What aggregation keys are, how they're used in the Attribution Reporting API, and how you can translate goals into keys.
As an ad tech company running campaigns in multiple locations for various product categories, you want to help advertisers answer the following questions:
- How many purchases of each product category did each of my campaigns in each geographic region generate?
- How much revenue for each product category did each of my campaigns in each geographic region generate?
While many ad tech companies encourage advertisers to configure a variety of conversion types, focusing on the most important conversions such as purchases is a good way to ensure that summary results are detailed and accurate for these important events.
To do so, you'll need to think of what questions you want to answer before data is collected.
Dimensions, keys, and values
To answer these questions, let's take a look at dimensions, keys, and values.
Dimensions
To understand how your campaigns are generating revenue, as described here, you'll want to track the following dimensions:
- Ad campaign ID: the identifier for the specific campaign.
- Geography ID: the geographic region where the ad was served.
- Product category: the type of product as you've defined it.
While the Campaign ID and the Geography ID dimensions are known when the ad is served (ad-serving time), the Product category will be known from a trigger event, when the user completes a conversion (conversion time).
The dimensions you want to track for this example are as shown in the following image:

What are aggregation keys (buckets)?
The terms aggregation key and bucket refer to the same thing. Aggregation key is used in the browser APIs used to configure reports. The term bucket is used in the aggregatable and summary reports, and in the aggregation service APIs.
An aggregation key (key for short) is a piece of data that represents the values of the dimensions being tracked. Data is later aggregated along each aggregation key.
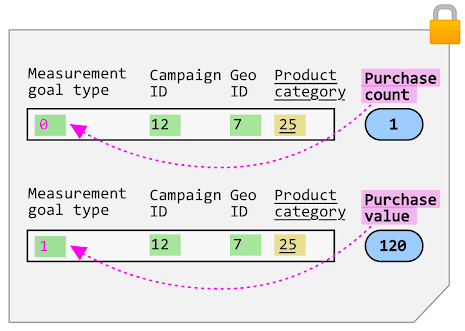
For example, let's assume you're tracking the dimensions Product category, Geography ID, and Campaign ID.
When a user located in Geography ID 7 sees an ad for Campaign ID 12, and later converts by purchasing a product in Product category 25, you may set an aggregation key that looks like the one in the following image:

You'll see later that an aggregation key does not look exactly like this in practice, but for now let's focus on the information contained in the key.
What are aggregatable values?
To answer your questions for the dimensions we've outlined, you want to know:
- The number of purchases (the purchase count). Once aggregated and made available in a summary report, this will be the total purchase count (summary value).
- The revenue for each purchase (the purchase value). Once aggregated and made available in a summary report, this will be the total revenue (summary value).
Each of these—the purchase count for one conversion and the purchase value for one conversion—is an aggregatable value. You can think of aggregatable values as the values of your measurement goals.
| Question | Aggregatable value = Measurement goal |
|---|---|
| How many purchases… | Purchase count |
| How much revenue… | Purchase value |
When a user located in Geography ID 7 sees an ad for Campaign ID 12, and later converts by purchasing a product of Product category 25 for $120 (assuming your currency is USD), you may set an aggregation key and aggregatable values that look like these:

Aggregatable values are summed per key across many users to generate aggregated insights, in the form of summary values in summary reports.
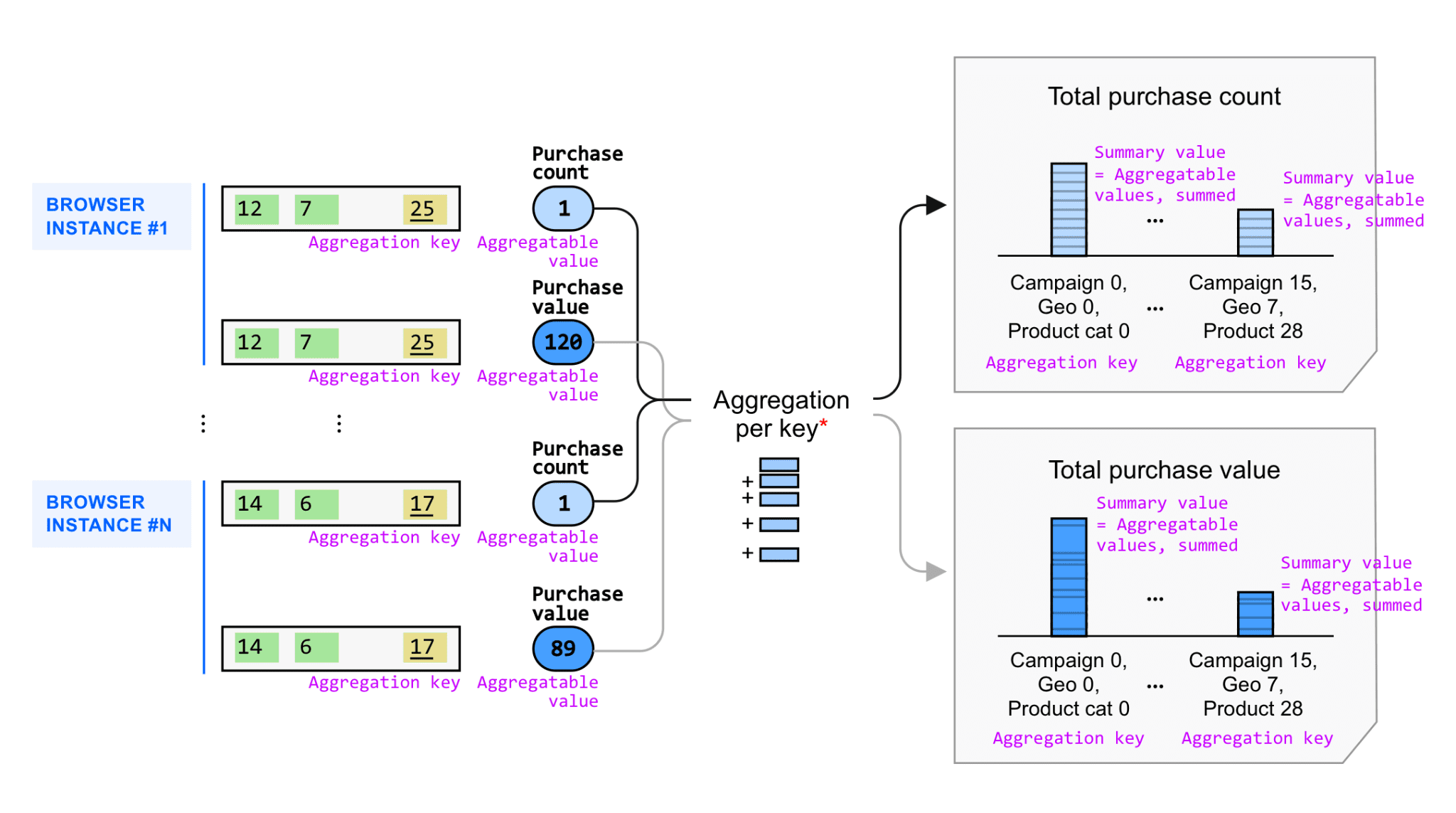
Aggregatable values are summed to generate aggregated insights for your measurement goals.
Note that this diagram omits decryption and represents a simplified example without noise applied. In the next section, we will outline this example with noise.
From keys and values to reports
Now let's discuss how aggregatable keys and values relate to reports.
Aggregatable reports
When a user clicks or views an ad and later converts, you instruct the browser to store an {aggregation key, aggregatable value} pair.
In our example, when a user clicks or views an ad and later converts, you instruct the browser to generate two contributions (one per measurement goal).
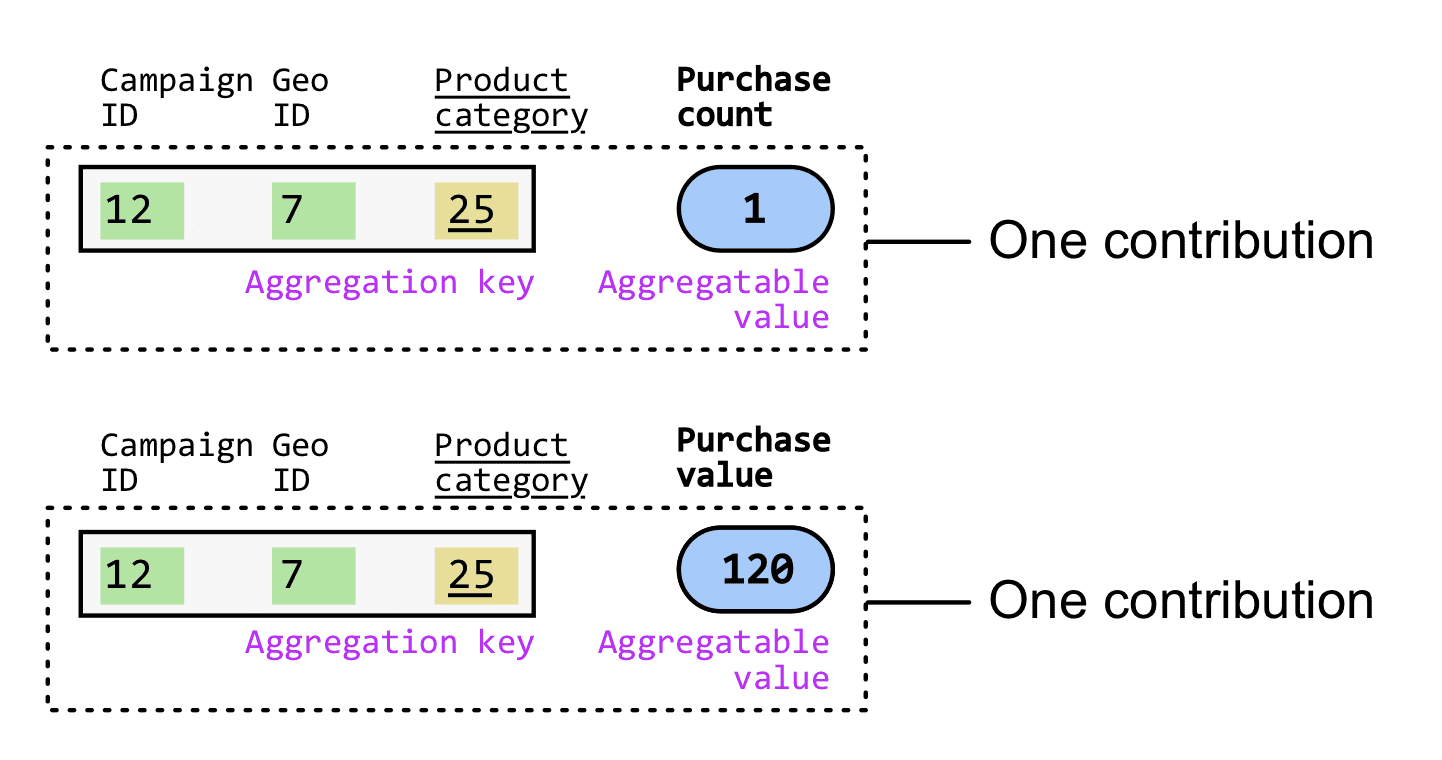
You'll see later that an {aggregation key, aggregatable value} aggregatable report does not look exactly like this—but for now let's focus on the information contained in the report.
When you instruct the browser to generate two contributions, the browser generates an aggregatable report (if it can match the conversion with a previous view or click).
An aggregatable report contains:
- The contribution(s) you've configured.
- Metadata about the click or view event and the conversion event: the site where the conversion occurred, and more. See all the fields in an aggregatable report.
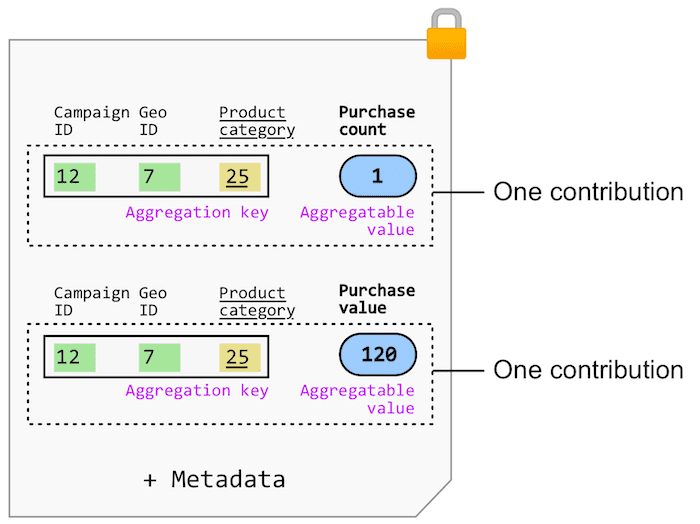
Aggregatable reports are JSON-formatted and include among other things, a payload field that will be used as a data input for the final summary report.
The payload contains a list of contributions, each one being an {aggregation key, aggregatable value} pair:
bucket: the aggregation key, encoded as a bytestring.value: the aggregatable value for that measurement goal, encoded as a bytestring.
Here's an example:
{
"data": [
{
"bucket": "111001001",
"value": "11111010000",
}
],
"operation": "histogram"
}
In practice, aggregatable reports are encoded in a way that will make buckets and values look different than in the previous example (that is, a bucket may look like \u0000\u0000\x80\u0000). Bucket and value are both bytestrings.
Summary reports
Aggregatable reports are aggregated across many browsers and devices (users) as follows:
- An ad tech requests summary reports for a given set of keys, and a given set of aggregatable reports that come from many different browsers (users).
- Aggregatable reports are decrypted by the aggregation service.
- For each key, the aggregatable values from the aggregatable reports are summed.
- Noise is added to the summary value.
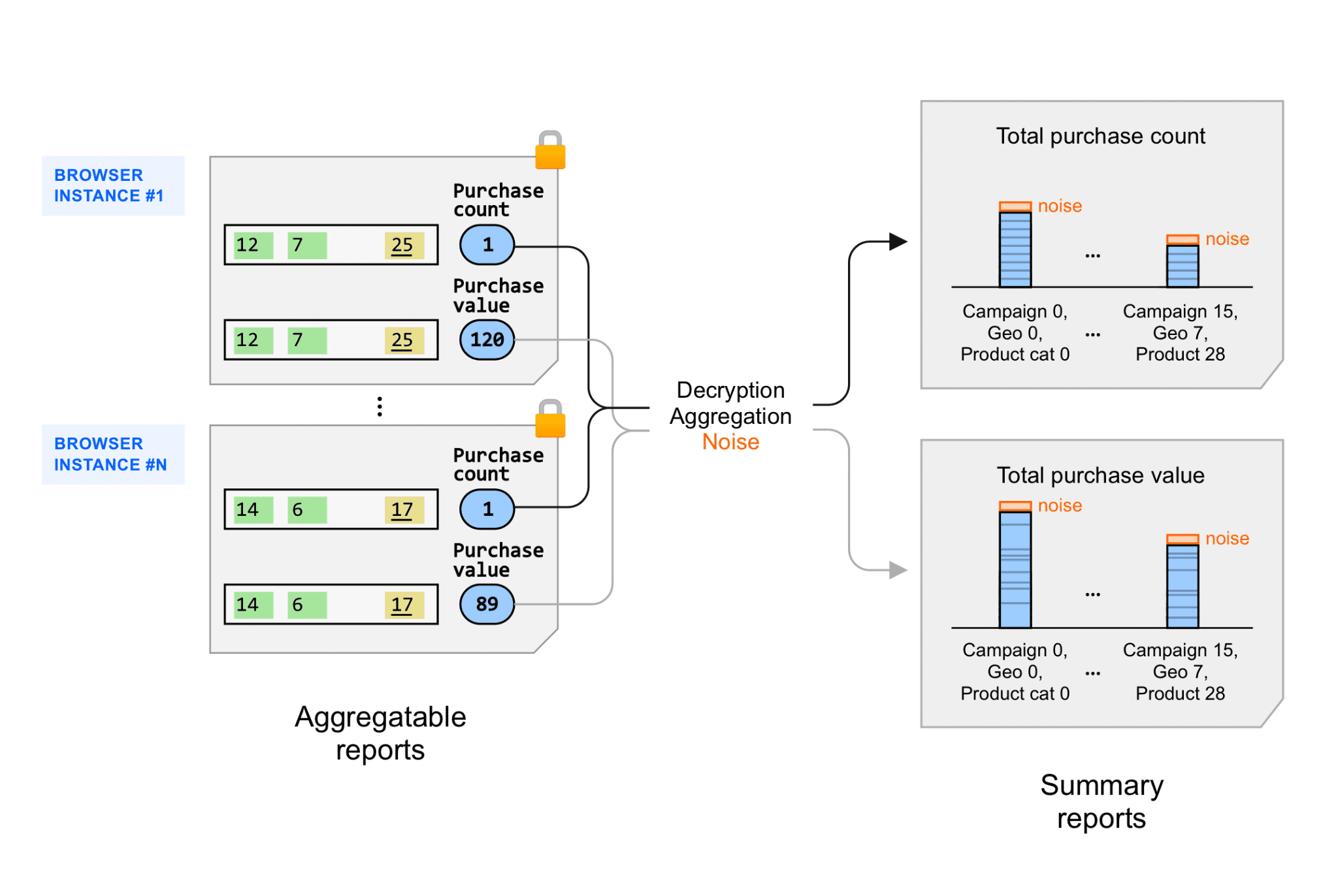
The result is a summary report that contains a set of {aggregation key, summary value} pairs.
A summary report contains a JSON dictionary-style set of key-value pairs. Each pair contains:
bucket: the aggregation key, encoded as a bytestring.value: the summary value in decimal for a given measurement goal, summed up from all available aggregatable reports, with an added level of noise.
Example:
[
{"bucket": "111001001", "value": "2558500"},
{"bucket": "111101001", "value": "3256211"},
{...}
]
In practice, summary reports are encoded in a way that will make buckets and values look different than stated in the example (that is, a bucket may look like \u0000\u0000\x80\u0000). Bucket and value are both bytestrings.
Aggregation keys in practice
Aggregation keys (buckets) are defined by an ad tech company, typically in two steps: when an ad is clicked or viewed, and when a user converts.
Key structure
We'll use the term key structure to designate the set of dimensions encoded into a key.
For example, Campaign ID × GeoID × Product category is a key structure.

Key types
Aggregatable values are summed for a given key across multiple users/browsers. But we've seen that aggregatable values can track different measurement goals, such as a purchase value or a purchase count. You want to ensure that the aggregation service will sum aggregatable values of the same type.
To do so, within each key, encode a piece of data that tells you what the summary value represents—the measurement goal this key is referring to. One way to do that is to create an additional dimension for your key that represents the measurement goal type.
Using our earlier example, this measurement goal type would have two different possible values:
- Purchase count is the first type of measurement goal.
- Purchase value is the second type of measurement goal.
If you had n measurement goals, the measurement goal type would have n different types of values.
You can think of a key's dimensions as a metric. For example, "the number of purchases of a certain product per campaign per geography".
Key size, dimension size
The maximum key size is defined in bits—the number of zeros and ones in binary to create the full key. The API allows for a key length of 128 bits.
This size allows for very granular keys, but more granular keys are more likely to lead to more noisy values. You can read more about noise in Understand noise.
As introduced earlier, dimensions are encoded into the aggregation key. Each dimension has a certain cardinality—that is, the number of distinct values the dimension can take. Depending on its cardinality, each dimension needs to be represented by a certain number of bits. With n bits, it is possible to express 2n distinct options.
For example, a Country dimension may have a cardinality of 200, as there are about 200 countries in the world. How many bits are needed to encode this dimension?
7 bits would only store 27 = 128 distinct options, which is less than the necessary 200.
8 bits would store 28 = 256 distinct options which is more than the necessary 200, so you can use n=8 bits to encode this dimension.
Key encoding
When you set keys in the browser, they should be encoded in hexadecimal. In summary reports, keys will appear in binary (and be named buckets).
Set two key pieces for a full key
Let's assume you use a key to track the following dimensions:
- Campaign ID
- Geography ID
- Product category
While the Campaign ID and the Geography ID dimensions are known when the ad is served (ad-serving time), the product category will be known from a trigger event, when the user completes a conversion (conversion time).
In practice, this means you'll set a key in two steps:
- You'll set one part of the key—Campaign ID × Geography ID—at click or view time.
- You'll set the second part of the key—Product category—at conversion time.
These different parts of the keys are called key pieces.
A key is calculated by taking the OR (v) of its key pieces.

Example:
- Source-side key piece =
0x159 - Trigger-side key piece =
0x400 - Key =
0x159 v 0x400 = 0x559
Aligning key pieces
With two 64-bit key pieces extended to 128 bits using carefully placed 64-bits fillers/offsets (the sixteen zeros), OR-ing key pieces is equivalent to concatenating them, which is easier to reason with and verify:
- Source-side key piece =
0xa7e297e7c8c8d0540000000000000000 - Trigger-side key piece =
0x0000000000000000674fbe308a597271 - Key =
0xa7e297e7c8c8d0540000000000000000 v 0x0000000000000000674fbe308a597271 = 0xa7e297e7c8c8d054674fbe308a597271
Multiple keys per ad click or view
In practice, you may set multiple keys per attribution source event (ad click or view). For example, you may set:
- A key that tracks Geography ID × Campaign ID.
- Another key that tracks Creative Type × Campaign ID.
Take a look at Strategy B for another example.
Encoding dimensions into keys
When requesting summary reports, you need to tell the aggregation service what metrics you want to access, by requesting summary reports for a certain set of aggregation keys.
Summary reports contain raw {key, summary value} pairs, and no additional information about the key. This means that:
- When setting keys as the user views or clicks an ad and later converts, you need to reliably set keys based on the values of the dimensions they represent.
- When defining the keys you want to request summary reports for, you need to reliably generate or access on the fly the same keys as the keys set when the user viewed or clicked an ad and converted, based on the values of the dimensions you want to see aggregated data for.
Encoding dimensions using key structure maps
To encode dimensions into keys, you can create and maintain a key structure map ahead of time, upon defining your keys (before ad-serving time).
A key structure map represents each of your dimensions and their position in the key.
In practice, creating and maintaining key structure maps means you have to implement and maintain decoder logic. If you're looking for a method that doesn't require you to do that, consider using a hash-based approach instead.
Here's an example:
Let's assume that you plan to track both purchases and purchase values for specific campaigns, geographic regions, and products.
The product category, geography ID, and campaign ID need to be dimensions in your keys. Additionally, because you want to track two different measurement goals—purchase count and purchase value—you need to add one dimension within your key that keeps track of the key type. This will allow you to define what the aggregatable value actually represents upon receiving {key, aggregatable value} pairs in summary reports.
With these measurement goals, your key has the following dimensions:
- Product category
- Measurement goal type
- Geography ID
- Campaign ID
Now, looking at each dimension, let's assume for your use case that you need to track the following:
- 29 different products categories.
- 8 different geographic regions: North America, Central America, South America, Europe, Africa, Asia, Caribbean, and Oceania.
- 16 different campaigns.
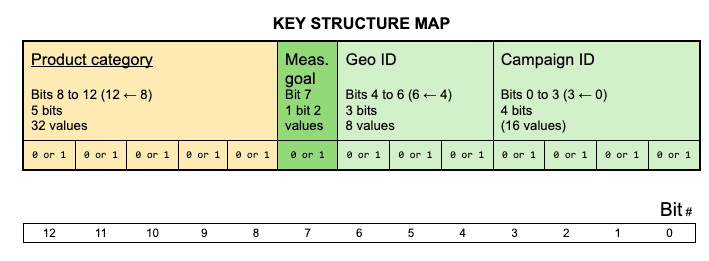
Here's the number of bits you would need to encode each dimension in your key:
- Product category: 5 bits (25 = 32 > 29).
- Measurement goal type: 1 bit. The measurement goal is either purchase count or purchase value, that means two distinct possibilities; therefore, one bit is sufficient to store this.
Geography ID: 3 bits (23 = 8). You would also define a dimension map for the Geography ID in order to know what geographic region each binary value represents. Your dimension map for your Geography ID dimension might look like this:
Binary value in the key Geography 000 North America 001 Central America 010 South America 011 Europe 100 Africa 101 Asia 110 Caribbean 111 Oceania Campaign ID: 4 bits (24 = 16)
Keys following this structure would be 13 bits long (5 + 1 + 3 + 4).
For this example, the key structure map for these keys would look like this:
The order of the dimensions within the key is up to you.
To illustrate how dimensions make up a key structure, we'll be using a binary representation, which is why the Campaign ID (first bits) is the right-most one, and the product category (last bits) is the left-most one.
Within each dimension, the most significant bit—the one that carries the greatest numerical value—is the left-most bit. The least significant bit—the one that carries the smallest numerical value—is the right-most bit.
Let's see how you would use a key structure map to decode a key.
Let's take 0b1100100111100 as an arbitrary example key, and let's assume you have a way to know that this key follows the key structure map in the previous illustration.
According to the key structure map, this key would decode into:
`11001 0 011 1100`
So the key 0b1100100111100 represents the number of purchases of Product category 25, for the Campaign ID 12 launched in Europe.
Encoding dimensions using a hash function
Rather than using a key structure map, you can use a hashing function to dynamically generate keys in a consistent and reliable way.
This works as follows:
- Select a hashing algorithm.
- At ad-serving time, generate a string that includes all the dimensions you want to track, and their values. To generate the source-side key piece,
hash this string and consider adding a 64-bit suffix of zeros to align
it with the trigger-side key piece and make OR easier to reason about.
- Source-side key piece
=<64-bit hex hash("COUNT, campaignID=12, geoID=7"))><64-bit 00000000…> - Note that
COUNTencodes the same thing asmeasurementGoalType=0in the key structure map approach.COUNTis a bit leaner and more explicit.
- Source-side key piece
- At conversion time, generate a string that includes all the dimensions you want to track, and
their values. To generate a trigger-side key piece, hash this string and add a 64-bit prefix of zeros:
- Trigger-side key piece
=
<64-bit 00000000…><64-bit hex hash("productCategory=25")>
- Trigger-side key piece
=
- The browser ORs these key pieces to generate a key.
- 128-bit aggregation key
=<64-bit hex source-side key piece hash><64-bit hex source-side key piece hash>
- 128-bit aggregation key
- Later, when you're ready to request a summary report for this key, generate it on the fly:
- Based on the dimensions you're interested in, generate a source-side and trigger-side key piece as you did earlier.
- Source-side key piece
=<64-bit hex hash("COUNT, campaignID=12, geoID=7"))><64-bit 00000000…> - Trigger-side key piece
=<64-bit 00000000…><64-bit hex hash("productCategory=25")> - trigger-side key piece =
toHex(hash("productCategory=25"))
- Source-side key piece
- Just like the browser, OR these key pieces to generate the same key the browser has generated earlier.
- 128-bit aggregation key
=<64-bit source-side key piece hash><64-bit source-side key piece hash>
- 128-bit aggregation key
- Based on the dimensions you're interested in, generate a source-side and trigger-side key piece as you did earlier.
A few practical tips if you're using this hash-based approach:
- Always use the same ordering of the dimensions. This ensures that your hashes can be reliably regenerated. (
"COUNT, CampaignID=12, GeoID=7"won't generate the same hash as"COUNT, GeoID=7, CampaignID=12"). One straightforward way to achieve this is to sort dimensions alphanumerically. This is what we'll be doing in the example, except for the fact that we'll always makeCOUNTorVALUEthe first item in the dimension—this is a choice for readability, asCOUNTorVALUEencodes information that's slightly different conceptually than all other dimensions. - Keep track of the set of dimensions you're using in keys. You want to avoid generating keys based on a set of dimensions that you've never used.
- Hash collisions are rare if a suitable hash function is used, but checking against previously used hashes (which should be stored to interpret the results from the aggregation service) can avoid introducing new keys that collide with older keys.
See how to use hash-based keys in practice in the one conversion per click or view example.
Aggregatable values in practice
The ad tech company sets aggregatable values when a user converts.
To protect user privacy, contributions from each user has an upper limit. Across all aggregatable values associated with a single source (ad click or view), no value can be higher than a certain contribution limit.
We'll refer to this limit as the CONTRIBUTION_BUDGET. In the explainer, this limit is called the L1 budget, but it's the same as the CONTRIBUTION_BUDGET.
For an in-depth discussion of the contribution budget, refer to Contribution budget for summary reports.
Example: one conversion per click or view
For this example, let's assume that you're looking to answer the following questions:
- Which product categories are the most valuable in each region?
- Which campaign strategies are the most effective in each region?
Let's also assume that for your use case, you need weekly insights.
You also need to track the following:
- 16 different campaigns.
- 8 different geographic regions: North America, Central America, South America, Europe, Africa, Asia, Caribbean, and Oceania.
- 29 different product categories.
What to measure
While many ad tech companies encourage advertisers to configure a variety of conversion types, focusing on the most important conversions such as purchases is a good way to ensure that aggregate results are detailed and accurate for these important conversion events. Indeed, the more metrics you measure, the smaller your contribution budget per metric, and hence the more noisy each value is likely to be. Therefore, you need to carefully select what to measure.
In this example, we'll focus on campaign setups that measure only one conversion per click or view: a purchase.
You'll still measure both the purchase count and the purchase value, and access a variety of important aggregate statistics such as total purchase value and geographic breakdowns. This keeps noise reasonable and ensures a simple scaling approach for your contribution budget.
What about currencies?
Running campaigns in different regions implies that currencies should be taken into account. You could:
- Make currency a dedicated dimension in the aggregation keys.
- Or infer the currency from a campaign ID, and convert all currencies to a reference currencies.
In this example, we'll assume that you can infer the currency from a campaign ID. This allows you to convert any given purchase value from the user's local currency to a reference currency of your choice. You can also perform that conversion on the fly, when the user purchases an item.
With this technique, all aggregatable values are in the same reference currency, and can therefore be summed to generate a total aggregated purchase value—a summary purchase value.
Translate goals into keys
With your measurement goals and metrics, you have a number of options for your key strategy. Let's focus on two of these strategies:
- Strategy A: one granular key structure.
- Strategy B: two coarse key structures.
Strategy A: one deep tree (one granular key structure)
In strategy A, you use one granular key structure, that includes all the dimensions you need:

All your keys use this structure.
You split this key structure into two key types to support two measurement goals.
- Key type 0: measurement goal type = 0, which you decide to define as a purchase count.
- Key type 1: measurement goal type = 1, which you decide to define as a purchase value.
Summary reports look as follows:
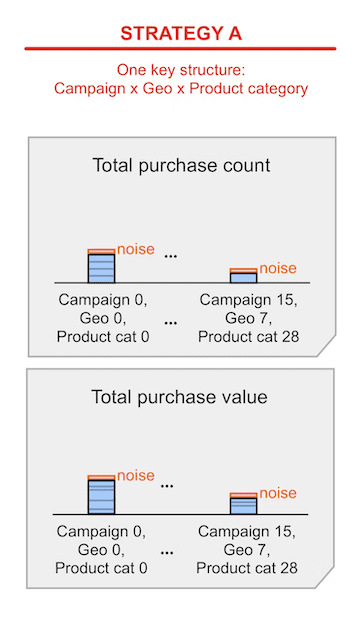
You can think of strategy A as a "one deep tree" strategy:
- Each summary value in summary reports is associated to all of the dimensions you're tracking.
- You can roll up these summary values alongside each of these dimensions, so these rollups can go as deep as the numbers of dimensions you have.
With strategy A, you would answer your questions as follows:
| Question | Answer |
|---|---|
| Which product categories are the most valuable in each region? | Sum the summary purchase counts and values that are in the summary
reports, across all campaigns. This gives you the purchase count and value per Geo ID × Product category. For each region, compare the purchase value and count of different product categories. |
| Which campaign strategies are the most effective in each region? | Sum the summary purchase counts and values that are in the summary
reports, across all product categories. This gives you the purchase count and value per Campaign ID × Geo ID. For each region, compare the purchase value and count for different campaigns. |
With strategy A, you can also directly answer this third question:
"How much revenue for each product did each of my campaigns in each geographic region generate?"
Even though the summary values will be noisy, you can determine when differences in the value measured between each campaign are not due to noise alone. Learn how to accomplish this in Understanding noise.
Strategy B: two shallow trees (two coarse key structures)
In strategy B, you use two coarse key structures, each including a subset of the dimensions you need:
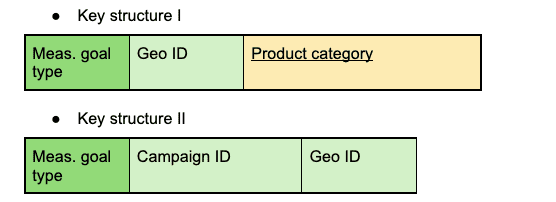
You split each of these key structures into two key types to support two measurement goals.
- Measurement goal type = 0, which you decide to define as a purchase count.
- Measurement goal type = 1, which you decide to define as a purchase value.
You end up with four key types:
- Key type I-0: Key structure I, purchase count.
- Key type I-1: Key structure I, purchase value.
- Key type II-0: Key structure II, purchase count.
- Key type II-1: Key structure II, purchase value.
Summary reports look as follows:
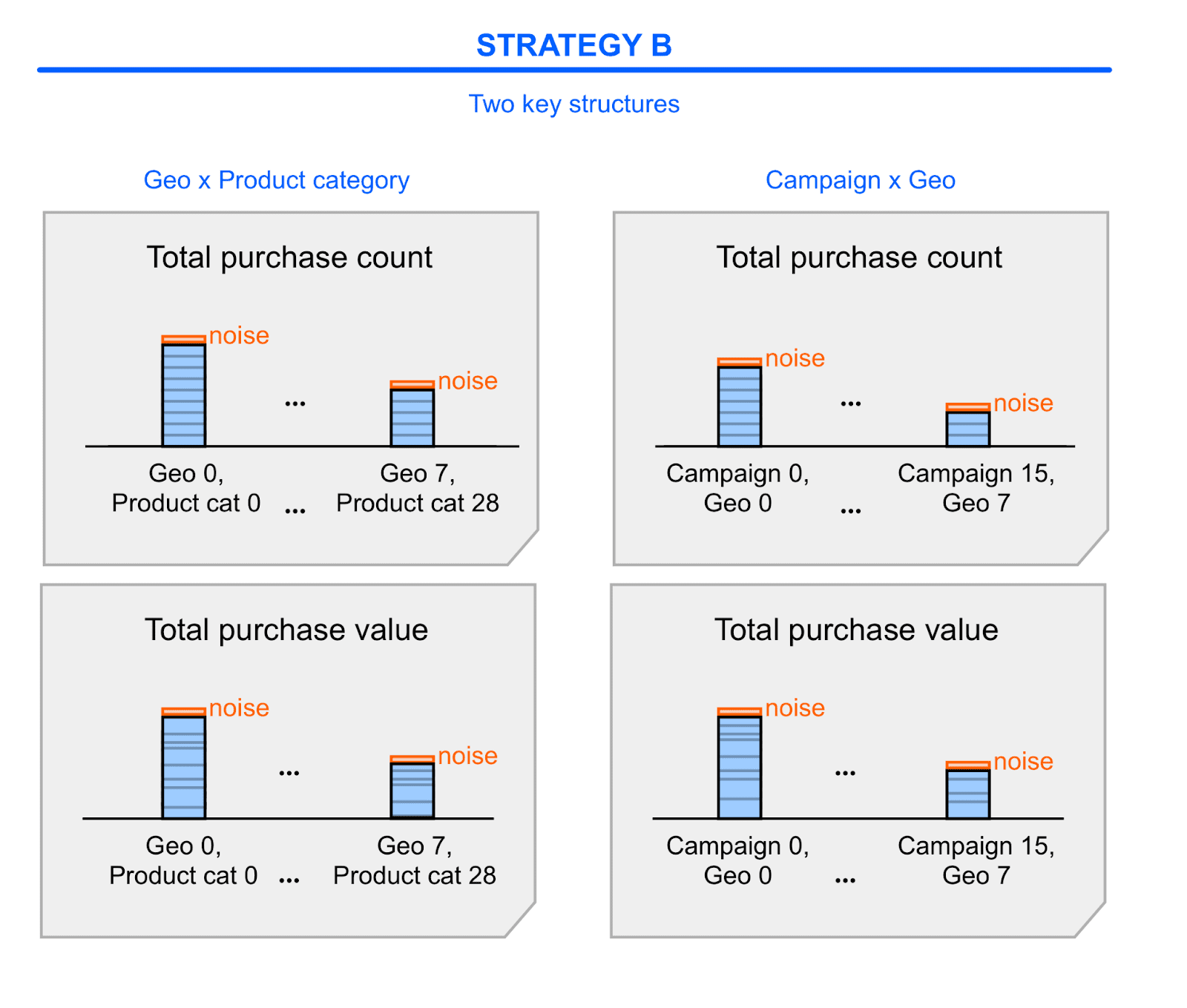
You can think of strategy B as a "two shallow trees" strategy:
- The summary values in summary reports map to one of two small sets of dimensions.
- You can roll up these summary values alongside each of the dimensions in these sets—this means that these rollups aren't as deep as in option A, since there are less dimensions to roll up against.
With strategy B, you would answer your questions as follows:
| Question | Answer |
|---|---|
| Which product categories are the most valuable in each region? | Directly access the summary purchase counts and values that are in the summary reports. |
| Which campaign strategies are the most effective in each region? | Directly access the summary purchase counts and values that are in the summary reports. |
Decision: Strategy A
Strategy A is simpler; all data follows the same key structure, which also means you only have one key structure to maintain.
However, with strategy A, you need to sum the summary values you receive in summary reports to answer some of your questions. Each of these summary values is noisy. By summing up that data, you're also summing the noise.
This isn't the case with strategy B, where summary values exposed in the summary reports already give you the information you need. This means that strategy B will likely lead to a lesser impact from noise than strategy A.
How should you determine which strategy to use? For existing advertisers or campaigns, you might rely on historical data to determine whether the volume of conversions is more suitable for strategy A or strategy B. However, for new advertisers or campaigns, you may decide to:
- Collect a month's worth of data with the granular keys (Strategy A). Because you're extending the duration of data collection, summary values will be higher and noise will be relatively lower.
- Assess with reasonable accuracy the weekly conversion count and purchase value.
In this example, let's assume that the weekly purchase count and purchase value are high enough that strategy A would lead to a noise percentage that you deem acceptable for your use case.
Because strategy A is simpler and leads to a noise impact that doesn't affect your ability to make decisions, you decide to go with strategy A.
Select a hashing algorithm
You decide to adopt a hash-based approach to generate your keys. To do so, you need to select a hashing algorithm to support that approach.
Let's assume that you've selected SHA-256. You could also use a simpler, less secure algorithm, such as MD5.
In the browser: set keys and values
Now that you've decided on a key structure and a hashing algorithm, you're ready to register keys and values when users click or view ads and subsequently convert.
Next is an overview of the headers you'll set to register keys and values in the browser:
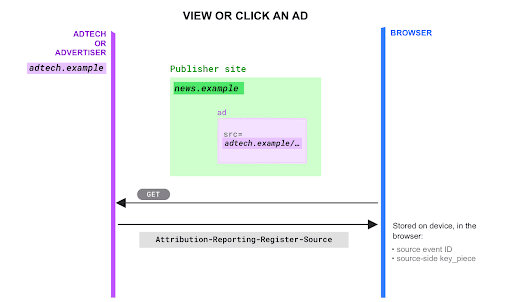
Set source-side key pieces
When a user clicks or views an ad, set the aggregation keys in the
Attribution-Reporting-Register-Aggregatable-Source header.
At this stage, for each key, you can only set the part of the key, or
key piece, that's known at ad-serving time.
Let's generate the key pieces:
| Source-side key piece for the key ID… | String containing the dimension values you want to set | Hash of this string as hex, trimmed to the first 64 bits (64/4 = 16 characters1) | Hex hash with appended zeros to simplify OR-ing. This is the source-side key piece. |
|---|---|---|---|
key_purchaseCount |
COUNT, CampaignID=12, GeoID=7 |
0x3cf867903fbb73ec | 0x3cf867903fbb73ec0000000000000000 |
key_purchaseValue |
VALUE, CampaignID=12, GeoID=7 |
0x245265f432f16e73 | 0x245265f432f16e730000000000000000 |
Let's now set the key pieces:
// Upon receiving the request from the publisher site
res.set(
"Attribution-Reporting-Register-Aggregatable-Source",
JSON.stringify([
{
"id": "key_purchaseCount",
"key_piece": "0x3cf867903fbb73ec0000000000000000"
},
{
"id": "key_purchaseValue",
"key_piece": "0x245265f432f16e730000000000000000"
}
])
);
Note that key IDs will not appear in the final reports. They're only used when setting keys in the browser, so that source-side and trigger-side key pieces can be mapped with each other and combined into a full key.
Optional: event-level reports
If you need to use event-level reports alongside aggregatable reports ensure that for a given source, the event-level data (source event ID and trigger data) and the aggregation key can be matched.
You might use both reports if, for example, you plan to use event-level reports to run models on which types of ads tend to lead to the greatest number of purchases.
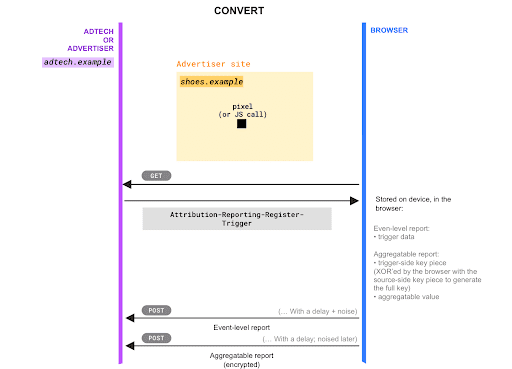
A user converts
When a user converts, a pixel request is typically sent to the ad tech server. Upon receiving this request:
- Set the conversion-side (trigger-side) key pieces to complete the key.
You'll set these key pieces via the header
Attribution-Reporting-Register-Aggregatable-Trigger-Data. - Set the aggregatable value for that conversion, via the header
Attribution-Reporting-Register-Aggregatable-Values.
Set trigger-side key pieces to complete the key
Let's generate the key pieces:
| Trigger-side key piece for the key ID… | String containing the dimension values you want to set | Hash of this string as hex, trimmed to the first 64 bits (64/4 = 16 characters1) | Hex hash with appended zeros to simplify OR-ing. This is the source-side key piece. |
|---|---|---|---|
key_purchaseCount |
ProductCategory=25 |
0x1c7ce88c4904bbe2 | 0x0000000000000000f9e491fe37e55a0c |
key_purchaseValue |
(same) | (same) | (same) |
Let's now set the key pieces:
// Upon receiving the pixel request from the advertiser site
res.set(
"Attribution-Reporting-Register-Aggregatable-Trigger-Data",
JSON.stringify([
// Each dictionary independently adds pieces to multiple source keys
{
"key_piece": "0x0000000000000000f9e491fe37e55a0c",
"source_keys": ["key_purchaseCount", "key_purchaseValue"]
},
])
);
Note how you're adding the same key piece to several keys, by listing several
key IDs in source_keys—the key piece will be added to both keys.
Set aggregatable values
Before you set the aggregatable values, you need to scale them up in order to reduce noise.
Let's assume one purchase was made for product type 25 for $52.
You won't set these directly as aggregatable values:
key_purchaseCount: 1 conversionkey_purchaseValue: $52
Instead, before you register these aggregatable values, you need to scale them in order to minimize noise.
You have two goals to spend your contribution budget against, so you might decide to split the contribution budget in two.
In this case, each goal is allocated a maximum of CONTRIBUTION_BUDGET/2
(=65,536/2=32,768).
Let's assume the maximum purchase value for a single user, based on purchase history across all users of the site, is $1,500. There may be outliers, for example very few users who spent over that sum, but you may decide to ignore these outliers.
Your scaling factor for the purchase value should be:
((CONTRIBUTION_BUDGET/2) / 1,500) = 32,768/1,500 = 21.8 ≈ 22
Your scaling factor for purchase count is 32,768/1 = 32,768, since you decided to track at most one purchase per ad click or view (source event).
You can now set these values:
key_purchaseCount: 1 × 32,768 = 32,768key_purchaseValue: 52 × 22 = 1,144
In practice, you would set them as follows, using the dedicated header
Attribution-Reporting-Register-Aggregatable-Values:
// Instruct the browser to schedule-send a report
res.set(
"Attribution-Reporting-Register-Aggregatable-Values",
JSON.stringify({
"key_purchaseCount": 32768,
"key_purchaseValue": 1144,
})
);
The aggregatable report is generated
The browser matches the conversion to a previous view or click and generates an aggregatable report, which includes the encrypted payload next to report metadata.
The following is an example of the data that could be found within the payload of the aggregatable report, if it was readable in cleartext:
[
{
key: 0x3cf867903fbb73ecf9e491fe37e55a0c, // = source-side key piece OR conversion-side key piece for the key key_purchaseCount
value: 32768 // the scaled value for 1 conversion, in the context of [CONTRIBUTION_BUDGET/2]
},
{
key: 0x245265f432f16e73f9e491fe37e55a0c, // source-side key piece OR conversion-side key piece for the key key_purchaseValue
value: 1144 // the scaled value for $52, in the context of [CONTRIBUTION_BUDGET/2]
},
]
Here, you can see two separate contributions within one single aggregatable report.
Request a summary report
- Batch aggregatable reports. Follow the advice offered in Batching.
- Generate the keys you want to see data for. For example, to see summary
data for
COUNT(total number of purchases) andVALUE(total purchase value) for the Campaign ID 12 × Geography ID 7 × Product category 25:- Generate the source-side key piece, as you did when setting it in the browser.
- Generate the trigger-side key piece, as you did when setting it in the browser.
| Metric you want to request1 | Source-side key piece | Trigger-side key piece | Key to request to the aggregation service2 |
|---|---|---|---|
Total purchase count (COUNT) |
0x3cf867903fbb73ec 0000000000000000 |
0x00000000000000 00f9e491fe37e55a0c |
0x3cf867903fbb73 ecf9e491fe37e55a0c |
Total purchase value (VALUE) |
0x245265f432f16e73 0000000000000000 |
0x0000000000000000 f9e491fe37e55a0c |
0x245265f432f16e73 f9e491fe37e55a0c |
- Request summary data to the aggregation service for these keys.
Handle the summary report
Ultimately, you receive a summary report that may look like this:
[
{"bucket": "00111100111110000110011110010000001111111011101101110011111011001111100111100100100100011111111000110111111001010101101000001100",
"value": "2558500"},
{"bucket": "00100100010100100110010111110100001100101111000101101110011100111111100111100100100100011111111000110111111001010101101000001100",
"value": "687060"},
…
]
The first bucket is the COUNT key in binary. The second bucket is the VALUE key
in binary.
Note that while the keys are heterogeneous (COUNT versus VALUE), they're contained
in the same report.
Scale down the values
- 2,558,500 refers to the number of purchases for this key, scaled up by your previously calculated scaling factor. The scaling factor for the purchase count was 32,768. Divide 2,558,500 by the goal's contribution budget: 2,558,500/32,768 = 156.15 purchases.
- 687,060 → 687,060/22 = $31,230 total purchase value.
As a result, the summary reports give you the following insights:
- Within the reporting time period, campaign #12
run in Europe drove about 156 purchases (± noise)
for the product category #25
```
```text
- Within the reporting time period, campaign #12
run in Europe drove $31,230 of purchases (± noise)
for the product category #25.