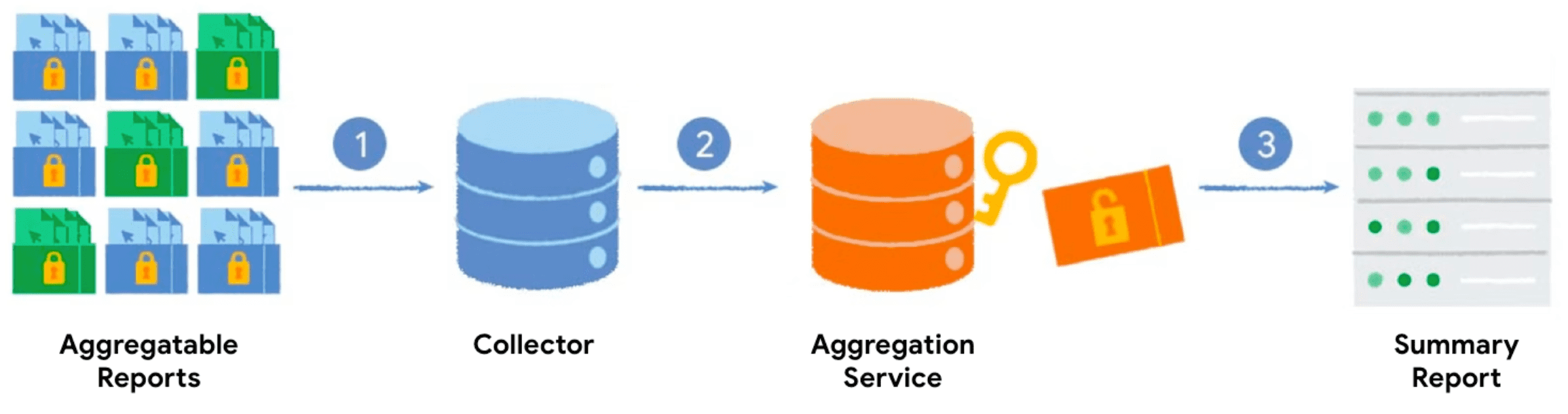
Private Aggregation
Web'in ihtiyaç duyduğu kritik özellikleri sağlamak için Private Aggregation API, siteler arası verileri gizliliği koruyacak şekilde toplayıp raporlamak üzere tasarlanmıştır. Gizli toplama özelliğiyle, Korunan Kitle'deki verileri ve Paylaşılan Depolama'daki siteler arası verileri kullanarak toplu veri raporları oluşturun.
Paylaşılan depolama alanı kullanım alanları

Tekil erişimi ölçme
Kullanıcıların içeriğinizi ilk kez gördüklerine dair veri kopyası olmadan özet bir rapor oluşturmak için özel toplama özelliğini kullanın.
Kullanıcı demografilerini ölçme
Kullanılabilir kullanıcı demografisi verilerini kaydetmek için Ortak Depolama Alanı'nı kullanın.
K+ sıklığını ölçme
Bir içeriği en az K kez görüntüleyen benzersiz kullanıcılarla ilgili raporlar oluşturmak için Paylaşılan Depolama'yı kullanın.
Etkileşimde bulunun ve geri bildirim paylaşın
Geri bildiriminiz, Gizli Toplama'nın iyileştirilmesi açısından çok önemlidir. Analizlerinizi paylaşarak ilgi alanına dayalı reklamcılık için gizliliği gözetme yaklaşımının geliştirilmesine katkıda bulunursunuz.
Bize ulaşın
Geliştirici desteği
Chrome'da şu anda kullanıma sunulan uygulamayla ilgili sorular sormak için yeni bir sorun oluşturun.
GitHub
Açıklamayı okuyun ve Topics API'nin tasarımı hakkında soru sorun ve tartışmayı takip edin.
Duyurular
Gizli toplama hakkında en son güncellemeleri almak için Shared Storage API grubuna ve Protected Audience API grubuna katılın.