
Google Docs API की मदद से, दस्तावेज़ के किसी भी टैब का कॉन्टेंट ऐक्सेस किया जा सकता है.
टैब क्या होते हैं?
Google Docs में, टैब नाम की एक लेयर होती है. Docs में, उपयोगकर्ताओं को एक ही दस्तावेज़ में एक या उससे ज़्यादा टैब बनाने की सुविधा मिलती है. यह सुविधा, Sheets में मौजूद टैब की तरह ही काम करती है. हर टैब का अपना टाइटल और आईडी होता है. यह आईडी, यूआरएल में जोड़ा जाता है. किसी टैब में चाइल्ड टैब भी हो सकते हैं. ये ऐसे टैब होते हैं जो किसी दूसरे टैब के नीचे नेस्ट किए जाते हैं.
दस्तावेज़ के कॉन्टेंट को Document Resource में दिखाने के तरीके में स्ट्रक्चरल बदलाव
पहले, दस्तावेज़ों में टैब का कॉन्सेप्ट नहीं था. इसलिए, Document रिसॉर्स में टेक्स्ट से जुड़ा सारा कॉन्टेंट इन फ़ील्ड के ज़रिए सीधे तौर पर शामिल होता था:
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
टैब की स्ट्रक्चरल हैरारकी के साथ, ये फ़ील्ड अब दस्तावेज़ के सभी टैब के टेक्स्ट कॉन्टेंट को सिमैंटिक तौर पर नहीं दिखाते. टेक्स्ट वाले कॉन्टेंट को अब एक अलग लेयर में दिखाया गया है. Google Docs में टैब की प्रॉपर्टी और कॉन्टेंट को document.tabs की मदद से ऐक्सेस किया जा सकता है. यह Tab ऑब्जेक्ट की एक सूची है. इनमें ऊपर बताए गए सभी टेक्स्ट कॉन्टेंट फ़ील्ड शामिल होते हैं. बाद के सेक्शन में, खास जानकारी दी गई है. साथ ही, टैब के JSON फ़ॉर्मैट में भी ज़्यादा जानकारी दी गई है.
टैब की प्रॉपर्टी ऐक्सेस करना
tab.tabProperties का इस्तेमाल करके, टैब की प्रॉपर्टी ऐक्सेस करें. इसमें टैब का आईडी, टाइटल, और पोज़िशनिंग जैसी जानकारी शामिल होती है.
किसी टैब में मौजूद टेक्स्ट कॉन्टेंट को ऐक्सेस करना
टैब में मौजूद दस्तावेज़ का असली कॉन्टेंट, tab.documentTab के तौर पर दिखता है.
ऊपर बताए गए सभी टेक्स्ट कॉन्टेंट फ़ील्ड, tab.documentTab का इस्तेमाल करके ऐक्सेस किए जा सकते हैं. उदाहरण के लिए, document.body के बजाय document.tabs[indexOfTab].documentTab.body का इस्तेमाल करें.
टैब हैरारकी
एपीआई में चाइल्ड टैब को Tab पर tab.childTabs फ़ील्ड के तौर पर दिखाया जाता है. किसी दस्तावेज़ के सभी टैब ऐक्सेस करने के लिए, चाइल्ड टैब के "ट्री" को ट्रैवर्स करना ज़रूरी होता है. उदाहरण के लिए,
ऐसे दस्तावेज़ पर विचार करें जिसमें टैब का क्रम इस तरह दिया गया है:
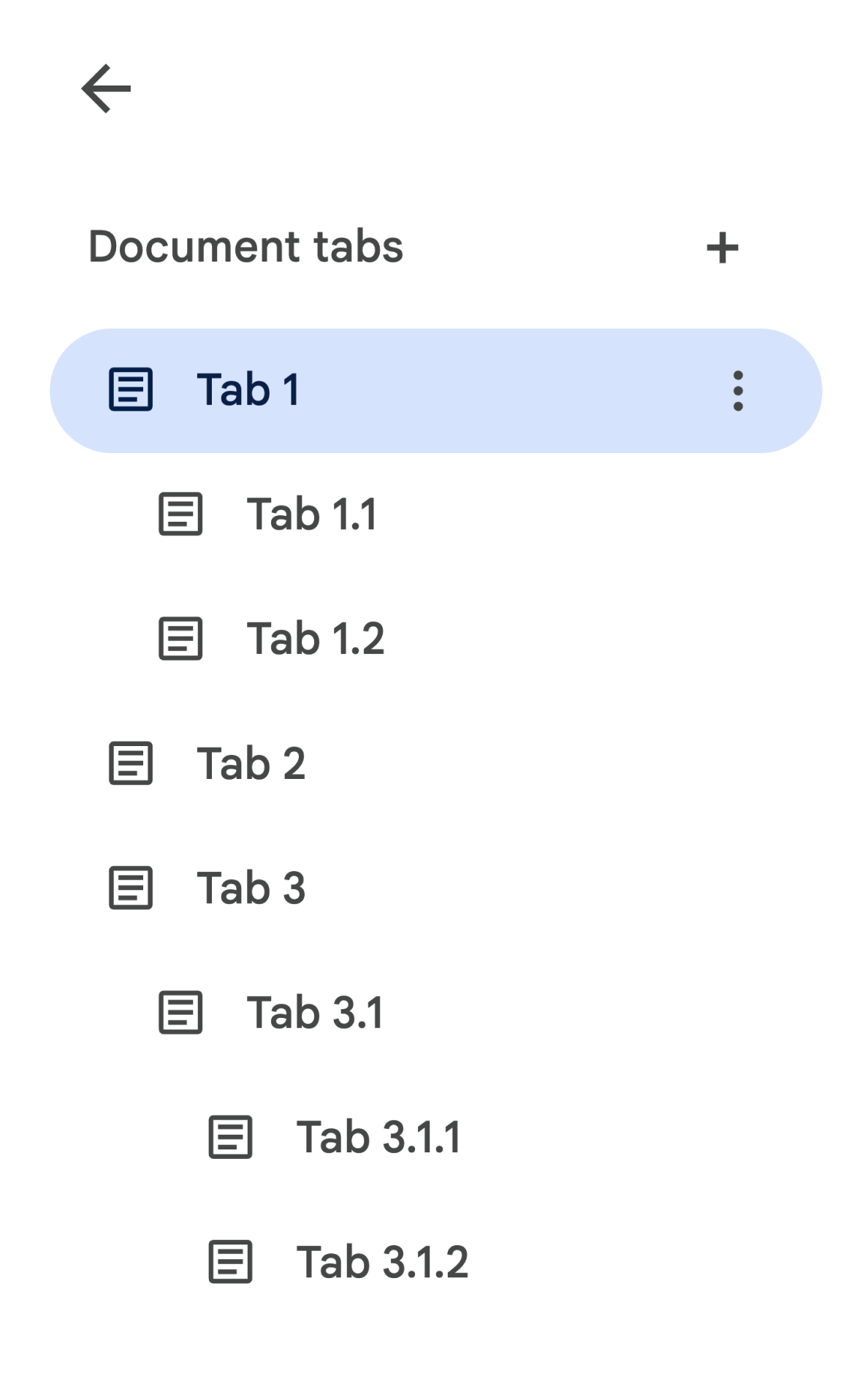
Tab 3.1.2 से Body को वापस पाने के लिए, आपको document.tabs[2].childTabs[0].childTabs[1].documentTab.body को ऐक्सेस करना होगा. बाद के सेक्शन में, सैंपल कोड ब्लॉक देखें. इनमें किसी दस्तावेज़ के सभी टैब में दोहराव करने के लिए सैंपल कोड दिया गया है.
तरीकों में बदलाव
टैब की सुविधा शुरू होने के बाद, दस्तावेज़ के हर तरीके में कुछ बदलाव किए गए हैं. इसके लिए, आपको अपना कोड अपडेट करना पड़ सकता है.
documents.get
डिफ़ॉल्ट रूप से, सभी टैब का कॉन्टेंट नहीं दिखाया जाता. डेवलपर को सभी टैब ऐक्सेस करने के लिए, अपना कोड अपडेट करना चाहिए. documents.get तरीके से includeTabsContent पैरामीटर का पता चलता है. इससे यह कॉन्फ़िगर किया जा सकता है कि जवाब में सभी टैब का कॉन्टेंट शामिल किया जाए या नहीं.
- अगर
includeTabsContentकोtrueपर सेट किया जाता है, तोdocuments.getतरीका,Documentरिसॉर्स दिखाएगा. इसमेंdocument.tabsफ़ील्ड की वैल्यू भरी होगी.documentपर मौजूद सभी टेक्स्ट फ़ील्ड (जैसे,document.body) खाली छोड़ दिए जाएंगे. - अगर
includeTabsContentनहीं दिया गया है, तोDocumentरिसॉर्स (जैसे,document.body) में मौजूद टेक्स्ट फ़ील्ड में, सिर्फ़ पहले टैब का कॉन्टेंट दिखेगा.document.tabsफ़ील्ड खाली होगा और अन्य टैब से कॉन्टेंट नहीं दिखेगा.
documents.create
documents.create वाला तरीका, बनाए गए खाली दस्तावेज़ को दिखाने वाला Document संसाधन दिखाता है. जवाब में मिले Document रिसॉर्स से, दस्तावेज़ के टेक्स्ट कॉन्टेंट फ़ील्ड और document.tabs, दोनों में दस्तावेज़ का खाली कॉन्टेंट भर जाएगा.
document.batchUpdate
हर Request में, उन टैब को तय करने का तरीका शामिल होता है जिन पर अपडेट लागू करना है. डिफ़ॉल्ट रूप से, अगर कोई टैब नहीं चुना जाता है, तो ज़्यादातर मामलों में Request को दस्तावेज़ के पहले टैब पर लागू किया जाएगा.
ReplaceAllTextRequest,
DeleteNamedRangeRequest,
और
ReplaceNamedRangeContentRequest
तीन खास अनुरोध हैं. ये सभी टैब पर डिफ़ॉल्ट रूप से लागू होंगे.
ज़्यादा जानकारी के लिए, Request के दस्तावेज़ देखें.
इंटरनल लिंक में बदलाव
उपयोगकर्ता, किसी दस्तावेज़ में मौजूद टैब, बुकमार्क, और हेडिंग के इंटरनल लिंक बना सकते हैं.
टैब की सुविधा शुरू होने के बाद, Link रिसॉर्स में मौजूद link.bookmarkId और link.headingId फ़ील्ड, दस्तावेज़ के किसी टैब में बुकमार्क या हेडिंग के तौर पर नहीं दिखाए जा सकते.
डेवलपर को अपने कोड को अपडेट करना चाहिए, ताकि वे पढ़ने और लिखने की कार्रवाइयों में link.bookmark और link.heading का इस्तेमाल कर सकें. ये BookmarkLink और HeadingLink ऑब्जेक्ट का इस्तेमाल करके इंटरनल लिंक दिखाते हैं. इनमें से हर ऑब्जेक्ट में, बुकमार्क या हेडिंग का आईडी और उस टैब का आईडी होता है जिसमें वह मौजूद है. इसके अलावा, link.tabId टैब के इंटरनल लिंक दिखाता है.
includeTabsContent पैरामीटर के आधार पर, documents.get रिस्पॉन्स में मौजूद लिंक का कॉन्टेंट भी अलग-अलग हो सकता है:
- अगर
includeTabsContentकोtrueपर सेट किया जाता है, तो सभी इंटरनल लिंकlink.bookmarkऔरlink.headingके तौर पर दिखेंगे. लेगसी फ़ील्ड का इस्तेमाल अब नहीं किया जाएगा. - अगर
includeTabsContentनहीं दिया गया है, तो एक टैब वाले दस्तावेज़ों में, उस टैब के अंदर मौजूद बुकमार्क या हेडिंग के सभी इंटरनल लिंक,link.bookmarkIdऔरlink.headingIdके तौर पर दिखते रहेंगे. एक से ज़्यादा टैब वाले दस्तावेज़ों में, इंटरनल लिंकlink.bookmarkऔरlink.headingके तौर पर दिखेंगे.
document.batchUpdate में, अगर लेगसी फ़ील्ड में से किसी एक का इस्तेमाल करके इंटरनल लिंक बनाया जाता है, तो बुकमार्क या हेडिंग को Request में दिए गए टैब आईडी का माना जाएगा. अगर कोई टैब नहीं दिया गया है, तो इसे दस्तावेज़ के पहले टैब से माना जाएगा.
लिंक किए गए JSON का रिप्रेज़ेंटेशन में ज़्यादा जानकारी दी गई है.
टैब के इस्तेमाल के सामान्य पैटर्न
यहां दिए गए कोड सैंपल में, टैब के साथ इंटरैक्ट करने के अलग-अलग तरीके बताए गए हैं.
दस्तावेज़ के सभी टैब से टैब का कॉन्टेंट पढ़ना
टैब की सुविधा से पहले, इस काम के लिए इस्तेमाल किए जा रहे मौजूदा कोड को माइग्रेट किया जा सकता है. इसके लिए, includeTabsContent पैरामीटर को true पर सेट करें, टैब ट्री के क्रम में जाएं, और Document के बजाय Tab और DocumentTab से गेटर मेथड कॉल करें. यहां दिया गया कोड का कुछ हिस्सा, किसी दस्तावेज़ से टेक्स्ट एक्सट्रैक्ट करना लेख में दिए गए स्निपेट पर आधारित है. इसमें बताया गया है कि किसी दस्तावेज़ के हर टैब में मौजूद टेक्स्ट कॉन्टेंट को कैसे प्रिंट करें. टैब ट्रैवर्सल के इस कोड को कई अन्य इस्तेमाल के उदाहरणों के लिए अडैप्ट किया जा सकता है. इनमें टैब के असल स्ट्रक्चर से कोई फ़र्क़ नहीं पड़ता.
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
दस्तावेज़ में पहले टैब से टैब का कॉन्टेंट पढ़ता है
यह सभी टैब को पढ़ने जैसा है.
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
पहले टैब को अपडेट करने का अनुरोध करना
यहां दिए गए कोड के कुछ हिस्से में, Request में किसी खास टैब को टारगेट करने का तरीका बताया गया है.
यह कोड, टेक्स्ट डालने, मिटाने, और उसे दूसरी जगह ले जाने से जुड़ी गाइड में दिए गए सैंपल पर आधारित है.
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }