
El SDK de Connector y la API de Google Cloud Search permiten crear colas de indexación de Cloud Search que se usan para realizar las tareas siguientes:
Conservar el estado por documento (estado, valores de hash, etc.) que se pueden usar para mantener el índice sincronizado con tu repositorio
Conservar una lista de elementos para indexar descubiertos durante el proceso transversal
Priorizar los elementos en colas según el estado del elemento
Conservar información de estado adicional para una integración eficiente, como puntos de control, tokens de cambio, etcétera
Una cola es una etiqueta asignada a un elemento indexado, como "predeterminada" para la cola predeterminada o "B" para la cola B.
Estado y prioridad
La prioridad de un documento en una cola se basa en su código ItemStatus. A continuación, se muestran los códigos ItemStatus posibles en orden de prioridad (que se controlan del primero al último):
ERROR: un elemento que encontró un error asíncrono durante el proceso de indexación y debe volver a indexarse.MODIFIED: un elemento que ya fue indexado y se modificó en el repositorio tras la última indexación.NEW_ITEM: Elemento que no está indexado.ACCEPTED: Documento que ya se indexó y no se modificó en el repositorio desde la última indexación.
Cuando dos elementos en una cola tienen el mismo estado, se otorga mayor prioridad a los elementos que han estado en la cola durante un período más largo.
Descripción general del uso de colas de indexación para indexar un elemento nuevo o modificado
En la figura 1, se muestran los pasos para indexar un elemento nuevo o modificado con una fila de indexación. Estos pasos muestran llamadas a la API de REST. Para ver las llamadas equivalentes al SDK, consulta Operaciones de cola (SDK de conector).
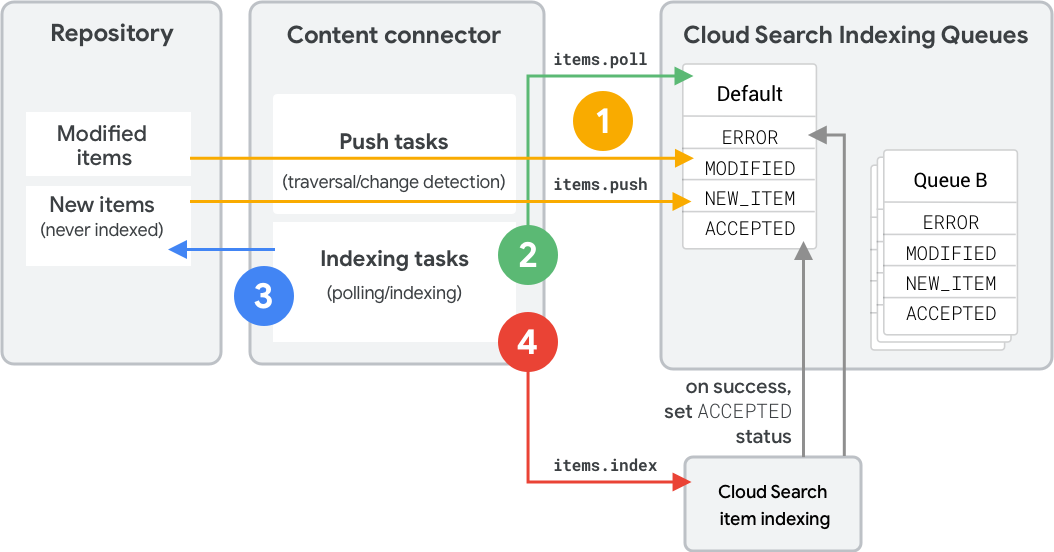
El conector de contenido usa
items.pushpara enviar elementos (metadatos y hash) a una cola de indexación a fin de establecer el estado del elemento (MODIFIED,NEW_ITEM,DELETED). Específicamente:- Cuando se envía un mensaje, el conector incluye de forma explícita un mensaje
typeocontentHash. - Si el conector no incluye
type, Cloud Search usa automáticamentecontentHashpara determinar el estado del elemento. - Si el artículo es desconocido, su estado se establece en
NEW_ITEM. - Si el elemento existe y los valores de hash coinciden, el estado se mantiene como
ACCEPTED. - Si el elemento existe y los valores hash difieren, el estado se convierte en
MODIFIED.
Para obtener más información sobre cómo se establece el estado de los elementos, consulta el código de muestra de Cómo recorrer los repositorios de GitHub en el instructivo de introducción a la Búsqueda de Cloud.
Por lo general, el envío está asociado con el recorrido de contenido o los procesos de detección de cambios en el conector.
- Cuando se envía un mensaje, el conector incluye de forma explícita un mensaje
El conector de contenido usa
items.pollpara sondear la cola y determinar los elementos que se indexarán. Cloud Search le indica al conector cuáles son los elementos que más necesitan indexarse, ordenados primero por código de estado y, luego, por tiempo en cola.El conector recupera estos elementos del repositorio y compila solicitudes de la API de index.
El conector usa
items.indexpara indexar los elementos. El elemento solo entra en el estadoACCEPTEDdespués de que Cloud Search termina de procesarlo correctamente.
Un conector también puede borrar un elemento si ya no existe en el repositorio o volver a enviar un elemento si no se modifica o si hay un error en el repositorio de código fuente. Para obtener información sobre la eliminación de elementos, consulta la siguiente sección.
Descripción general del uso de colas de indexación para borrar un elemento
La estrategia de recorrido completo usa un proceso de dos filas para indexar elementos y detectar eliminaciones. En la Figura 2, se muestran los pasos para borrar un elemento con dos filas de indexación. Específicamente, en la Figura 2, se muestra el segundo recorrido realizado con una estrategia de recorrido completo. En estos pasos, se usan las llamadas a la API de REST. Para llamadas al SDK equivalentes, consulta Operaciones de cola (SDK de conector).
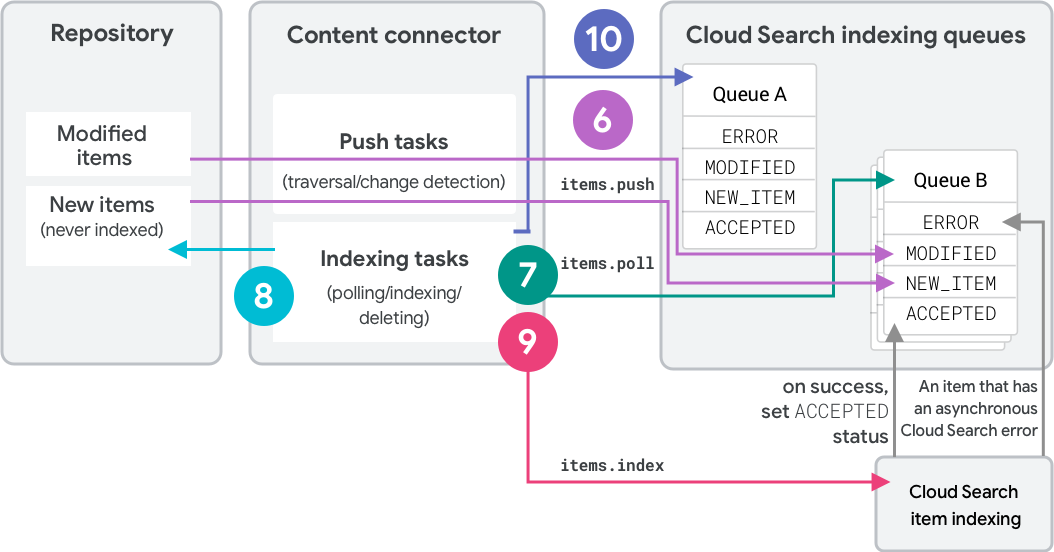
En el recorrido inicial, el conector de contenido usa
items.pushpara enviar elementos (metadatos y hash) a una fila de indexación, "fila A" comoNEW_ITEM, ya que no existe en la fila. A cada elemento se le asigna la etiqueta "A" para la "cola A". El contenido se indexa en Cloud Search.El conector de contenido usa
items.pollpara consultar la cola A y determinar los elementos que se indexarán. Cloud Search le indica al conector cuáles son los elementos que más necesitan indexarse, ordenados primero por código de estado y, luego, por tiempo en cola.El conector recupera estos elementos del repositorio y compila solicitudes de la API de index.
El conector usa
items.indexpara indexar los elementos. El elemento solo entra en el estadoACCEPTEDdespués de que Cloud Search termina de procesarlo correctamente.Se llama al método
deleteQueueItemsen la "cola B". Sin embargo, no se envió ningún elemento a la cola B, por lo que no se puede borrar nada.En el segundo recorrido completo, el conector de contenido usa
items.pushpara enviar elementos (metadatos y hash) a la cola B:- Cuando se envía un mensaje, el conector incluye de forma explícita un mensaje
typeocontentHash. - Si el conector no incluye el
type, Cloud Search usa automáticamente elcontentHashpara determinar el estado del elemento. - Si el elemento es desconocido, su estado se establece en
NEW_ITEMy la etiqueta de la fila cambia a "B". - Si el elemento existe y los valores de hash coinciden, el estado se mantiene como
ACCEPTEDy la etiqueta de la cola cambia a “B”. - Si el elemento existe y los valores hash difieren, el estado se convierte en
MODIFIEDy la etiqueta de fila cambia a "B".
- Cuando se envía un mensaje, el conector incluye de forma explícita un mensaje
El conector de contenido usa
items.pollpara sondear la cola y determinar los elementos que se indexarán. Cloud Search le indica al conector cuáles son los elementos que más necesitan indexarse, ordenados primero por código de estado y, luego, por tiempo en cola.El conector recupera estos elementos del repositorio y compila solicitudes de la API de index.
El conector usa
items.indexpara indexar los elementos. El elemento solo entra en el estadoACCEPTEDdespués de que Cloud Search termina de procesarlo correctamente.Por último, se llama a
deleteQueueItemsen la cola A para borrar todos los elementos de la Búsqueda de CCloud indexados anteriormente que aún tengan la etiqueta de cola "A".Con las iteraciones completas posteriores, se intercambian la cola que se usa para el indexado y la que se usa para la eliminación.
Operaciones de cola (SDK de conector)
El SDK de Content Connector proporciona operaciones para enviar elementos a una cola y extraerlos de ella.
Para agrupar y enviar un elemento a una cola, usa la clase de compilador pushItems.
No necesitas hacer nada específico si quieres extraer elementos de una cola para procesarlos. En su lugar, el SDK extrae automáticamente elementos de la cola, en orden de prioridad, con el método getDoc de la clase Repository.
Operaciones de cola (API de REST)
La API de REST proporciona los dos métodos siguientes para enviar elementos a una cola y extraerlos de ella:
- Para enviar un elemento a una cola, usa
Items.push. - Para sondear elementos en la fila, usa
Items.poll.
También puedes usar Items.index para enviar elementos a una cola durante la indexación. Los elementos que se envían a la cola durante la indexación no necesitan un type y se les asigna automáticamente un estado de ACCEPTED.
Items.push
El método Items.push agrega varios ID a la cola. Se puede llamar a este método con un valor type específico que determina el resultado de la operación de envío. Para obtener una lista de valores de type, consulta el campo item.type en el método Items.push.
Cuando se envía un ID nuevo, se agrega una entrada nueva con un código NEW_ITEM
ItemStatus.
La carga útil opcional siempre se almacena, se trata como un valor opaco y se muestra desde Items.poll.
Cuando se sondea un elemento, se reserva, por lo que no se puede mostrar con otra llamada a Items.poll.
El uso de Items.push con type como NOT_MODIFIED, REPOSITORY_ERROR o REQUEUE anula la reserva de las entradas sondeadas. Para obtener más información sobre las entradas reservadas y no reservadas, consulta la sección Items.poll.
Items.push con hash
La API de Google Cloud Search admite la especificación de metadatos y valores de hash de contenido en las solicitudes de Items.index. En lugar de especificar type, los metadatos o los valores de hash de contenido se pueden especificar con una solicitud de envío. La cola de indexación de Cloud Search compara los valores de hash proporcionados con los valores almacenados disponibles y el elemento en la fuente de datos. Si no coinciden, esa entrada se marca como MODIFIED. Si un elemento correspondiente no existe en el índice, el estado es NEW_ITEM.
Items.poll
El método Items.poll recupera los datos de entrada de más alta prioridad de la cola. Los valores de estado solicitados y mostrados indican los estados de las colas de prioridad solicitadas o el estado de los IDs mostrados.
De forma predeterminada, los datos de entradas de una sección de la cola se pueden mostrar, según la prioridad. Cada entrada que se muestra se reserva, y otras llamadas a Items.poll no la muestran hasta que se cumple una de las siguientes condiciones:
- Que se agote el tiempo de la reserva.
Items.indexvuelve a colocar la entrada en la cola.- Se llama a
Items.pushcon un valor detypedeNOT_MODIFIED,REPOSITORY_ERRORoREQUEUE.