剖析宣傳活動。標題連結的錨定文字和網址分別包含在 T 和 U 子標記中。內文和連結的行數則包含在 BODY_LINE 子標記中。 |
| 子標記 | BODY_LINE*、T、U |
| 子標記主體 | SL_RESULTS |
| 內容格式 | 空白 |
| SL_RESULTS | |
|---|---|
| 定義 | 宣傳結果的容器代碼。只要搜尋結果中有宣傳活動,就會顯示其中一個代碼。SL_MAIN 子代碼包含主要結果資料。 |
| 子標記 | SL_MAIN* |
| 子標記主體 | R 鍵 |
| 內容格式 | 空白 |
| 拼字 | |
|---|---|
| 定義 | <Spelling> 標記會封裝所提交查詢的替代拼字建議。這個標記只會顯示在搜尋結果的第一頁。拼字建議支援英文、中文、日文和韓文。 注意:只有在查詢的 gl 參數值為小寫字母時,Google 才會傳回拼字建議。 |
| 範例 | <Spelling> |
| 子標記 | 建議 |
| 子標記主體 | GSP |
| 內容格式 | 空白 |
| 建議 | |||||||
|---|---|---|---|---|---|---|---|
| 定義 | <Suggestion> 標記包含所提交查詢的替代拼字建議。你可以使用標記的內容,向搜尋使用者建議替代拼字。q 屬性的值是經過網址逸出的拼字建議,可做為查詢字詞。 | ||||||
| 屬性 |
|
||||||
| 範例 | <Suggestion q="soccer"><b><i>soccer</i></b></Suggestion> | ||||||
| 子標記主體 | 拼字 | ||||||
| 內容格式 | 文字 (HTML) | ||||||
| T | |
|---|---|
| 定義 | <T> 標記含有結果的標題。 |
| 範例 | <T>Amici's East Coast Pizzeria</T> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 (HTML) |
| title | |
|---|---|
| 定義 | 做為 <Context> 的子項,<title> 標記包含程式化搜尋引擎的名稱。 做為 <Facet> 的子項,<title> 標記會為一組層面提供標題。 |
| 範例 | 做為 <Context> 的子項:<title>我的搜尋引擎</title> 做為 <Facet> 的子項:<title>facet title</title> |
| 子標記主體 | Context、Facet |
| 內容格式 | 文字 |
| TM | |
|---|---|
| 定義 | <TM> 代碼會以秒為單位,指出傳回搜尋結果所需的伺服器總時間。 |
| 範例 | <TM>0.100445</TM> |
| 子標記主體 | GSP |
| 內容格式 | 文字 (浮點數) |
| TT | |
|---|---|
| 定義 | <TT> 標記提供搜尋提示。 |
| 範例 | <TT><i>提示:在大多數瀏覽器中,按下 Return 鍵會產生與點選「搜尋」按鈕相同的結果。</i></TT> |
| 子標記主體 | GSP |
| U | |
|---|---|
| 定義 | <U> 代碼提供搜尋結果的網址。 |
| 範例 | <U>http://www.dominos.com/</U> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 (絕對網址) |
| UD | |
|---|---|
| 定義 | <UD> 標記會提供搜尋結果的 IDN 編碼 (國際化網域名稱) 網址。這個值可讓網域以當地語言顯示。舉例來說,IDN 編碼網址 http://www.%E8%8A%B1%E4%BA%95.com 可以解碼並顯示為 http://www.花井鮨.com。只有在要求包含 ud 參數時,搜尋結果才會包含這個 <UD> 標記。 注意:這項功能目前為 Beta 版。 |
| 範例 | <UD>http://www.%E8%8A%B1%E4%BA%95.com/</UD> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 (IDN 編碼網址) |
| UE | |
|---|---|
| 定義 | <UE> 代碼會提供搜尋結果的網址。這個值會經過網址逸出處理,因此適合做為網址中的查詢參數傳遞。 |
| 範例 | <UE>http://www.dominos.com/</UE> |
| 子標記主體 | R 鍵 |
| 內容格式 | 文字 (網址逸出網址) |
| XT | |
|---|---|
| 定義 | <XT> 標記表示 M 標記指定的預估結果總數,實際上代表確切的結果總數。詳情請參閱本文的「自動篩選」一節。 |
| 範例 | <XT /> |
| 子標記主體 | RES |
| 內容格式 | 空白 |
圖片搜尋查詢的 XML 結果
這個圖片要求範例會針對搜尋字詞「monkey」要求 5 個結果 (num=5)。
http://www.google.com/cse? searchtype=image &num=2 &q=monkey &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
這項要求會產生下列 XML 結果。
<GSP VER="3.2">
<TM>0.395037</TM>
<Q>monkeys</Q>
<PARAM name="cx" value="011737558837375720776:mbfrjmyam1g" original_value="011737558837375720776:mbfrjmyam1g" url_<escaped_value="011737558837375720776%3Ambfrjmyam1g" js_escaped_value="011737558837375720776:mbfrjmyam1g"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe" url_escaped_value="google-csbe" js_escaped_value="google-csbe"/>
<PARAM name="q" value="monkeys" original_value="monkeys" url_escaped_value="monkeys" js_escaped_value="monkeys"/>
<PARAM name="num" value="2" original_value="2" url_escaped_value="2" js_escaped_value="2"/>
<PARAM name="output" value="xml_no_dtd" original_value="xml_no_dtd" url_escaped_value="xml_no_dtd" js_escaped_value="xml_no_dtd"/>
<PARAM name="adkw" value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" original_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" url_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" js_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A"/>
<PARAM name="hl" value="en" original_value="en" url_escaped_value="en" js_escaped_value="en"/>
<PARAM name="oe" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="ie" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="boostcse" value="0" original_value="0" url_escaped_value="0" js_escaped_value="0"/>
<Context>
<title>domestigeek</title>
</Context>
<ARES/>
<RES SN="1" EN="2">
<M>2500000</M>
<NB>
<NU>/images?q=monkeys&num=2&hl=en&client=google-csbe&cx=011737558837375720776:mbfrjmyam1g&boostcse=0&output=xml_no_dtd
&ie=UTF-8&oe=UTF-8&tbm=isch&ei=786oTsLiJaaFiALKrPChBg&start=2&sa=N
</NU>
</NB>
<RG START="1" SIZE="2"/>
<R N="1" MIME="image/jpeg">
<RU>http://www.flickr.com/photos/fncll/135465558/</RU>
<U>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</U>
<UE>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</UE>
<T>Computer <b>Monkeys</b> | Flickr - Photo Sharing!</T>
<RK>0</RK>
<BYLINEDATE>1146034800</BYLINEDATE>
<S>Computer <b>Monkeys</b> | Flickr</S>
<LANG>en</LANG>
<IMG WH="500" HT="305" IID="ANd9GcQARKLwzi-t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs">
<SZ>88386</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="130" HT="79" URL="http://t0.gstatic.com/images?q=tbn:ANd9GcQARKLwzi-
t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs"/>
</R>
<R N="2" MIME="image/jpeg">
<RU>
http://www.flickr.com/photos/flickerbulb/187044366/
</RU>
<U>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</U>
<UE>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</UE>
<T>
one. ugly. <b>monkey</b>. | Flickr - Photo Sharing!
</T>
<RK>0</RK>
<BYLINEDATE>1152514800</BYLINEDATE>
<S>one. ugly. <b>monkey</b>.</S>
<LANG>en</LANG>
<IMG WH="400" HT="481" IID="ANd9GcQ3Qom0bYbee4fThCQVi96jMEwMU6IvVf2b8K5vERKVw-
EF4tQQnDDKOq0"><SZ>58339</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="107" HT="129" URL="http://t1.gstatic.com/images?q=tbn:ANd9GcQ3Qom0bYbee4fThCQ
Vi96jMEwMU6IvVf2b8K5vERKVw-EF4tQQnDDKOq0"/>
</R>
</RES>
</GSP>圖片搜尋:XML 標記
下表列出圖片搜尋查詢的 XML 回應中使用的其他 XML 標記。
在下列定義中,部分子標記旁可能會顯示特定符號。這些符號和它們的意義分別是:
* = 零或多個子標記執行個體
+ = 一或多個子標記執行個體
| RG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定義 | <RG> 標記會封閉個別圖片搜尋結果的詳細資料。 |
|||||||||
| 屬性 |
| |||||||||
| 子標記主體 | RES | |||||||||
| RU | |
|---|---|
| 定義 | <RU tag> 標記會封閉每個圖片搜尋結果的詳細資料。 |
| 子標記主體 | R 鍵 |