이 페이지에서는 Google 사이트 검색 고객에게만 제공되는 Custom Search JSON API의 XML 버전을 참조합니다.
개요
Google 웹 검색 서비스를 사용하면 Google 사이트 검색 고객이 자체 웹사이트에 Google 검색 결과를 표시할 수 있습니다. WebSearch 서비스는 간단한 HTTP 기반 프로토콜을 사용하여 검색 결과를 제공합니다. 검색 관리자는 검색 결과를 요청하는 방식과 최종 사용자에게 결과를 표시하는 방식을 완전히 제어할 수 있습니다. 이 문서에서는 Google 검색 요청 및 결과 형식의 기술 세부정보를 설명합니다.
Google 웹 검색 결과를 가져오려면 애플리케이션에서 Google에 간단한 HTTP 요청을 보냅니다. 그러면 Google에서 검색 결과를 XML 형식으로 반환합니다. XML 형식의 결과를 사용하면 검색 결과가 표시되는 방식을 맞춤설정할 수 있습니다.
WebSearch 요청 형식
- 요청 개요
- 검색어
- 요청 매개변수
- 샘플 웹 검색어
- WebSearch 쿼리 매개변수 정의
- 샘플 이미지 쿼리
- 이미지 검색 쿼리 매개변수 정의
- 고급 검색
- 고급 검색 쿼리 매개변수
- 특별 질문 용어
- 요청 한도
요청 개요
Google 검색 요청은 표준 HTTP GET 명령입니다. 여기에는 쿼리와 관련된 매개변수 모음이 포함됩니다. 이러한 매개변수는 앰퍼샌드 (&) 문자로 구분된 name=value 쌍으로 요청 URL에 포함됩니다. 매개변수에는 검색어와 HTTP 요청을 수행하는 엔진을 식별하는 고유 엔진 ID (cx)와 같은 데이터가 포함됩니다. WebSearch 또는 Image Search 서비스는 HTTP 요청에 대한 응답으로 XML 결과를 반환합니다.
검색어
대부분의 검색 요청에는 하나 이상의 쿼리어가 포함됩니다. 검색 요청에서 쿼리 용어가 매개변수 값으로 표시됩니다.
검색어는 Google에서 반환하는 검색 결과를 필터링하고 정리하기 위해 여러 유형의 정보를 지정할 수 있습니다. 검색어는 다음을 지정할 수 있습니다.
- 포함하거나 제외할 단어 또는 구문
- 검색어의 모든 단어 (기본값)
- 검색어의 정확한 문구
- 검색어의 단어나 구문
- 문서의 어느 부분에서 검색어를 찾아야 하는지 나타냅니다.
- 문서 전체 (기본값)
- 문서의 링크에만
- 문서 자체에 대한 제한사항
- 특정 파일 형식(예: PDF 파일 또는 Word 문서)의 문서를 포함하거나 제외
- 검색을 실행하는 대신 지정된 URL에 관한 정보를 반환하는 특수 URL 쿼리
- URL에 관한 일반 정보(예: Open Directory 카테고리, 스니펫, 언어)를 반환하는 쿼리
- URL에 연결되는 웹페이지 집합을 반환하는 쿼리
- 지정된 URL과 유사한 웹페이지 집합을 반환하는 쿼리
기본 검색
검색어 매개변수 값은 URL로 이스케이프되어야 합니다. 검색어의 공백 시퀀스는 더하기 기호 ('+')로 대체됩니다. 이에 대해서는 이 문서의 URL 이스케이핑 섹션에서 자세히 설명합니다.
검색어는 q 매개변수를 사용하여 WebSearch 서비스에 제출됩니다. 샘플 검색어는 다음과 같습니다.
q=horses+cows+pigs
기본적으로 Google WebSearch 서비스는 검색어의 모든 용어를 포함하는 문서만 반환합니다.
요청 매개변수
이 섹션에서는 검색 요청을 할 때 사용할 수 있는 매개변수를 나열합니다. 매개변수는 두 목록으로 나뉩니다. 첫 번째 목록에는 모든 검색 요청과 관련된 매개변수가 포함됩니다. 두 번째 목록에는 고급 검색 요청과 관련된 매개변수만 포함됩니다.
다음 세 가지 요청 매개변수가 필요합니다.
- client 매개변수를
google-csbe로 설정해야 합니다. - output 매개변수는 반환된 XML 결과의 형식을 지정합니다. 결과는 Google의 DTD에 대한 참조와 함께 (xml) 또는 참조 없이 (
xml_no_dtd) 반환될 수 있습니다. 이 값을xml_no_dtd로 설정하는 것이 좋습니다. 참고: 이 매개변수를 지정하지 않으면 결과가 XML 대신 HTML로 반환됩니다.
- 엔진의 고유 ID를 나타내는 cx 매개변수입니다.
위에서 언급한 매개변수 외에 가장 흔히 사용되는 요청 매개변수는 다음과 같습니다.
샘플 웹 검색 쿼리
아래 예에서는 다양한 쿼리 매개변수가 사용되는 방식을 보여주기 위해 몇 가지 WebSearch HTTP 요청을 보여줍니다. 다양한 쿼리 매개변수의 정의는 이 문서의 WebSearch 쿼리 매개변수 정의 및 고급 검색 쿼리 매개변수 섹션에 제공됩니다.
이 요청은 'red sox'(q=red+sox)이라는 검색어에 대한 처음 10개의 결과(start=0&num=10)를 요청합니다. 또한 이 요청은 결과가 캐나다 웹사이트 (cr=countryCA)에서 제공되어야 하고 프랑스어 (lr=lang_fr)로 작성되어야 한다고 지정합니다. 마지막으로 이 요청은 client, output, cx 매개변수의 값을 지정합니다. 이 세 가지 매개변수는 모두 필수입니다.
http://www.google.com/search?
start=0
&num=10
&q=red+sox
&cr=countryCA
&lr=lang_fr
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
이 예에서는 고급 검색 쿼리 매개변수를 사용하여 검색 쿼리를 추가로 맞춤설정합니다. 이 요청은 q 매개변수 대신 as_q 매개변수 (as_q=red+sox)를 사용합니다. 또한 as_eq 매개변수를 사용하여 'Yankees'라는 단어가 포함된 문서를 검색 결과에서 제외합니다 (as_eq=yankees).
http://www.google.com/search?
start=0
&num=10
&as_q=red+sox
&as_eq=Yankees
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
WebSearch 쿼리 매개변수 정의
| c2coff | |||||||
|---|---|---|---|---|---|---|---|
| 설명 | 선택사항. c2coff 매개변수는 간체 및 번체 중국어 검색 기능을 사용 설정하거나 사용 중지합니다. 이 파라미터의 기본값은
|
||||||
| 예시 | q=google&c2coff=1 |
||||||
| 클라이언트 | |
|---|---|
| 설명 | 필수사항: |
| 예시 | q=google&client=google-csbe |
| cr | |
|---|---|
| 설명 | 선택사항. Google WebSearch는 다음 항목을 분석하여 문서의 국가를 결정합니다.
이 매개변수의 유효한 값 목록은 국가 (cr) 매개변수 값 섹션을 참고하세요. |
| 예시 | q=Frodo&cr=countryNZ |
| cx | |
|---|---|
| 설명 | 필수사항: |
| 예시 | q=Frodo&cx=00255077836266642015:u-scht7a-8i |
| filter | |||||||
|---|---|---|---|---|---|---|---|
| 설명 | 선택사항. filter 매개변수는 Google 검색 결과의 자동 필터링을 활성화하거나 비활성화합니다. Google 검색 결과 필터에 관한 자세한 내용은 이 문서의 자동 필터링 섹션을 참고하세요.
참고: 기본적으로 Google은 모든 검색 결과에 필터링을 적용하여 검색 결과의 품질을 개선합니다. |
||||||
| 예시 | q=google&filter=0 |
||||||
| gl | |
|---|---|
| 설명 | 선택사항. WebSearch 요청에서 |
| 예시 | 이 요청은 WebSearch 결과에서 영국에서 작성된 문서를 부스팅합니다. |
| hl | |
|---|---|
| 설명 | 선택사항. 자세한 내용은 쿼리 및 결과 표시 국제화의 인터페이스 언어 섹션을 참고하고 지원되는 언어 목록은 지원되는 인터페이스 언어를 참고하세요. |
| 예시 | 이 요청은 프랑스어로 된 와인 광고를 타겟팅합니다. (Vin은 프랑스어로 와인을 뜻합니다.) q=vin&ip=10.10.10.10&ad=w5&hl=fr |
| hq | |
|---|---|
| 설명 | 선택사항. |
| 예시 | 이 요청은 'pizza' AND 'cheese'를 검색합니다. 표현식은
|
| ie | |
|---|---|
| 설명 | 선택사항. 이 매개변수를 사용해야 하는 경우에 대한 설명은 문자 인코딩 섹션을 참고하세요. 가능한 |
| 예시 | q=google&ie=utf8&oe=utf8 |
| lr | |
|---|---|
| 설명 | 선택사항. Google WebSearch는 다음 항목을 분석하여 문서의 언어를 결정합니다.
이 매개변수의 유효한 값 목록은 언어 ( |
| 예시 | q=Frodo&lr=lang_en |
| num | |
|---|---|
| 설명 | 선택사항. 기본 참고: 총 검색 결과 수가 요청된 결과 수보다 적으면 사용 가능한 모든 검색 결과가 반환됩니다. |
| 예시 | q=google&num=10 |
| oe | |
|---|---|
| 설명 | 선택사항. 이 매개변수를 사용해야 하는 경우에 대한 설명은 문자 인코딩 섹션을 참고하세요. 가능한 |
| 예시 | q=google&ie=utf8&oe=utf8 |
| output | |||||||
|---|---|---|---|---|---|---|---|
| 설명 | 필수사항:
|
||||||
| 예시 | output=xml_no_dtd |
||||||
| q | |
|---|---|
| 설명 | 선택사항.
Google 검색 관리 패널에는 참고: q 매개변수에 지정된 값은 URL 이스케이프되어야 합니다. |
| 예시 | q=vacation&as_oq=london+paris |
| 안전 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 설명 | 선택사항.
이 기능에 관한 자세한 내용은 세이프서치로 성인용 콘텐츠 필터링하기 섹션을 참고하세요. |
||||||||
| 예시 | q=adult&safe=high |
||||||||
| start | |
|---|---|
| 설명 | 선택사항.
|
| 예시 | start=10 |
| 정렬 | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
| ud | |
|---|---|
| 설명 | 선택사항. http://www.花井鮨.com 이 매개변수의 유효한 값은
http://www.xn--elq438j.com. 참고: 이 기능은 베타 기능입니다. |
| 예시 | q=google&ud=1 |
고급검색
이미지 아래에 나열된 추가 쿼리 매개변수는 고급 검색어와 관련이 있습니다. 고급 검색을 제출하면 여러 매개변수 (예: as_eq, as_epq, as_oq 등)의 값이 모두 해당 검색의 검색어에 반영됩니다. 이미지는 Google의 고급 검색 페이지를 보여줍니다. 이미지에서 각 고급 검색 매개변수의 이름은 해당 매개변수가 해당하는 페이지의 필드 내부 또는 옆에 빨간색 텍스트로 작성되어 있습니다.
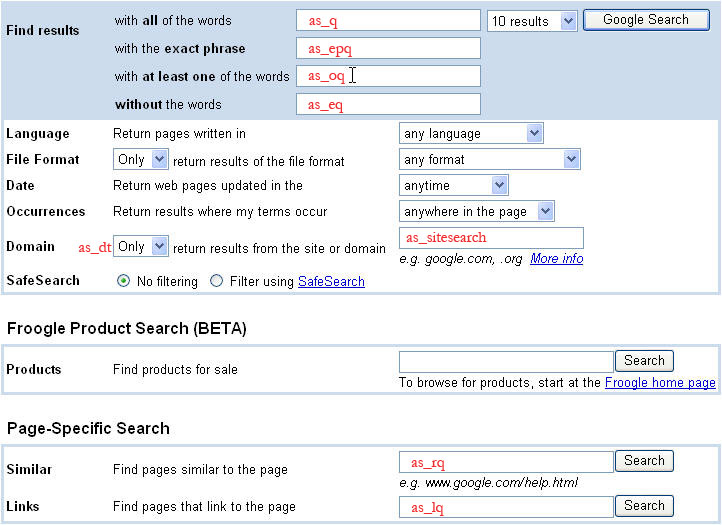
고급 검색 쿼리 매개변수
| as_dt | |
|---|---|
| 설명 | 선택사항. |
| 예시 | as_dt=i,as_dt=e |
| as_epq | |
|---|---|
| 설명 | 선택사항. |
| 예시 | as_epq=abraham+lincoln |
| as_eq | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
| as_lq | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
| as_nlo | |
|---|---|
| 설명 | 선택사항. |
| 예시 | 다음은 5~10(포함)의 검색 범위를 설정합니다.
|
| as_nhi | |
|---|---|
| 설명 | 선택사항. |
| 예시 | 다음은 5~10(포함)의 검색 범위를 설정합니다.
|
| as_oq | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
| as_q | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
| as_qdr | |
|---|---|
| 설명 | 선택사항.
|
| 예시 |
이 예시에서는 지난 1년간의 결과를 요청합니다.
이 예에서는 지난 10일 동안의 결과를 요청합니다.
|
| as_sitesearch | |
|---|---|
| 설명 | 선택사항. |
| 예시 |
|
특수 검색어
Google 웹 검색에서는 Google 검색 엔진의 추가 기능에 액세스하는 여러 특수 쿼리어를 사용할 수 있습니다. 이러한 특수 검색어는 q 요청 매개변수의 값에 포함되어야 합니다. 다른 검색어와 마찬가지로 특수 검색어도 URL 이스케이프 처리되어야 합니다. 특수 쿼리 용어 중 다수에는 콜론 (:)이 포함됩니다. 이 문자도 URL로 이스케이프 처리해야 하며 URL로 이스케이프 처리된 값은 %3A입니다.
| 백 링크[link:] | |
|---|---|
| 설명 |
as_lq 요청 매개변수를 사용하여 참고: |
| 예시 |
|
| 불리언 OR 검색 [ OR ] | |
|---|---|
| 설명 |
as_oq 요청 매개변수를 사용하여 검색어 집합에 있는 검색어를 검색할 수도 있습니다. 참고: 검색 요청에서 'London+OR+Paris'라는 쿼리를 지정하면 검색 결과에 이 두 단어 중 하나 이상이 포함된 문서가 포함됩니다. 경우에 따라 검색 결과의 문서에 두 단어가 모두 포함될 수 있습니다. |
| 예시 | 런던 또는 파리 검색: 사용자 입력:
london OR
paris 검색어:q=london+OR+paris휴가와 런던 또는 파리를 검색합니다. 쿼리 용어:
q=vacation+london+OR+paris휴가와 런던, 파리 또는 초콜릿 중 하나를 검색합니다. 쿼리 용어:
q=vacation+london+OR+paris+OR+chocolates휴가, 초콜릿, 런던 또는 파리를 검색하되 초콜릿에 가장 적은 가중치를 부여합니다. 쿼리 용어:
q=vacation+london+OR+paris+chocolates런던 또는 파리가 포함된 문서에서 휴가, 초콜릿, 꽃을 검색합니다. 쿼리 용어:
q=vacation+london+OR+paris+chocolates+flowers휴가와 런던 또는 파리 중 하나를 검색하고 초콜릿 또는 꽃 중 하나도 검색합니다. 쿼리 용어: q=vacation+london+OR+paris+chocolates+OR+flowers |
| 검색어 제외 [-] | |
|---|---|
| 설명 | 제외 (
제외 쿼리 용어는 검색어에 두 가지 이상의 의미가 있는 경우에 유용합니다. 예를 들어 '베이스'라는 단어를 사용하면 물고기 또는 음악에 관한 결과가 반환될 수 있습니다. 물고기에 관한 문서를 찾고 있다면 제외 쿼리 용어를 사용하여 음악에 관한 문서를 검색 결과에서 제외할 수 있습니다. as_eq 요청 매개변수를 사용하여 특정 단어나 구문과 일치하는 문서를 검색 결과에서 제외할 수도 있습니다. |
| 예시 | 사용자 입력: bass -music검색어: q=bass+%2Dmusic |
| 파일 형식 제외[ -filetype: ] | |
|---|---|
| 설명 |
참고: 쿼리에 Google에서 지원하는 파일 형식은 다음과 같습니다.
향후 파일 형식이 추가될 수 있습니다. 최신 목록은 언제든지 Google의 파일 형식 FAQ에서 확인할 수 있습니다. |
| 예시 | 이 예에서는 'Google'을 언급하지만 PDF 문서가 아닌 문서를 반환합니다. 이 예에서는 'Google'을 언급하는 문서를 반환하지만 PDF 문서와 Word 문서는 모두 제외합니다. |
| 파일 형식 필터링[ filetype: ] | |
|---|---|
| 설명 |
쿼리에 기본적으로 검색 결과에는 모든 파일 확장자가 있는 문서가 포함됩니다. Google에서 지원하는 파일 형식은 다음과 같습니다.
향후 파일 형식이 추가될 수 있습니다. 최신 목록은 언제든지 Google의 파일 형식 FAQ에서 확인할 수 있습니다. |
| 예시 | 이 예에서는 'Google'을 언급하는 PDF 문서를 반환합니다. 이 예에서는 'Google'을 언급하는 PDF 및 Word 문서를 반환합니다. |
| 검색어 포함[+] | |
|---|---|
| 설명 | 포함 (+) 쿼리 용어는 검색 결과에 포함된 모든 문서에 단어나 구문이 포함되어야 함을 지정합니다. 포함 쿼리 용어를 사용하려면 모든 검색 결과에 포함되어야 하는 단어나 구문 앞에 '+' (더하기 기호)를 붙입니다.
Google에서 검색 결과를 식별하기 전에 일반적으로 삭제하는 일반적인 단어 앞에 |
| 예시 | 사용자 입력: Star Wars Episode +I검색어: q=Star+Wars+Episode+%2BI |
| 링크만 검색, 모든 용어[ allinlinks: ] | |
|---|---|
| 설명 |
검색어에
|
| 예시 | 사용자 입력:allinlinks: Google search검색어: q=allinlinks%3A+Google+search |
| 구문 검색 | |
|---|---|
| 설명 | 구문 검색 (") 쿼리 용어를 사용하면 구문을 따옴표로 묶거나 하이픈으로 연결하여 완전한 구문을 검색할 수 있습니다.
구문 검색은 유명한 인용구 또는 고유명사를 검색할 때 특히 유용합니다. as_epq 요청 매개변수를 사용하여 구문 검색을 제출할 수도 있습니다. |
| 예시 | 사용자 입력:"Abraham Lincoln"검색어: q=%22Abraham+Lincoln%22 |
| 웹 문서 정보[info:] | |
|---|---|
| 설명 |
참고: |
| 예시 | 사용자 입력: info:www.google.com검색어: q=info%3Awww.google.com |
샘플 이미지 쿼리
아래 예는 다양한 쿼리 매개변수가 사용되는 방식을 보여주는 이미지 HTTP 요청을 보여줍니다. 다양한 쿼리 매개변수의 정의는 이 문서의 이미지 쿼리 매개변수 정의 섹션에 제공되어 있습니다.
이 요청은 파일 유형이 .png인 검색어 'monkey'(q=monkey)에 대한 처음 5개의 결과(start=0&num=5)를 요청합니다. 마지막으로 쿼리는 client, output, cx 매개변수의 값을 지정하며, 이 세 가지 매개변수는 모두 필수입니다.
http://www.google.com/cse? searchtype=image start=0 &num=5 &q=monkey &as_filetype=png &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
이미지 검색 쿼리 매개변수
| as_filetype | |
|---|---|
| 설명 | 선택사항. 지정된 유형의 이미지를 반환합니다. 허용되는 값은 |
| 예시 | q=google&as_filetype=png |
| imgsz | |
|---|---|
| 설명 | 선택사항. 지정된 크기의 이미지를 반환합니다. 여기서 크기는 다음 중 하나일 수 있습니다.
|
| 예시 | q=google&as_filetype=png&imgsz=icon |
| imgtype | |
|---|---|
| 설명 | 선택사항. 다음 중 하나일 수 있는 유형의 이미지를 반환합니다.
|
| 예시 | q=google&as_filetype=png&imgtype=photo |
| imgc | |
|---|---|
| 설명 | 선택사항. 흑백, 그레이 스케일 또는 컬러 이미지를 반환합니다.
|
| 예시 | q=google&as_filetype=png&imgc=gray |
| imgcolor | |
|---|---|
| 설명 | 선택사항. 특정 주요 색상의 이미지를 반환합니다.
|
| 예시 | q=google&as_filetype=png&imgcolor=yellow |
| as_rights | |
|---|---|
| 설명 | 선택사항. 라이선스에 따라 필터링합니다. 지원되는 값은 다음과 같습니다.
|
| 예시 | q=cats&as_filetype=png&as_rights=cc_attribute |
요청 한도
아래 차트에는 Google에 전송하는 검색 요청에 대한 제한사항이 나와 있습니다.
| 구성요소 | 한도 | 댓글 |
|---|---|---|
| 검색 요청 길이 | 2,048바이트 | |
| 질문 용어 수 | 10 | q, as_epq, as_eq, as_lq, as_oq, as_q 매개변수에 용어가 포함됩니다. |
| 알림당 결과 수 | 20 | num 매개변수를 20보다 큰 숫자로 설정하면 결과가 20개만 반환됩니다. 결과를 더 많이 가져오려면 요청을 여러 번 보내고 각 요청마다 start 매개변수의 값을 늘려야 합니다. |
질문 및 결과 표시 국제화
Google 웹 검색 서비스를 사용하면 여러 언어로 문서를 검색할 수 있습니다. HTTP 요청을 해석하고 XML 응답을 인코딩하는 데 사용할 문자 인코딩을 지정할 수 있습니다(ie 및 oe 검색 매개변수 사용). 특정 언어로 작성된 문서만 포함하도록 결과를 필터링할 수도 있습니다.
다음 섹션에서는 여러 언어로 검색하는 것과 관련된 문제를 설명합니다.
문자 인코딩
서버는 인코딩된 바이트 시퀀스로 웹페이지와 같은 데이터를 브라우저와 같은 사용자 에이전트에 전송합니다. 그러면 사용자 에이전트가 바이트를 문자 시퀀스로 디코딩합니다. WebSearch 서비스에 요청을 보낼 때 검색어와 수신하는 XML 응답의 인코딩 체계를 모두 지정할 수 있습니다.
ie 요청 매개변수를 사용하여 HTTP 요청의 문자 인코딩 메커니즘을 지정할 수 있습니다. oe 매개변수를 사용하여 Google에서 XML 응답을 인코딩하는 데 사용해야 하는 인코딩 스키마를 지정할 수도 있습니다. ISO-8859-1 (또는 latin1) 이외의 인코딩 체계를 사용하는 경우 ie 및 oe 매개변수에 올바른 값을 지정해야 합니다.
참고: 여러 언어의 검색 기능을 제공하는 경우 ie 및 oe 매개변수 모두에 utf8 (UTF-8) 인코딩 값을 사용하는 것이 좋습니다.
ie 및 oe 매개변수에 사용할 수 있는 값의 전체 목록은 문자 인코딩 방식 부록을 참고하세요.
문자 인코딩에 관한 일반적인 내용은 http://www.w3.org/TR/REC-html40/charset.html을 참고하세요.
인터페이스 언어
hl 요청 파라미터를 사용하여 그래픽 인터페이스의 언어를 식별할 수 있습니다. hl 파라미터 값은 특히 언어 제한 (lr 파라미터 사용)이 명시적으로 지정되지 않은 국제 검색어의 경우 XML 검색 결과에 영향을 줄 수 있습니다. 이러한 경우 hl 파라미터는 사용자의 입력 언어와 동일한 언어로 된 검색 결과를 우선적으로 표시할 수 있습니다.
Google이 각 쿼리에 대해 가장 높은 품질의 검색 결과를 선택하도록 검색 결과에서 hl 매개변수를 명시적으로 설정하는 것이 좋습니다.
hl 매개변수의 유효한 값의 전체 목록은 지원되는 인터페이스 언어 섹션을 참고하세요.
특정 언어로 작성된 문서 검색
lr 요청 매개변수를 사용하여 검색 결과를 특정 언어 또는 언어 집합으로 작성된 문서로 제한할 수 있습니다.
lr 매개변수는 불리언 연산자를 지원하므로 검색 결과에 포함 (또는 제외)할 여러 언어를 지정할 수 있습니다.
다음 예에서는 불리언 연산자를 사용하여 다양한 언어로 문서를 요청하는 방법을 보여줍니다.
일본어로 작성된 문서의 경우:
lr=lang_jp
이탈리아어 또는 독일어로 작성된 문서의 경우:
lr=lang_it|lang_de
헝가리어 또는 체코어로 작성되지 않은 문서의 경우:
lr=(-lang_hu).(-lang_cs)
lr 매개변수의 가능한 값의 전체 목록은 언어 컬렉션 값 섹션을 참고하고, 이러한 연산자 사용에 대한 전체 논의는 불리언 연산자 섹션을 참고하세요.
중국어 간체 및 번체 검색
중국어 간체와 중국어 번체는 중국어의 두 가지 쓰기 변형입니다. 동일한 개념이 각 변형에서 다르게 작성될 수 있습니다. 변형 중 하나로 검색어를 입력하면 Google 웹 검색 서비스에서 두 변형의 페이지를 모두 포함하는 결과를 반환할 수 있습니다.
이 기능을 사용하려면 다음과 같이 하세요.
- c2coff 요청 매개변수를 0으로 설정합니다.
그리고 - 다음 중 한 가지 방법을 사용합니다.
다음 예에서는 간체 중국어와 번체 중국어로 결과를 요청할 때 포함할 쿼리 매개변수를 보여줍니다. (client와 같은 추가 필수 정보는 예에 포함되지 않습니다.)
search?hl=zh-CN
&lr=lang_zh-TW|lang_zh-CN
&c2coff=0결과 필터링
Google 웹 검색에서는 검색 결과를 필터링하는 다양한 방법을 제공합니다.
검색 결과 자동 필터링
최상의 검색 결과를 제공하기 위해 Google에서는 다음 두 가지 기법을 사용하여 일반적으로 바람직하지 않은 것으로 간주되는 검색 결과를 자동으로 필터링합니다.
-
중복 콘텐츠: 여러 문서에 동일한 정보가 포함되어 있으면 해당 세트 중 가장 관련성이 높은 문서만 검색 결과에 포함됩니다.
-
호스트 크라우딩: 동일한 사이트의 검색 결과가 여러 개 있는 경우 Google에서는 해당 사이트의 결과를 모두 표시하지 않거나
그렇지 않은 경우보다 순위를 낮춰 표시할 수 있습니다.
필터는 대부분의 검색 결과의 품질을 크게 향상시키므로 일반적인 검색 요청에는 이러한 필터를 사용 설정해 두는 것이 좋습니다. 하지만 검색 요청에서 filter 쿼리 매개변수를 0으로 설정하면 이러한 자동 필터를 우회할 수 있습니다.
언어 및 국가 필터링
Google WebSearch 서비스는 모든 웹 문서의 마스터 색인에서 결과를 반환합니다. 마스터 색인에는 언어와 출신 국가 등 특정 속성별로 그룹화된 문서의 하위 컬렉션이 포함됩니다.
lr 및 cr 요청 매개변수를 사용하여 검색 결과를 특정 언어로 작성되거나 특정 국가에서 유래한 문서의 하위 컬렉션으로 각각 제한할 수 있습니다.
Google WebSearch는 다음 항목을 분석하여 문서의 언어를 결정합니다.
- 문서 URL의 최상위 도메인 (TLD)
- 문서 내 언어 메타 태그
- 문서의 본문 텍스트에 사용되는 기본 언어
언어를 기준으로 결과를 제한하는 방법에 대한 자세한 내용은 lr 매개변수 정의, 특정 언어로 작성된 문서 검색 섹션, lr 매개변수의 값으로 사용할 수 있는 언어 컬렉션 값을 참고하세요.
Google WebSearch는 다음 항목을 분석하여 문서의 국가를 결정합니다.
- 문서 URL의 최상위 도메인 (TLD)
- 웹 서버 IP 주소의 지리적 위치
원산지 국가별로 결과를 제한하는 방법에 대한 자세한 내용은 cr 매개변수 정의와 cr 매개변수의 값으로 사용할 수 있는 국가 컬렉션 값을 참고하세요.
참고: 언어 값과 국가 값을 결합하여 검색 결과를 맞춤설정할 수 있습니다. 예를 들어 프랑스나 캐나다에서 온 프랑스어로 작성된 문서를 요청하거나 네덜란드에서 온 영어로 작성되지 않은 문서를 요청할 수 있습니다. lr 및 cr 매개변수는 모두 불리언 연산자를 지원합니다.
세이프서치로 성인용 콘텐츠 필터링
많은 Google 고객은 성인용 콘텐츠가 포함된 사이트의 검색 결과를 표시하지 않기를 원합니다. Google의 세이프서치 필터를 사용하면 성인용 콘텐츠가 포함된 검색 결과를 검사하여 삭제할 수 있습니다. Google의 필터는 독점 기술을 사용하여 키워드, 문구, URL을 확인합니다. 100% 정확한 필터는 없지만 세이프서치는 검색 결과에서 대부분의 성인용 콘텐츠를 삭제합니다.
Google은 웹을 지속적으로 크롤링하고 사용자 제안의 업데이트를 통합하여 세이프서치를 최대한 최신 상태로 유지하기 위해 노력합니다.
세이프서치는 다음 언어로 제공됩니다.
| 네덜란드어 영어 프랑스어 독일어 |
이탈리아어 포르투갈어(브라질) 스페인어 중국어(번체) |
safe 쿼리 매개변수를 사용하여 Google에서 성인용 콘텐츠를 필터링하는 정도를 조정할 수 있습니다. 다음 표에서는 Google 세이프서치 설정과 이러한 설정이 검색 결과에 미치는 영향을 설명합니다.
| 세이프서치 수준 | 설명 |
|---|---|
| 높음 | 더 엄격한 버전의 세이프서치를 사용 설정합니다. |
| 중간 | 포르노 및 기타 성적인 콘텐츠가 포함된 웹페이지를 차단합니다. |
| 사용 안함 | 검색 결과에서 성인용 콘텐츠를 필터링하지 않습니다. |
* 기본 세이프서치 설정은 사용 안함입니다.
세이프서치를 사용 설정했는데 검색 결과에 불쾌감을 주는 콘텐츠가 포함된 사이트가 표시되면 사이트의 URL을 safesearch@google.com으로 이메일을 보내주세요. Google에서 사이트를 조사하겠습니다.
XML 결과
Google XML 결과 DTD
Google은 모든 유형의 검색 결과에 동일한 DTD를 사용하여 XML 형식을 설명합니다. 태그와 속성 대부분은 모든 검색 유형에 적용됩니다. 하지만 일부 태그는 특정 검색 유형에만 적용됩니다. 따라서 DTD의 정의는 이 문서에 제공된 정의보다 제한적이지 않을 수 있습니다.
이 문서에서는 웹 검색과 관련된 DTD의 측면을 설명합니다. DTD를 볼 때 WebSearch에서 작업하는 경우 여기에 문서화되지 않은 태그와 속성은 무시해도 됩니다. DTD와 문서 간에 정의가 다른 경우 이 문서에 해당 사실이 명시됩니다.
Google은 최신 DTD에 대한 참조를 포함하거나 포함하지 않고 XML 결과를 반환할 수 있습니다. DTD는 검색 관리자와 XML 파서가 Google의 XML 결과를 이해하는 데 도움이 되는 가이드입니다. Google의 XML 문법은 경우에 따라 변경될 수 있으므로 DTD를 사용하여 각 XML 결과를 검증하도록 파서를 구성해서는 안 됩니다.
또한 검색 요청을 제출할 때마다 DTD를 가져오도록 XML 파서를 구성해서는 안 됩니다. Google은 DTD를 자주 업데이트하지 않으며 이러한 요청은 불필요한 지연과 대역폭 요구사항을 만듭니다.
XML 결과를 얻으려면 xml_no_dtd 출력 형식을 사용하는 것이 좋습니다. 검색 요청에서 xml 출력 형식을 지정하면 XML 결과에 다음 줄이 포함된다는 점만 다릅니다.
<!DOCTYPE GSP SYSTEM "google.dtd">최신 DTD는 http://www.google.com/google.dtd에서 확인할 수 있습니다.
현재 DTD의 일부 기능은 지원되지 않을 수 있습니다.
XML 응답 정보
- 모든 요소 값은 XML 태그 정의에 달리 명시되지 않는 한 표시하기에 적합한 유효한 HTML입니다.
- 일부 요소 값은 표시되기 전에 HTML로 인코딩해야 하는 URL입니다.
- XML 파서는 문서화되지 않은 속성과 태그를 무시해야 합니다. 이렇게 하면 Google에서 XML 출력에 기능을 추가하더라도 애플리케이션이 수정 없이 계속 작동할 수 있습니다.
- 특정 문자는 XML 태그에 값으로 포함될 때 이스케이프해야 합니다. XML 프로세서는 이러한 엔티티를 적절한 문자로 다시 변환해야 합니다. 엔티티를 올바르게 변환하지 않으면 브라우저에서 예를 들어 '&' 문자를 '&'로 렌더링할 수 있습니다. XML 표준에 이러한 문자가 문서화되어 있으며 아래 표에 이러한 문자가 재현되어 있습니다.
문자 이스케이프된 양식 항목 문자 코드 앰퍼샌드 & & & 작은따옴표 ' ' ' 큰따옴표 " " " 초과 > > > 미만 < < <
일반 및 고급 검색어의 XML 결과
일반/고급 검색: 샘플 쿼리 및 XML 결과
이 샘플 WebSearch 요청은 검색어 'socer'(q=socer)에 관한 10개의 결과(num=10)를 요청합니다. 'socer'는 이 예시를 위해 의도적으로 잘못된 철자로 입력된 단어 'soccer'입니다.
http://www.google.com/search?
q=socer
&hl=en
&start=10
&num=10
&output=xml
&client=google-csbe
&cx=00255077836266642015:u-scht7a-8i
이 요청은 아래의 XML 결과를 생성합니다. 결과에 포함되지 않은 특정 태그가 표시되는 위치를 나타내는 주석이 XML 결과에 여러 개 있습니다.
<?xml version="1.0" encoding="ISO-8859-1" standalone="no" ?>
<GSP VER="3.2">
<TM>0.452923</TM>
<Q>socer</Q>
<PARAM name="cx" value="00255077836266642015:u-scht7a-8i" original_value="00255077836266642015%3Au-scht7a-8i"/>
<PARAM name="hl" value="en" original_value="en"/>
<PARAM name="q" value="socer" original_value="socer"/>
<PARAM name="output" value="xml" original_value="xml"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe"/>
<PARAM name="num" value="10" original_value="10"/>
<Spelling>
<Suggestion q="soccer"><b><i>soccer</i></b></Suggestion>
</Spelling>
<Context>
<title>Sample Vacation CSE</title>
<Facet>
<FacetItem>
<label>restaurants</label>
<anchor_text>restaurants</anchor_text>
</FacetItem>
<FacetItem>
<label>wineries</label>
<anchor_text>wineries</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>golf_courses</label>
<anchor_text>golf courses</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>hotels</label>
<anchor_text>hotels</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>nightlife</label>
<anchor_text>nightlife</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>soccer_sites</label>
<anchor_text>soccer sites</anchor_text>
</FacetItem>
</Facet>
</Context>
<RES SN="1" EN="10">
<M>6080</M>
/*
* The FI tag after the comment indicates that the result
* set has been filtered. If the number of results were exact, the
* FI tag would be replaced by an XT tag in the same format.
*/
<FI />
<NB>
/*
* Since the request is for the first page of results, the PU tag,
* which contains a link to the previous page of search results,
* is not included in this XML result. If the sample result did include
* a previous page of results, it would be listed here, in the same format
* as the NU tag on the following line
*/
<NU>/search?q=socer&hl=en&lr=&ie=UTF-8&output=xml&client=test&start=10&sa=N</NU>
</NB>
<R N="1">
<U>http://www.soccerconnection.net/</U>
<UE>http://www.soccerconnection.net/</UE>
<T>SoccerConnection.net</T>
<CRAWLDATE>May 21, 2007</CRAWLDATE>
<S><b>soccer</b>; players; coaches; ball; world cup;<b>...</b></S>
<Label>transcodable_pages</Label>
<Label>accessible</Label>
<Label>soccer_sites</Label>
<LANG>en</LANG>
<HAS>
<DI>
<DT>SoccerConnection.net</DT>
<DS>Post your <b>soccer</b> resume directly on the Internet.</DS>
</DI>
<L/>
<C SZ="8k" CID="kWAPoYw1xIUJ"/>
<RT/>
</HAS>
</R>
/*
* The result includes nine more results, each enclosed by an R tag.
*/
</RES>
</GSP>
일반/고급 검색: XML 태그
일반 검색 요청과 고급 검색 요청의 XML 응답은 모두 동일한 XML 태그 집합을 사용합니다. 이러한 XML 태그는 위의 XML 예에 표시되어 있으며 아래 표에 설명되어 있습니다.
아래 XML 태그는 태그 이름의 알파벳순으로 나열되어 있으며 각 태그 정의에는 태그 설명, XML 결과에 태그가 표시되는 방식을 보여주는 예, 태그 콘텐츠 형식이 포함되어 있습니다. 태그가 다른 XML 태그의 하위 태그이거나 태그에 자체 하위 태그나 속성이 있는 경우 해당 정보도 태그의 정의 표에 제공됩니다.
아래 정의의 일부 하위 태그 옆에 특정 기호가 표시될 수 있습니다. 이러한 기호와 기호의 의미는 다음과 같습니다.
* = 하위 태그의 인스턴스가 0개 이상
+ = 하위 태그의 인스턴스가 1개 이상
| A | B | C | D | F | H | I | L | M | 북 | P | Q | R | 남 | T | U | X |
| anchor_text | |
|---|---|
| 정의 | <anchor_text> 태그는 검색 결과 세트와 연결된 세부검색 라벨을 식별하기 위해 사용자에게 표시해야 하는 텍스트를 지정합니다. 세부검색 라벨은 영숫자가 아닌 문자를 밑줄로 대체하므로 사용자 인터페이스에 <label> 태그의 값을 표시해서는 안 됩니다. 대신 <anchor_text> 태그의 값을 표시해야 합니다. |
| 예 | <anchor_text>골프 코스</anchor_text> |
| 하위 태그 | FacetItem |
| 콘텐츠 형식 | 텍스트 |
| 차단 | |
|---|---|
| 정의 | 이 태그는 프로모션 결과의 본문 줄에 있는 블록의 콘텐츠를 캡슐화합니다. 각 블록에는 하위 태그 T, U, L이 있습니다. 비어 있지 않은 T 태그는 블록에 텍스트가 포함되어 있음을 나타내고, 비어 있지 않은 U 및 L 태그는 블록에 링크가 포함되어 있음을 나타냅니다 (U 하위 태그에 URL이 제공되고 L 하위 태그에 앵커 텍스트가 있음). |
| 하위 태그 | T, U, L |
| 하위 태그 | BODY_LINE |
| 콘텐츠 형식 | 비어 있음 |
| BODY_LINE | |
|---|---|
| 정의 | 이 태그는 프로모션 결과 본문의 행 콘텐츠를 캡슐화합니다. 각 본문 줄은 텍스트 또는 URL과 앵커 텍스트가 포함된 링크를 포함하는 여러 BLOCK 태그로 구성됩니다. |
| 하위 태그 | 차단* |
| 하위 태그 | SL_MAIN |
| 콘텐츠 형식 | 비어 있음 |
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 정의 | <C> 태그는 WebSearch 서비스가 이 검색 결과 URL의 캐시된 버전을 가져올 수 있음을 나타냅니다. XML API를 통해 캐시된 페이지를 가져올 수는 없지만 이 콘텐츠에 대해 사용자를 www.google.com으로 리디렉션할 수는 있습니다. |
|||||||||
| 속성 |
|
|||||||||
| 예 | <C SZ="6k" CID="kvOXK_cYSSgJ" /> | |||||||||
| 하위 태그 | HAS | |||||||||
| 콘텐츠 형식 | 비어 있음 | |||||||||
| C2C | |
|---|---|
| 정의 | <C2C> 태그는 결과가 중국어(번체) 페이지를 참조함을 나타냅니다. 이 태그는 중국어 간체 및 번체 검색이 사용 설정된 경우에만 표시됩니다. 이 기능을 사용 설정 및 중지하는 방법에 관한 자세한 내용은 c2coff 쿼리 매개변수 정의를 참고하세요. |
| 콘텐츠 형식 | 텍스트 |
| 컨텍스트 | |
|---|---|
| 정의 | <Context> 태그는 검색 결과 집합과 연결된 세부검색 라벨 목록을 캡슐화합니다. |
| 예 | <Context> |
| 하위 태그 | title, Facet+ |
| 콘텐츠 형식 | 컨테이너 |
| CRAWLDATE | |
|---|---|
| 정의 | <CRAWLDATE> 태그는 페이지가 마지막으로 크롤링된 날짜를 식별합니다. |
| 예 | <CRAWLDATE>2005년 5월 21일</CRAWLDATE> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 |
| DI | |
|---|---|
| 정의 | <DI> 태그는 단일 검색 결과의 공개 디렉터리 프로젝트(ODP) 카테고리 정보를 캡슐화합니다. |
| 예 | <DI> |
| 하위 태그 | DT?, DS? |
| 하위 태그 | HAS |
| 콘텐츠 형식 | 비어 있음 |
| DS | |
|---|---|
| 정의 | <DS> 태그는 ODP 디렉터리의 단일 카테고리에 대해 나열된 요약을 제공합니다. |
| 예 | <DS>인터넷에 바로 <b>축구</b> 이력서를 게시하세요.</DS> |
| 하위 태그 | DI |
| 콘텐츠 형식 | 텍스트 (HTML 포함 가능) |
| DT | |
|---|---|
| 정의 | <DT> 태그는 ODP 디렉터리에 나열된 단일 카테고리의 제목을 제공합니다. |
| 예 | <DT>SoccerConnection.net</DT> |
| 하위 태그 | DI |
| 콘텐츠 형식 | 텍스트 (HTML 포함 가능) |
| 패싯 | |
|---|---|
| 정의 | <Facet> 태그에는 <FacetItem> 태그의 논리적 그룹이 포함됩니다. 프로그래밍 검색 엔진 엔진 XML 사양 형식을 사용하여 이러한 그룹을 만들 수 있습니다. 이러한 그룹을 만들지 않으면 results_xml_tag_Context><Context> 태그에 최대 4개의 <Facet> 태그가 포함됩니다. 각 <Facet> 태그 내의 항목은 표시 목적으로 그룹화되지만 논리적 관계가 없을 수도 있습니다. |
| 예 | <Facet> |
| 하위 태그 | FacetItem+, title+ |
| 상위 태그 | 컨텍스트 |
| 콘텐츠 형식 | 컨테이너 |
| FacetItem | |
|---|---|
| 정의 | <FacetItem> 태그는 검색 결과 집합과 연결된 상세검색 라벨에 관한 정보를 요약합니다. |
| 예 | <FacetItem> |
| 하위 태그 | label, anchor_text+ |
| 상위 태그 | 패싯 |
| 콘텐츠 형식 | FacetItem |
| FI | |
|---|---|
| 정의 | <FI> 태그는 검색에 문서 필터링이 실행되었는지 여부를 나타내는 플래그 역할을 합니다. Google 검색 결과 필터에 관한 자세한 내용은 이 문서의 자동 필터링 섹션을 참고하세요. |
| 예 | <FI /> |
| 하위 태그 | RES |
| 콘텐츠 형식 | 비어 있음 |
| GSP | |||||||
|---|---|---|---|---|---|---|---|
| 정의 | <GSP> 태그는 Google XML 검색 결과에 반환된 모든 데이터를 캡슐화합니다. 'GSP'는 'Google 검색 프로토콜'의 약어입니다. |
||||||
| 속성 |
|
||||||
| 예 | <GSP VER="3.2"> | ||||||
| 하위 태그 | PARAM+, Q, RES?, TM | ||||||
| 콘텐츠 형식 | 비어 있음 | ||||||
| HAS | |
|---|---|
| 정의 | <HAS> 태그는 특정 URL에 지원되는 특수 검색 요청 매개변수에 관한 정보를 캡슐화합니다.
참고: WebSearch의 <HAS> 정의는 DTD보다 더 제한적입니다. |
| 하위 태그 | DI?, L? C? RT? |
| 하위 태그 | R |
| ISURL | |
|---|---|
| 정의 | 연결된 검색어가 URL인 경우 Google은 <ISURL> 태그를 반환합니다. |
| 하위 태그 | GSP |
| 콘텐츠 형식 | 비어 있음 |
| L | |
|---|---|
| 정의 | <L> 태그가 있으면 WebSearch 서비스가 이 검색 결과 URL에 연결된 다른 사이트를 찾을 수 있음을 나타냅니다. 이러한 사이트를 찾으려면 link: 특수 검색어 용어를 사용합니다. |
| 하위 태그 | HAS |
| 콘텐츠 형식 | 비어 있음 |
| 라벨 | |
|---|---|
| 정의 | <label> 태그는 수신하는 검색 결과를 필터링하는 데 사용할 수 있는 세부검색 라벨을 지정합니다. 세부검색 라벨을 사용하려면 다음 예와 같이 Google에 대한 HTTP 요청에서 q 매개변수의 값에 more:[[라벨 태그 값]] 문자열을 추가합니다. 이 값은 Google에 쿼리를 보내기 전에 URL로 이스케이프되어야 합니다. This example uses the refinement label golf_courses to 참고: <label> 태그는 검색 결과의 특정 URL과 연결된 세부검색 라벨을 식별하는 <Label> 태그와 다릅니다. |
| 예 | <label>golf_courses</label> |
| 하위 태그 | FacetItem |
| 콘텐츠 형식 | 텍스트 |
| LANG | |
|---|---|
| 정의 | <LANG> 태그에는 Google에서 추정한 검색 결과의 언어가 포함됩니다. |
| 예 | <LANG>en</LANG> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 |
| M | |
|---|---|
| 정의 | <M> 태그는 검색의 예상 총 결과 수를 식별합니다. 참고: 이 추정치는 정확하지 않을 수 있습니다. |
| 예 | <M>16200000</M> |
| 상위 태그 | RES |
| 콘텐츠 형식 | 텍스트 |
| NB | |
|---|---|
| 정의 | <NB> 태그는 결과 집합의 탐색 정보(검색 결과의 다음 페이지 또는 이전 페이지로 연결되는 링크)를 캡슐화합니다. 참고: 이 태그는 더 많은 결과를 사용할 수 있는 경우에만 표시됩니다. |
| 예 | <NB> |
| 하위 태그 | NU?, PU? |
| 하위 태그 | RES |
| 콘텐츠 형식 | 비어 있음 |
| NU | |
|---|---|
| 정의 | <NU> 태그에는 검색 결과의 다음 페이지로 연결되는 상대 링크가 포함됩니다. |
| 예 | <NU>/search?q=flowers&num=10&hl=en&ie=UTF-8 &output=xml&client=test&start=10</NU> |
| 상위 태그 | NB |
| 콘텐츠 형식 | 텍스트 (상대 URL) |
| PARAM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 정의 | <PARAM> 태그는 XML 결과와 연결된 HTTP 요청에 제출된 입력 매개변수를 식별합니다. 매개변수에 관한 정보는 태그 속성(name, value, original_value)에 포함되며 HTTP 요청에 제출된 각 매개변수에 대해 하나의 PARAM 태그가 있습니다. |
||||||||||||
| 속성 |
|
||||||||||||
| 예 | <PARAM name="cr" value="countryNZ" original_value="countryNZ" /> | ||||||||||||
| 하위 태그 | GSP | ||||||||||||
| 콘텐츠 형식 | 복잡 | ||||||||||||
| PU | |
|---|---|
| 정의 | <PU> 태그는 검색 결과의 이전 페이지에 대한 상대 링크를 제공합니다. |
| 예 | <PU>/search?q=flowers&num=10&hl=en&output=xml &client=test&start=10</PU> |
| 하위 태그 | NB |
| 콘텐츠 형식 | 텍스트 (상대 URL) |
| Q | |
|---|---|
| 정의 | <Q> 태그는 XML 결과와 연결된 HTTP 요청에 제출된 검색어를 식별합니다. |
| 예 | <Q>pizza</Q> |
| 하위 태그 | GSP |
| 콘텐츠 형식 | 텍스트 |
| R | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 정의 | <R> 태그는 개별 검색 결과의 세부정보를 캡슐화합니다. 참고: WebSearch의 <R> 태그 정의는 DTD보다 더 제한적입니다. |
|||||||||
| 속성 |
|
|||||||||
| 하위 태그 | U, UE, T?, CRAWLDATE, S?, LANG?, HAS | |||||||||
| 상위 태그 | RES | |||||||||
| 저항군 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 정의 | <RES> 태그는 개별 검색 결과와 해당 결과에 관한 세부정보를 캡슐화합니다. |
|||||||||
| 속성 |
|
|||||||||
| 예 | <RES SN="1" EN="10"> | |||||||||
| 하위 태그 | M, FI?, XT?, NB?, R* | |||||||||
| 하위 태그 | GSP | |||||||||
| 콘텐츠 형식 | 비어 있음 | |||||||||
| S | |
|---|---|
| 정의 | <S> 태그에는 검색 결과의 발췌문이 포함되어 있으며, 발췌문에는 쿼리 용어가 굵게 강조 표시되어 있습니다. 줄바꿈은 텍스트 줄바꿈을 올바르게 처리하기 위해 발췌문에 포함됩니다. |
| 예 | <S>워싱턴 (CNN) -- <b>부시</b> 대통령의 사법부 지명자들을 둘러싼 상원의 대치를 끝내기 위한 입찰은 5명의 지명자가 최종 투표로 진출할 수 있도록 허용하면서 <b>...<b>...</b><S> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 (HTML) |
| SL_MAIN | |
|---|---|
| 정의 | 이 태그는 프로모션 결과의 콘텐츠를 캡슐화합니다. 프로모션 파싱에 사용됩니다. 제목 링크의 앵커 텍스트와 URL은 각각 T 및 U 하위 태그에 포함됩니다. 본문 텍스트와 링크는 BODY_LINE 하위 태그에 포함됩니다. |
| 하위 태그 | BODY_LINE*, T, U |
| 하위 태그 | SL_RESULTS |
| 콘텐츠 형식 | 비어 있음 |
| SL_RESULTS | |
|---|---|
| 정의 | 프로모션 결과의 컨테이너 태그입니다. 검색 결과에 프로모션이 표시될 때마다 이러한 항목 중 하나가 표시됩니다. SL_MAIN 하위 태그에는 기본 결과 데이터가 포함됩니다. |
| 하위 태그 | SL_MAIN* |
| 하위 태그 | R |
| 콘텐츠 형식 | 비어 있음 |
| 맞춤법 | |
|---|---|
| 정의 | <Spelling> 태그는 제출된 질문의 대체 맞춤법 제안을 요약합니다. 이 태그는 검색 결과의 첫 페이지에만 표시됩니다. 맞춤법 제안은 한국어, 영어, 중국어, 일본어로 제공됩니다. 참고: Google은 gl 매개변수 값이 소문자인 쿼리에 대해서만 맞춤법 제안을 반환합니다. |
| 예 | <Spelling> |
| 하위 태그 | 제안 |
| 하위 태그 | GSP |
| 콘텐츠 형식 | 비어 있음 |
| 추천 | |||||||
|---|---|---|---|---|---|---|---|
| 정의 | <Suggestion> 태그에는 제출된 쿼리의 대체 맞춤법 제안이 포함됩니다. 태그의 콘텐츠를 사용하여 검색 사용자에게 대체 철자를 제안할 수 있습니다. q 속성의 값은 쿼리 용어로 사용할 수 있는 URL로 이스케이프된 맞춤법 제안입니다. | ||||||
| 속성 |
|
||||||
| 예 | <Suggestion q="soccer"><b><i>soccer</i></b></Suggestion> | ||||||
| 하위 태그 | 맞춤법 | ||||||
| 콘텐츠 형식 | 텍스트 (HTML) | ||||||
| T | |
|---|---|
| 정의 | <T> 태그에는 결과의 제목이 포함됩니다. |
| 예 | <T>Amici's East Coast Pizzeria</T> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 (HTML) |
| 제목 | |
|---|---|
| 정의 | <Context>의 하위 요소인 <title> 태그에는 프로그래밍 검색 엔진의 이름이 포함됩니다. <Facet>의 하위 요소인 <title> 태그는 패싯 집합의 제목을 제공합니다. |
| 예 | <Context>의 하위 요소: <title>내 검색엔진</title> <Facet>의 하위 요소: <title>facet title</title> |
| 하위 태그 | Context, Facet |
| 콘텐츠 형식 | 텍스트 |
| TM | |
|---|---|
| 정의 | <TM> 태그는 검색 결과를 반환하는 데 필요한 총 서버 시간을 초 단위로 식별합니다. |
| 예 | <TM>0.100445</TM> |
| 하위 태그 | GSP |
| 콘텐츠 형식 | 텍스트 (부동 소수점 수) |
| TT | |
|---|---|
| 정의 | <TT> 태그는 검색 도움말을 제공합니다. |
| 예 | <TT><i>도움말: 대부분의 브라우저에서 Return 키를 누르면 검색 버튼을 클릭하는 것과 동일한 결과가 표시됩니다.</i></TT> |
| 하위 태그 | GSP |
| U | |
|---|---|
| 정의 | <U> 태그는 검색 결과의 URL을 제공합니다. |
| 예 | <U>http://www.dominos.com/</U> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 (절대 URL) |
| UD | |
|---|---|
| 정의 | <UD> 태그는 검색 결과의 IDN 인코딩(International Domain Name) URL을 제공합니다. 이 값을 사용하면 도메인이 현지 언어로 표시될 수 있습니다. 예를 들어 IDN으로 인코딩된 URL http://www.%E8%8A%B1%E4%BA%95.com은 디코딩되어 http://www.花井鮨.com으로 표시될 수 있습니다. 이 <UD> 태그는 ud 매개변수가 포함된 요청의 검색 결과에만 포함됩니다. 참고: 이 기능은 베타 기능입니다. |
| 예 | <UD>http://www.%E8%8A%B1%E4%BA%95.com/</UD> |
| 상위 태그 | R |
| 콘텐츠 형식 | 텍스트 (IDN 인코딩 URL) |
| UE | |
|---|---|
| 정의 | <UE> 태그는 검색 결과의 URL을 제공합니다. 이 값은 URL에서 쿼리 매개변수로 전달하는 데 적합하도록 URL 이스케이프 처리됩니다. |
| 예 | <UE>http://www.dominos.com/</UE> |
| 하위 태그 | R |
| 콘텐츠 형식 | 텍스트 (URL 이스케이프 처리된 URL) |
| XT | |
|---|---|
| 정의 | <XT> 태그는 M 태그로 지정된 예상 총 결과 수가 실제 총 결과 수를 나타냄을 나타냅니다. 자세한 내용은 이 문서의 자동 필터링 섹션을 참고하세요. |
| 예 | <XT /> |
| 상위 태그 | RES |
| 콘텐츠 형식 | 비어 있음 |
이미지 검색 쿼리의 XML 결과
이 샘플 이미지 요청은 검색어 'monkey'(q=monkey)에 대한 5개의 결과(num=5)를 요청합니다.
http://www.google.com/cse? searchtype=image &num=2 &q=monkey &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
이 요청은 아래의 XML 결과를 생성합니다.
<GSP VER="3.2">
<TM>0.395037</TM>
<Q>monkeys</Q>
<PARAM name="cx" value="011737558837375720776:mbfrjmyam1g" original_value="011737558837375720776:mbfrjmyam1g" url_<escaped_value="011737558837375720776%3Ambfrjmyam1g" js_escaped_value="011737558837375720776:mbfrjmyam1g"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe" url_escaped_value="google-csbe" js_escaped_value="google-csbe"/>
<PARAM name="q" value="monkeys" original_value="monkeys" url_escaped_value="monkeys" js_escaped_value="monkeys"/>
<PARAM name="num" value="2" original_value="2" url_escaped_value="2" js_escaped_value="2"/>
<PARAM name="output" value="xml_no_dtd" original_value="xml_no_dtd" url_escaped_value="xml_no_dtd" js_escaped_value="xml_no_dtd"/>
<PARAM name="adkw" value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" original_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" url_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" js_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A"/>
<PARAM name="hl" value="en" original_value="en" url_escaped_value="en" js_escaped_value="en"/>
<PARAM name="oe" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="ie" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="boostcse" value="0" original_value="0" url_escaped_value="0" js_escaped_value="0"/>
<Context>
<title>domestigeek</title>
</Context>
<ARES/>
<RES SN="1" EN="2">
<M>2500000</M>
<NB>
<NU>/images?q=monkeys&num=2&hl=en&client=google-csbe&cx=011737558837375720776:mbfrjmyam1g&boostcse=0&output=xml_no_dtd
&ie=UTF-8&oe=UTF-8&tbm=isch&ei=786oTsLiJaaFiALKrPChBg&start=2&sa=N
</NU>
</NB>
<RG START="1" SIZE="2"/>
<R N="1" MIME="image/jpeg">
<RU>http://www.flickr.com/photos/fncll/135465558/</RU>
<U>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</U>
<UE>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</UE>
<T>Computer <b>Monkeys</b> | Flickr - Photo Sharing!</T>
<RK>0</RK>
<BYLINEDATE>1146034800</BYLINEDATE>
<S>Computer <b>Monkeys</b> | Flickr</S>
<LANG>en</LANG>
<IMG WH="500" HT="305" IID="ANd9GcQARKLwzi-t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs">
<SZ>88386</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="130" HT="79" URL="http://t0.gstatic.com/images?q=tbn:ANd9GcQARKLwzi-
t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs"/>
</R>
<R N="2" MIME="image/jpeg">
<RU>
http://www.flickr.com/photos/flickerbulb/187044366/
</RU>
<U>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</U>
<UE>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</UE>
<T>
one. ugly. <b>monkey</b>. | Flickr - Photo Sharing!
</T>
<RK>0</RK>
<BYLINEDATE>1152514800</BYLINEDATE>
<S>one. ugly. <b>monkey</b>.</S>
<LANG>en</LANG>
<IMG WH="400" HT="481" IID="ANd9GcQ3Qom0bYbee4fThCQVi96jMEwMU6IvVf2b8K5vERKVw-
EF4tQQnDDKOq0"><SZ>58339</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="107" HT="129" URL="http://t1.gstatic.com/images?q=tbn:ANd9GcQ3Qom0bYbee4fThCQ
Vi96jMEwMU6IvVf2b8K5vERKVw-EF4tQQnDDKOq0"/>
</R>
</RES>
</GSP>이미지 검색: XML 태그
아래 표에는 이미지 검색 쿼리의 XML 응답에 사용되는 추가 XML 태그가 나와 있습니다.
아래 정의의 일부 하위 태그 옆에 특정 기호가 표시될 수 있습니다. 이러한 기호와 기호의 의미는 다음과 같습니다.
* = 하위 태그의 인스턴스가 0개 이상
+ = 하위 태그의 인스턴스가 1개 이상
| RG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 정의 | <RG> 태그는 개별 이미지 검색 결과의 세부정보를 포함합니다. |
|||||||||
| 속성 |
| |||||||||
| 하위 태그 | RES | |||||||||
| RU | |
|---|---|
| 정의 | <RU tag> 태그는 각 이미지 검색 결과의 세부정보를 묶습니다. |
| 하위 태그 | R |