La biblioteca de fuentes de datos de visualización de Google facilita la creación de una fuente de datos de visualización. La biblioteca implementa el lenguaje de consulta y el protocolo de conexión de la API de visualización de Google. Solo escribes el código necesario a fin de que tus datos estén disponibles para la biblioteca en forma de tabla de datos. Una tabla de datos es una tabla bidimensional de valores en la que cada columna es de un solo tipo. La provisión de clases abstractas y funciones auxiliares facilita la escritura del código que necesitas.
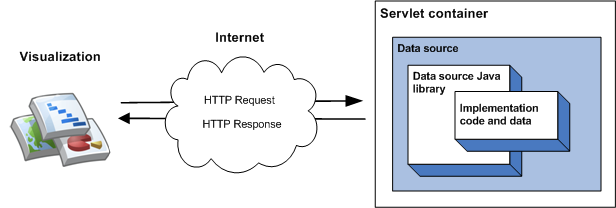
La implementación más simple de la biblioteca implica heredar de una sola clase, implementar una función de miembro y ejecutar la fuente de datos como un servlet en un contenedor de servlet. En la implementación más simple, la siguiente secuencia de eventos ocurre cuando una visualización consulta la fuente de datos:
- El contenedor de servlet controla la consulta y la pasa a la biblioteca de Java de la fuente de datos.
- La biblioteca analiza la consulta.
- El código de implementación, el código que escribes, muestra una tabla de datos en la biblioteca.
- La biblioteca ejecuta la consulta en la tabla de datos.
- La biblioteca procesa la tabla de datos en la respuesta que espera la visualización.
- El contenedor de servlet muestra la respuesta a la visualización.
Esto se ilustra en el siguiente diagrama:
En la sección Introducción a las fuentes de datos, se describe cómo implementar este tipo de fuente de datos.
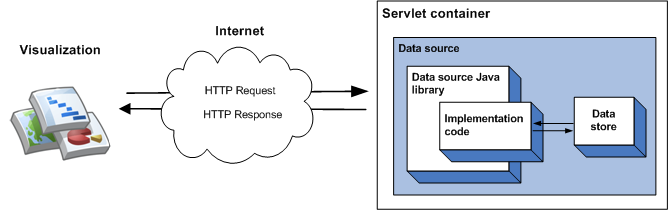
Los datos que entrega una fuente de datos se pueden especificar en tu código de implementación, lo cual está bien para cantidades pequeñas de datos estáticos. Para conjuntos de datos más grandes, es más probable que necesites usar un almacén de datos externo, como un archivo externo o una base de datos. Si una fuente de datos usa un almacén de datos externo, ocurre la siguiente secuencia de eventos cuando una visualización consulta la fuente de datos:
- El contenedor de servlet controla la consulta y la pasa a la biblioteca de Java de la fuente de datos.
- La biblioteca analiza la consulta.
- El código de implementación (el código que escribes) lee los datos almacenados en el almacén de datos y muestra una tabla de datos en la biblioteca. Si el conjunto de datos es grande y el almacén de datos tiene capacidades de consulta, puedes usar esas capacidades de forma opcional para aumentar la eficiencia de la fuente de datos.
- La biblioteca ejecuta la consulta en la tabla de datos.
- La biblioteca procesa la tabla de datos en la respuesta que espera la visualización.
- El contenedor de servlet muestra la respuesta a la visualización.
Esto se ilustra en el siguiente diagrama:
En la sección Cómo usar un almacén de datos externo se describe cómo implementar este tipo de fuente de datos.