
Cloud Search のクエリ解釈機能は、ユーザーのクエリ内の演算子とフィルタを自動的に解釈し、それらの要素を構造化された演算子ベースのクエリに変換します。クエリ解釈では、インデックス付きドキュメントとともに、スキーマで定義された演算子を使用して、ユーザのクエリの意味を推測します。この機能により、ユーザーは最小限のキーワードで検索できるとともに、正確な結果が得られます。
ユーザーに提示される実際の結果は、クエリ解釈の信頼度に依存します。信頼度は、クエリ文字列がインデックス付きドキュメントのどこに現れるかなど、いくつかの要因に基づきます。俳優の名前「Tom Hanks」などの文字列が、actors というスキーマ フィールドに一貫して現れる場合、結果として信頼度が高くなります。同じ文字列(「Tom Hanks」)がスキーマ フィールドではなく段落内に表示されると、信頼度が低下する可能性があります。信頼度が高い場合、クエリ解釈からの結果のみがユーザーに表示されます。信頼度が低い場合、クエリ解釈からの結果に混ざり通常のキーワード検索結果が表示されます。
クエリ解釈の例
映画に関する情報を含むデータベースなどのデータソースがあるとします。図 1 は、検索クエリの例とその結果の解釈を示しています。
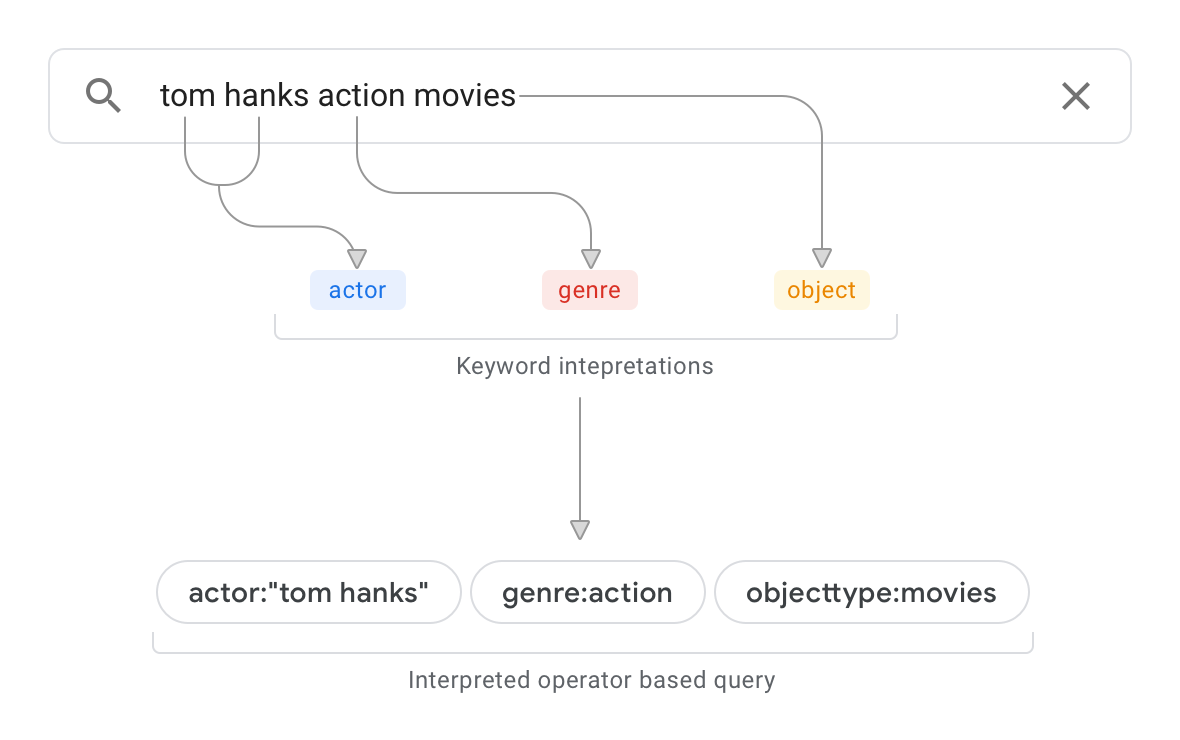
このクエリの例では、クエリ解釈によって次のことが行われます。
スキーマを解析し、データソース内の最上位のオブジェクトが
objecttype:moviesに分類されることを判別します。上記のクエリ解釈では、クエリ内の「movies」がオブジェクト タイプであることが認識されています。スキーマを併用してデータソース内のドキュメントをスキャンし、文字列「action」が現れる場所を特定します。この文字列が主に特定の「genre」データソース フィールドに現れる場合、クエリ解釈では、「action」がスキーマで定義されたプロパティ「genre」のプロパティ値であることを確実にします。この文字列が主にコンテンツの段落のコンテキスト内に現れる場合、クエリ解釈の信頼レベルは低下します。
結果のクエリ解釈は次のようになります。
actor:“tom hanks” genre:action objecttype:movies
クエリ解釈は、追加の作業なしで、すべての Cloud Search のお客様に対して自動的に有効になります。ただし、最適なクエリ解釈を実現するためには、このドキュメントの指示に従ってスキーマを構造化する必要があります。
クエリ解釈をサポートするためにスキーマを構造化する
クエリ解釈を活用できるようにスキーマを構造化する必要があります。
表示名の解釈を有効にする
Cloud Search のクエリ解釈では、スキーマの objectDefinitions と propertyDefinitions を使用して、ユーザーのクエリを解釈し、結果を調整します。これらのスキーマ要素のメリットを最大限に活用するには、プロパティ名には displayLabel、オブジェクト名には objectDisplayLabel、演算子には operatorName を使用して、直感的な表示名を作成する必要があります。
次のスキーマは、映画オブジェクトの直感的な表示名を示しています。
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
上記の例では、次のようになっています。
映画オブジェクトの定義には「Film」
objectDisplayLabelがあります。genre の propertyDefinition には、「genre」
operatorNameと「Category」displayLabelがあります。
これらの表示名により、Cloud Search では次のクエリ解釈を行うことができます。
- 「action movies」、「genre action type movies」、「movies genre action」は
genre:action object:moviesとして解釈されます。 - 「movies with genre action or thriller」は、
objecttype:movies genre:(action OR thriller)として解釈されます。 - 「action film」または「action films」は、
genre:action objecttype:moviesとして解釈されます。 - 「comedy category movies」は
genre:comedy objecttype:moviesとして解釈されます。
日付、数値、並べ替えの解釈を有効にする
すべての日付プロパティと数値プロパティに、IntegerOperatorOptions で指定されている lessThanOperatorName と greaterThanOperatorName を定義する必要があります。これらの設定により、日付と数値の自動解釈が可能になります。さらに、並べ替えの解釈を有効にするには、日付と数値のプロパティに isSortable オプションを設定します。次のスキーマは、これらのオプションを有効にする方法を示しています。
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
上記の例では、次のようになっています。
- 数値プロパティ
runtimeは、映画の長さを示しています。このプロパティにはruntimelessthanとruntimegreaterthanが設定されています。 - 日付プロパティ
releaseDateは、映画が映画館で公開される日付を示します。このプロパティにはreleasedbeforeとreleasedafterが設定されています。
これらの設定により、Cloud Search では次のクエリ解釈を行うことができます。
- 年が 2019 年だとすると、「movies released this year」は
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31として解釈されます。 - 週が 3 月の 3 週目だとすると、「movies released last week」は
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16として解釈されます - 「movies with runtime less than 90」は
objjecttype: movies runtimelessthan:90として解釈されます。 - 年が 2019 年だとすると、「movies released this year and length more than 120」は
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120として解釈されます。 - 「sort movies by release date」の場合は「objecttype: movies」でフィルタリングが実行され、表示される結果は公開日で並べ替えられます。デフォルトの並べ替え順は昇順です。
予約済み演算子の解釈を有効にする
type、before、after、objecttype の予約済み組み込み演算子を使用して、クエリ解釈の機能を高めることもできます。ドキュメントをインデックス付けするときは、次のようにしてください。
before演算子とafter演算子を使用するには、ItemMetadataのupdateTimeフィールドに値を設定します。これらの設定により、Cloud Search では次のクエリ解釈を行うことができます。- 「movies from last week」は、先週インデックス内で更新されたすべての映画を一覧表示します。
- 「movies before jan 2019」は、2019 年 1 月以前にインデックスに登録されたすべての映画を一覧表示します。
ItemMetadataのmimeTypeフィールドを、タイプの自動検出を使用するように入力します。「action videos」というクエリは、MIME タイプがapplication/mp4、application/mpeg4、application/x-shockwave-flash、video/、application/vnd.google-apps.videoのすべてのアクション映画を一覧表示します。
クエリ解釈の制限
クエリ解釈機能には次の制限があります。
- クエリ解釈は、次のデータソース ACL に対してのみ機能します。
- すべてのドキュメントがドメイン公開にされている(ドメイン内の全員がアクセスできる)。
- すべてのドキュメントがデータソース公開にされている(データソース ACL にアクセスできるすべての人)。
- データソース内のドキュメントの大多数は同じ ACL を持ち(すべてのドキュメントが同じコンテナ アイテムから ACL を継承する)、追加のリーダーが定義されていない。
- 複数のスキーマ演算子が同じ値を持つ場合、クエリについての演算子の意図に対するその値の解釈は、クエリ解釈システムによって返される総合的な信頼度係数に依存します。たとえば、プロパティ
priorityとseverityにスキーマ内で同じ演算子名が定義されているとします。このとき、両方の演算子が 0、1、2、または 3 の値を持つことができるとします。この例では、クエリ内の「0」は、priorityまたはseverityのいずれかの演算子値を指している可能性があります。これらの値は曖昧なため、信頼レベルは低くなります。 - デフォルトでは、Cloud Search のクエリ解釈ではクエリを解釈するときにフィールド値の大文字を小文字にします(
exactMatchWithOperatorオプションで定義されたテキスト演算子を除く)。 source演算子はクエリでサポートされていません。- 演算子ベースの用語とフリーテキスト形式の用語を組み合わせたクエリは解釈されません。たとえば、「p0 priority cases severity:s0」というクエリはサポートされません。これは、「p0 priority cases」はフリーテキスト形式の用語で、「severity:s0」は演算子ベースの用語であるためです。
- クエリ解釈戦略では、解釈された結果と通常の(解釈されていない、関連性でランク付けされている)結果が常にブレンドされます。結果の全ページ置換は実行されません。