Conceitos principais da API Private Aggregation
Para quem é este documento?
A API Private Aggregation permite a coleta de dados agregados de worklets com acesso a dados entre sites. Os conceitos compartilhados aqui são importantes para desenvolvedores que criam funções de relatórios na API Shared Storage e Protected Audience.
- Se você é um desenvolvedor criando um sistema de relatórios para medição em vários sites.
- Se você é um profissional de marketing, cientista de dados ou outro usuário de relatórios de resumo, entender esses mecanismos vai ajudar você a tomar decisões de design para extrair um relatório de resumo otimizado.
Termos-chave
Antes de ler este documento, é recomendável se familiarizar com os principais termos e conceitos. Cada um desses termos será descrito em detalhes aqui.
- Uma chave de agregação (também conhecida como bucket) é uma coleção predeterminada de pontos de dados. Por exemplo, você pode coletar um bucket de dados de local em que o navegador informa o nome do país. Uma chave de agregação pode conter mais de uma dimensão (por exemplo, país e ID do widget de conteúdo).
- Um valor agregável é um ponto de dados individual
coletado em uma chave de agregação. Se você quiser medir quantos usuários da França acessaram seu conteúdo,
Franceé uma dimensão na chave de agregação, e oviewCountde1é o valor agregável. - Os relatórios agregáveis são gerados e criptografados em um navegador. Para a API Private Aggregation, ele contém dados sobre um único evento.
- O serviço de agregação processa dados de relatórios agregáveis para criar um relatório de resumo.
- Um relatório de resumo é a saída final do serviço de agregação e contém dados de usuários agregados com ruídos e dados de conversão detalhados.
- Um worklet é uma parte da infraestrutura que permite executar funções JavaScript específicas e retornar informações ao solicitante. Em um worklet, você pode executar JavaScript, mas não pode interagir ou se comunicar com a página externa.
Fluxo de trabalho da Private Aggregation
Quando você chama a API Private Aggregation com uma chave de agregação e um valor agregável, o navegador gera um relatório agregável. Os relatórios são enviados para o servidor, que agrupa os relatórios. Os relatórios em lote são processados mais tarde pelo serviço de agregação, e um relatório de resumo é gerado.
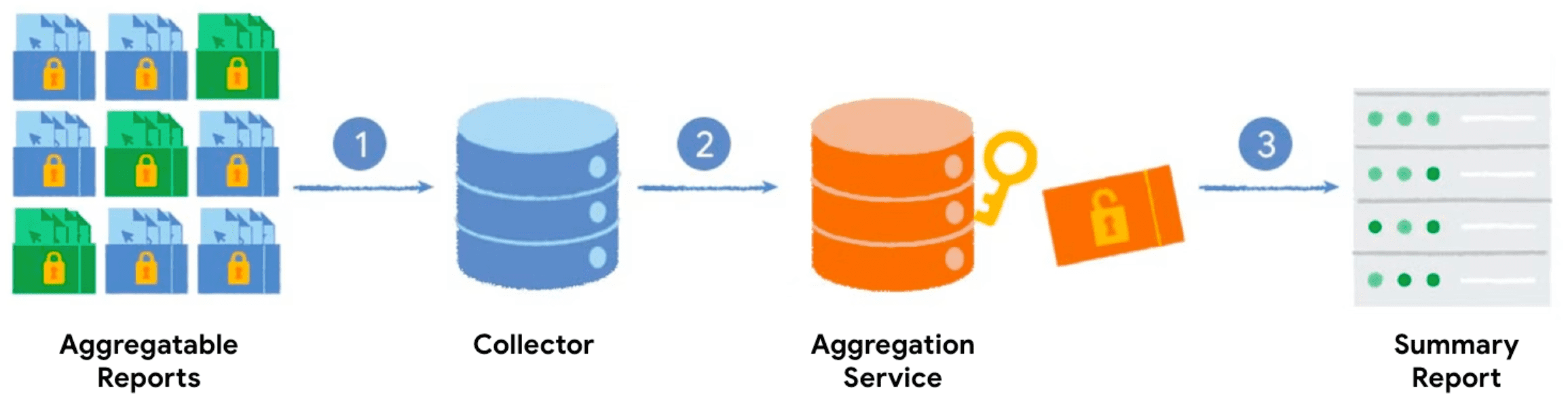
- Quando você chama a API Private Aggregation, o cliente (navegador) gera e envia o relatório agregável para o servidor ser coletado.
- Seu servidor coleta os relatórios dos clientes e os agrupa para serem enviados ao serviço de agregação.
- Depois de coletar relatórios suficientes, envie-os em lote para o serviço de agregação, em execução em um ambiente de execução confiável, para gerar um relatório resumido.
O fluxo de trabalho descrito nesta seção é semelhante à API Attribution Reporting. No entanto, os Relatórios de atribuição associam dados coletados de um evento de impressão e um evento de conversão, que acontecem em momentos diferentes. A agregação particular mede um único evento em vários sites.
Chave de agregação
Uma chave de agregação ("chave" abreviada) representa o bucket em que os valores agregáveis serão acumulados. Uma ou mais dimensões podem ser codificadas na chave. Uma dimensão representa um aspecto sobre o qual você quer ter mais informações, como a faixa etária dos usuários ou a contagem de impressões de uma campanha publicitária.
Por exemplo, você pode ter um widget incorporado em vários sites e querer analisar o país dos usuários que visualizaram o widget. Você quer responder a perguntas como "Quantos dos usuários que viram meu widget são do país X?" Para gerar relatórios sobre essa pergunta, configure uma chave de agregação que codifica duas dimensões: ID do widget e ID do país.
A chave fornecida à API Private Aggregation é um
BigInt,
que consiste em várias dimensões. Neste exemplo, as dimensões são o ID do widget e o ID do país. Digamos que o ID do widget possa ter até quatro dígitos, como 1234, e que cada país seja mapeado para um número em ordem alfabética, como o Afeganistão é 1, a França é 61 e o Zimbábue é 195.
Portanto, a chave agregável teria sete dígitos, em que os quatro primeiros caracteres são reservados para WidgetID e os três últimos são reservados para CountryID.
Digamos que a chave represente a contagem de usuários da França (ID do país 061)
que visualizaram o ID do widget 3276. A chave de agregação é 3276061.
| Chave de agregação | |
| ID do widget | ID do país |
| 3276 | 061 |
A chave de agregação também pode ser gerada com um mecanismo de hash, como
SHA-256. Por exemplo, a string
{"WidgetId":3276,"CountryID":67} pode ser hash e, em seguida, convertida em um
valor BigInt de
42943797454801331377966796057547478208888578253058197330928948081739249096287n.
Se o valor do hash tiver mais de 128 bits, você poderá truncá-lo para garantir que ele não
ultrapasse o valor máximo permitido do bucket de 2^128−1.
Em um worklet de armazenamento compartilhado, é possível acessar os módulos
crypto e
TextEncoder,
que podem ajudar a gerar um hash. Para saber mais sobre como gerar um hash, consulte
SubtleCrypto.digest() no
MDN.
O exemplo a seguir descreve como gerar uma chave de bucket a partir de um valor em hash:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Valor agregável
Os valores agregáveis são somados por chave em vários usuários para gerar insights agregados na forma de valores de resumo nos relatórios de resumo.
Agora, volte à pergunta de exemplo feita anteriormente: "Quantos dos usuários que viram meu widget são da França?" A resposta para essa pergunta vai ser algo como "Aproximadamente 4881 usuários que viram meu ID de widget 3276 são da França". O valor agregável é 1 para cada usuário, e "4881 usuários" é o valor agregado, que é a soma de todos os valores agregáveis para essa chave de agregação.
| Chave de agregação | Valor agregável | |
| ID do widget | ID do país | Contagem de visualizações |
| 3276 | 061 | 1 |
Neste exemplo, aumentamos o valor em 1 para cada usuário que vê o widget. Na prática, o valor agregável pode ser dimensionado para melhorar a proporção sinal-ruído.
Orçamento de contribuição
Cada chamada para a API Private Aggregation é chamada de contribuição. Para proteger a privacidade do usuário, o número de contribuições que podem ser coletadas de um indivíduo é limitado.
Quando você soma todos os valores agregáveis em todas as chaves de agregação, a soma precisa ser menor que o orçamento de contribuição. O orçamento é definido por origem de worklet, por dia, e é separado para worklets da API Protected Audience e do Shared Storage. Uma janela de aproximadamente as últimas 24 horas é usada para o dia. Se um novo relatório agregável ultrapassar o orçamento, ele não será criado.
O orçamento de contribuição é representado pelo parâmetro L1 e é definido como 216 (65.536) a cada dez minutos por dia com um limite de 220 (1.048.576). Consulte o explicador para saber mais sobre esses parâmetros.
O valor do orçamento de contribuição é arbitrário, mas o ruído é dimensionado para ele. Você pode usar esse orçamento para maximizar a relação entre sinal e ruído nos valores de resumo, conforme discutido na seção Ruído e dimensionamento.
Para saber mais sobre os orçamentos de contribuição, consulte o texto explicativo. Consulte também o orçamento de contribuição para mais orientações.
Limite de contribuição por alerta
Dependendo do autor da chamada, o limite de contribuição pode variar. No momento, os relatórios gerados para os autores de chamada da API Shared Storage têm um limite de 20 contribuições por relatório. Por outro lado, os autores de chamadas da API Protected Audience têm um limite de 100 contribuições por relatório. Esses limites foram escolhidos para equilibrar o número de contribuições que podem ser incorporadas com o tamanho do payload.
Para o armazenamento compartilhado, as contribuições feitas em uma única operação run() ou selectURL()
são agrupadas em um relatório. Para a Protected Audience, as contribuições feitas
por uma única origem em um leilão são agrupadas.
Contribuições com padding
As contribuições são modificadas com um recurso de preenchimento. O ato de preencher o
payload protege informações sobre o número real de contribuições incorporadas no
relatório agregável. O padding aumenta o payload com contribuições null
(ou seja, com valor de 0) para alcançar um comprimento fixo.
Relatórios agregáveis
Quando o usuário invoca a API Private Aggregation, o navegador gera
relatórios agregáveis para serem processados pelo serviço de agregação em um momento posterior
para gerar relatórios
de resumo. Um
relatório agregável tem formato JSON e contém uma lista criptografada de
contribuições, cada uma sendo um par {aggregation key, aggregatable value}.
Os relatórios agregáveis são enviados com um atraso aleatório de até uma hora.
As contribuições são criptografadas e não podem ser lidas fora do serviço de agregação. O serviço de agregação descriptografa os relatórios e gera um relatório de resumo. A chave de criptografia do navegador e a chave de descriptografia do serviço de agregação são emitidas pelo coordenador, que atua como o serviço de gerenciamento de chaves. O coordenador mantém uma lista de hashes binários da imagem do serviço para verificar se o autor da chamada tem permissão para receber a chave de descriptografia.
Exemplo de relatório agregável com o modo de depuração ativado:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Os relatórios agregáveis podem ser inspecionados na página
chrome://private-aggregation-internals:

Para fins de teste, o botão "Enviar relatórios selecionados" pode ser usado para enviar o relatório ao servidor imediatamente.
Coletar e agrupar relatórios agregáveis
O navegador envia os relatórios agregáveis para a origem do worklet que contém a chamada para a API Private Aggregation, usando o caminho conhecido listado:
- Para o armazenamento compartilhado:
/.well-known/private-aggregation/report-shared-storage - Para a API Protected Audience:
/.well-known/private-aggregation/report-protected-audience
Nesses endpoints, você vai precisar operar um servidor, que atua como coletor, que recebe os relatórios agregáveis enviados pelos clientes.
O servidor precisa agrupar os relatórios e enviar o lote para o serviço de agregação. Crie lotes com base nas informações disponíveis no payload não criptografado
do relatório agregável, como o campo shared_info. O ideal é que os lotes tenham 100 ou mais relatórios cada.
Você pode agrupar os dados diariamente ou semanalmente. Essa estratégia é flexível, e você pode mudar a estratégia de agrupamento para eventos específicos em que você espera mais volume, por exemplo, dias do ano em que mais impressões são esperadas. Os lotes precisam incluir relatórios da mesma versão da API, origem do relatório e horário do relatório programado.
Como filtrar IDs
A API e o serviço de agregação privada permitem o uso de IDs de filtragem para processar medições em um nível mais granular, como por campanha publicitária, em vez de processar os resultados em consultas maiores.

Para começar a usar essa função, siga estas etapas gerais para aplicar à sua implementação atual.
Etapas do armazenamento compartilhado
Se você estiver usando a API Shared Storage no seu fluxo:
Defina onde você vai declarar e executar o novo módulo de armazenamento compartilhado. No exemplo a seguir, nomeamos o arquivo de módulo como
filtering-worklet.js, registrado emfiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();O
filteringIdMaxBytesé configurável por relatório e, se não for definido, será definido como 1 por padrão. Esse valor padrão evita o aumento desnecessário do tamanho do payload e, consequentemente, dos custos de armazenamento e processamento. Leia mais no explicador de contribuições flexíveis.No arquivo usado acima, neste caso
filtering-worklet.js, ao transmitir uma contribuição paraprivateAggregation.contributeToHistogram(...)no worklet de armazenamento compartilhado, é possível especificar um ID de filtragem.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Os relatórios agregáveis serão enviados para onde você definiu o endpoint
/.well-known/private-aggregation/report-shared-storage. Continue no guia de filtragem de IDs para saber quais mudanças são necessárias nos parâmetros de jobs do serviço de agregação.
Depois que o processamento em lote for concluído e enviado ao serviço de agregação implantado, os resultados filtrados vão aparecer no relatório de resumo final.
Etapas da Protected Audience
Se você estiver usando a API Protected Audience no seu fluxo:
Na sua implementação atual da API Protected Audience, é possível definir o seguinte para conectar a API Private Aggregation. Ao contrário do armazenamento compartilhado, ainda não é possível configurar o tamanho máximo do ID de filtragem. Por padrão, o tamanho máximo do ID de filtragem é de 1 byte e será definido como
0n. Elas são definidas nas funções de relatórios da API Protected Audience (por exemplo,reportResult()ougenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Os relatórios agregáveis serão enviados para onde você definiu o endpoint
/.well-known/private-aggregation/report-protected-audience. Depois que o processamento em lote for concluído e enviado ao serviço de agregação implantado, os resultados filtrados vão aparecer no relatório de resumo final. Os seguintes explicadores para a API Attribution Reporting e a API Private Aggregation estão disponíveis, assim como a proposta inicial.
Continue com nosso guia de filtragem de IDs no Serviço de agregação ou acesse as seções da API Attribution Reporting para ler uma conta mais detalhada.
Serviço de agregação
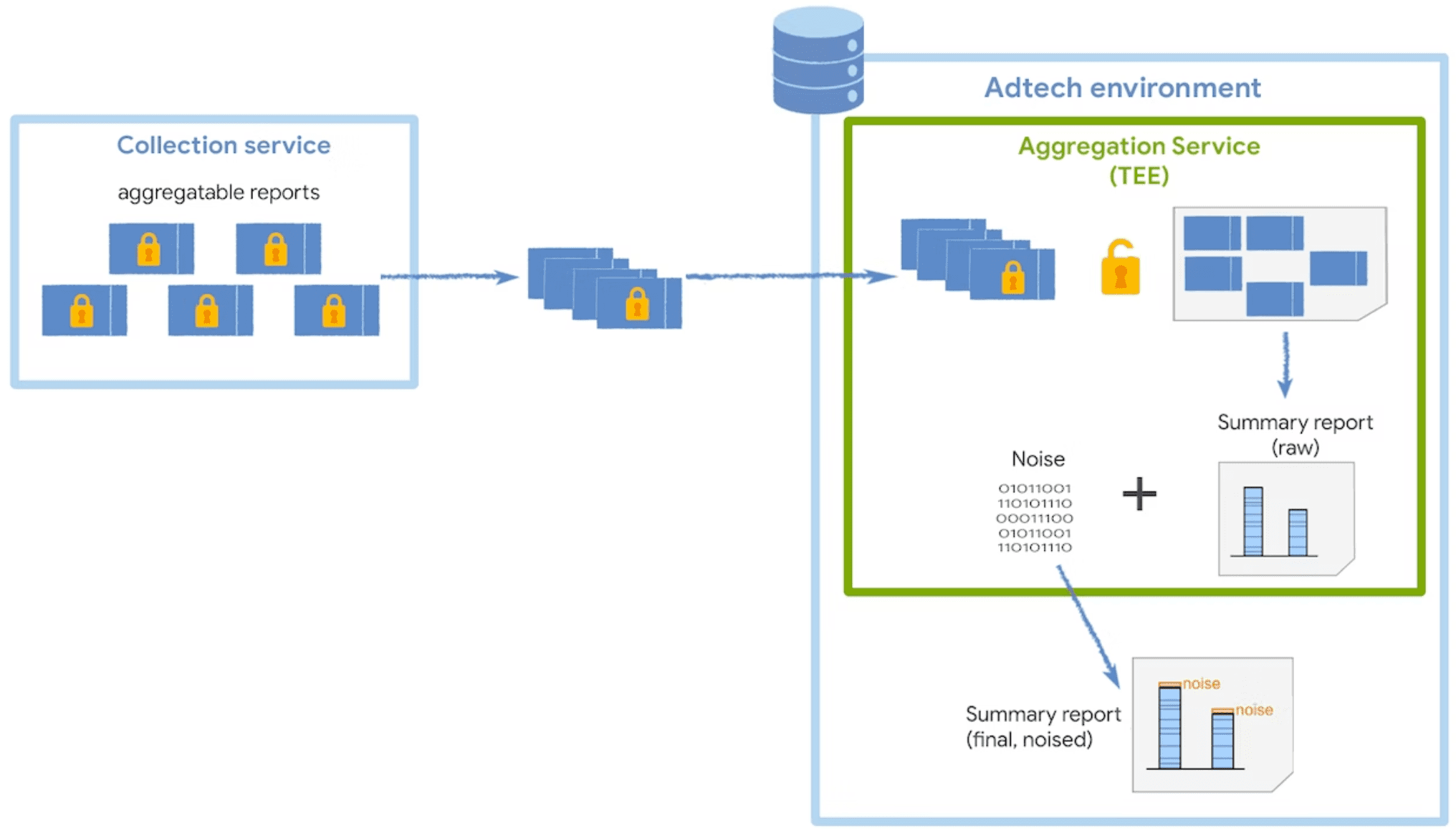
O serviço de agregação recebe relatórios criptografados e agregáveis do coletor e gera relatórios de resumo. Para mais estratégias sobre como agrupar relatórios no coletor, consulte nosso guia de agrupamento.
O serviço é executado em um ambiente de execução confiável (TEE), que oferece um nível de garantia de integridade de dados, confidencialidade de dados e integridade do código. Se você quiser saber mais sobre como os coordenadores são usados com TEEs, leia mais sobre o papel e a finalidade deles.
Relatórios de resumo
Os relatórios de resumo mostram os dados coletados com a adição de ruído. É possível solicitar relatórios de resumo para um determinado conjunto de chaves.
Um relatório de resumo contém um conjunto de pares de chave-valor no estilo de dicionário JSON. Cada par contém:
bucket: a chave de agregação como uma string de número binário. Se a chave de agregação usada for "123", o bucket será "1111011".value: o valor de resumo de uma determinada meta de medição, somado de todos os relatórios agregáveis disponíveis com ruído adicionado.
Exemplo:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Ruído e escalonamento
Para preservar a privacidade do usuário, o serviço de agregação adiciona ruído uma vez a cada valor de resumo sempre que um relatório de resumo é solicitado. Os valores de ruído são extraídos aleatoriamente de uma distribuição de probabilidade de Laplace. Embora você não tenha controle direto sobre as maneiras como o ruído é adicionado, é possível influenciar o impacto do ruído nos dados de medição.
A distribuição de ruído é a mesma, independentemente da soma de todos os valores agregáveis. Portanto, quanto maiores forem os valores agregáveis, menor será o impacto do ruído.
Por exemplo, digamos que a distribuição de ruído tenha um desvio padrão de 100 e esteja centralizada em zero. Se o valor do relatório agregável coletado (ou "valor agregável") for apenas 200, a variação padrão do ruído será de 50% do valor agregado. No entanto, se o valor agregável for 20.000,a desvio padrão do ruído será apenas 0, 5% do valor agregado. Portanto, o valor agregável de 20.000 teria uma relação sinal-ruído muito maior.
Portanto, multiplicar o valor agregável por um fator de escalonamento pode ajudar a reduzir o ruído. O fator de escalonamento representa o quanto você quer escalonar um determinado valor agregável.

Aumentar os valores escolhendo um fator de escalonamento maior reduz o ruído relativo. No entanto, isso também faz com que a soma de todas as contribuições em todos os buckets alcance o limite de orçamento de contribuição mais rapidamente. Reduzir os valores escolhendo uma constante de fator de escalonamento menor aumenta o ruído relativo, mas reduz o risco de atingir o limite de orçamento.
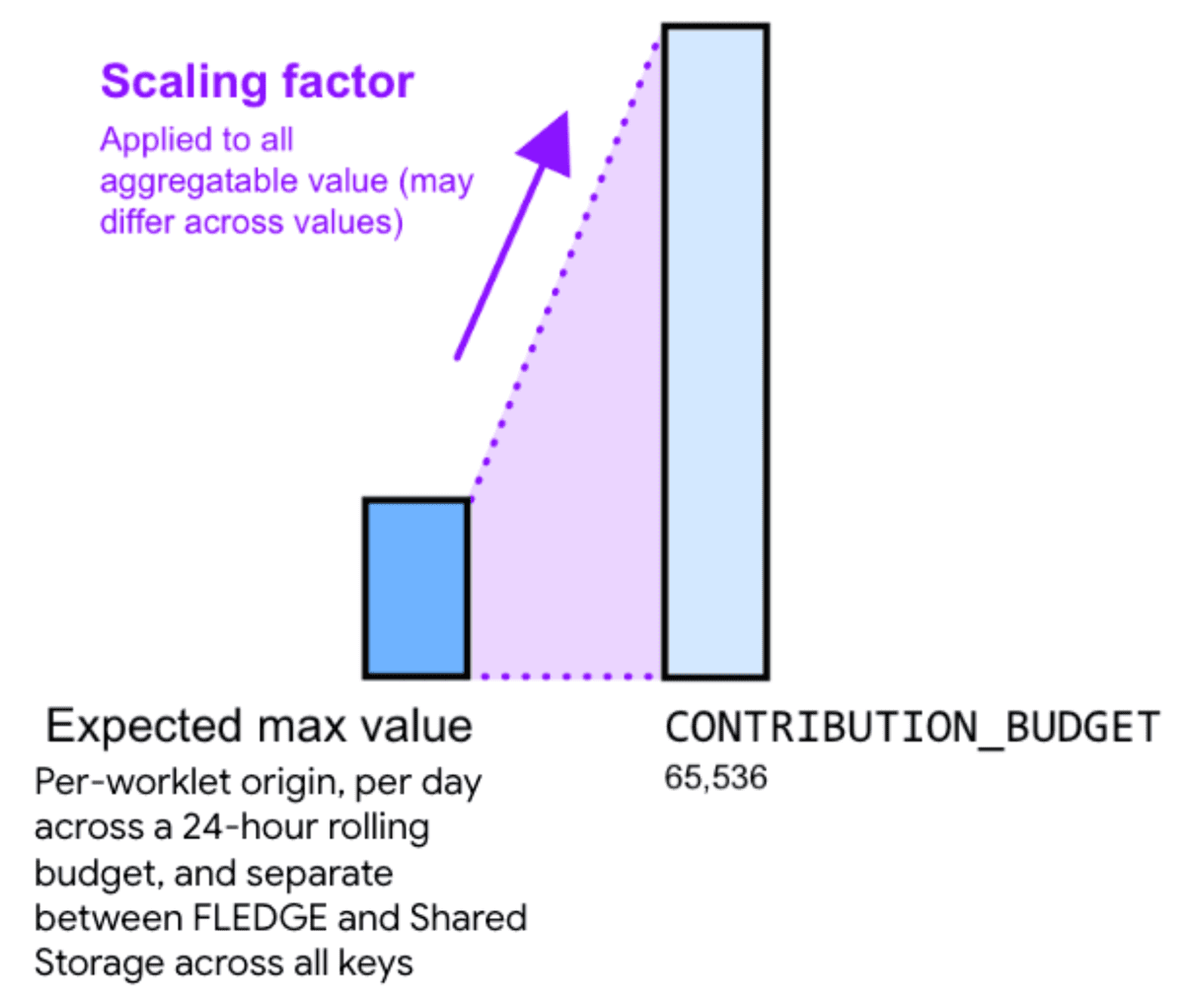
Para calcular um fator de escalonamento adequado, divida o orçamento de contribuição pela soma máxima de valores agregáveis em todas as chaves.
Consulte a documentação do orçamento de contribuição para saber mais.
Engajamento e compartilhamento de feedback
A API Private Aggregation está em discussão ativa e sujeita a mudanças no futuro. Se você testar essa API e tiver feedback, adoraríamos saber sua opinião.
- GitHub: leia a explicação, faça perguntas e participe da discussão.
- Suporte para desenvolvedores: faça perguntas e participe das discussões no Repositório de suporte para desenvolvedores do Sandbox de privacidade.
- Participe do grupo da API Shared Storage e do grupo da API Protected Audience para conferir os anúncios mais recentes relacionados à agregação particular.