개요
프로그래밍 검색 엔진은 사용자가 사이트에서 원하는 페이지로 이동할 수 있도록 구조화된 검색 연산자를 제공합니다. 이 연산자를 사용하면 페이지의 구조화된 데이터 또는 사이트의 이미지와 연결된 메타데이터를 기반으로 검색결과의 하위 집합을 상세히 살펴볼 수 있습니다.
이미지 검색의 경우 Google은 페이지의 구조화된 데이터와 사이트를 크롤링할 때 발견된 이미지 메타데이터를 모두 사용합니다. 모든 웹마스터는 Google의 이미지 게시 가이드라인을 숙지하는 것이 좋습니다.
- 웹 검색 <ph type="x-smartling-placeholder">
- 이미지 검색
<ph type="x-smartling-placeholder">
- </ph>
- 속성별 필터링
- 프로그래밍 검색 요소의 구조화된 검색
웹 검색
자유 형식의 단어 시퀀스인 텍스트와 달리 구조화된 데이터는 속성 집합을 가진 객체 집합으로 논리적으로 구성됩니다. 프로그래밍 검색 엔진은 구조화된 검색엔진이 사용할 수 있도록 다양한 구조화된 데이터를 추출합니다. 날짜, 작성자, 평점 및 가격을 포함한 검색 연산자 이것이 바로 맞춤 스니펫에 동일한 데이터를 사용할 수 있습니다. 포함 또한 프로그래밍 검색 엔진은 다음 형식의 구조화된 데이터를 지원합니다.
- 페이지 지도: 구조화된 데이터를 DataObject로 명시적으로 나타내는 PageMap XML 블록으로 인코딩되어 웹페이지일 것입니다. 프로그래밍 검색 엔진으로 올바른 형식의 모든 PageMap 데이터 만들기 구조화된 검색 연산자에 사용할 수 있습니다. GCP 콘솔에서도 맞춤 스니펫에 대해 자세히 알아보세요.
- 태그
meta개: Google이meta에서 선택한 콘텐츠를 추출합니다.<meta name="NAME" content="VALUE">양식의 태그입니다. 양식의meta태그<meta name="pubdate" content="20100101">의 가능한 값은 다음과 같습니다. 다음 형식의 검색 연산자와 함께 사용됩니다.&sort=metatags-pubdate입니다. - 페이지 날짜:
Google은 URL, 제목, 서명 날짜를 바탕으로 페이지의 날짜를 추정합니다.
확인할 수 있습니다 이 날짜는
&sort=date에서와 같이 특수 구조화된 데이터 유형date. - 리치 스니펫 데이터:
또한 Google은 다음과 같은 공개 표준에서 데이터의 하위 집합을 추출합니다.
<ph type="x-smartling-placeholder"> 프로그래밍 검색 엔진의 구조화된 데이터 연산자에 사용됩니다.
예를 들어 Microformat을 사용하여 마크업된 페이지를 정렬
hrecipe표준을 사용하려면 다음을 사용합니다.&sort=recipe-ratingstars입니다.
페이지에 구조화된 데이터가 포함되어 있다면 프로그래밍 검색 엔진의 구조화된 검색 연산자를 사용하여 검색을 특정 내용이 있는 필드로 제한 데이터 값, 숫자 값으로 엄격하게 정렬, 특정 값에 편향 정렬하거나 심지어 주어진 숫자 값 범위로 제한하기 보다는
프로그래밍 검색 엔진은 구조화된 데이터에 대해 다음 검색 연산자를 지원합니다.
- 속성별 필터링(모든 구조화된 콘텐츠에 사용할 수 있음) 데이터 형식을 지원합니다.
- 트리 브랜치로 필터링(JSON-LD에 사용할 수 있음) Microformat 및 RDFa
- 속성별 정렬
- 속성별 편향
- 범위로 제한
속성별 필터링
속성별로 필터링하면 다음 세 가지 종류의 결과를 선택할 수 있습니다.
- 연결된 특정 DataObject가 포함된 결과(예: 리뷰)
- 지정된 필드가 있는 DataObject가 있는 결과(예: 리뷰로 만들 수도 있습니다
- 필드의 특정 값이 있는 결과(예: 리뷰(별표 5개)
속성별로 필터링하려면
more:pagemap:TYPE-NAME:VALUE
연산자를 검색어에 추가할 수 있습니다. 이렇게 하면
구조화된 데이터가 해당 유형, 이름 및 값과 정확히 일치해야 합니다. (프로그래밍 검색 엔진
는 페이지당 최대 200개의 속성을 변환합니다.
JSON-LD, 마이크로포맷, 메타태그, RDFa, 마이크로데이터가 뒤따릅니다.) 속성은
128자 이상이어야 합니다.
일치를 위해 VALUE를 생략하여 이 연산자를 일반화할 수 있습니다.
이름이 지정된 필드의 모든 인스턴스 또는 -NAME:VALUE 생략
주어진 유형의 모든 객체와 일치시킵니다.
구조화된 데이터에서 전체 연산자가 생성되는 방식을 확인하려면 다음 안내를 따르세요. 앞서 사용한 예를 떠올려 보세요.
[halloween more:pagemap:document-author:lisamorton]
more:pagemap:document-author:lisamorton 분석
좀 더 자세히 설명하자면
more: 연산자는 프로그래밍 검색 엔진에서 사용합니다.
상세검색 라벨의 경우 상세검색의 pagemap: 부분
를 사용하면 색인이 생성된 페이지 지도의 특정 속성별로 결과를 세분화할 수 있습니다.
연산자의 나머지 요소인 document-author 및
lisamorton: 제한에서 드릴 콘텐츠를 지정합니다.
되돌립니다. 다음 예에서 PageMap을 떠올려 보세요.
<PageMap>
<DataObject type="document">
<Attribute name="title">The Five Scariest Traditional Halloween Stories</Attribute>
<Attribute name="author">lisamorton</Attribute>
</DataObject>
</PageMap>
연산자의 document-author: 한정자는
(속성이 author인 document 유형인 DataObject의 경우)
이 구조화된 데이터 키 뒤에 lisamorton 값이 옵니다.
이 값은
이 제한이 포함된 검색
more:p:document-author:lisamorton
속성별로 필터링하면 더 복잡한 필터를 만들 수 있고 명령)을 실행할 수 있습니다. 예를 들어 URL의 PageMap:
<pagemap> <DataObject type="document"> <Attribute name="keywords">horror</Attribute> <Attribute name="keywords">fiction</Attribute> <Attribute name="keywords">Irish</Attribute> </DataObject> </pagemap> </page>
'아일랜드 및 픽션'이라는 쿼리 결과를 검색하려면 다음을 사용하세요.
more:p:document-keywords:irish*fiction
more:pagemap:document-keywords:Irish more:pagemap:document-keywords:fiction와 동일합니다.
'아일랜드 AND (픽션 OR 공포)'에 대한 결과를 검색하려면 다음을 사용합니다.
more:p:document-keywords:irish*fiction,irish*horror
브랜치로 필터링
분기별 필터링은 다음에 사용할 수 있는 속성별 필터링의 변형입니다. JSON-LD, Microformat 및 RDFa입니다. 속성별 필터링의 유일한 유형입니다. JSON-LD 구조화된 데이터에 사용할 수 있습니다.
구조화된 데이터에 트리가 포함되어 있지 않거나 트리가 없는 트리만 포함된 경우 하위 요소가 있는 경우, 제한은 속성별 필터와 동일합니다. 그러나 하위 요소가 있는 트리에는 다음을 포함하는 제한이 있습니다. type-name이 필요합니다. 즉, 다음과 같은 트리입니다.
- 루트는 Event 유형입니다.
- 자녀의 이름은 rating입니다.
- 하위 요소의 유형은 AggregateRating입니다.
- 하위 항목에 이름이 ratingCount이고 값이 22인 속성이 있습니다.
다른 특성과 함께 속성 또는 브랜치별 필터링 사용하기
이 개방형 구문을 사용하여
사이트의 문서에 대한 PageMaps 같은 구문을 사용하여
거의 모든 유형의 구조화된 데이터
단,
예상 페이지 날짜. 다음과 같은 작업을 할 수 있습니다.
다음과 같은 more:pagemap: 연산자를 함께 사용합니다.
<ph type="x-smartling-placeholder"></ph>
상세검색 라벨 또는
<ph type="x-smartling-placeholder"></ph>
숨겨진 쿼리 요소
애플리케이션에 중요한 속성별로 결과를 필터링할 수 있습니다.
최종 사용자가 이러한 제한 한정자를 직접 입력하지 않아도 됩니다.
검색 연산자의 일부를 생략할 수도 있습니다. 위의 예에서
PageMap은 document 유형의 DataObject를 지정하고
author 유형의 속성 하지만 사이트의 모든 페이지가
모든 문서에 작성자가 표시되지 않을 수 있습니다. 만약
more:pagemap:document-author 형식의 연산자를 사용합니다.
반환된 결과에는 author 속성이 있는 모든 페이지가 포함됩니다.
document DataObject의 값으로
속성은 다음과 같습니다. 마찬가지로 more:pagemap:document는
document 유형의 DataObject가 포함된 PageMaps가 포함된 모든 결과
모든 필드를 변경할 수 있습니다.
제한의 텍스트 값 토큰화
공백, 구두점, 특수문자가 포함된 속성 값 거의 항상 별도의 토큰으로 분할됩니다. 예를 들어 'Programmable Search Engine@google'의 값 세 개의 개별 토큰으로 분할되어 '맞춤', '검색' 'google'이 포함됩니다. 이렇게 하면 한 단어에 대한 검색이 허용됩니다. 단어와 구두점의 더 큰 순서(예: 프로덕션 설명 프로그래밍 검색 엔진은 문자열당 최대 10개의 토큰을 추출하므로 속성 값에 10개 이상의 단어가 포함되어 있어 일부 단어만 제한에 사용할 수 있습니다. results.) 예를 들어, 다음 PageMap에는 프로그래밍 검색 엔진:
<PageMap>
<DataObject type="product">
<Attribute name="description">Programmable Search Engine provides customized search engines</Attribute>
</DataObject>
</PageMap>
다음 제한사항은 product-description이 있는 모든 페이지를 찾습니다.
'search'에 대한 속성:
[more:pagemap:product-description:search]
텍스트 값을 토큰화하기 위한 추가 규칙:
- 제한의 경우 텍스트 값이 소문자로 변환됩니다.
- 토큰이 최대 6개인 문자열의 경우 전체 문자열에 대한 추가 제한이 생성됩니다.
공백은
_로 대체됩니다(예:please_attend). - 중지 단어(the, a, 하지만 따라서 검색에 덜 유용합니다. 따라서 텍스트 값: '주요 포인트' main, point, the_main_point가 아닌 the에 대한 제한을 생성하지 않습니다.
- 텍스트 값의 처음 10개 단어만 제한을 형성하는 데 사용됩니다.
-
구분 기호로 취급되지 않는 구두점 문자는 밑줄로 변환됩니다.
_
여러 제한사항을 사용하여 토큰화된 값 분석
더 상세히 살펴보려면 다른 제한사항을 추가하면 됩니다. 예를 들어 검색엔진의 제품을 설명하는 페이지만 가져오려면 다음과 같이 제한사항을 추가합니다.
[more:pagemap:product-description:search more:pagemap:product-description:engine]
more:pagemap: 제한의 순서는 중요하지 않습니다.
토큰은 속성 값에서 순서가 지정되지 않은 집합으로 추출됩니다.
이러한 제한사항 기본적으로 AND로 결합됩니다. 인코더-디코더 아키텍처를 OR 연산자 제한 중 하나와 일치하는 결과를 가져옵니다. 예를 들어 다음은 은 검색 또는 게임에 관한 콘텐츠와 일치합니다.
[more:pagemap:product-description:search OR more:pagemap:product-description:game]
토큰화의 한 가지 예외는 URL인 속성 값입니다. 이후 URL 토큰의 경우 미미한 유용성이 있지만 속성 값입니다.
특정한 경우(예: 짧은 토큰이 함께 자주 발견되는 경우)
프로그래밍 검색 엔진에서 이를 결합하여 슈퍼토큰을 생성할 수 있습니다. 예를 들어 토큰이
"대통령" 및 '오바마' 나란히 표시되는 경우가 많으므로 프로그래밍 검색 엔진은
슈퍼토큰인 'ppresent_obama'를 만듭니다. 그 결과 [more:pagemap:leaders-name:president_obama]
는 [more:pagemap:leaders-name:president AND more:pagemap:leaders-name:obama]와 동일한 결과를 반환합니다.
구두점 기반 토큰화의 또 다른 주요 예외는 슬래시 '/' 그것이 숫자를 구분할 때. 속성 값 'NUMBER/NUMBER' 형식의 또는 'NUMBER/NUMBER/NUMBER' 처리됨 단일 연속 토큰으로 표현합니다. 예를 들어 '3.5/5.0' 및 '09/23/2006' 단일 토큰으로 취급됩니다 예를 들어 값이 '2006/09/23'인 속성에서 검색하려면 제한을 사용합니다.
[more:pagemap:birth-date:2006/09/23]
슬래시를 사용하여 조인은 슬래시가 사이에 있는 경우에만 작동합니다. 공백 없는 숫자 슬래시와 숫자 사이의 공백은 별도의 토큰이 생성됩니다. 뿐만 아니라 슬래시는 정확히 일치해야 합니다. Filter by Attribute 연산자는 이러한 값을 분수나 날짜로 해석하지 않습니다. 프로그래밍 검색 엔진의 기타 구조화된 검색 연산자(예: 속성별 정렬 및 범위로 제한, 해석 이 숫자는 분수와 날짜로 되어 있고, 자세한 내용은 다음에 대해 구조화된 데이터 제공: 확인하세요.
JSON-LD에서 제한
JSON-LD는 구조화된 데이터를 위한 강력한 표준 형식입니다.
데이터는 JSON 형식으로 지정되며
type="application/ld+json"가 포함된 <script> 태그
다음은 간단한 JSON-LD를 사용한 최소한의 HTML입니다.
<script type="application/ld+json"> { "@id": "http://event.example.com/events/presenting-foo", "@type": "http://schema.org/AggregateRating", "http://schema.org/ratingCount": "22", "http://schema.org/ratingValue": "4.4", "http://schema.org/itemReviewed": { "@type": "http://schema.org/Event", "http://schema.org/description": "Please attend.", "http://schema.org/name": "Presenting Foo", "http://schema.org/startdate": "2022-05-24", "http://schema.org/location": "Back room" } } </script>
다음과 같은 제한이 생성됩니다.
- more:pagemap:aggregaterating-ratingcount:22
- more:pagemap:aggregaterating-ratingvalue:4.4
- more:pagemap:aggregaterating-itemreviewed-event-description:please_attend
- more:pagemap:aggregaterating-itemreviewed-event-description:please
- more:pagemap:aggregaterating-itemreviewed-event-description:attend
- more:pagemap:aggregaterating-itemreviewed-event-name:presenting_foo
- more:pagemap:aggregaterating-itemreviewed-event-name:presenting
- more:pagemap:aggregaterating-itemreviewed-event-name:foo
- more:pagemap:aggregaterating-itemreviewed-event-startdate:2022-05-24
- more:pagemap:aggregaterating-itemreviewed-event-location:back_room
- more:pagemap:aggregaterating-itemreviewed-event-location:back
- more:pagemap:aggregaterating-itemreviewed-event-location:room
JSON-LD의 경우 루트에서 전체 경로에 대한 제한만 생성합니다. 분기별 필터링을 참조하세요. 그러나 JSON-LD 트리의 루트에는 리프 노드가 결과 제한은 Attribute Restricts와 형태가 동일합니다. 일부 제한사항은 루트의 리프 노드에서 구성되며 (type-name-value) 형식을 사용합니다. more:pagemap:aggregaterating-ratingcount:22
참고: 다른 구조화된 데이터 형식에서는 최대 128바이트의 문자열을 허용하지만 JSON-LD의 경우, 모든 문자열이 약 50자(영문 기준)로 잘리므로 끝나지 않습니다. 단어를 반환합니다. 단어 길이에 따라 생성되는 토큰 수가 제한될 수 있습니다. 제한보다 엄격하게 10개의 토큰으로 변경합니다.
속성별 정렬
때로는 특정 유형의 결과로만 검색을 제한하기에 충분하지 않을 때가 있습니다.
예를 들어 음식점 리뷰를 검색하는 경우 광고에 가장 높은 가격을
평가된 음식점이 목록 맨 위에 표시됩니다. 이렇게 하면
프로그래밍 검색 엔진의 속성별 정렬 기능으로
결과를 정렬하는 데 사용됩니다.
정렬은
&sort=TYPE-NAME:DIRECTION
URL 매개변수를 프로그래밍 검색 엔진의 요청 URL에 추가합니다.
구조화된 검색과 마찬가지로 속성별 정렬은
페이지 구조화된 검색과 달리 정렬하려면
필드는 숫자 및 날짜와 같이 숫자 해석을 갖습니다.
가장 간단한 형태는
데이터 객체 유형과
PageMap의 속성 이름을 가져와서 요청 URL에
&sort=TYPE-NAME 예를 들어
데이터를 date 유형으로 나타내는 페이지의 날짜
이름을 sdate로 지정하고 다음 문법을 사용합니다.
https://www.google.com/cse?cx=000525776413497593842:aooj-2z_jjm&q=comic+con&sort=date-sdate
이는 기본적으로 내림차순으로 하드 정렬을 수행합니다.
검색결과는 날짜순으로 표시되며 최신 항목 순으로 정렬됩니다.
가장 큰 숫자로 변환되는 날짜의 순서입니다.
정렬 순서를 오름차순으로 변경하려면
필드에 :a를 추가하거나 명시적으로 지정하려면 :d을 추가합니다.
내림차순 지정). 예를 들어 가장 오래된 결과를 먼저 표시하려면
다음과 같은 형식의 제한사항을 사용할 수 있습니다.
https://www.google.com/cse?cx=000525776413497593842:aooj-2z_jjm&q=comic+con&sort=date-sdate:a
엔진에서 정렬된 결과는
페이지가 해당 DataObject 및 속성에 대해
표시됩니다 페이지
해당 DataObject 유형 또는 파싱 가능한 값이 없는
속성은 하드 정렬로 표시되지 않습니다. 위의 예에서 페이지는
date-sdate 속성이 없으면 표시되지 않습니다.
표시됩니다. 하드 정렬은 속성별 편향과 결합할 수 없습니다.
기능을 지원하지만
속성별로 필터링
범위로 제한.
속성별 편향
값이 없는 결과는 제외하지 않으려는 경우가 있습니다.
예를 들어 레바논 요리를 검색하려는 경우 다양한
순수한 레바논 음식부터 가장 관련성이 높은 식당까지
그리스어 (관련성이 가장 낮음) 이 경우 '강함' 또는 '약함'을 사용하여
검색 결과를 크게 또는 약하게 끌어올리는 경향을 보이는 셈입니다.
값이 없는 결과는 제외하지 않습니다. 강력한
정렬 방향 뒤에 두 번째 값을 추가하여 약한 편향을
줄일 수도 있습니다
&sort=TYPE-NAME:DIRECTION:STRENGTH,
강력한 편향의 경우 :s 또는
약한 편향의 경우 :w, 약한 편향의 경우 :h
정렬되지만 :h 추가는 기본값이므로 선택사항입니다.
예를 들어 강력한 편향을 추가하면
개의 지중해 음식점의 실적이 가장 낮은 평점보다 높습니다.
다른 식당보다 지중해식 음식점이 더 많을 것 같지 않습니다.
레바논 음식점에 대한 일치검색:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-rating:d:s
쉼표 연산자를 사용하여 여러 편향을 결합할 수 있습니다.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-rating:d:s,review-pricerange:d:w
편향의 순서는 중요하지 않습니다. 하지만 하드 정렬은 만들 수 있습니다 목록에서 마지막으로 지정하는 정렬 연산자는 모든 정렬 및 편향 연산자를 재정의합니다.
범위로 제한
값의 범위 사이 또는 특정 값보다 크거나 작은 결과를 포함하려면
범위 제한을 사용합니다. 범위 제한은 :r에서 지정합니다.
뒤에 최대값과 하한값이 오고 그 뒤에
속성 값: &sort=TYPE-NAME:r:LOWER:UPPER
예를 들어 3월과 4월 사이에 작성된 리뷰만 포함할 수 있습니다.
다음과 같이 범위 제한을 지정할 수 있습니다.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-date:r:20090301:20090430
Google은 Restrict to Range 연산자의 경우 숫자를 지원합니다.
날짜는 부동 소수점 수 형식으로
ISO 8601
YYYYMMDD(대시 제외)
상한 또는 하한을 지정할 필요가 없습니다. 예를 들어 2009년 이전의 날짜만 지정하려면 다음과 같이 작성할 수 있습니다.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-date:r::20091231
별 3개 이상의 평점만 포함하려면 다음 코드를 사용하세요.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars:r:3.0
범위는 포함적이며 다음과 같이 쉼표 연산자와 결합할 수 있습니다. 하나의 정렬 또는 하나 이상의 편향 기준을 사용해야 합니다 참고 범위 제한을 정렬 및 편향 기준과 결합하면 그러면 범위 내의 값이 있는 항목만 정렬됩니다. 예를 들어 별표가 3개 이상인 항목만 평가하여 정렬하려면 다음을 사용하세요.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars,rating-stars:r:3.0
하나의 기준으로 정렬하고 범위를 기준으로 다른 기준으로 제한할 수 있습니다. 예를 들어 '월'에 리뷰가 작성된 항목만 평점별로 정렬할 수 있습니다. 10월에는 다음을 사용합니다.
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars,review-date:r:20101001:20101031
이미지 검색
검색엔진에서 이미지 검색을 사용하도록 설정하면 Google에서 별도의 탭에 이미지 검색결과를 표시합니다. 프로그래밍 검색 엔진 제어판을 사용하거나 context.xml 파일을 업데이트하여 이미지 검색을 사용하도록 설정할 수 있습니다.
이미지 검색은 Google이 사이트를 크롤링할 때 발견하는 정보를 사용합니다. 이미지가 검색 결과 (프로그래밍 검색 엔진 및 Google 웹 검색 모두에서)에 표시되는 방식을 개선하려면 Google의 이미지 게시 가이드라인을 숙지하는 것이 좋습니다.
이미지 속성으로 필터링
웹 검색과 마찬가지로 이미지 검색에서는 src, alt, title와 같은 속성에 대한 필터링을 지원합니다.
프로그래밍 검색 요소의 구조화된 검색
구조화된 검색 기능은 Google 검색 결과와 함께
프로그래밍 검색 요소 쿼리에서 표현된 연산자와 마찬가지로
또는 URL 매개변수가 포함된 경우 먼저 요소의 구조화된 검색을 사용하려면
검색 중인 페이지가 원하는 속성으로 마크업되어 있는지
다음을 기준으로 검색합니다. 그런 다음 프로그래밍 검색 요소의 sort 연산자
쿼리에서 more:pagemap: 연산자와 결합하면
검색결과를 적절히 정렬하거나 제한합니다.
예를 들어 캘리포니아 뉴스 포털인 SignOnSanDiego.com은 결과에 사진이 포함된 최근 뉴스를 렌더링하는 프로그래밍 검색 요소:
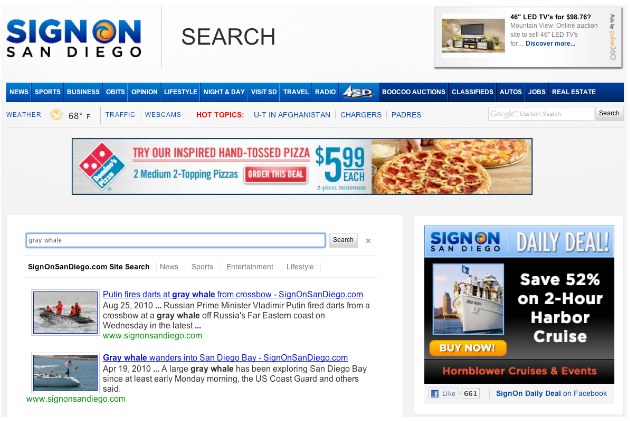
독자들이 가장 관련성이 높은 뉴스뿐만 아니라 시기적절한 뉴스를 볼 수 있도록 SignOnSanDiego는 '강력' 속성이 포함된 Bias by Attribute를 사용합니다. 가중치 적용 최근 게시일 SignOnSanDiego는 이러한 날짜 속성을 구현합니다. PageMaps와 함께 SignOnSanDiego에서 사용되는 인증의 형식은 다음과 같습니다.
<!-- <PageMap> <DataObject type="date"> <Attribute name="displaydate" value="Wednesday, August 25, 2010"/> <Attribute name="sdate" value="20100825"/> </DataObject> <DataObject type="thumbnail"> <Attribute name="src" value="http://media.signonsandiego.com/img/photos/2010/08/25/635a63e9-f4a1-45aa-835a-ebee666b82e0news.ap.org_t100.jpg"/> <Attribute name="width" value="100"/> </DataObject> </PageMap> -->
이 필드에 속성별 정렬을 적용하려면
sort 옵션을
프로그래밍 검색 요소를 추가합니다.
... <div class="gcse-search" sort_by="date-sdate:d:s"></div> ...
위에서 설명한 URL &sort= 매개변수와 마찬가지로 프로그래밍 검색 요소의 정렬 옵션은
<div class="gcse-search" sort_by="date-sdate:d:s"></div>
는 date-sdate와 같은 결합된 속성 이름을 가지며 여러 개의 선택 사항이 있습니다.
매개변수를 콜론으로 구분해야 합니다. 이 경우 SignOnSanDiego는
강력한 편향을 사용하여 d 내림차순으로 정렬
연산자의 s 버전입니다. 광고주가
기본적으로 하드 정렬, 내림차순,
URL 연산자의 경우와 동일합니다.
정렬 옵션을 사용하면 범위별 제한 기능도 사용할 수 있습니다. 예:
SignOnSanDiego와 같은 사이트를 통해 사용자가 기사를 검색할 수 있습니다.
에 게시되었습니다. 이를 구현하려면
정렬 옵션을 설정하여
date-sdate:r:20100825:20100907 이번에도 마찬가지로
속성 이름 date-sdate를 사용하지만 대신
지정된 값 20100825:20100907의 r 범위입니다.
URL 매개변수와 마찬가지로
프로그래밍 검색 요소의 sort 옵션에서 범위를 지정할 수 있습니다.
정렬 옵션의 또 다른 강력한 기능은
속성 및 범위로 제한. 에서 여러 연산자를 결합할 수 있습니다.
정렬 옵션을 선택합니다. 예를 들어
위의 날짜 제한이 적용된 SignOnSanDiego의 강력한 편향은 다음과 같습니다.
date-sdate:d:s,date-sdate:r:20100825:20100907를 지정합니다. 이
특성은 고유한 속성을 결합할 수 있습니다. 예를 들어 영화 리뷰가
사이트에 최근 개봉한 가장 높은 평점을 받은 영화를 표시할 수 있습니다.
review-rating,release-date:r:20100907: 옵션을 선택하세요.
지원되는 모든 속성은 이 페이지를 참고하세요.
프로그래밍 검색 요소와 함께 속성별 필터링을 사용할 수도 있습니다.
예를 들어 이전 예에서
linked-blog 속성이 있는 페이지 커스텀 모델을
다음 코드를 사용하도록 연결된 페이지만 표시한 검색 컨트롤
에 more:pagemap:linked-blog:blogspot 연산자를 삽입하기 위해
모든 쿼리:
... <div class="gcse-search" webSearchQueryAddition="more:pagemap:linked-blog:blogspot"></div> ...
이 메서드는 이 컨트롤에서 실행된 검색어입니다. 다른 옵션을 보려면 문서를 참고하세요. 에 프로그래밍 검색 요소.
기타 기능 살펴보기
구조화된 검색 기능은 검색 애플리케이션을 세밀하게 제어할 수 있기 때문에 맞춤 속성을 사용하여 검색 결과를 사용자를 위한 강력한 방법입니다 또한 구조화된 검색은 맞춤 결과 스니펫 등 기타 프로그래밍 검색 엔진 기능 추가 정보:
- Google에서 제공하는 구조화된 데이터에 대해 자세히 알아보려면 구조화된 데이터 제공을 참조하세요.
- 스니펫에 구조화된 데이터를 사용하는 방법을 자세히 알아보려면 결과 스니펫 맞춤설정을 참조하세요.