
Google Docs API를 사용하면 문서의 모든 탭에서 콘텐츠에 액세스할 수 있습니다.
탭이란 무엇인가요?
Google Docs에는 탭이라는 조직 레이어가 있습니다. Docs를 사용하면 현재 Sheets에 탭이 있는 것과 마찬가지로 단일 문서 내에서 하나 이상의 탭을 만들 수 있습니다. 각 탭에는 자체 제목과 ID (URL에 추가됨)가 있습니다. 탭에는 다른 탭 아래에 중첩된 탭인 하위 탭이 있을 수도 있습니다.
문서 리소스에서 문서 콘텐츠가 표현되는 방식의 구조적 변경사항
이전에는 문서에 탭 개념이 없었으므로 Document 리소스에 다음 필드를 통해 모든 텍스트 콘텐츠가 직접 포함되었습니다.
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
탭의 추가 구조적 계층을 사용하면 이러한 필드가 더 이상 문서의 모든 탭에 있는 텍스트 콘텐츠를 의미적으로 나타내지 않습니다. 이제 텍스트 기반 콘텐츠가 다른 레이어로 표시됩니다. Google Docs의 탭 속성과 콘텐츠는 document.tabs를 사용하여 액세스할 수 있습니다. document.tabs는 Tab 객체 목록이며, 각 객체에는 위에 언급된 모든 텍스트 콘텐츠 필드가 포함되어 있습니다. 후반부 섹션에서는 간략한 개요를 제공하며, 탭 JSON 표현에서도 자세한 정보를 확인할 수 있습니다.
액세스 탭 속성
탭의 ID, 제목, 위치 등의 정보를 포함하는 tab.tabProperties를 사용하여 탭 속성에 액세스합니다.
탭 내 텍스트 콘텐츠 액세스
탭 내의 실제 문서 콘텐츠는 tab.documentTab로 노출됩니다.
앞서 언급한 텍스트 콘텐츠 필드는 모두 tab.documentTab를 사용하여 액세스할 수 있습니다. 예를 들어 document.body 대신 document.tabs[indexOfTab].documentTab.body를 사용해야 합니다.
탭 계층 구조
하위 탭은 API에서 Tab의 tab.childTabs 필드로 표현됩니다. 문서의 모든 탭에 액세스하려면 하위 탭의 '트리'를 순회해야 합니다. 예를 들어 다음과 같은 탭 계층 구조가 포함된 문서를 살펴보겠습니다.
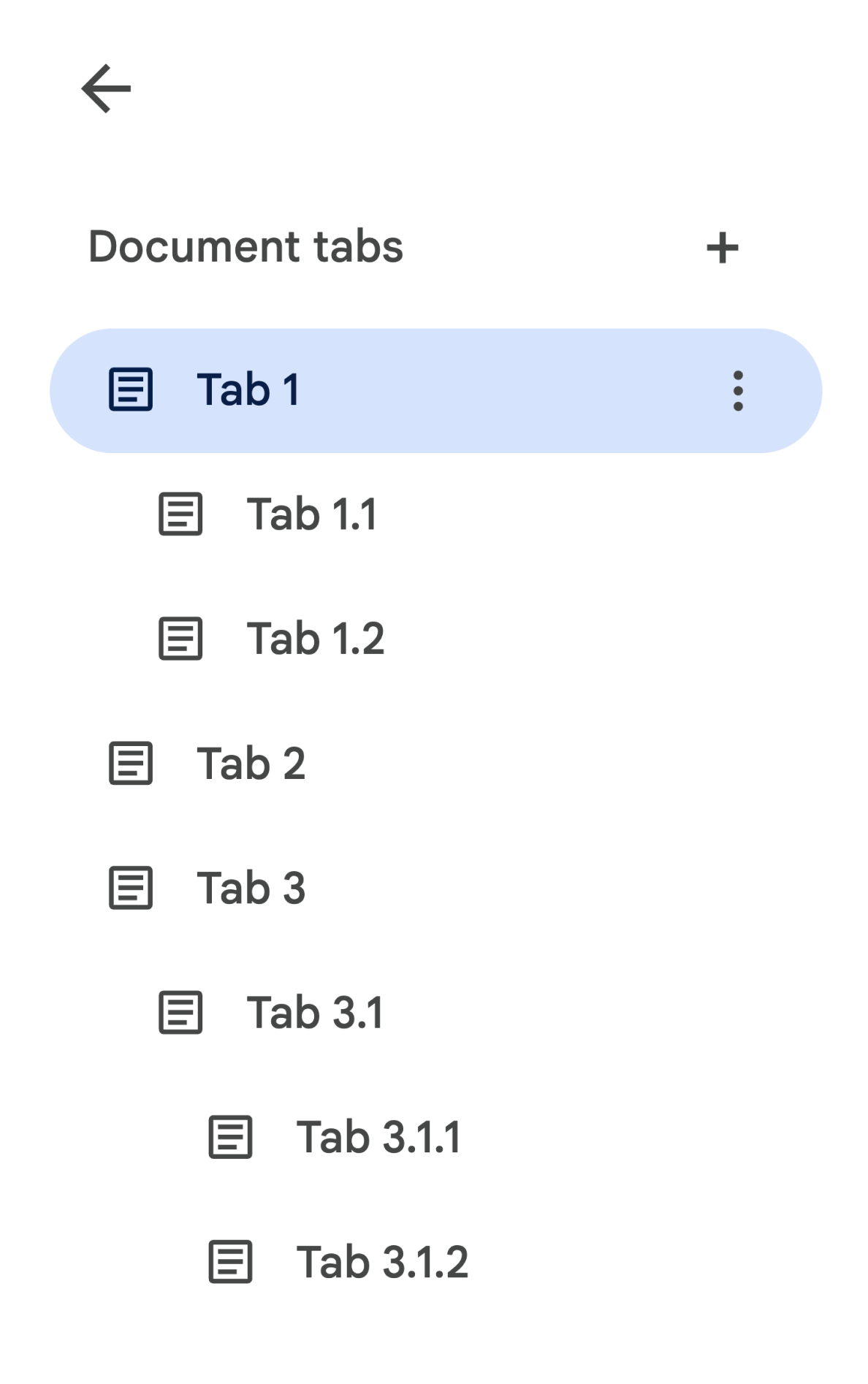
탭 3.1.2에서 Body를 가져오려면 document.tabs[2].childTabs[0].childTabs[1].documentTab.body에 액세스합니다. 문서의 모든 탭을 반복하는 샘플 코드를 제공하는 뒷부분의 샘플 코드 블록을 참고하세요.
메서드 변경사항
탭이 도입됨에 따라 각 문서 메서드에 몇 가지 변경사항이 적용되어 코드를 업데이트해야 할 수 있습니다.
documents.get
기본적으로 일부 탭 콘텐츠는 반환되지 않습니다. 개발자는 모든 탭에 액세스할 수 있도록 코드를 업데이트해야 합니다. documents.get 메서드는 모든 탭의 콘텐츠가 대답에 제공되는지 여부를 구성할 수 있는 includeTabsContent 매개변수를 노출합니다.
includeTabsContent이true로 설정되면documents.get메서드는document.tabs필드가 채워진Document리소스를 반환합니다.document에 직접 있는 모든 텍스트 필드 (예:document.body)는 비워 둡니다.includeTabsContent가 제공되지 않으면Document리소스의 텍스트 필드 (예:document.body)가 첫 번째 탭의 콘텐츠로만 채워집니다.document.tabs필드가 비어 있고 다른 탭의 콘텐츠는 반환되지 않습니다.
documents.create
documents.create 메서드는 생성된 빈 문서를 나타내는 Document 리소스를 반환합니다. 반환된 Document 리소스는 문서의 텍스트 콘텐츠 필드와 document.tabs 모두에서 빈 문서 콘텐츠를 채웁니다.
document.batchUpdate
각 Request에는 업데이트를 적용할 탭을 지정하는 방법이 포함되어 있습니다. 기본적으로 탭을 지정하지 않으면 대부분의 경우 Request이 문서의 첫 번째 탭에 적용됩니다.
ReplaceAllTextRequest,
DeleteNamedRangeRequest,
ReplaceNamedRangeContentRequest은 모든 탭에 기본적으로 적용되는 세 가지 특별 요청입니다.
자세한 내용은 Request 문서를 참고하세요.
내부 링크 변경사항
사용자는 문서의 탭, 북마크, 제목으로 연결되는 내부 링크를 만들 수 있습니다.
탭 기능이 도입됨에 따라 Link 리소스의 link.bookmarkId 및 link.headingId 필드가 더 이상 문서의 특정 탭에 있는 북마크나 제목을 나타낼 수 없습니다.
개발자는 읽기 및 쓰기 작업에서 link.bookmark 및 link.heading을 사용하도록 코드를 업데이트해야 합니다. 이러한 객체는 BookmarkLink 및 HeadingLink 객체를 사용하여 내부 링크를 노출하며, 각 객체에는 북마크 또는 제목의 ID와 해당 북마크 또는 제목이 있는 탭의 ID가 포함됩니다. 또한 link.tabId는 탭에 대한 내부 링크를 노출합니다.
documents.get 대답의 링크 콘텐츠는 includeTabsContent 매개변수에 따라 달라질 수도 있습니다.
includeTabsContent이true로 설정되면 모든 내부 링크가link.bookmark및link.heading로 노출됩니다. 레거시 필드는 더 이상 사용되지 않습니다.includeTabsContent가 제공되지 않으면 단일 탭이 포함된 문서에서 해당 단일 탭 내의 북마크 또는 제목으로 연결되는 내부 링크가link.bookmarkId및link.headingId로 계속 표시됩니다. 탭이 여러 개 포함된 문서에서 내부 링크는link.bookmark및link.heading로 표시됩니다.
document.batchUpdate에서 기존 필드 중 하나를 사용하여 내부 링크를 만드는 경우 북마크 또는 제목은 Request에 지정된 탭 ID에서 가져온 것으로 간주됩니다. 탭이 지정되지 않으면 문서의 첫 번째 탭에서 가져온 것으로 간주됩니다.
링크 JSON 표현은 더 자세한 정보를 제공합니다.
탭의 일반적인 사용 패턴
다음 코드 샘플에서는 탭과 상호작용하는 다양한 방법을 설명합니다.
문서의 모든 탭에서 탭 콘텐츠를 읽습니다.
탭 기능 전에 이를 실행한 기존 코드는 includeTabsContent 매개변수를 true로 설정하고 탭 트리 계층 구조를 순회하고 Document 대신 Tab 및 DocumentTab에서 getter 메서드를 호출하여 탭을 지원하도록 이전할 수 있습니다. 다음 부분 코드 샘플은 문서에서 텍스트 추출의 스니펫을 기반으로 합니다. 문서의 모든 탭에서 텍스트 콘텐츠를 인쇄하는 방법을 보여줍니다. 이 탭 순회 코드는 탭의 실제 구조를 신경 쓰지 않는 다른 많은 사용 사례에 맞게 조정할 수 있습니다.
자바
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
문서의 첫 번째 탭에서 탭 콘텐츠 읽기
이는 모든 탭을 읽는 것과 유사합니다.
자바
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
첫 번째 탭을 업데이트하도록 요청
다음 부분 코드 샘플은 Request에서 특정 탭을 타겟팅하는 방법을 보여줍니다.
이 코드는 텍스트 삽입, 삭제, 이동 가이드의 샘플을 기반으로 합니다.
자바
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }