שירות הצבירה יוצר דוחות סיכום של נתוני המרות מפורטים ומדידות של פוטנציאל החשיפה מדוחות גולמיים שניתן לצבור. בתור ספקי טכנולוגיות פרסום, אתם יכולים להשתמש ב-Attribution Reporting API וב-Private Aggregation API, שתי נקודות הכניסה העיקריות לנתונים מצטברים בצד הלקוח, כדי להעביר דוחות לשירות הצבירה ולקבל דוח סיכום בתגובה.
הדף הזה מיועד למומחים בתחום טכנולוגיית הפרסום. הוא מכיל מידע על:
- סטטוס ההטמעה
- מושגים ומונחים מרכזיים
- תרחישים לדוגמה לשימוש ב-Aggregation
- תהליך מקצה לקצה
- צבירה של דוחות שניתן לצבור
- רכיבי Cloud
סטטוס ההטמעה
- שירות הצבירה זמין עכשיו לכלל המשתמשים.
- אפשר להשתמש בשירות הצבירה עם Attribution Reporting API ו-Private Aggregation API ל-Protected Audience API ול-Shared Storage API.
זמינות
| הצעה | סטטוס |
|---|---|
| שירות תקציב לפרטיות בעננים שונים
הסבר |
זמין |
| תמיכה בשירות צבירה ל-Amazon Web Services (AWS) ב-Attribution Reporting API וב-Private Aggregation API
הסבר |
זמין |
| תמיכה בשירות צבירה ב-Google Cloud ב-Attribution Reporting API וב-Private Aggregation API הסבר |
זמין |
| הרשמה של אתרים ל-Aggregation Service וצבירה ממקורות מרובים. ההרשמה של האתר כוללת מיפוי של האתר לחשבונות בענן (AWS או GCP). כדי לצבור נתונים ממקורות מרובים, הם צריכים להיות מאותו אתר.
שאלות נפוצות ב-GitHub מסמכי תיעוד של Site aggregation API |
זמין |
| הערך של epsilon בשירות הצבירה יישמר כטווח של עד 64, כדי לאפשר ניסויים ומשוב על פרמטרים שונים.
שליחת משוב על ARA epsilon שליחת משוב על 'הוספת רכיב נוסף לאתר' |
זמינים. נודיע מראש לסביבה העסקית לפני שערכים של טווח האפסילון יעודכנו. |
| סינון גמיש יותר של תרומות לשאילתות של Aggregation Service
הסבר |
זמין |
| תהליך לשחזור התקציב לאחר אסונות (שגיאות, הגדרות שגויות וכו')
הסבר |
זמין מנגנון לבדיקה של אחוז המזהים המשותפים ש-AdTech משחזרת באמצעות שחזור תקציב, ולהשעיית שחזור עתידי של נתונים במקרים של שחזור מוגזם שתוכנן במחצית הראשונה של שנת 2025 |
| Accenture פועלת כאחד מהרכזים ב-AWS
בלוג למפתחים |
זמין |
| צד עצמאי שפועל כאחד מהרכזים ב-Google Cloud
בלוג למפתחים |
זמין |
| תמיכה ב-Aggregation Service בדוחות ניפוי באגים מצטברים ב-Attribution Reporting API
הסבר |
זמין |
מונחים ומושגים מרכזיים
אם אתם שוקלים להשתמש בשירות הצבירה בתהליך העבודה שלכם, המונחים והמושגים הבאים יכולים לעזור לכם להבין מה תהליך הצבירה החדש יכול לספק לצוות שלכם.
מילון מונחים
- דוחות שניתן לצבור
-
דוחות שאפשר לצבור הם דוחות מוצפנים שנשלחים ממכשירים של משתמשים ספציפיים. הדוחות האלה מכילים נתונים על המרות ועל התנהגות משתמשים באתרים שונים. המפרסם או חברת טכנולוגיית הפרסום מגדירים את ההמרות (שנקראות לפעמים אירועי הפעלה של שיוך) והמדדים המשויכים. כל דוח מוצפן כדי למנוע מגורמים שונים לגשת לנתונים הבסיסיים.
- דיווח על דוחות עם נתונים מצטברים
-
ספר חשבון מבוזבז שנמצא בשני התאמים, ומעקב אחרי תקציב הפרטיות שהוקצה ואכיפת הכלל'אין כפילויות'. זהו המנגנון לשמירה על הפרטיות, שנמצא ומופעל בתוך מנהלים, ומבטיח שאף דוח לא יעבור דרך שירות הצבירה מעבר לתקציב הפרטיות שהוקצה.
מידע נוסף על הקשר בין שיטות ארגון קבוצות לבין דוחות שניתן לצבור
- תקציב דיווח מצטבר לצורכי חשבונאות
-
הפניות לתקציב שמבטיחות שלא יתבצע עיבוד של דוחות ספציפיים יותר מפעם אחת.
- Aggregation Service
-
שירות שמופעל על ידי טכנולוגיית פרסום, שמטפל בדוחות שניתן לצבור כדי ליצור דוח סיכום.
מידע נוסף על הרקע של שירות הצבירה זמין במאמר ההסבר וברשימת התנאים המלאה.
- הצהרה
-
מנגנון לאימות הזהות של תוכנה, בדרך כלל באמצעות חתימה קריפטוגרפית או גיבוב קריפטוגרפית. בהצעה לשירות המצטבר, האימות מתבצע על ידי התאמה של הקוד שפועל בשירות המצטבר שמופעל על ידי חברת טכנולוגיית הפרסום לקוד בקוד המקור הפתוח.
- תרומה עם התחייבות לשימוש
- רכז/ת
-
ישויות שאחראיות לניהול מפתחות ולניהול חשבונות של דוחות שניתן לצבור. רכז שומר רשימה של גיבובים של הגדרות שירות שאושרו, ומגדיר את הגישה למפתחות הפענוח.
- רעש והתאמה לעומס
-
רעש סטטיסטי שנוסף לדוחות הסיכום במהלך תהליך הצבירה, כדי לשמור על הפרטיות ולוודא שהדוחות הסופיים כוללים נתוני מדידה אנונימיים.
מידע נוסף על מנגנון רעשי תוספת, שמבוסס על התפלגות Laplace
- מקור הדיווח
-
הישות שמקבלת דוחות שניתן לצבור – כלומר, אתם או חברת טכנולוגיית הפרסום שהפעילה את Attribution Reporting API. דוחות שניתן לצבור נשלחים ממכשירי המשתמשים לכתובת URL ידועה שמשויכת למקור הדיווח. מקור הדיווח מוגדר במהלך ההרשמה.
- מזהה משותף
-
ערך מחושב שמורכב מ-
shared_info,reporting_origin,destination_site(ל-Attribution Reporting API בלבד),source_registration-time(ל-Attribution Reporting API בלבד),scheduled_report_timeוגרסת ה-API.לדוחות שחולקים את אותם מאפיינים בשדה
shared_infoצריך להיות אותו מזהה משותף. למזהים משותפים יש תפקיד חשוב בדיווח על נתונים מצטברים. - דוח סיכום
-
סוג דוח של Attribution Reporting API ו-Private Aggregation API. דוח סיכום כולל נתוני משתמשים מצטברים, ויכול להכיל נתוני המרות מפורטים עם רעש נוסף. דוחות הסיכום מורכבים מדוחות צבירה. הם מאפשרים גמישות רבה יותר ומספקים מודל נתונים עשיר יותר מאשר דיווח ברמת האירוע, במיוחד בתרחישי שימוש מסוימים כמו ערכי המרות.
- סביבת מחשוב אמינה (TEE)
-
תצורה מאובטחת של חומרה ותוכנה במחשב, שמאפשרת לצדדים חיצוניים לאמת את הגרסאות המדויקות של התוכנות שפועלות במכונה בלי חשש לחשיפת המידע. סביבות TEE מאפשרות לצדדים חיצוניים לוודא שהתוכנה עושה בדיוק את מה שמפתח התוכנה טוען שהיא עושה – לא יותר ולא פחות.
למידע נוסף על סביבות TEE שמשמשות להצעות של 'ארגז החול לפרטיות', אפשר לקרוא את הסבר על שירותי Protected Audience API ואת הסבר על שירות האגרגציה.
תרחישים לדוגמה לצבירה
כדאי לעיין בתהליכים הבאים למפתחים למדידת מודעות ובספריות הלקוח המתאימות למדידת ביצועים.
| תרחיש לדוגמה | נקודת כניסה | תיאור |
|---|---|---|
| אופטימיזציה של הבידינג | Attribution Reporting API (Chrome ו-Android) | שימוש בדוחות מצטברים כדי להטמיע אותות המרה לצורכי אופטימיזציה של הבידינג. |
| מדידה בפלטפורמות שונות | Attribution Reporting API (Chrome ו-Android) | בעזרת יכולות המדידה באתרים ובאפליקציות תוכלו לקבל תמונה ברורה יותר של הביצועים ב-Chrome וב-Android. |
| דיווח על המרות | Attribution Reporting API (Chrome ו-Android) | ליצור דוחות המרות מצטברים שמותאמים לצורכי הקמפיינים של הלקוחות (כולל דוחות על המרות מסוג 'המרות מסוג 'קליק להמרה'' ודוחות על המרות מסוג 'קליק להצגת מודעה'). |
| מדידת פוטנציאל החשיפה של הקמפיין | Shared Storage API ו-Private Aggregation API (ב-Chrome) | שימוש במשתני צפיות במודעות באתרים שונים כדי למדוד את פוטנציאל החשיפה של הקמפיין. |
| דיווח על מאפיינים דמוגרפיים | Shared Storage API ו-Private Aggregation API (ב-Chrome) | שימוש בנתונים על צפיות במודעות באתרים שונים ובמידע דמוגרפי כדי למדוד את פוטנציאל החשיפה לפי מאפיינים דמוגרפיים. |
| ניתוח נתיבי המרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | אחסון משתני המרות וצפיות במודעות באתרים שונים כדי לבצע ניתוח מצטבר של נתיבי ההמרות. |
| התחזקות המותג ועלייה בהמרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | דיווח על קבוצות ניסוי/בקרה ועל נתוני סקרים כדי למדוד את התחזקות המותג ואת העלייה המצטברת בנפח המכירות. |
| ניפוי באגים במכרזים | Protected Audience API ו-Private Aggregation API (ב-Chrome) | שימוש בדוחות צבירה לניפוי באגים. |
| חלוקת הצעות המחיר | Protected Audience API ו-Private Aggregation API (ב-Chrome) | שימוש בדוחות מצטברים כדי לתעד את התפלגות ערכי הצעות המחיר במכרזים. |
תהליך מקצה לקצה
בתרשים הבא מוצג שירות האגרגציה בפעולה. נתמקד בתהליך מקצה לקצה, מרגע קבלת הדוחות מהאתרים ומהמכשירים הניידים ועד ליצירת דוח הסיכום בשירות הצבירה.
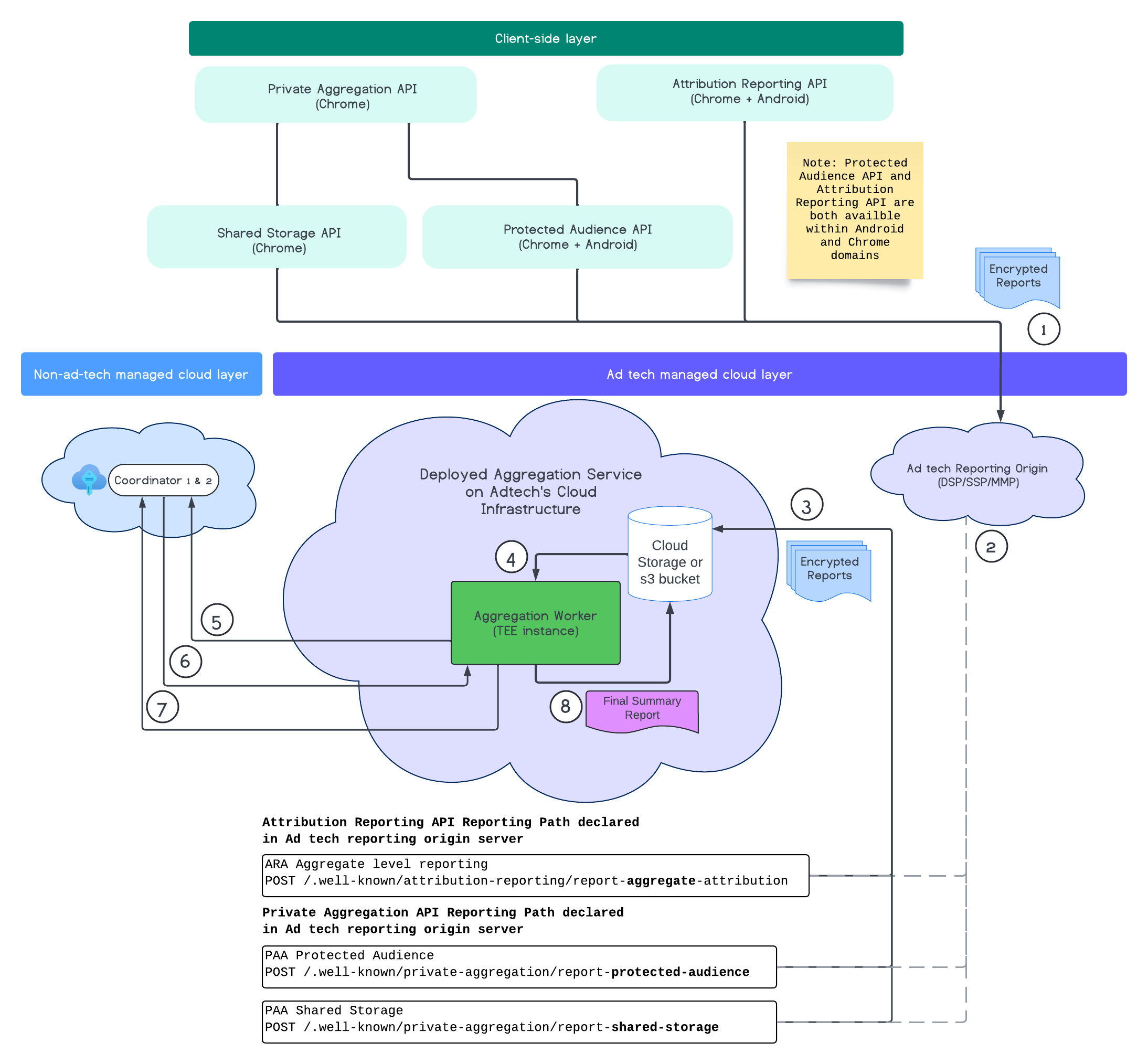
- אחזור המפתח הציבורי ליצירת דוחות מוצפנים.
- דוחות מוצפנים שניתן לצבור אותם נשלחים לשרתים של טכנולוגיות הפרסום כדי שנוכל לאסוף אותם, לשנות אותם ולקבץ אותם בקבוצות.
- שרת טכנולוגיית הפרסום אוסף דוחות (בפורמט avro) ושולח אותם לשירות הצבירה. (חובה להשלים את השלב הזה).
- Aggregation Worker מאחזר את הדוחות המצטברים כדי לפענח אותם.
- Aggregation Worker מאחזר מפתחות פענוח מ-Coordinator.
- Aggregation Worker מפענח את הדוחות לצורך צבירה והוספת רעש.
- שירות החשבונאות של דוחות שניתנים לצבירה בודק אם יש מספיק תקציב פרטיות כדי ליצור דוח סיכום של הדוחות הנתונים שניתנים לצבירה.
- שולחים דוח סיכום סופי.
בתרשים מוצגות היחסים ברמה גבוהה שיש לשירות הצבירה עם ממשקי ה-API העיקריים למדידת ביצועי לקוחות: Attribution Reporting API, Private Aggregation API ו-Coordinators.
התהליך מתחיל בממשקי API למדידת ביצועים, כמו Attribution Reporting API או Private Aggregation API, שמפיקים דוחות מכמה מכונות דפדפן. Chrome מקבל את המפתח הציבורי משירות אירוח המפתחות במרכז התיאום כדי להצפין את הדוחות לפני שהוא שולח אותם למקור הדיווח של חברת טכנולוגיית הפרסום. המפתחות הציבוריים עוברים רוטציה כל שבעה ימים.
צריך להגדיר את המקור של דוחות טכנולוגיית הפרסום כך שיאסוף את הדוחות הנכנסים וימיר אותם לפורמט avro, וישלח אותם לשירות הצבירה כפי שמתואר בקטע שיטות ארגון נתונים בקבוצות.
כשהאצווה מוכנה, שולחים בקשה באצווה לשירות הצבירה. שירות הצבירה מאחזר מפתחות פענוח משירות אירוח המפתחות, מפענח את הדוחות ומאגד אותם עם רעשי רקע כדי ליצור דוח סיכום. חשוב לזכור שהאפשרות הזו תלויה בכך שיש מספיק תקציב פרטיות כדי ליצור אותם.
אתם מארחים את נקודת הקצה המקורית של דיווח על טכנולוגיות הפרסום, שבה נאספים הדוחות, ושירות הצבירה נפרס בענן של טכנולוגיות הפרסום.
קיבוץ דוחות שניתן לצבור
תהליך הדיווח לא יושלם ללא עזרה משרת המקור הייעודי לדיווח. זהו המקור שציינתם בתהליך ההרשמה. מקור הדיווח אחראי על איסוף הדוחות שהוא מקבל, על טרנספורמציה שלהם ועל קיבוץ שלהם, ועל הכנתם לשליחה לשירות הצבירה ב-Google Cloud או ב-Amazon Web Services. מידע נוסף על הכנת דוחות שניתן לצבור
עכשיו, אחרי שהסברנו את הקונספט הכללי, נוכל להסתכל לעומק על הרכיבים שנפרסים בשירות הצבירה.
רכיבי Cloud
שירות האגרגציה מורכב מכמה רכיבים של שירותי ענן. משתמשים בסקריפטים של Terraform שסופקו כדי להקצות ולהגדיר את כל הרכיבים הנדרשים של שירותי הענן.
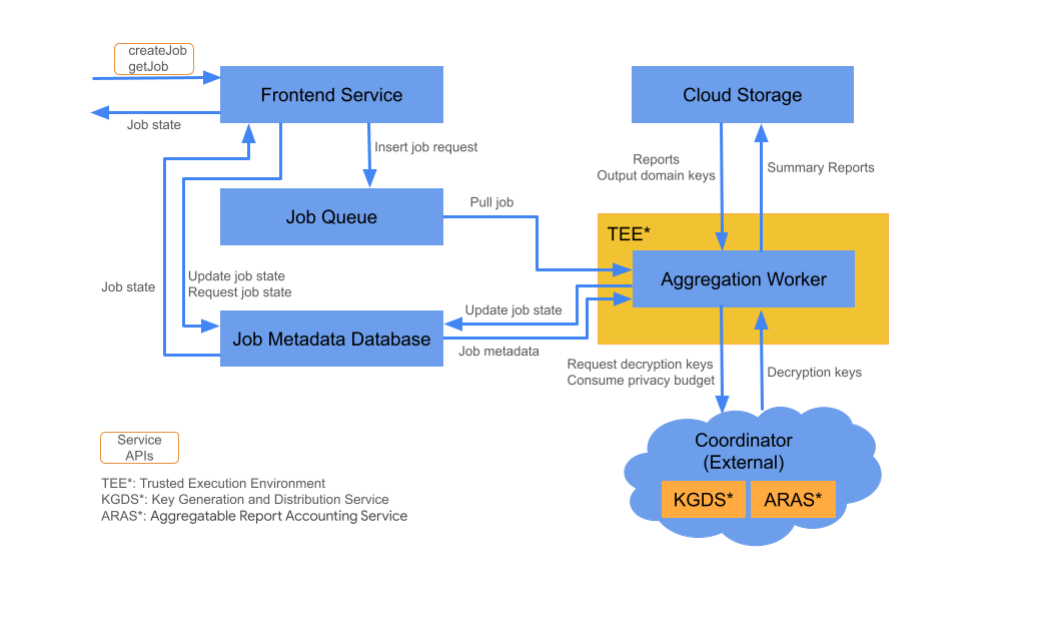
שירות קצה קדמי
שירות מנוהל בענן: Cloud Function (Google Cloud) או API Gateway (Amazon Web Services)
שירות הקצה הוא שער ללא שרת, שהוא נקודת הכניסה הראשית לקריאות ל-Aggregation API ליצירת משימות ולאחזור סטטוס של משימות. הוא אחראי לקבלת בקשות ממשתמשי שירות האגרגציה, לאימות הפרמטרים של הקלט ולהפעלת תהליך תזמון משימות האגרגציה.
לשירות הקצה יש שני ממשקי API זמינים:
| נקודת קצה | תיאור |
|---|---|
createJob |
ה-API הזה מפעיל משימה של Aggregation Service. כדי להפעיל את המשימה, נדרשים פרטים כמו מזהה המשימה, פרטי האחסון של הקלט, פרטי האחסון של הפלט, מקור הדיווח ועוד. |
getJob |
ה-API הזה מחזיר את הסטטוס של המשימה עם מזהה המשימה שצוין. הוא מספק מידע על סטטוס המשימה, כמו 'נשלחה', 'בטיפול' או 'הושלמה'. אם המשימה הסתיימה, היא גם מחזירה את תוצאת המשימה, כולל הודעות שגיאה שנתקלו בהן במהלך ביצוע המשימה. |
מאמרי העזרה של Aggregation Service API
Job Queue
שירות מנוהל בענן: Pub/Sub (Google Cloud) או Amazon SQS (Amazon Web Services)
Job Queue הוא תור הודעות שמכיל בקשות עבודה לשירות הצבירה. השירות לקצה העורפי מכניס את בקשות המשימות לתור, ולאחר מכן העובדים של Aggregation צורכים אותן ומעבדים אותן.
אחסון בענן
שירות מנוהל בענן: Google Cloud Storage (Google Cloud) או Amazon S3 (Amazon Web Services)
קובצי הקלט והפלט שבהם משתמש שירות האגרגציה, כמו קובצי דוחות מוצפנים ודוחות סיכום פלט, נשמרים באחסון בענן.
מסד נתונים של מטא-נתונים של משימות
שירות מנוהל בענן: Spanner (Google Cloud) או DynamoDB (Amazon Web Services)
מסד הנתונים של מטא-נתונים של משימות משמש לאחסון ולמעקב אחר הסטטוס של משימות צבירת נתונים. הוא מתעד מטא-נתונים כמו זמן היצירה, זמן הבקשה, זמן העדכון ומצבים כמו 'נשלחה', 'בטיפול' או 'הושלמה'. Aggregation Workers מעדכנים את מסד הנתונים של המטא-נתונים של המשימות במהלך ההתקדמות שלהן.
Aggregation Worker
שירות מנוהל בענן: Compute Engine עם Confidential space (Google Cloud) או Amazon Web Services EC2 עם Nitro Enclave (Amazon Web Services)
עובד צבירה מעבד בקשות של משימות בתור המשימות ומפענח את הקלט המוצפן באמצעות מפתחות שהוא מאחזר משירות היצירה וההפצה של מפתחות (KGDS) ברכזים. כדי לצמצם את זמן האחזור של עיבוד המשימות, Aggregation Workers שומרים במטמון מפתחות פענוח למשך 8 שעות ומשתמשים בהם במשימות שהם מעבדים.
משימות Aggregation Worker פועלות במכונה של Trusted Execution Environment (TEE). כל משאב עבודה מטפל רק במשימה אחת בכל פעם. אפשר להגדיר כמה עובדים לעיבוד משימות במקביל על ידי הגדרת ההגדרה של התאמה אוטומטית לעומס. אם משתמשים בהתאמה אוטומטית, מספר העובדים משתנה באופן דינמי בהתאם למספר ההודעות בתור המשימות. אפשר להגדיר את המספר המינימלי והמקסימלי של עובדים להתאמה אוטומטית באמצעות קובץ הסביבה של Terraform. מידע נוסף על התאמה אוטומטית של קיבולת זמין בסקריפטים הבאים של Terraform: Amazon Web Services או Google Cloud.
עובדים של צבירה קוראים לשירות 'חשבונאות דוחות שניתנים לצבירה' לצורך חשבונאות של דוחות שניתנים לצבירה. השירות הזה מבטיח שהמשימות יפעלו רק אם לא חרגתם ממכסת התקציב לשמירה על הפרטיות. (ראו כלל 'ללא כפילויות'). אם התקציב זמין, המערכת יוצרת דוח סיכום באמצעות צבירות הנתונים עם הרעש. מידע נוסף על דיווח על דוחות שניתן לצבור
משימות Aggregation Worker מעדכנות את המטא-נתונים של המשימות במסד הנתונים של המטא-נתונים של המשימות. המידע הזה כולל קודי החזרה של משימות ומספרי דיווח על שגיאות במקרה של כשלים חלקיים בדוחות. המשתמשים יכולים לאחזר את המצב באמצעות ה-API לאחזור מצב המשימה getJob.
במאמר הזה מוסבר בפירוט על שירות האגרגציה.
השלבים הבאים
אחרי שסיפרנו לכם על היתרונות העיקריים של שירות הצבירה, הגיע הזמן לפרוס מכונה משלכם של שירות הצבירה דרך Google Cloud או Amazon Web Services. אפשר לעיין בקטע 'תחילת העבודה' או ללחוץ על הקישור הזה כדי לקבל מידע נוסף על הפעלת שירות האגרגציה.
פתרון בעיות
במסמך קודי שגיאה נפוצים והקלות מפורטים תיאורים מפורטים של הודעות השגיאה, מה יכול להיות הגורם לשגיאה שבה נתקלת והשלבים הבאים להקלה על הבעיה.
קבלת תמיכה ושליחת משוב
- אם יש לכם שאלות לגבי המוצר, משוב או בקשות למאפיינים חדשים, אתם יכולים ליצור דיווח על בעיה במאגר שלנו ב-GitHub.
- אם נתקלתם בשגיאה בזמן הפריסה, התחזוקה או ההרצה של משימות באמצעות Aggregation Service, אתם יכולים להשתמש בטופס הזה כדי לבקש תמיכה טכנית בפתרון בעיות.
- כדאי לבדוק במרכז הבקרה הציבורי לסטטוסים אם יש בעיות ידועות.