
L'API Google Docs ti consente di accedere ai contenuti di qualsiasi scheda del documento.
Che cosa sono le schede?
Documenti Google include un livello organizzativo chiamato schede. Documenti consente agli utenti di creare una o più schede all'interno di un singolo documento, in modo simile a come sono presenti le schede in Fogli oggi. Ogni scheda ha il proprio titolo e ID (aggiunto nell'URL). Una scheda può anche avere schede secondarie, ovvero schede nidificate sotto un'altra scheda.
Modifiche strutturali al modo in cui i contenuti del documento sono rappresentati nella risorsa documento
In passato, i documenti non avevano il concetto di schede, quindi la risorsa
Document conteneva direttamente tutti i contenuti di testo tramite i seguenti campi:
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
Con la gerarchia strutturale aggiuntiva delle schede, questi campi non rappresentano più
semanticamente i contenuti di testo di tutte le schede del documento. I contenuti
basati su testo ora sono rappresentati in un livello diverso. Le proprietà delle schede e
i contenuti in Documenti Google sono accessibili con
document.tabs, che è
un elenco di oggetti Tab,
ognuno dei quali contiene tutti i campi di contenuti di testo menzionati in precedenza. Le sezioni
successive forniscono una breve panoramica; anche la rappresentazione
JSON della scheda
fornisce informazioni più dettagliate.
Proprietà della scheda Accesso
Accedi alle proprietà della scheda utilizzando
tab.tabProperties,
che include informazioni quali ID, titolo e posizionamento della scheda.
Accedere ai contenuti di testo all'interno di una scheda
Il contenuto effettivo del documento all'interno della scheda viene visualizzato come
tab.documentTab.
Tutti i campi dei contenuti di testo menzionati in precedenza sono accessibili tramite
tab.documentTab. Ad esempio, invece di utilizzare document.body, dovresti utilizzare
document.tabs[indexOfTab].documentTab.body.
Gerarchia delle schede
Le schede secondarie sono rappresentate nell'API come un campo
tab.childTabs in
Tab. Per accedere a tutte le schede
di un documento è necessario attraversare l'"albero" delle schede secondarie. Ad esempio,
considera un documento che contiene una gerarchia di schede come segue:
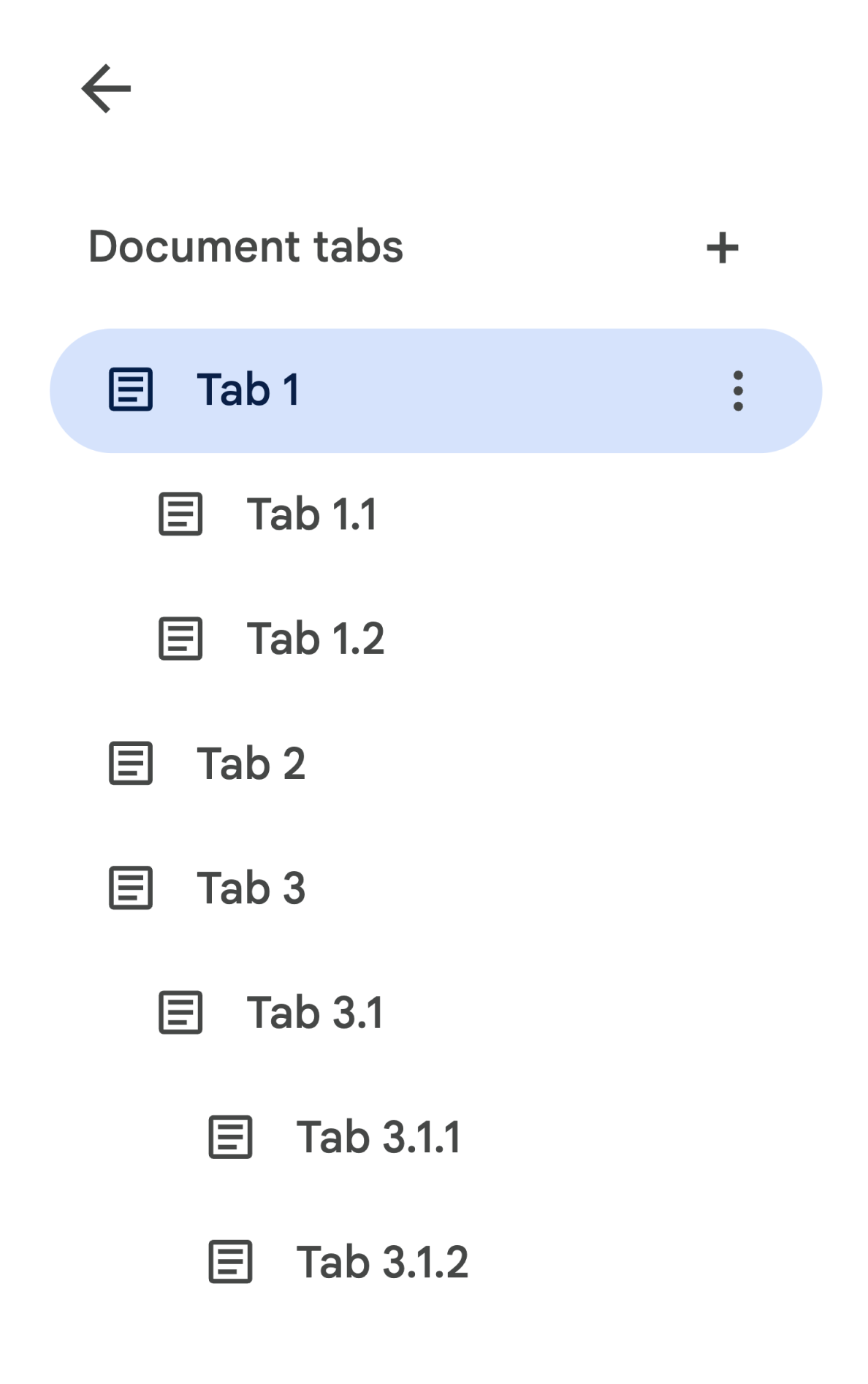
Per recuperare Body
dalla scheda 3.1.2, devi accedere a
document.tabs[2].childTabs[0].childTabs[1].documentTab.body. Consulta i blocchi di codice campione nella sezione successiva, che fornisce un codice campione per scorrere tutte le schede di un documento.
Modifiche ai metodi
Con l'introduzione delle schede, ciascuno dei metodi del documento ha subito alcune modifiche che potrebbero richiedere l'aggiornamento del codice.
documents.get
Per impostazione predefinita, non vengono restituiti tutti i contenuti delle schede. Gli sviluppatori devono aggiornare il codice per accedere a tutte le schede. Il metodo
documents.get espone un parametro includeTabsContent che consente di configurare se
i contenuti di tutte le schede vengono forniti nella risposta.
- Se
includeTabsContentè impostato sutrue, il metododocuments.getrestituirà una risorsaDocumentcon il campodocument.tabscompilato. Tutti i campi di testo direttamente sudocument(ad es.document.body) verranno lasciati vuoti. - Se
includeTabsContentnon viene fornito, i campi di testo nella risorsaDocument(ad es.document.body) verranno compilati solo con i contenuti della prima scheda. Il campodocument.tabssarà vuoto e i contenuti delle altre schede non verranno restituiti.
documents.create
Il metodo documents.create restituisce una risorsa Document che rappresenta il documento vuoto creato. La risorsa
Document restituita
popolerà i contenuti vuoti del documento sia nei campi dei contenuti di testo del documento
sia in document.tabs.
document.batchUpdate
Ogni
Request
include un modo per specificare le schede a cui applicare l'aggiornamento. Per impostazione predefinita, se una scheda non è specificata, Request verrà applicato nella maggior parte dei casi alla prima scheda del documento.
ReplaceAllTextRequest,
DeleteNamedRangeRequest,
e
ReplaceNamedRangeContentRequest
sono tre richieste speciali che verranno applicate per impostazione predefinita a tutte le schede.
Per i dettagli, consulta la documentazione di
Request.
Modifiche ai link interni
Gli utenti possono creare link interni a schede, segnalibri e intestazioni in un documento.
Con l'introduzione della funzionalità delle schede, i campi link.bookmarkId e
link.headingId nella risorsa
Link non possono più
rappresentare un segnalibro o un'intestazione in una scheda specifica del documento.
Gli sviluppatori devono aggiornare il codice per utilizzare link.bookmark e link.heading nelle operazioni di lettura e scrittura. Espongono i link interni utilizzando gli oggetti
BookmarkLink
e HeadingLink, ognuno dei quali contiene l'ID del segnalibro o dell'intestazione e l'ID della scheda
in cui si trova. Inoltre, link.tabId espone i link interni alle schede.
I contenuti del link di una risposta documents.get possono variare anche a seconda del parametro includeTabsContent:
- Se
includeTabsContentè impostato sutrue, tutti i link interni verranno esposti comelink.bookmarkelink.heading. I campi legacy non verranno più utilizzati. - Se
includeTabsContentnon viene fornito, nei documenti contenenti una singola scheda, tutti i link interni a segnalibri o intestazioni all'interno di quella singola scheda continuano a essere esposti comelink.bookmarkIdelink.headingId. Nei documenti contenenti più schede, i link interni verranno visualizzati comelink.bookmarkelink.heading.
In
document.batchUpdate,
se viene creato un link interno utilizzando uno dei campi legacy, il segnalibro o
l'intestazione verrà considerato proveniente dall'ID scheda specificato in
Request. Se
non viene specificata alcuna scheda, verrà considerata la prima scheda del
documento.
La rappresentazione JSON del link fornisce informazioni più dettagliate.
Pattern di utilizzo comuni per le schede
I seguenti esempi di codice descrivono vari modi di interagire con le schede.
Leggere i contenuti delle schede di tutte le schede del documento
Il codice esistente che lo faceva prima della funzionalità delle schede può essere migrato per supportare le schede impostando il parametro includeTabsContent su true, attraversando la gerarchia ad albero delle schede e chiamando i metodi getter da Tab e DocumentTab anziché da Document. Il
seguente esempio di codice parziale si basa sullo snippet riportato in Estrai il testo
da un documento. Mostra come
stampare tutti i contenuti di testo di ogni scheda di un documento. Questo codice di attraversamento delle schede può essere adattato a molti altri casi d'uso che non tengono conto della struttura effettiva delle schede.
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
Legge il contenuto della scheda Leggi dalla prima scheda del documento
È simile alla lettura di tutte le schede.
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
Invia una richiesta per aggiornare la prima scheda
Il seguente esempio di codice parziale mostra come scegliere come target una scheda specifica in un Request.
Questo codice si basa sull'esempio nella guida
Inserire, eliminare e spostare il testo.
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }