खास जानकारी
Programmable Search Engine, स्ट्रक्चर्ड खोज ऑपरेटर उपलब्ध कराता है, ताकि उपयोगकर्ता आपकी साइट के सही पेजों पर पहुंच सकें. इन ऑपरेटर की मदद से, आपके पेजों में मिले स्ट्रक्चर्ड डेटा या आपकी साइटों पर मौजूद इमेज से जुड़े मेटाडेटा के आधार पर, खोज के नतीजों के सबसेट में ड्रिल-डाउन किया जा सकता है.
इमेज खोज के लिए, Google आपकी साइट क्रॉल करते समय मिले इमेज मेटाडेटा और आपके पेजों पर मौजूद स्ट्रक्चर्ड डेटा, दोनों का इस्तेमाल करता है. हमारा सुझाव है कि सभी वेबमास्टर हमारे इमेज पब्लिश करने से जुड़े दिशा-निर्देशों के बारे में जान लें.
वेब खोज
टेक्स्ट के उलट, जो शब्दों का फ़्री फ़ॉर्म क्रम होता है, लेकिन स्ट्रक्चर्ड डेटा एट्रिब्यूट के सेट के साथ, चीज़ों को तार्किक रूप से व्यवस्थित किया जाता है. Programmable Search Engine अलग-अलग तरह का स्ट्रक्चर्ड डेटा एक्सट्रैक्ट करता है, जिसका इस्तेमाल स्ट्रक्चर्ड डेटा के लिए किया जाता है खोज ऑपरेटर, जिनमें तारीखें, लेखक, रेटिंग और कीमतें शामिल हैं; यह है वही डेटा मौजूद है जो कस्टम स्निपेट में इस्तेमाल करने के लिए उपलब्ध है. तय सीमा में इसके अलावा, Programmable Search Engine को इनमें से किसी भी फ़ॉर्मैट के स्ट्रक्चर्ड डेटा के साथ इस्तेमाल किया जा सकता है:
- पेजमैप: PageMap, स्ट्रक्चर्ड डेटा को साफ़ तौर पर DataObjects के तौर पर दिखाता है एट्रिब्यूट और वैल्यू के साथ, एम्बेड किए गए एक्सएमएल ब्लॉक के तौर पर एन्कोड किए गए एक वेब पेज होता है. Programmable Search Engine पूरी तरह से व्यवस्थित PageMap डेटा बनाता है स्ट्रक्चर्ड खोज ऑपरेटर के लिए उपलब्ध; इसका इस्तेमाल इसमें भी किया जा सकता है कस्टम स्निपेट.
metaटैग: Google,metaसे चुना गया कॉन्टेंट एक्सट्रैक्ट करता है<meta name="NAME" content="VALUE">फ़ॉर्म के टैग. फ़ॉर्म का एकmetaटैग<meta name="pubdate" content="20100101">इस फ़ॉर्म के खोज ऑपरेटर के साथ उपयोग किया जाता है:&sort=metatags-pubdate.- पेज की तारीखें:
Google, यूआरएल, टाइटल, बायलाइन की तारीख के आधार पर, पेज की तारीख का अनुमान लगाता है
और दूसरी सुविधाएँ उपलब्ध हैं. इस तारीख का इस्तेमाल, क्रम से लगाने वाले ऑपरेटर के साथ
खास स्ट्रक्चर्ड डेटा टाइप
date, जैसा कि&sort=dateमें है. - रिच स्निपेट का डेटा:
Google, सार्वजनिक स्टैंडर्ड से भी डेटा का एक सबसेट निकालता है. जैसे:
Programmable Search Engine के स्ट्रक्चर्ड डेटा ऑपरेटर में इस्तेमाल करने के लिए.
उदाहरण के लिए, माइक्रोफ़ॉर्मैट के साथ मार्कअप किए गए पेजों को क्रम से लगाने के लिए
रेटिंग के आधार पर
hrecipeमानक, इस्तेमाल करें&sort=recipe-ratingstars.
स्ट्रक्चर्ड डेटा देने के बारे में ज़्यादा जानकारी.
अगर आपके पेजों में स्ट्रक्चर्ड डेटा शामिल है, तो Programmable Search Engine आप अपनी खोजों को सिर्फ़ उन फ़ील्ड तक सीमित कर सकते हैं जिनमें डेटा की वैल्यू, अंकों वाली वैल्यू के हिसाब से क्रम में लगाना, और तय की गई वैल्यू का पूर्वाग्रह और वैल्यू की दी गई संख्या तक सीमित करें.
Programmable Search Engine, स्ट्रक्चर्ड डेटा के बजाय, नीचे दिए गए खोज ऑपरेटर के साथ काम करता है:
- एट्रिब्यूट के हिसाब से फ़िल्टर करें. यह सभी स्ट्रक्चर्ड डेटा के लिए उपलब्ध है JSON-LD को छोड़कर अन्य डेटा फ़ॉर्मैट.
- पेड़ की शाखा के हिसाब से फ़िल्टर करें. यह JSON-LD के लिए उपलब्ध है, माइक्रोफ़ॉर्मैट और RDFa
- एट्रिब्यूट के हिसाब से क्रम से लगाना
- एट्रिब्यूट के हिसाब से बायस
- रेंज तक सीमित करें
एट्रिब्यूट के हिसाब से फ़िल्टर करें
एट्रिब्यूट के हिसाब से फ़िल्टर करने पर, तीन तरह के नतीजे चुने जा सकते हैं:
- अटैच किए गए खास DataObject के साथ नतीजे, जैसे कि समीक्षा
- दिए गए फ़ील्ड के साथ DataObject के साथ नतीजे, जैसे कीमत सीमा के साथ समीक्षा की जा सकती है.
- किसी फ़ील्ड की खास वैल्यू वाले नतीजे, जैसे कि समीक्षा करने के लिए 5 स्टार दें.
एट्रिब्यूट के हिसाब से फ़िल्टर करने के लिए,
more:pagemap:TYPE-NAME:VALUE अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
ऑपरेटर का इस्तेमाल कर सकते हैं. इससे खोज के नतीजों में सिर्फ़ वे पेज दिखते हैं जिन पर
ऐसा स्ट्रक्चर्ड डेटा मौजूद होना चाहिए जो उस टाइप, नाम, और वैल्यू से पूरी तरह मेल खाता हो. (Programmable Search Engine
हर पेज के लिए ज़्यादा से ज़्यादा 200 एट्रिब्यूट जोड़े जाएंगे. इनकी शुरुआत पेजमैप डेटा से होगी,
इसके बाद, JSON-LD, माइक्रोफ़ॉर्मैट, मेटाटैग, RDFa, और माइक्रोडेटा). विशेषताएं ज़्यादा नहीं होनी चाहिए
128 वर्णों से लंबा.
आप मिलान करने के लिए VALUE को हटाकर, इस ऑपरेटर को सामान्य बना सकते हैं
नाम वाले फ़ील्ड के सभी इंस्टेंस या -NAME:VALUE को छोड़कर
का इस्तेमाल करें.
स्ट्रक्चर्ड डेटा से पूरा ऑपरेटर बनाने का तरीका देखने के लिए, वह उदाहरण फिर से याद करें जिसका हमने पहले इस्तेमाल किया था:
[halloween more:pagemap:document-author:lisamorton]
more:pagemap:document-author:lisamorton का विश्लेषण करें
तो आपको
more: ऑपरेटर वह है जिसे Programmable Search Engine इस्तेमाल करता है
रिफ़ाइनमेंट लेबल के लिए, रिफ़ाइनमेंट लेबल्स के लिए, रिफ़ाइनमेंट का pagemap: हिस्सा
हमें यह बताने के लिए कि इंडेक्स किए गए PageMaps में मौजूद खास एट्रिब्यूट के हिसाब से, खोज के नतीजों को बेहतर बनाया जाए या नहीं,
और ऑपरेटर के बाकी एलिमेंट—document-author और
lisamorton—पाबंदी के बारे में जानकारी देने वाले कॉन्टेंट के बारे में बताएं
CANNOT TRANSLATE इस उदाहरण से PageMap को याद करें:
<PageMap>
<DataObject type="document">
<Attribute name="title">The Five Scariest Traditional Halloween Stories</Attribute>
<Attribute name="author">lisamorton</Attribute>
</DataObject>
</PageMap>
ऑपरेटर का document-author: क्वालीफ़ायर हमें बताता है कि
author नाम वाले एट्रिब्यूट के साथ document टाइप वाले DataObject के लिए.
इस स्ट्रक्चर्ड डेटा कुंजी के बाद, lisamorton वैल्यू आती है,
जिसका मिलान उस विशेषता के मान से सटीक रूप से होना चाहिए,
खोज के लिए इस्तेमाल करें.
more:p:document-author:lisamorton
एट्रिब्यूट के हिसाब से फ़िल्टर करने पर, ज़्यादा मुश्किल फ़िल्टर बनाए जा सकते हैं. साथ ही, फ़िल्टर को छोटे साइज़ में भी बनाया जा सकता है कमांड) का इस्तेमाल करें. उदाहरण के लिए, आप निम्न को जोड़ सकते हैं यूआरएल के लिए PageMap:
<pagemap> <DataObject type="document"> <Attribute name="keywords">horror</Attribute> <Attribute name="keywords">fiction</Attribute> <Attribute name="keywords">Irish</Attribute> </DataObject> </pagemap> </page>
"आयरिश AND फ़िक्शन" क्वेरी के नतीजे फिर से पाने के लिए, इनका इस्तेमाल करें:
more:p:document-keywords:irish*fiction
यह more:pagemap:document-keywords:Irish more:pagemap:document-keywords:fiction के बराबर है.
"आयरिश AND (फ़िक्शन OR हॉरर)" के नतीजे पाने के लिए, इनका इस्तेमाल करें:
more:p:document-keywords:irish*fiction,irish*horror
शाखा के हिसाब से फ़िल्टर करें
ब्रांच के हिसाब से फ़िल्टर करें, एट्रिब्यूट के हिसाब से फ़िल्टर करें का एक वैरिएशन है, जो इनके लिए उपलब्ध है JSON-LD, माइक्रोफ़ॉर्मैट, और RDFa. एट्रिब्यूट के हिसाब से, यह सिर्फ़ एक फ़िल्टर है यह सिर्फ़ JSON-LD स्ट्रक्चर्ड डेटा के लिए उपलब्ध है.
अगर स्ट्रक्चर्ड डेटा में पेड़ नहीं हैं या सिर्फ़ बिना पेड़ के बच्चों के लिए, पाबंदियां और एट्रिब्यूट के हिसाब से फ़िल्टर करना एक ही है. हालांकि, बच्चों वाले पेड़ों पर पाबंदी है, जिनमें ये शामिल हैं: type-name: रूट आउट से लीफ़ नोड तक हर नोड के लिए, इसलिए एक ट्री जहां:
- रूट, Event टाइप का है
- बच्चे का नाम रेटिंग होता है
- इस बच्चे का टाइप AggregateRating है
- बच्चे के पास एक एट्रिब्यूट है जिसका नाम ratingCount और वैल्यू 22 है
अन्य सुविधाओं के साथ एट्रिब्यूट या शाखा के हिसाब से फ़िल्टर करना
इस ओपन-एंडेड सिंटैक्स का इस्तेमाल, यहां दिए गए कॉन्टेंट में ड्रिल-डाउन करने के लिए किया जा सकता है
आपकी साइट पर दस्तावेज़ों पर PageMaps; तो उसी सिंटैक्स का भी इस्तेमाल किया जा सकता है
अन्य सभी तरह के स्ट्रक्चर्ड डेटा के साथ
Google द्वारा समर्थित है, जिसमें से केवल
पेज की अनुमानित तारीख. आप
इन more:pagemap: ऑपरेटर का इस्तेमाल इसके साथ भी करता है
रिफ़ाइनमेंट लेबल या
छिपे हुए क्वेरी एलिमेंट
आपके ऐप्लिकेशन के लिए ज़रूरी एट्रिब्यूट के हिसाब से नतीजे फ़िल्टर करें.
इसलिए, असली उपयोगकर्ताओं को पाबंदी वाले इन क्वालीफ़ायर को सीधे टाइप नहीं करना होगा.
सर्च ऑपरेटर के हिस्सों को भी छोड़ा जा सकता है. ऊपर दिए गए उदाहरण में,
ध्यान दें कि PageMap एक DataObject document टाइप के बारे में बताता है और
author टाइप की एक विशेषता. हालांकि, यह ज़रूरी नहीं है कि आपकी साइट का हर पेज
हो सकता है कि सभी दस्तावेज़ों में लेखक के बारे में जानकारी न दी गई हो. अगर आपको
more:pagemap:document-author फ़ॉर्म के ऑपरेटर का इस्तेमाल करने पर,
दिखाए गए नतीजों में, author एट्रिब्यूट वाले सभी पेज शामिल होंगे
चाहे आप किसी भी समय document DataObject
एट्रिब्यूट है. इसी तरह, more:pagemap:document वापस लौटेगा
PageMaps से जुड़े वे सभी नतीजे जिनमें document टाइप के DataObjects हैं,
भले ही डेटा ऑब्जेक्ट में कौन-से फ़ील्ड हों.
पाबंदियों के लिए टेक्स्ट वैल्यू का टोकन बनाना
एट्रिब्यूट की ऐसी वैल्यू जिनमें स्पेस, विराम चिह्न या खास वर्ण शामिल हों करीब-करीब हमेशा अलग-अलग टोकन में बंटे होते हैं; उदाहरण के लिए, एट्रिब्यूट "Programmable Search Engine@google" की वैल्यू तीन अलग-अलग टोकन में बांट दिया जाएगा. "कस्टम", "खोज" और "google" है. इससे एक शब्द पर खोज की जा सकती है शब्दों और विराम चिह्नों के बड़े क्रम में एम्बेड किया गया हो. जैसे, प्रोडक्शन ब्यौरा. (Programmable Search Engine, हर स्ट्रिंग के लिए ज़्यादा से ज़्यादा 10 टोकन एक्सट्रैक्ट करेगा. इसलिए, अगर आपके विशेषता के मान में 10 से ज़्यादा शब्द हैं, इसलिए हो सकता है कि सीमित करने के लिए सभी उपलब्ध न हों results.) उदाहरण के लिए, नीचे दिए गए PageMap में Programmable Search Engine:
<PageMap>
<DataObject type="product">
<Attribute name="description">Programmable Search Engine provides customized search engines</Attribute>
</DataObject>
</PageMap>
यह पाबंदी, product-description वाले सभी पेजों पर लागू होगी
"search" के बारे में एट्रिब्यूट:
[more:pagemap:product-description:search]
टेक्स्ट वैल्यू को टोकन करने के अन्य नियम:
- पाबंदियों के लिए टेक्स्ट वैल्यू को लोअर केस में बदला जाता है
- छह टोकन तक की स्ट्रिंग के लिए, पूरी स्ट्रिंग के लिए एक अतिरिक्त पाबंदी जनरेट की जाती है,
खाली सेल को
_से बदल दिया गया है, जैसे किplease_attend. - स्टॉप शब्दों, the जैसे शब्दों के लिए अलग से प्रतिबंध जनरेट नहीं किए जाते a, लेकिन, और इसलिए, जो खोजने के लिए कम उपयोगी होते हैं. इसलिए, टेक्स्ट वैल्यू: "मुख्य बिंदु" मुख्य, पॉइंट के लिए प्रतिबंध जनरेट करेगा, और the_main_point, लेकिन the के लिए कोई पाबंदी जनरेट नहीं करेगा.
- प्रतिबंध बनाने के लिए, टेक्स्ट वैल्यू में सिर्फ़ पहले दस शब्दों का इस्तेमाल किया गया है.
-
विराम चिह्न वाले जिन वर्णों को डीलिमिटर नहीं माना जाता उन्हें अंडरस्कोर में बदला जाता है,
_.
कई पाबंदियों का इस्तेमाल करके, टोकन के तौर पर मौजूद वैल्यू के बारे में जानकारी हासिल करना
ज़्यादा गहराई से ड्रिल-डाउन करने के लिए, अन्य पाबंदियां जोड़ी जा सकती हैं; उदाहरण के लिए, सिर्फ़ सर्च इंजन के प्रॉडक्ट की जानकारी देने वाले पेज दिखाने के लिए, पाबंदियां जोड़ें:
[more:pagemap:product-description:search more:pagemap:product-description:engine]
more:pagemap: की पाबंदियों का क्रम अहम नहीं है;
टोकन, एट्रिब्यूट की वैल्यू से बिना क्रम वाले सेट में एक्सट्रैक्ट किए जाते हैं.
ये पाबंदियां डिफ़ॉल्ट रूप से एक AND के साथ जोड़ा जाता है; हालांकि, उन्हें एक साथ एक OR ऑपरेटर ताकि पाबंदी से मेल खाने वाले नतीजे मिल सकें. उदाहरण के लिए, नीचे दी गई खोज में खोज या गेम से जुड़ी जानकारी देने वाले कॉन्टेंट से मैच करेगा:
[more:pagemap:product-description:search OR more:pagemap:product-description:game]
टोकनाइज़ेशन का एक अपवाद, यूआरएल वाले एट्रिब्यूट की वैल्यू के लिए है. से यूआरएल के टोकन की उपयोगिता बहुत ज़्यादा होती है. हम इससे कोई टोकन जनरेट नहीं करते विशेषता मान सेट करें जो मान्य URL हैं.
कुछ मामलों में—उदाहरण के लिए, जब छोटे टोकन एक साथ मिलते हैं,
Programmable Search Engine उन्हें जोड़कर सुपर टोकन बना सकता है. उदाहरण के लिए, अगर टोकन
"राष्ट्रपति" और "ओबामा" Programmable Search Engine अक्सर एक-दूसरे के बगल में दिखता है, तो
एक सुपरटोकन "pResident_obama" बनाएं. इस वजह से, [more:pagemap:leaders-name:president_obama]
वही नतीजे दिखाएगा जो [more:pagemap:leaders-name:president AND more:pagemap:leaders-name:obama] के जैसा है.
विराम चिह्न के आधार पर टोकनाइज़ेशन का एक और मुख्य अपवाद यह है फ़ॉरवर्ड स्लैश '/' जब यह संख्याओं को अलग करता है. विशेषता के मान 'NUMBER/NUMBER' फ़ॉर्म का या 'NUMBER/NUMBER/NUMBER' इलाज किया जाता है आपस में जुड़े हुए एक टोकन के तौर पर; उदाहरण के लिए, '3.5/5.0' और '23/09/2006' उन्हें सिंगल टोकन माना जाता है. उदाहरण के लिए, खोजने के लिए, '2006/09/23' वैल्यू वाली किसी एट्रिब्यूट का इस्तेमाल करें, तो पाबंदी का इस्तेमाल करें:
[more:pagemap:birth-date:2006/09/23]
स्लैश के आधार पर शामिल होने की सुविधा सिर्फ़ तब काम करती है, जब फ़ॉरवर्ड स्लैश बिना स्पेस वाली संख्याएं; स्लैश और संख्या के बीच स्पेस इससे अलग-अलग टोकन बनाए जाते हैं. इसके अलावा, फ़ोन से जुड़े आंकड़ों को स्लैश के हिसाब से डेटा पूरी तरह मैच होना चाहिए; विशेषता के अनुसार फ़िल्टर करें ऑपरेटर इन वैल्यू को भिन्नों या तारीखों के रूप में नहीं समझना चाहिए. Programmable Search Engine अन्य संरचित खोज ऑपरेटर, जैसे एट्रिब्यूट के हिसाब से क्रम से लगाएं और रेंज तक सीमित करें, जानकारी दें इन संख्याओं को भिन्नों और तारीखों के रूप में लिखना; दस्तावेज़ यहां देखें: इसके लिए स्ट्रक्चर्ड डेटा देना देखें.
JSON-LD में इस्तेमाल होने वाली पाबंदियां
JSON-LD, स्ट्रक्चर्ड डेटा के लिए एक बेहतरीन और स्टैंडर्ड फ़ॉर्मैट है.
डेटा को JSON के तौर पर फ़ॉर्मैट किया जाता है और
type="application/ld+json" के साथ <script> टैग.
यहां कुछ सामान्य JSON-LD के साथ एचटीएमएल का एक छोटा सा हिस्सा दिखाया गया है: अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
<script type="application/ld+json"> { "@id": "http://event.example.com/events/presenting-foo", "@type": "http://schema.org/AggregateRating", "http://schema.org/ratingCount": "22", "http://schema.org/ratingValue": "4.4", "http://schema.org/itemReviewed": { "@type": "http://schema.org/Event", "http://schema.org/description": "Please attend.", "http://schema.org/name": "Presenting Foo", "http://schema.org/startdate": "2022-05-24", "http://schema.org/location": "Back room" } } </script>
इससे ये पाबंदियां जनरेट होंगी:
- more:pagemap:aggregaterating-ratingcount:22
- more:pagemap:aggregaterating-ratingvalue:4.4
- more:pagemap:aggregaterating-itemreviewed-event-description:please_attend
- more:pagemap:aggregaterating-itemreviewed-event-description:please
- more:pagemap:aggregaterating-itemreviewed-event-description:attend
- more:pagemap:aggregaterating-itemreviewed-event-name:presenting_foo
- more:pagemap:aggregaterating-itemreviewed-event-name:presenting
- more:pagemap:aggregaterating-itemreviewed-event-name:foo
- more:pagemap:aggregaterating-itemreviewed-event-startdate:2022-05-24
- more:pagemap:aggregaterating-itemreviewed-event-location:back_room
- more:pagemap:aggregaterating-itemreviewed-event-location:back
- more:pagemap:aggregaterating-itemreviewed-event-location:room
JSON-LD के लिए, हम सिर्फ़ रूट से पूरे पाथ के लिए पाबंदियां जनरेट करते हैं, शाखा के हिसाब से फ़िल्टर करें देखें. हालांकि, JSON-LD ट्री के रूट में लीफ़ नोड होते हैं, जो कि चाइल्ड नतीजे के तौर पर दिखने वाली पाबंदियों का फ़ॉर्म, एट्रिब्यूट की पाबंदियों की तरह ही होता है. इनमें से कुछ पाबंदी ऊपर दिया गया उदाहरण, रूट पर लीफ़ नोड से बनता है और एट्रिब्यूट की पाबंदी है (type-name-value) फ़ॉर्म, जैसे: more:pagemap:aggregaterating-ratingcount:22
ध्यान दें: अन्य स्ट्रक्चर्ड डेटा फ़ॉर्मैट, 128 बाइट तक की स्ट्रिंग की अनुमति देते हैं, लेकिन JSON-LD, सभी स्ट्रिंग को करीब 50 वर्णों तक छोटा कर दिया जाता है—यह कोशिश रहती है कि यह खत्म न हो स्ट्रिंग को फिर से शुरू करें. शब्दों की लंबाई के हिसाब से, इससे जनरेट किए गए टोकन की संख्या सीमित हो सकती है 10 टोकन की सीमा से ज़्यादा कड़ाई से स्ट्रिंग.
विशेषता के मुताबिक क्रम से लगाएं
कभी-कभी, खोज को किसी खास तरह के नतीजे तक सीमित करना ही काफ़ी नहीं होता;
उदाहरण के लिए, किसी रेस्टोरेंट की समीक्षाओं में,
रेट किया है. यह लक्ष्य हासिल किया जा सकता है
के साथ Programmable Search Engine, एट्रिब्यूट के हिसाब से क्रम में लगाने की सुविधा देता है. इससे,
स्ट्रक्चर्ड डेटा एट्रिब्यूट की वैल्यू के आधार पर नतीजों का क्रम.
एक
&sort=TYPE-NAME:DIRECTION अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
आपके Programmable Search Engine के लिए अनुरोध किए गए यूआरएल का यूआरएल पैरामीटर.
स्ट्रक्चर्ड खोज की तरह, एट्रिब्यूट के हिसाब से क्रम में लगाने के लिए, स्ट्रक्चर्ड डेटा का इस्तेमाल
आपके पेज; से अलग, स्ट्रक्चर्ड खोज से अलग होता है, तो क्रम में लगाने के लिए
फ़ील्ड में एक संख्यात्मक व्याख्या होती है, जैसे कि संख्याएं और तारीखें.
सबसे आसान फ़ॉर्मैट में, स्ट्रक्चर्ड डेटा टाइप तय करने पर,
डेटा ऑब्जेक्ट टाइप और
किसी PageMap में एट्रिब्यूट का नाम डालें और उसे अनुरोध यूआरएल में इस तौर पर जोड़ें
&sort=TYPE-NAME. उदाहरण के लिए,
ऐसे पेज पर तारीख जो अपने डेटा को date टाइप के तौर पर दिखाता है
और नाम sdate के लिए, इस सिंटैक्स का इस्तेमाल करें:
https://www.google.com/cse?cx=000525776413497593842:aooj-2z_jjm&q=comic+con&sort=date-sdate
यह डिफ़ॉल्ट रूप से घटते क्रम में हार्ड सॉर्ट करता है - यानी,
खोज के नतीजों को सिर्फ़ तारीख के हिसाब से क्रम में लगाया जाता है. इनमें सबसे हाल ही के
(जो सबसे बड़ी संख्याओं में बदल जाती हैं) पहले ऑर्डर की जाती हैं.
अगर आपको, क्रम से लगाने के क्रम को बढ़ते क्रम में बदलना है, तो
:a फ़ील्ड में जोड़ें या साफ़ तौर पर :d को जोड़ें
घटते क्रम में बताएं). उदाहरण के लिए, सबसे पुराने नतीजे पहले दिखाने के लिए,
तो इस फ़ॉर्म पर लगाई गई पाबंदी का इस्तेमाल किया जा सकता है:
https://www.google.com/cse?cx=000525776413497593842:aooj-2z_jjm&q=comic+con&sort=date-sdate:a
आपके इंजन के क्रम से लगाए गए नतीजे, उन वैल्यू के आधार पर दिखाए जाते हैं
है, जो उस DataObject और विशेषता के लिए अपने PageMaps में होता है. पेज
जिसमें PageMaps नहीं है, डेटा ऑब्जेक्ट का टाइप या उसके लिए पार्स किया जा सकने वाला मान नहीं है
विशेषता हार्ड क्रम में नहीं दिखेगी. ऊपर दिए गए उदाहरण में, पेज
date-sdate एट्रिब्यूट के बिना, नहीं दिखेगा
नतीजों में दिखाया जा सकता है. हार्ड सॉर्टिंग को विशेषता के अनुसार बायस के साथ नहीं जोड़ा जा सकता
अगले सेक्शन में बताई गई सुविधा के बारे में नहीं बताया है, लेकिन इसे एक साथ जोड़ा जा सकता है.
एट्रिब्यूट के हिसाब से फ़िल्टर करें और
रेंज तक सीमित करें.
विशेषता के अनुसार पूर्वाग्रह
कभी-कभी आप बिना कोई मान वाले परिणामों को छोड़ना नहीं चाहते;
उदाहरण के लिए, आपको लेबनीज़ पकवान के बारे में खोजना है; कई तरह के
शुद्ध लेबनीज़ (सबसे प्रासंगिक) से लेकर
ग्रीक (सबसे कम काम का). इस मामले में, मज़बूत या कमज़ोर सिग्नल वाली क्वेरी का इस्तेमाल किया जा सकता है.
भेदभाव वाली सोच होती है. इसकी वजह से, आपके
मान लेकिन उन परिणामों को नहीं दिखाएगा जिनमें इसकी कमी है. आप तय करें कि
या क्रम से लगाने की दिशा के बाद दूसरी वैल्यू जोड़कर कमज़ोर मापदंड से बाहर हो सकता है:
&sort=TYPE-NAME:DIRECTION:STRENGTH,
पूर्वाग्रह के लिए :s या
कमज़ोर पक्षपात के लिए :w (और कठिन के लिए :h
क्रम से लगाएं. हालांकि, :h जोड़ना ज़रूरी नहीं है, क्योंकि यह डिफ़ॉल्ट है).
उदाहरण के लिए, बहुत ज़्यादा पूर्वाग्रह जोड़ने से यह पक्का होगा कि
सबसे अच्छी रेटिंग वाले मेडिटरेनियन रेस्टोरेंट, सबसे खराब रेटिंग वाले रेस्टोरेंट से बेहतर परफ़ॉर्म करेंगे
मेडिटरेनियन रेस्टोरेंट, लेकिन इस बात की संभावना कम है कि वे बेहतर रैंक पाएं
लेबनीज़ रेस्टोरेंट के लिए एग्ज़ैक्ट मैच वाला कीवर्ड:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-rating:d:s
एक से ज़्यादा पूर्वाग्रहों को कॉमा ऑपरेटर का इस्तेमाल करके जोड़ा जा सकता है:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-rating:d:s,review-pricerange:d:w
पक्षपातों के क्रम से कोई फ़र्क़ नहीं पड़ता. हालांकि, हार्ड सॉर्ट को किसी अन्य क्रम के साथ जोड़ा नहीं जा सकता, क्योंकि यह लागू होता है मैसेज का क्रम सख्त है. सूची में क्रम से लगाने वाला आखिरी ऑपरेटर सभी पिछले सॉर्ट और बायस ऑपरेटर को ओवरराइड कर देता है.
रेंज तक सीमित
वैल्यू की रेंज के बीच या वैल्यू से ज़्यादा या कम नतीजे शामिल करने के लिए,
किसी रेंज की पाबंदी का इस्तेमाल करें. रेंज की सीमाएं :r से तय की जाती हैं
विशेषता के नाम के बाद ऊपरी और निचली सीमा के बाद
विशेषता मान: &sort=TYPE-NAME:r:LOWER:UPPER.
उदाहरण के लिए, केवल मार्च और अप्रैल के बीच लिखी गई समीक्षाओं को शामिल करने के लिए
2009 के बाद, आप इनमें से एक रेंज की पाबंदी तय कर सकते हैं:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-date:r:20090301:20090430
श्रेणी तक सीमित करें ऑपरेटर के लिए, Google नंबरों का समर्थन करता है
फ़्लोट फ़ॉर्मैट और तारीख में
आईएसओ 8601
डैश के बिना YYYYMMDD.
आपको ऊपरी या निचली सीमा में से किसी एक को बताने की ज़रूरत नहीं है: के लिए उदाहरण के लिए, सिर्फ़ 2009 से पहले की तारीखें बताने के लिए, आप यह लिख सकते हैं:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=review-date:r::20091231
सिर्फ़ तीन स्टार से ज़्यादा रेटिंग शामिल करने के लिए, इनका इस्तेमाल करें:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars:r:3.0
रेंज शामिल होती हैं और इन्हें कॉमा ऑपरेटर के साथ जोड़ा जा सकता है या एक-दूसरे से या एक क्रम या एक या ज़्यादा पूर्वाग्रह की शर्तों के साथ. नोट जोड़ें जो श्रेणी प्रतिबंध को सॉर्ट और पूर्वाग्रह मानदंड, दोनों के साथ संयोजित करते हैं, नतीजे में, इस रेंज में मौजूद वैल्यू वाले आइटम ही क्रम से लगाए जाते हैं. उदाहरण के लिए, केवल तीन या ज़्यादा स्टार वाले आइटम की रेटिंग के अनुसार क्रमबद्ध करने के लिए, इनका उपयोग करें:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars,rating-stars:r:3.0
आप एक मानदंड को क्रमित कर सकते हैं और दूसरे पर श्रेणी के अनुसार सीमित कर सकते हैं. उदाहरण के लिए, सिर्फ़ इस महीने में समीक्षा किए गए आइटम की रेटिंग के हिसाब से क्रम में लगाने के लिए: अक्टूबर, इनका इस्तेमाल करें:
https://www.google.com/cse?cx=12345:example&q=lebanese+restaurant&sort=rating-stars,review-date:r:20101001:20101031
इमेज सर्च
जब अपने सर्च इंजन के लिए इमेज सर्च की सुविधा चालू की जाती है, तो Google एक अलग टैब में इमेज के नतीजे दिखाता है. Programmable Search Engine के कंट्रोल पैनल का इस्तेमाल करके याcontext.xml फ़ाइल को अपडेट करके, इमेज खोजने की सुविधा को चालू किया जा सकता है.
इमेज सर्च उस जानकारी का इस्तेमाल करती है जिसे Google आपकी साइट क्रॉल करते समय ढूंढता है. Programmable Search Engine और Google Web Search के खोज नतीजों में इमेज किस तरह दिखें, इसे बेहतर बनाने के लिए, Google के इमेज पब्लिश करने से जुड़े दिशा-निर्देशों के बारे में जान लेना बेहतर होगा.
इमेज एट्रिब्यूट के हिसाब से फ़िल्टर करें
Web Search की तरह, इमेज सर्च से भी src, alt, और title जैसे एट्रिब्यूट को फ़िल्टर किया जा सकता है.
Programmable Search एलिमेंट में स्ट्रक्चर्ड खोज
स्ट्रक्चर्ड खोज फ़ीचर को Google के साथ मिलाकर भी इस्तेमाल किया जा सकता है
Programmable Search एलिमेंट. जैसा कि क्वेरी में बताए गए ऑपरेटर के साथ किया जाता है
नहीं है, तो एलीमेंट में संरचित खोज के लिए पहले वह होना ज़रूरी है
जिन पेजों पर आप खोज कर रहे हैं, उन्हें आपकी पसंद की विशेषताओं के साथ मार्क अप किया गया हो
खोजने के लिए; इसके बाद, Programmable Search Element का sort ऑपरेटर
क्वेरी में more:pagemap: ऑपरेटर के साथ जोड़े जाने पर
खोज के नतीजों को सही तरीके से क्रम से लगा सकते हैं या प्रतिबंधित कर सकते हैं.
उदाहरण के लिए, कैलिफ़ोर्निया का एक समाचार पोर्टल SignOnSanDiego.com, Programmable Search Element, खोज नतीजों में फ़ोटो के साथ हाल ही की खबरों को रेंडर करने के लिए:
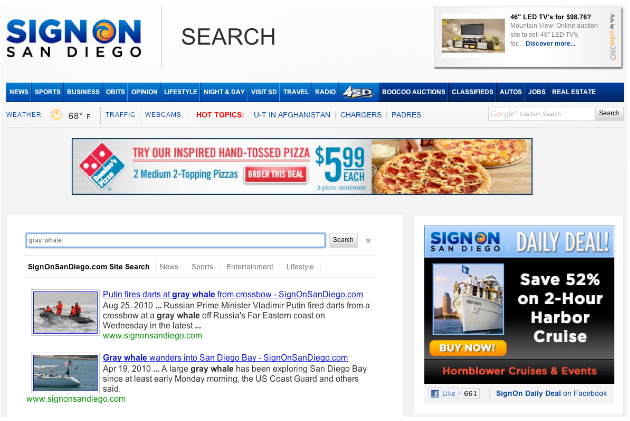
यह पक्का करने के लिए कि पाठक सिर्फ़ सबसे काम की खबरें ही नहीं, बल्कि सही समय पर भी देख सकें, SignOnSanDiego, विशेषता के अनुसार पूर्वाग्रह का इस्तेमाल एक "मज़बूत" के साथ करता है वज़न की दिशा हाल के पब्लिकेशन की तारीखें. SignOnSanDiego इन तारीख एट्रिब्यूट को लागू करता है PageMaps से; जो SignOnSanDiego में इस्तेमाल किया जाता है, वह ऐसा दिखता है:
<!-- <PageMap> <DataObject type="date"> <Attribute name="displaydate" value="Wednesday, August 25, 2010"/> <Attribute name="sdate" value="20100825"/> </DataObject> <DataObject type="thumbnail"> <Attribute name="src" value="http://media.signonsandiego.com/img/photos/2010/08/25/635a63e9-f4a1-45aa-835a-ebee666b82e0news.ap.org_t100.jpg"/> <Attribute name="width" value="100"/> </DataObject> </PageMap> -->
इस फ़ील्ड में विशेषता के अनुसार क्रम से लगाएं लागू करने के लिए, आप
इसके लिए खोज कोड में sort विकल्प होता है:
Programmable Search एलिमेंट, जैसा कि नीचे दिखाया गया है:
... <div class="gcse-search" sort_by="date-sdate:d:s"></div> ...
ऊपर बताए गए यूआरएल &sort= पैरामीटर की तरह ही, Programmable Search एलिमेंट में क्रम से लगाने का विकल्प
<div class="gcse-search" sort_by="date-sdate:d:s"></div>
एक मिला-जुला एट्रिब्यूट नाम लेता है, जैसे कि date-sdate और कई वैकल्पिक नाम होते हैं
कोलन से अलग किए गए पैरामीटर. इस मामले में, SignOnSanDiego ने बताया
ज़्यादा पूर्वाग्रह के हिसाब से d को घटते क्रम में लगाया जा रहा है
ऑपरेटर का s फ़्लेवर. अगर आप
क्वालिफ़ायर के तौर पर, हार्ड क्रम के साथ घटते क्रम में डिफ़ॉल्ट रूप से सेट होता है,
की तरह ही काम करता है.
क्रम से लगाने का विकल्प, 'सीमा के हिसाब से सीमित करें' सुविधा को भी चालू करता है. उदाहरण के लिए
SignOnSanDiego जैसी साइट, उपयोगकर्ताओं को लेख खोजने में मदद कर सकती है
जो 25 अगस्त से 9 सितंबर, 2010 के बीच पब्लिश किए गए थे. इसे लागू करने के लिए,
तो क्रम से लगाने के विकल्पों को
date-sdate:r:20100825:20100907. यह फिर से संयुक्त
एट्रिब्यूट नाम date-sdate, लेकिन इसके बजाय
दर्ज मान 20100825:20100907 में से r श्रेणी.
यूआरएल पैरामीटर की तरह ही, यूआरएल पैरामीटर की तरह ही, यूआरएल पैरामीटर के ऊपर या नीचे वाला आइटम छोड़ा जा सकता है
Programmable Search एलिमेंट के sort विकल्प की रेंज में होता है.
क्रम से लगाएं विकल्प की एक और बेहतरीन सुविधा यह है कि आप इसके हिसाब से क्रम में लगाएं
विशेषता और श्रेणी के हिसाब से सीमित करें. एक से ज़्यादा ऑपरेटर को
को कॉमा का इस्तेमाल करके, क्रम से लगाने का विकल्प चुना जा सकता है. उदाहरण के लिए,
ऊपर बताई गई तारीख की पाबंदी की वजह से SignOnSanDiego में काफ़ी फ़र्क़ पड़ रहा है, तो
date-sdate:d:s,date-sdate:r:20100825:20100907 तय करें. यह
सुविधा में अलग-अलग एट्रिब्यूट को मिलाया जा सकता है; उदाहरण के लिए, किसी फ़िल्म की समीक्षा
साइट पिछले 15 दिनों में रिलीज़ हुई, सबसे ज़्यादा रेटिंग वाली फ़िल्में दिखा सकती है
review-rating,release-date:r:20100907: विकल्प के साथ एक हफ़्ता.
इस्तेमाल किए जा सकने वाले सभी एट्रिब्यूट के बारे में जानने के लिए, कृपया यह पेज देखें.
Programmable Search एलिमेंट के साथ, एट्रिब्यूट के हिसाब से फ़िल्टर करने की सुविधा का इस्तेमाल भी किया जा सकता है.
उदाहरण के लिए, हमारे पहले के उदाहरण को
ऐसे पेज जिनमें linked-blog एट्रिब्यूट थे; कस्टम बनाने के लिए
खोज नियंत्रण से केवल वे पेज दिखाई देते हैं, जो नीचे दिए गए कोड का उपयोग करने के लिए लिंक किए गए थे
में more:pagemap:linked-blog:blogspot ऑपरेटर इंजेक्ट करने के लिए
हर क्वेरी:
... <div class="gcse-search" webSearchQueryAddition="more:pagemap:linked-blog:blogspot"></div> ...
यह तरीका अन्य प्लैटफ़ॉर्म पर लागू नहीं होता, क्योंकि यह सभी इस कंट्रोल से जारी की गई क्वेरी. अन्य विकल्प देखने के लिए, दस्तावेज़ देखें पूरी तरह कैसे Programmable Search एलिमेंट.
अन्य सुविधाओं के बारे में जानना
स्ट्रक्चर्ड खोज की सुविधाओं का इस्तेमाल करके, कई तरह के विकल्पों का इस्तेमाल किया जा सकता है. अपने खोज ऐप्लिकेशन पर बहुत ज़्यादा नियंत्रण रहता है. इसकी मदद से कस्टम विशेषताओं का उपयोग करके आप खोज परिणामों को बहुत को भी बनाए रखता है. स्ट्रक्चर्ड खोज की सुविधा, इनके साथ भी अच्छी तरह से काम करती है Programmable Search Engine की अन्य सुविधाएं, जैसे कि कस्टम रिज़ल्ट के स्निपेट. अधिक जानकारी के लिए:
- अगर आपको इस बारे में ज़्यादा जानना है कि Google किस तरह के स्ट्रक्चर्ड डेटा स्ट्रक्चर्ड डेटा उपलब्ध कराना देखें.
- अगर आपको स्निपेट के लिए स्ट्रक्चर्ड डेटा का इस्तेमाल करने के बारे में ज़्यादा जानना है, अपने नतीजे के स्निपेट को पसंद के मुताबिक बनाना देखें.