本页面介绍的是 Custom Search JSON API 的 XML 版本,该版本仅适用于 Google 网站搜索 客户。
概览
Google WebSearch 服务可让 Google Site Search 客户在其自己的网站上显示 Google 搜索结果。WebSearch 服务使用基于 HTTP 的简单协议来提供搜索结果。搜索管理员可以完全控制他们请求搜索结果的方式以及向最终用户呈现这些结果的方式。本文档介绍了 Google 搜索请求和结果格式的技术细节。
如需检索 Google WebSearch 结果,您的应用会向 Google 发送简单的 HTTP 请求。然后,Google 会以 XML 格式返回搜索结果。借助 XML 格式的结果,您可以自定义搜索结果的显示方式。
WebSearch 请求格式
请求概述
Google 搜索请求是一个标准的 HTTP GET 命令。它包含与查询相关的一组参数。这些参数会以名称=值对的形式包含在请求网址中,并以和号 (&) 字符分隔。参数包括搜索查询等数据,以及用于标识发出 HTTP 请求的引擎的唯一引擎 ID (cx)。WebSearch 或 Image Search 服务会返回 XML 结果来响应您的 HTTP 请求。
查询字词
大多数搜索请求都包含一个或多个查询字词。查询字词会显示为搜索请求中某个参数的值。
搜索查询字词可以指定多种类型的信息,以过滤和整理 Google 返回的搜索结果。查询可以指定:
- 要包含或排除的字词或短语
- 搜索查询中的所有字词(默认)
- 搜索查询中的确切词组
- 搜索查询中的任何字词或词组
- 文档中的哪个位置可查找搜索字词
- 文档中的任何位置(默认)
- 仅在文档中的链接中
- 对文档本身的限制
- 包含或排除特定文件类型(例如 PDF 文件或 Word 文档)的文档
- 返回指定网址相关信息(而非执行搜索)的特殊网址查询
- 返回网址相关一般信息的查询,例如其开放目录类别、摘要或语言
- 返回链接到某个网址的一组网页的查询
- 返回一组与指定网址类似的网页的查询
默认搜索
搜索查询参数值必须经过网址转义。请注意,您需要将搜索查询中的所有空格序列替换为加号“+”。本文档的 网址 转义部分对此进行了进一步讨论。
使用 q 参数将搜索查询字词提交给 WebSearch 服务。搜索查询字词示例:
q=horses+cows+pigs
默认情况下,Google WebSearch 服务仅返回包含搜索查询中所有字词的文档。
请求参数
本部分列出了您在发出搜索请求时可以使用的参数。这些参数分为两个列表。第一个列表包含与所有搜索请求相关的参数。第二个列表包含仅与高级搜索请求相关的参数。
需要提供三个请求参数:
- 客户端参数必须设置为
google-csbe - 输出参数用于指定返回的 XML 结果的格式;结果可以包含 (xml) 或不包含 (
xml_no_dtd) 对 Google DTD 的引用。我们建议您将此值设置为xml_no_dtd。注意:如果您未指定此参数,则结果将以 HTML 格式而非 XML 格式返回。
- 表示引擎唯一 ID 的 cx 参数。
除了上述参数之外,最常用的请求参数还包括:
WebSearch 查询示例
以下示例展示了几个 WebSearch HTTP 请求,用于说明如何使用不同的查询参数。本文档的 WebSearch 查询参数定义和高级搜索查询参数部分提供了不同查询参数的定义。
此请求要求针对搜索字词“red sox”(q=red+sox) 返回前 10 个结果 (start=0&num=10)。该查询还指定结果应来自加拿大网站 (cr=countryCA),并且应以法语 (lr=lang_fr) 撰写。最后,该查询还指定了 client、output 和 cx 参数的值,这三个参数都是必需的。
http://www.google.com/search?
start=0
&num=10
&q=red+sox
&cr=countryCA
&lr=lang_fr
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
此示例使用了一些高级搜索查询参数来进一步自定义搜索查询。此请求使用 as_q 参数 (as_q=red+sox) 而不是 q 参数。它还使用 as_eq 参数从搜索结果中排除包含“Yankees”一词的所有文档 (as_eq=yankees)。
http://www.google.com/search?
start=0
&num=10
&as_q=red+sox
&as_eq=Yankees
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
WebSearch 查询参数定义
| c2coff | |||||||
|---|---|---|---|---|---|---|---|
| 说明 | 可选。c2coff 参数用于启用或停用简体中文和繁体中文搜索功能。 此参数的默认值为
|
||||||
| 示例 | q=google&c2coff=1 |
||||||
| 客户端 | |
|---|---|
| 说明 | 必需。 |
| 示例 | q=google&client=google-csbe |
| cr | |
|---|---|
| 说明 | 可选。 Google WebSearch 通过分析以下各项来确定文档所属的国家/地区:
如需查看此参数的有效值列表,请参阅国家/地区 (cr) 参数值部分。 |
| 示例 | q=Frodo&cr=countryNZ |
| cx | |
|---|---|
| 说明 | 必需。 |
| 示例 | q=Frodo&cx=00255077836266642015:u-scht7a-8i |
| filter | |||||||
|---|---|---|---|---|---|---|---|
| 说明 | 可选。过滤参数用于启用或停用 Google 搜索结果的自动过滤功能。如需详细了解 Google 的搜索结果过滤条件,请参阅本文档的自动过滤部分。
注意:默认情况下,Google 会对所有搜索结果应用过滤功能,以提高这些结果的质量。 |
||||||
| 示例 | q=google&filter=0 |
||||||
| gl | |
|---|---|
| 说明 | 可选。 在 WebSearch 请求中指定 |
| 示例 | 此请求可提升英国境内撰写的文档在 WebSearch 结果中的排名: |
| hl | |
|---|---|
| 说明 | 可选。 如需了解详情,请参阅查询和结果呈现的国际化一文中的界面语言部分;如需查看支持的语言列表,请参阅支持的界面语言。 |
| 示例 | 此请求定位的是法语葡萄酒广告。(Vin 是法语中“葡萄酒”的意思。) q=vin&ip=10.10.10.10&ad=w5&hl=fr |
| hq | |
|---|---|
| 说明 | 可选。 |
| 示例 | 此请求搜索“pizza”和“cheese”。该表达式与
|
| ie | |
|---|---|
| 说明 | 可选。 如需了解何时可能需要使用此参数,请参阅字符编码部分。 如需查看可能的 |
| 示例 | q=google&ie=utf8&oe=utf8 |
| lr | |
|---|---|
| 说明 | 可选。 Google WebSearch 通过分析以下各项来确定文档所用的语言:
如需查看此参数的有效值列表,请参阅语言 ( |
| 示例 | q=Frodo&lr=lang_en |
| num | |
|---|---|
| 说明 | 可选。 默认 注意:如果搜索结果总数少于请求的结果数,系统将返回所有可用的搜索结果。 |
| 示例 | q=google&num=10 |
| oe | |
|---|---|
| 说明 | 可选。 如需了解何时可能需要使用此参数,请参阅字符编码部分。 如需查看可能的 |
| 示例 | q=google&ie=utf8&oe=utf8 |
| 输出 | |||||||
|---|---|---|---|---|---|---|---|
| 说明 | 必需。
|
||||||
| 示例 | output=xml_no_dtd |
||||||
| q | |
|---|---|
| 说明 | 可选。 还有许多特殊查询字词可用作 Google 搜索控制面板包含一份报告,其中列出了使用 注意:为 q 参数指定的值必须经过网址转义。 |
| 示例 | q=vacation&as_oq=london+paris |
| 安全 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 说明 | 可选。
如需详细了解此功能,请参阅使用安全搜索过滤成人内容部分。 |
||||||||
| 示例 | q=adult&safe=high |
||||||||
| start | |
|---|---|
| 说明 | 可选。
|
| 示例 | start=10 |
| 排序 | |
|---|---|
| 说明 | 可选。 |
| 示例 |
|
| ud | |
|---|---|
| 说明 | 可选。 http://www.花井鮨.com 此参数的有效值为 如果 http://www.xn--elq438j.com. 注意:这是一项 Beta 版功能。 |
| 示例 | q=google&ud=1 |
高级搜索
图片下方列出的其他查询参数与高级搜索查询相关。 提交高级搜索查询时,系统会将多个参数(例如 as_eq、as_epq、as_oq 等)的值纳入相应搜索的查询字词中。此图片显示的是 Google 的高级搜索页面。在图片中,每个高级搜索参数的名称都以红色文字写在页面上与该参数对应的字段内或旁边。
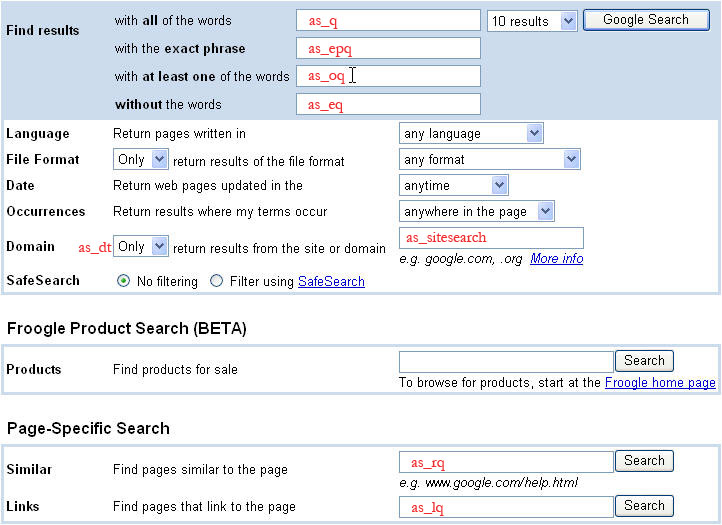
高级搜索查询参数
| as_dt | |
|---|---|
| 说明 | 可选。 |
| 示例 | as_dt=i,as_dt=e |
| as_epq | |
|---|---|
| 说明 | 可选。 |
| 示例 | as_epq=abraham+lincoln |
| as_eq | |
|---|---|
| 说明 | 可选。 |
| 示例 |
|
| as_lq | |
|---|---|
| 说明 | 可选。 |
| 示例 |
|
| as_nlo | |
|---|---|
| 说明 | 可选。 |
| 示例 | 以下示例将搜索范围设置为 5 到 10(含):
|
| as_nhi | |
|---|---|
| 说明 | 可选。 |
| 示例 | 以下示例将搜索范围设置为 5 到 10(含):
|
| as_oq | |
|---|---|
| 说明 | 可选。 |
| 示例 |
|
| as_q | |
|---|---|
| 说明 | 可选。 |
| 示例 |
|
| as_qdr | |
|---|---|
| 说明 | 可选。
|
| 示例 |
此示例请求过去一年的结果:
此示例请求过去 10 天内的结果:
|
| as_sitesearch | |
|---|---|
| 说明 | 可选。借助 |
| 示例 |
|
特殊查询字词
Google 网页搜索允许使用多个特殊搜索查询字词,以便访问 Google 搜索引擎的其他功能。这些特殊搜索字词应包含在 q 请求参数的值中。与其他搜索查询字词一样,特殊搜索查询字词必须经过 网址 转义。许多特殊搜索字词都包含英文冒号 (:)。此字符也必须进行网址转义;其网址转义值为 %3A。
| 反向链接 [link:] | |
|---|---|
| 说明 |
您还可以使用 as_lq 请求参数提交 注意:使用 |
| 示例 |
|
| 布尔值“或”搜索 [ OR ] | |
|---|---|
| 说明 |
您还可以使用 as_oq 请求参数来搜索一组字词中的任何字词。 注意:如果搜索请求指定了“London+OR+Paris”查询,搜索结果将包含至少包含这两个字词之一的文档。在某些情况下,搜索结果中的文档可能同时包含这两个字词。 |
| 示例 | 搜索“伦敦”或“巴黎”: 用户输入:
london OR
paris 搜索字词:q=london+OR+paris搜索“度假”以及“伦敦”或“巴黎”: 搜索查询字词:
q=vacation+london+OR+paris搜索“度假”和“伦敦”“巴黎”或“巧克力”中的一个: 搜索查询字词:
q=vacation+london+OR+paris+OR+chocolates搜索“vacation”和“chocolates”,以及“london”或“paris”,其中“chocolates”的权重最低: 搜索查询字词:
q=vacation+london+OR+paris+chocolates在还包含“伦敦”或“巴黎”的文档中搜索“度假”“巧克力”和“鲜花”: 搜索查询字词:
q=vacation+london+OR+paris+chocolates+flowers搜索“度假”和“伦敦”或“巴黎”,同时搜索“巧克力”或“鲜花”: 搜索查询字词: q=vacation+london+OR+paris+chocolates+OR+flowers |
| 排除查询字词 [-] | |
|---|---|
| 说明 | 排除 (
当搜索字词有多种含义时,排除查询字词非常有用。例如,字词“bass”可能会返回与鱼或音乐相关的搜索结果。如果您要查找有关鱼的文档,可以使用排除查询字词从搜索结果中排除有关音乐的文档。 您还可以使用 as_eq 请求参数从搜索结果中排除与特定字词或词组匹配的文档。 |
| 示例 | 用户输入: bass -music搜索字词: q=bass+%2Dmusic |
| 文件类型排除 [ -filetype: ] | |
|---|---|
| 说明 |
注意:您可以在查询中添加更多 Google 支持的文件类型包括:
未来可能会添加其他文件类型。您随时可以在 Google 的文件类型常见问题解答中找到最新列表。 |
| 示例 | 此示例返回提及“Google”但不是 PDF 文档的文档: 此示例返回提及“Google”的文档,但排除 PDF 文档和 Word 文档: |
| 文件类型过滤 [ filetype: ] | |
|---|---|
| 说明 |
您可以在查询中添加更多 默认情况下,搜索结果将包含具有任何文件扩展名的文档。 Google 支持的文件类型包括:
未来可能会添加其他文件类型。您随时可以在 Google 的文件类型常见问题解答中找到最新列表。 |
| 示例 | 此示例返回提及“Google”的 PDF 文档: 此示例会返回提及“Google”的 PDF 和 Word 文档: |
| 包含查询字词 [+] | |
|---|---|
| 说明 | 包含 (+) 查询字词用于指定搜索结果中包含的所有文档都必须包含某个字词或词组。若要使用包含查询字词,您需要在必须包含在所有搜索结果中的字词或短语前面加上“+”(加号)。
您应在 Google 通常会在确定搜索结果之前舍弃的常用字词前使用 |
| 示例 | 用户输入: Star Wars Episode +I搜索字词: q=Star+Wars+Episode+%2BI |
| 仅限链接搜索,所有字词 [ allinlinks: ] | |
|---|---|
| 说明 |
如果您的搜索查询包含
|
| 示例 | 用户输入:allinlinks: Google search搜索字词: q=allinlinks%3A+Google+search |
| 词组搜索 | |
|---|---|
| 说明 | 词组搜索 (") 查询字词可让您通过将词组括在引号中或使用连字符连接词组来搜索完整词组。
如果您要搜索名言或专有名词,词组搜索就特别有用。 您还可以使用 as_epq 请求参数提交短语搜索。 |
| 示例 | 用户输入:"Abraham Lincoln"搜索字词: q=%22Abraham+Lincoln%22 |
| 网页文档信息 [info:] | |
|---|---|
| 说明 |
注意:使用 |
| 示例 | 用户输入: info:www.google.com搜索字词: q=info%3Awww.google.com |
图片查询示例
以下示例展示了几个图片 HTTP 请求,用于说明如何使用不同的查询参数。本文档的“图片查询参数定义”部分提供了不同查询参数的定义。
此请求要求针对查询字词“monkey”(q=monkey) 获取前 5 个结果 (start=0&num=5),文件类型为 .png。最后,该查询为 client、output 和 cx 参数指定了值,这三个参数都是必需的。
http://www.google.com/cse? searchtype=image start=0 &num=5 &q=monkey &as_filetype=png &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
图片搜索查询参数
| as_filetype | |
|---|---|
| 说明 | 可选。返回指定类型的图片。允许的值包括: |
| 示例 | q=google&as_filetype=png |
| imgsz | |
|---|---|
| 说明 | 可选。返回指定大小的图片,其中 size 可以是以下值之一:
|
| 示例 | q=google&as_filetype=png&imgsz=icon |
| imgtype | |
|---|---|
| 说明 | 可选。返回指定类型的图片,可以是以下类型之一:
|
| 示例 | q=google&as_filetype=png&imgtype=photo |
| imgc | |
|---|---|
| 说明 | 可选。返回黑白、灰度或彩色图片:
|
| 示例 | q=google&as_filetype=png&imgc=gray |
| imgcolor | |
|---|---|
| 说明 | 可选。返回具有特定主色的图片:
|
| 示例 | q=google&as_filetype=png&imgcolor=yellow |
| as_rights | |
|---|---|
| 说明 | 可选。基于许可的过滤条件。支持的值包括:
|
| 示例 | q=cats&as_filetype=png&as_rights=cc_attribute |
请求限制
下表列出了您向 Google 发送的搜索请求的限制:
| 组件 | 限制 | 评论 |
|---|---|---|
| 搜索请求长度 | 2048 字节 | |
| 查询字词数 | 10 | 包括以下参数中的字词:q、as_epq、as_eq、as_lq、as_oq、as_q |
| 结果数量 | 20 | 如果您将 num 参数设置为大于 20 的数字,则只会返回 20 个结果。如需获取更多结果,您需要发送多个请求,并在每个请求中递增 start 参数的值。 |
查询和结果呈现的国际化
借助 Google WebSearch 服务,您可以搜索多种语言的文档。您可以指定用于解析 HTTP 请求和对 XML 响应进行编码的字符编码(使用 ie 和 oe 搜索参数)。您还可以过滤结果,以仅包含以特定语言撰写的文档。
以下部分讨论了与使用多种语言进行搜索相关的问题:
字符编码
服务器以编码字节序列的形式向用户代理(例如浏览器)发送数据(例如网页)。然后,用户代理将这些字节解码为字符序列。向 WebSearch 服务发送请求时,您可以为搜索查询和收到的 XML 响应指定编码方案。
您可以使用 ie 请求参数来指定 HTTP 请求中字符的编码机制。您还可以使用 oe 参数来指定 Google 对 XML 响应进行编码时应采用的编码方案。如果您使用的编码方案不是 ISO-8859-1(或 latin1),请确保为 ie 和 oe 参数指定正确的值。
注意:如果您要为多种语言提供搜索功能,建议您为 ie 和 oe 参数都使用 utf8 (UTF-8) 编码值。
如需查看可用于 ie 和 oe 参数的值的完整列表,请参阅字符编码方案附录。
如需了解有关字符编码的更多一般信息,请参阅 http://www.w3.org/TR/REC-html40/charset.html。
界面语言
您可以使用 hl 请求参数来标识图形界面的语言。hl 参数值可能会影响 XML 搜索结果,尤其是在未明确指定语言限制(使用 lr 参数)的国际查询中。在这种情况下,hl 参数可能会促使搜索结果以用户输入语言显示。
我们建议您在搜索结果中明确设置 hl 参数,以确保 Google 为每个查询选择最优质的搜索结果。
如需查看 hl 参数的有效值完整列表,请参阅支持的界面语言部分。
搜索以特定语言撰写的文档
您可以使用 lr 请求参数,将搜索结果限制为以特定语言或一组语言撰写的文档。
lr 参数支持布尔值运算符,可让您指定应包含(或排除)在搜索结果中的多种语言。
以下示例展示了如何使用布尔运算符来请求不同语言的文档。
对于以日语撰写的文档:
lr=lang_jp
对于以意大利语或德语撰写的文档:
lr=lang_it|lang_de
对于非匈牙利语或捷克语的文档:
lr=(-lang_hu).(-lang_cs)
如需查看 lr 参数的完整可能值列表,请参阅语言集合值部分;如需查看有关这些运算符用法的完整讨论,请参阅布尔值运算符部分。
简体中文和繁体中文搜索
简体中文和繁体中文是中文的两种书写变体。同一概念在每种变体中的写法可能不同。如果用户以其中一种变体输入查询,Google WebSearch 服务可以返回包含两种变体网页的结果。
要使用此功能,请执行以下操作:
以下示例展示了您在请求简体中文和繁体中文结果时应包含的查询参数。(请注意,示例中未包含其他必需信息,例如客户端。)
search?hl=zh-CN
&lr=lang_zh-TW|lang_zh-CN
&c2coff=0过滤结果
Google 网页搜索提供了多种过滤搜索结果的方法:
自动过滤搜索结果
为了尽可能提供最佳的搜索结果,Google 会使用以下两种技术自动过滤通常被视为不合适的搜索结果:
-
重复内容 - 如果多个文档包含相同的信息,那么搜索结果只会纳入该组文档中最相关的文档。
-
密集主机 - 如果有多个搜索结果来自同一网站,Google 可能不会显示该网站上的所有结果,或者可能会使这些结果在
排名中低于原本应有的位置。
我们建议您针对常规搜索请求启用这些过滤条件,因为它们可以显著提升大多数搜索结果的质量。不过,您可以在搜索请求中将 filter 查询参数设置为 0,从而绕过这些自动过滤条件。
语言和国家/地区过滤
Google WebSearch 服务会返回所有网络文档的主索引中的结果。主索引包含按特定属性(包括语言和来源国家/地区)分组的文档子集合。
您可以使用 lr 和 cr 请求参数,分别将搜索结果限定为采用特定语言或源自特定国家/地区的文档子集合。
Google WebSearch 通过分析以下各项来确定文档所用的语言:
- 文档网址的顶级域名 (TLD)
- 文档中的语言元标记
- 文档正文中主要内容使用的语言
另请参阅 lr 参数的定义、搜索以特定语言撰写的文档部分以及可用作 lr 参数值的语言集合值,详细了解如何根据语言限制结果。
Google WebSearch 通过分析以下各项来确定文档所属的国家/地区:
- 文档网址的顶级域名 (TLD)
- 网络服务器 IP 地址的地理位置
另请参阅 cr 参数的定义以及可作为 cr 参数的值使用的国家/地区集合值,详细了解如何按来源国家/地区限制结果。
注意:您可以将语言值和国家/地区值结合使用,从而自定义搜索结果。例如,您可以请求搜索用法语撰写且来自法国或加拿大的文档,也可以请求搜索来自荷兰且不是用英语撰写的文档。lr 和 cr 参数均支持布尔运算符。
使用安全搜索功能过滤成人内容
许多 Google 客户都不希望显示包含成人内容的网站的搜索结果。借助我们的安全搜索过滤器,您可以过滤出包含成人内容的搜索结果并将其排除。Google 的过滤器使用专有技术来检查关键字、短语和网址。虽然没有任何过滤器能做到百分之百准确,但安全搜索功能可从搜索结果中移除绝大多数成人内容。
Google 会不断抓取网页并根据用户建议进行更新,力求使安全搜索功能尽可能保持最新状态并提供全面的过滤效果。
安全搜索功能支持以下语言:
| 荷兰语 英语 法语 德语 |
意大利语 葡萄牙语(巴西) 西班牙语 繁体中文 |
您可以使用 safe 查询参数调整 Google 过滤成人内容的程度。下表介绍了 Google 的安全搜索设置,以及这些设置对搜索结果的影响:
| 安全搜索级别 | 说明 |
|---|---|
| 高价 | 启用更严格的安全搜索版本。 |
| 中 | 屏蔽包含色情内容和其他露骨色情内容的网页。 |
| 关闭 | 不会从搜索结果中滤除成人内容。 |
* 安全搜索设置的默认值为关闭。
如果您已启用安全搜索功能,但在搜索结果中发现包含冒犯性内容的网站,请将该网站的网址发送电子邮件至 safesearch@google.com,我们会对该网站进行调查。
XML 结果
Google XML 结果 DTD
Google 使用相同的 DTD 来描述所有类型的搜索结果的 XML 格式。许多标记和属性都适用于所有搜索类型。不过,有些标记仅适用于某些搜索类型。因此,DTD 中的定义可能不如本文档中给出的定义严格。
本文档介绍了与 WebSearch 相关的 DTD 方面。查看 DTD 时,如果您正在处理 WebSearch,可以放心地忽略此处未记录的标记和属性。如果 DTD 与文档中的定义不同,本文档中会说明这一点。
Google 可以返回包含或不包含最新 DTD 参考的 XML 结果。DTD 是一份指南,可帮助搜索管理员和 XML 解析器了解 Google 的 XML 结果。由于 Google 的 XML 语法可能会不时发生变化,因此您不应将解析器配置为使用 DTD 来验证每个 XML 结果。
此外,您不应将 XML 解析器配置为在每次提交搜索请求时都提取 DTD。Google 不会经常更新 DTD,而这些请求会造成不必要的延迟并增加带宽要求。
Google 建议您使用 xml_no_dtd 输出格式来获取 XML 结果。 如果您在搜索请求中指定 xml 输出格式,唯一的区别是 XML 结果中会包含以下行:
<!DOCTYPE GSP SYSTEM "google.dtd">您可以访问 http://www.google.com/google.dtd 来获取最新的 DTD。
请注意,DTD 中的部分功能目前可能无法使用或不受支持。
关于 XML 响应
- 除非 XML 标记定义中另有说明,否则所有元素值都是适合显示的有效 HTML。
- 某些元素值是网址,需要在显示之前进行 HTML 编码。
- 您的 XML 解析器应忽略未记录的属性和标记。这样一来,如果 Google 向 XML 输出添加更多功能,您的应用无需修改即可继续正常运行。
- 当某些字符作为值包含在 XML 标记中时,必须进行转义。您的 XML 处理器应将这些实体转换回相应的字符。如果您未正确转换实体,浏览器可能会将 & 字符呈现为“&”。XML 标准文档中记录了这些字符;下表中列出了这些字符:
角色 转义形式 实体 字符代码 和符号 & & & 单引号 ' ' ' 双引号 " " " 大于号 > > > 小于号 < < <
常规搜索查询和高级搜索查询的 XML 结果
常规/高级搜索:示例查询和 XML 结果
此 WebSearch 请求示例要求返回 10 条 (num=10) 与搜索字词“socer”(q=socer) 相关的结果(在本示例中,“socer”是故意拼错的“soccer”)。
http://www.google.com/search?
q=socer
&hl=en
&start=10
&num=10
&output=xml
&client=google-csbe
&cx=00255077836266642015:u-scht7a-8i
此请求会生成以下 XML 结果。请注意,XML 结果中包含多条注释,用于指明未包含在结果中的某些标记会显示在何处。
<?xml version="1.0" encoding="ISO-8859-1" standalone="no" ?>
<GSP VER="3.2">
<TM>0.452923</TM>
<Q>socer</Q>
<PARAM name="cx" value="00255077836266642015:u-scht7a-8i" original_value="00255077836266642015%3Au-scht7a-8i"/>
<PARAM name="hl" value="en" original_value="en"/>
<PARAM name="q" value="socer" original_value="socer"/>
<PARAM name="output" value="xml" original_value="xml"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe"/>
<PARAM name="num" value="10" original_value="10"/>
<Spelling>
<Suggestion q="soccer"><b><i>soccer</i></b></Suggestion>
</Spelling>
<Context>
<title>Sample Vacation CSE</title>
<Facet>
<FacetItem>
<label>restaurants</label>
<anchor_text>restaurants</anchor_text>
</FacetItem>
<FacetItem>
<label>wineries</label>
<anchor_text>wineries</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>golf_courses</label>
<anchor_text>golf courses</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>hotels</label>
<anchor_text>hotels</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>nightlife</label>
<anchor_text>nightlife</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>soccer_sites</label>
<anchor_text>soccer sites</anchor_text>
</FacetItem>
</Facet>
</Context>
<RES SN="1" EN="10">
<M>6080</M>
/*
* The FI tag after the comment indicates that the result
* set has been filtered. If the number of results were exact, the
* FI tag would be replaced by an XT tag in the same format.
*/
<FI />
<NB>
/*
* Since the request is for the first page of results, the PU tag,
* which contains a link to the previous page of search results,
* is not included in this XML result. If the sample result did include
* a previous page of results, it would be listed here, in the same format
* as the NU tag on the following line
*/
<NU>/search?q=socer&hl=en&lr=&ie=UTF-8&output=xml&client=test&start=10&sa=N</NU>
</NB>
<R N="1">
<U>http://www.soccerconnection.net/</U>
<UE>http://www.soccerconnection.net/</UE>
<T>SoccerConnection.net</T>
<CRAWLDATE>May 21, 2007</CRAWLDATE>
<S><b>soccer</b>; players; coaches; ball; world cup;<b>...</b></S>
<Label>transcodable_pages</Label>
<Label>accessible</Label>
<Label>soccer_sites</Label>
<LANG>en</LANG>
<HAS>
<DI>
<DT>SoccerConnection.net</DT>
<DS>Post your <b>soccer</b> resume directly on the Internet.</DS>
</DI>
<L/>
<C SZ="8k" CID="kWAPoYw1xIUJ"/>
<RT/>
</HAS>
</R>
/*
* The result includes nine more results, each enclosed by an R tag.
*/
</RES>
</GSP>
常规/高级搜索:XML 标记
常规搜索请求和高级搜索请求的 XML 响应都使用相同的 XML 标记集。这些 XML 标记显示在上面的 XML 示例中,并在下表中进行了说明。
以下 XML 标记按标记名称的字母顺序列出,每个标记定义都包含标记说明、展示标记在 XML 结果中显示方式的示例以及标记内容的格式。如果某个标记是另一个 XML 标记的子标记,或者该标记本身具有子标记或属性,则该信息也会在相应标记的定义表中提供。
在下面的定义中,某些子标记旁边可能会显示特定符号。这些符号及其含义如下:
* = 子标记的零个或多个实例
+ = 子标记的一个或多个实例
| B | C | D | F | G | H | I | L | M | 北 | P | 问题 | R | 南 | T | U | X |
| anchor_text | |
|---|---|
| 定义 | <anchor_text> 标记用于指定应向用户显示的文本,以标识与一组搜索结果相关联的过滤条件标签。由于细化标签会将非字母数字字符替换为下划线,因此您不应在界面中显示 <label> 标记的值。您应改为显示 <anchor_text> 标记的值。 |
| 示例 | <anchor_text>高尔夫球场</anchor_text> |
| 子标记 | FacetItem |
| 内容格式 | 文字 |
| 屏蔽 | |
|---|---|
| 定义 | 此标记用于封装宣传结果的正文行中某个块的内容。每个块都有子标记 T、U 和 L。非空的 T 标记表示相应块包含文本;非空的 U 和 L 标记表示相应块包含链接(网址在 U 子标记中给出,定位文字在 L 子标记中给出)。 |
| 子标记 | T、U、L |
| 子标记 | BODY_LINE |
| 内容格式 | 空 |
| BODY_LINE | |
|---|---|
| 定义 | 此标记用于封装推广结果正文中的一行内容。每个正文行都包含多个 BLOCK 标记,这些标记要么包含一些文本,要么包含带有网址和定位文字的链接。 |
| 子标记 | BLOCK* |
| 子标记 | SL_MAIN |
| 内容格式 | 空 |
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定义 | <C> 标记表示 WebSearch 服务可以检索此搜索结果网址的缓存版本。您无法通过 XML API 检索缓存的网页,但可以将用户重定向到 www.google.com 以查看此内容。 |
|||||||||
| 属性 |
|
|||||||||
| 示例 | <C SZ="6k" CID="kvOXK_cYSSgJ" /> | |||||||||
| 子标记 | HAS | |||||||||
| 内容格式 | 空 | |||||||||
| C2C | |
|---|---|
| 定义 | <C2C> 标记表示结果是指向繁体中文网页的。此标记仅在启用简体中文和繁体中文搜索时显示。如需详细了解如何启用和停用此功能,请参阅 c2coff 查询参数定义。 |
| 内容格式 | 文字 |
| 上下文 | |
|---|---|
| 定义 | <Context> 标记封装了与一组搜索结果相关联的优化标签列表。 |
| 示例 | <Context> |
| 子标记 | title、Facet+ |
| 内容格式 | Container |
| CRAWLDATE | |
|---|---|
| 定义 | <CRAWLDATE> 标记用于标识网页的上次抓取日期。并非每个搜索结果页面都会返回 |
| 示例 | <CRAWLDATE>2005 年 5 月 21 日</CRAWLDATE> |
| 子标记 | R |
| 内容格式 | 文字 |
| DI | |
|---|---|
| 定义 | <DI> 标记封装了单个搜索结果的开放目录项目 (ODP) 类别信息。 |
| 示例 | <DI> |
| 子标记 | DT?DS? |
| 子标记 | HAS |
| 内容格式 | 空 |
| DS | |
|---|---|
| 定义 | <DS> 标记提供 ODP 目录中单个类别的摘要。 |
| 示例 | <DS>直接在互联网上发布您的<b>足球</b>简历。</DS> |
| 子标记 | DI |
| 内容格式 | 文本(可能包含 HTML) |
| 数据表 | |
|---|---|
| 定义 | <DT> 标记用于提供 ODP 目录中列出的单个类别的标题。 |
| 示例 | <DT>SoccerConnection.net</DT> |
| 子标记 | DI |
| 内容格式 | 文本(可能包含 HTML) |
| 商品详情 | |
|---|---|
| 定义 | <Facet> 标记包含 <FacetItem> 标记的逻辑分组。您可以使用可编程搜索引擎 XML 规范格式创建这些分组。如果您不创建这些分组,results_xml_tag_Context><Context> 标记将包含最多四个 <Facet> 标记。每个 <Facet> 标记中的项将分组显示,但可能没有逻辑关系。 |
| 示例 | <Facet> |
| 子标记 | FacetItem,title,+ |
| 子标记 | 上下文 |
| 内容格式 | Container |
| FacetItem | |
|---|---|
| 定义 | <FacetItem> 标记包含与一组搜索结果关联的优化标签的相关信息。 |
| 示例 | <FacetItem> |
| 子标记 | label、anchor_text+ |
| 子标记 | 商品详情 |
| 内容格式 | FacetItem |
| FI | |
|---|---|
| 定义 | <FI> 标记用作标志,用于指示是否对搜索结果执行了文档过滤。 如需详细了解 Google 的搜索结果过滤条件,请参阅本文档的自动过滤部分。 |
| 示例 | <FI /> |
| 子标记 | RES |
| 内容格式 | 空 |
| GSP | |||||||
|---|---|---|---|---|---|---|---|
| 定义 | <GSP> 标记封装了 Google XML 搜索结果中返回的所有数据。“GSP”是“Google 搜索协议”的缩写。 |
||||||
| 属性 |
|
||||||
| 示例 | <GSP VER="3.2"> | ||||||
| 子标记 | PARAM、Q、RES?TM | ||||||
| 内容格式 | 空 | ||||||
| HAS | |
|---|---|
| 定义 | <HAS> 标记封装了特定网址支持的任何特殊搜索请求参数的相关信息。
注意:WebSearch 的 <HAS> 定义比 DTD 中的定义更严格。 |
| 子标记 | DI?L?C?RT? |
| 子标记 | R |
| ISURL | |
|---|---|
| 定义 | 如果关联的搜索查询是网址,Google 会返回 <IS网址> 标记。 |
| 子标记 | GSP |
| 内容格式 | 空 |
| L | |
|---|---|
| 定义 | <L> 标记的存在表示 WebSearch 服务可以找到链接到此搜索结果网址的其他网站。如需查找此类网站,您可以使用 link: 特殊搜索查询字词。 |
| 子标记 | HAS |
| 内容格式 | 空 |
| 标签 | |
|---|---|
| 定义 | <label> 标记用于指定细化标签,您可以使用该标签来过滤收到的搜索结果。如需使用细化标签,请将字符串 more:[[label tag value]] 添加到 HTTP 请求中发送给 Google 的 q 参数的值中,如以下示例所示。请注意,在将查询发送给 Google 之前,必须对该值进行网址转义。 This example uses the refinement label golf_courses to 注意:<label> 标记与 <Label> 标记不同,后者用于标识与搜索结果中特定网址相关联的优化标签。 |
| 示例 | <label>golf_courses</label> |
| 子标记 | FacetItem |
| 内容格式 | 文字 |
| LANG | |
|---|---|
| 定义 | <LANG> 标记包含 Google 对搜索结果语言的最佳猜测。 |
| 示例 | <LANG>en</LANG> |
| 子标记 | R |
| 内容格式 | 文字 |
| M | |
|---|---|
| 定义 | <M> 标记用于标识搜索的估计总结果数。 注意: 此估算值可能并不准确。 |
| 示例 | <M>16200000</M> |
| 子标记 | RES |
| 内容格式 | 文字 |
| 新生儿 | |
|---|---|
| 定义 | <NB> 标记用于封装结果集的导航信息,即指向下一页搜索结果或上一页搜索结果的链接。 注意:仅当有更多结果可用时,系统才会显示此标记。 |
| 示例 | <NB> |
| 子标记 | NU?PU? |
| 子标记 | RES |
| 内容格式 | 空 |
| NU | |
|---|---|
| 定义 | <NU> 标记包含指向下一页搜索结果的相对链接。 |
| 示例 | <NU>/search?q=flowers&num=10&hl=en&ie=UTF-8 &output=xml&client=test&start=10</NU> |
| 子标记 | NB |
| 内容格式 | 文字(相对网址) |
| PARAM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 定义 | <PARAM> 标记用于标识在与 XML 结果关联的 HTTP 请求中提交的输入参数。有关参数的信息包含在标记属性(名称、值、原始值)中,并且 HTTP 请求中提交的每个参数都对应一个 PARAM 标记。 |
||||||||||||
| 属性 |
|
||||||||||||
| 示例 | <PARAM name="cr" value="countryNZ" original_value="countryNZ" /> | ||||||||||||
| 子标记 | GSP | ||||||||||||
| 内容格式 | 复杂 | ||||||||||||
| PU | |
|---|---|
| 定义 | <PU> 标记提供指向上一个搜索结果页面的相对链接。 |
| 示例 | <PU>/search?q=flowers&num=10&hl=en&output=xml &client=test&start=10</PU> |
| 子标记 | NB |
| 内容格式 | 文字(相对网址) |
| Q | |
|---|---|
| 定义 | <Q> 标记用于标识与 XML 结果关联的 HTTP 请求中提交的搜索查询。 |
| 示例 | <Q>披萨</Q> |
| 子标记 | GSP |
| 内容格式 | 文字 |
| R | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定义 | <R> 标记用于封装单个搜索结果的详细信息。 注意:WebSearch 的 <R> 标记定义比 DTD 中的定义更严格。 |
|||||||||
| 属性 |
|
|||||||||
| 子标记 | U、UE、T?CRAWLDATE、S?LANG?, HAS | |||||||||
| 子标记 | RES | |||||||||
| 反抗军 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定义 | <RES> 标记封装了一组单独的搜索结果以及有关这些结果的详细信息。 |
|||||||||
| 属性 |
|
|||||||||
| 示例 | <RES SN="1" EN="10"> | |||||||||
| 子标记 | M、FI?XT?注意?R* | |||||||||
| 子标记 | GSP | |||||||||
| 内容格式 | 空 | |||||||||
| S | |
|---|---|
| 定义 | <S> 标记包含搜索结果的摘要,其中以粗体突出显示了搜索查询字词。摘要中包含换行符,以便正确进行文本换行。 |
| 示例 | <S>华盛顿(美国有线电视新闻网)——一项旨在结束参议院就<b>布什</b>总统的司法任命僵持不下的局面而提出的动议,将允许五名被提名人进入最终投票阶段,同时保留<b>...<b>...</b><S> |
| 子标记 | R |
| 内容格式 | 文本 (HTML) |
| SL_MAIN | |
|---|---|
| 定义 | 此标记用于封装促销结果的内容。用于解析促销信息。标题链接的定位文字和网址分别包含在 T 和 U 子标记中。正文和链接的行包含在 BODY_LINE 子标记中。 |
| 子标记 | BODY_LINE*、T、U |
| 子标记 | SL_RESULTS |
| 内容格式 | 空 |
| SL_RESULTS | |
|---|---|
| 定义 | 用于推广结果的容器代码。每当您的搜索结果中包含促销信息时,系统都会显示其中一种。SL_MAIN 子标记包含主要结果数据。 |
| 子标记 | SL_MAIN* |
| 子标记 | R |
| 内容格式 | 空 |
| 拼写 | |
|---|---|
| 定义 | <拼写> 标记用于封装针对提交的查询的替代拼写建议。此标记仅显示在搜索结果的第一页上。拼写建议支持英语、中文、日语和韩语。 注意:Google 只会针对 gl 参数值为小写字母的查询返回拼写建议。 |
| 示例 | <Spelling> |
| 子标记 | 建议 |
| 子标记 | GSP |
| 内容格式 | 空 |
| 建议 | |||||||
|---|---|---|---|---|---|---|---|
| 定义 | <Suggestion> 标记包含针对提交的查询的替代拼写建议。您可以使用该标记的内容向搜索用户建议替代拼写。q 属性的值是经过网址转义的拼写建议,您可以将其用作搜索字词。 | ||||||
| 属性 |
|
||||||
| 示例 | <Suggestion q="soccer"><b><i>soccer</i></b></Suggestion> | ||||||
| 子标记 | 拼写 | ||||||
| 内容格式 | 文本 (HTML) | ||||||
| T | |
|---|---|
| 定义 | <T> 标记包含结果的标题。 |
| 示例 | <T>Amici's East Coast Pizzeria</T> |
| 子标记 | R |
| 内容格式 | 文本 (HTML) |
| title | |
|---|---|
| 定义 | 作为 <Context> 的子标记,<title> 标记包含可编程搜索引擎的名称。 作为 <Facet> 的子元素,<title> 标记可为一组 Facet 提供标题。 |
| 示例 | 作为 <Context> 的子元素:<title>我的搜索引擎</title> 作为 <Facet> 的子元素:<title>分面标题</title> |
| 子标记 | 上下文、Facet |
| 内容格式 | 文字 |
| TM | |
|---|---|
| 定义 | <TM> 标记用于标识返回搜索结果所需的总服务器时间(以秒为单位)。 |
| 示例 | <TM>0.100445</TM> |
| 子标记 | GSP |
| 内容格式 | 文本(浮点数) |
| TT | |
|---|---|
| 定义 | <TT> 标记提供搜索提示。 |
| 示例 | <TT><i>提示:对于大多数浏览器,按 Return 键与点击“搜索”按钮的效果相同。</i></TT> |
| 子标记 | GSP |
| U | |
|---|---|
| 定义 | <U> 标记提供搜索结果的网址。 |
| 示例 | <U>http://www.dominos.com/</U> |
| 子标记 | R |
| 内容格式 | 文本(绝对网址) |
| UD | |
|---|---|
| 定义 | <UD> 标记提供搜索结果的 IDN 编码(国际域名)网址。该值允许使用本地语言显示域名。例如,IDN 编码的网址 http://www.%E8%8A%B1%E4%BA%95.com 可以解码并显示为 http://www.花井鮨.com。此 <UD> 标记仅会包含在包含 ud 参数的请求的搜索结果中。 注意:这是一项 Beta 版功能。 |
| 示例 | <UD>http://www.%E8%8A%B1%E4%BA%95.com/</UD> |
| 子标记 | R |
| 内容格式 | 文本(IDN 编码的网址) |
| UE | |
|---|---|
| 定义 | <UE> 标记提供搜索结果的网址。该值经过网址转义,因此适合作为网址中的查询参数传递。 |
| 示例 | <UE>http://www.dominos.com/</UE> |
| 子标记 | R |
| 内容格式 | 文本(网址转义后的网址) |
| XT | |
|---|---|
| 定义 | <XT> 标记表示由 M 标记指定的估计结果总数实际上表示确切的结果总数。如需了解详情,请参阅本文档的自动过滤部分。 |
| 示例 | <XT /> |
| 子标记 | RES |
| 内容格式 | 空 |
图片搜索查询的 XML 结果
此示例图片请求要求提供 5 条 (num=5) 与搜索字词“monkey”(q=monkey) 相关的结果。
http://www.google.com/cse? searchtype=image &num=2 &q=monkey &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
此请求会产生以下 XML 结果。
<GSP VER="3.2">
<TM>0.395037</TM>
<Q>monkeys</Q>
<PARAM name="cx" value="011737558837375720776:mbfrjmyam1g" original_value="011737558837375720776:mbfrjmyam1g" url_<escaped_value="011737558837375720776%3Ambfrjmyam1g" js_escaped_value="011737558837375720776:mbfrjmyam1g"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe" url_escaped_value="google-csbe" js_escaped_value="google-csbe"/>
<PARAM name="q" value="monkeys" original_value="monkeys" url_escaped_value="monkeys" js_escaped_value="monkeys"/>
<PARAM name="num" value="2" original_value="2" url_escaped_value="2" js_escaped_value="2"/>
<PARAM name="output" value="xml_no_dtd" original_value="xml_no_dtd" url_escaped_value="xml_no_dtd" js_escaped_value="xml_no_dtd"/>
<PARAM name="adkw" value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" original_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" url_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" js_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A"/>
<PARAM name="hl" value="en" original_value="en" url_escaped_value="en" js_escaped_value="en"/>
<PARAM name="oe" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="ie" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="boostcse" value="0" original_value="0" url_escaped_value="0" js_escaped_value="0"/>
<Context>
<title>domestigeek</title>
</Context>
<ARES/>
<RES SN="1" EN="2">
<M>2500000</M>
<NB>
<NU>/images?q=monkeys&num=2&hl=en&client=google-csbe&cx=011737558837375720776:mbfrjmyam1g&boostcse=0&output=xml_no_dtd
&ie=UTF-8&oe=UTF-8&tbm=isch&ei=786oTsLiJaaFiALKrPChBg&start=2&sa=N
</NU>
</NB>
<RG START="1" SIZE="2"/>
<R N="1" MIME="image/jpeg">
<RU>http://www.flickr.com/photos/fncll/135465558/</RU>
<U>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</U>
<UE>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</UE>
<T>Computer <b>Monkeys</b> | Flickr - Photo Sharing!</T>
<RK>0</RK>
<BYLINEDATE>1146034800</BYLINEDATE>
<S>Computer <b>Monkeys</b> | Flickr</S>
<LANG>en</LANG>
<IMG WH="500" HT="305" IID="ANd9GcQARKLwzi-t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs">
<SZ>88386</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="130" HT="79" URL="http://t0.gstatic.com/images?q=tbn:ANd9GcQARKLwzi-
t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs"/>
</R>
<R N="2" MIME="image/jpeg">
<RU>
http://www.flickr.com/photos/flickerbulb/187044366/
</RU>
<U>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</U>
<UE>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</UE>
<T>
one. ugly. <b>monkey</b>. | Flickr - Photo Sharing!
</T>
<RK>0</RK>
<BYLINEDATE>1152514800</BYLINEDATE>
<S>one. ugly. <b>monkey</b>.</S>
<LANG>en</LANG>
<IMG WH="400" HT="481" IID="ANd9GcQ3Qom0bYbee4fThCQVi96jMEwMU6IvVf2b8K5vERKVw-
EF4tQQnDDKOq0"><SZ>58339</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="107" HT="129" URL="http://t1.gstatic.com/images?q=tbn:ANd9GcQ3Qom0bYbee4fThCQ
Vi96jMEwMU6IvVf2b8K5vERKVw-EF4tQQnDDKOq0"/>
</R>
</RES>
</GSP>图片搜索:XML 标记
下表显示了图片搜索查询的 XML 响应中使用的其他 XML 标记。
在下面的定义中,某些子标记旁边可能会显示特定符号。这些符号及其含义如下:
* = 子标记的零个或多个实例
+ = 子标记的一个或多个实例
| RG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 定义 | <RG> 标记用于封装单个图片搜索结果的详细信息。 |
|||||||||
| 属性 |
| |||||||||
| 子标记 | RES | |||||||||
| RU | |
|---|---|
| 定义 | <RU 标记> 标记用于封装每个图片搜索结果的详细信息。 |
| 子标记 | R |