Private Aggregation API 的重要概念
這份文件的適用對象
Private Aggregation API 可讓您從可存取跨網站資料的 worklet 收集匯總資料。對於開發人員來說,這裡分享的概念非常重要,因為他們需要在 Shared Storage 和 Protected Audience API 中建構報表函式。
- 如果您是開發人員,並正在建構跨網站評估的報表系統。
- 如果您是行銷人員、數據科學家或其他摘要報表使用者,瞭解這些機制有助於您做出設計決策,以便擷取最佳化的摘要報表。
重要詞彙
閱讀本文前,請先熟悉關鍵字詞和概念。我們將在本文中詳細說明每個術語。
- 匯總鍵 (也稱為值區) 是預先指定的資料點集合。舉例來說,您可能會想收集位置資料值區,其中瀏覽器會回報國家/地區名稱。匯總鍵可能包含多個維度 (例如內容小工具的國家/地區和 ID)。
- 可匯總的值是收集至匯總鍵的個別資料點。如果您想評估法國有多少使用者看過您的內容,
France就是匯總鍵中的維度,而1的viewCount就是可匯總的值。 - 可匯總報表會在瀏覽器中產生及加密。對於 Private Aggregation API,這會包含單一事件的資料。
- 匯總服務會處理可匯總報表中的資料,並建立摘要報表。
- 摘要報表是匯總服務的最終輸出內容,其中包含雜訊匯總使用者資料和詳細轉換資料。
- 工作單元是一種基礎架構,可讓您執行特定 JavaScript 函式,並將資訊傳回給要求者。您可以在 worklet 中執行 JavaScript,但無法與外部網頁互動或進行通訊。
「私密匯總」工作流程
當您使用匯總鍵和可匯總值呼叫 Private Aggregation API 時,瀏覽器會產生可匯總報表。報表會傳送至您的伺服器,以便匯出報表。匯總服務稍後會處理批次報表,並產生摘要報表。
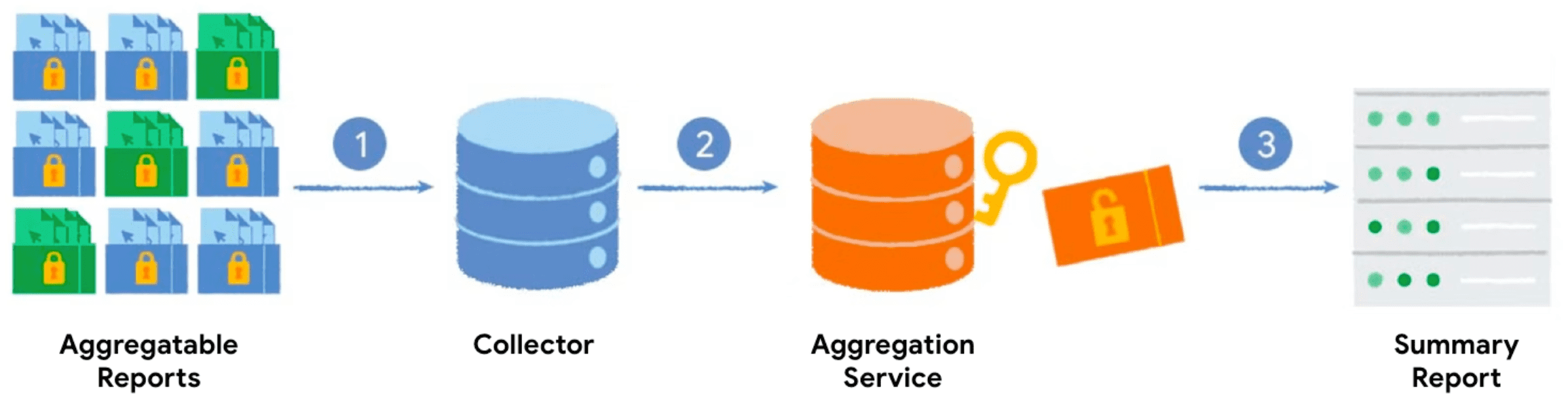
- 當您呼叫 Private Aggregation API 時,用戶端 (瀏覽器) 會產生匯總報表,並將該報表傳送至伺服器進行收集。
- 您的伺服器會收集用戶端的報表,並將報表批次傳送至匯總服務。
- 收集足夠的報表後,您就可以將報表批次處理並傳送至匯總服務,在可信執行環境中執行,以產生摘要報表。
本節所述的工作流程與 Attribution Reporting API 相似。不過,歸因報表會將來自曝光事件和轉換事件的資料建立關聯,而這兩種事件發生的時間不同。私密匯總會評估單一跨網站事件。
匯總鍵
匯總鍵 (簡稱「鍵」) 代表匯總值會累積的值區。您可以將一或多個維度編碼至鍵中。維度代表您想深入瞭解的某些面向,例如使用者的年齡層或廣告活動的曝光次數。
舉例來說,您可能會在多個網站上嵌入小工具,並想分析看過小工具的使用者所在國家/地區。您想解答的問題包括:「有多少使用者看過我的小工具,且來自 X 國家/地區?」如要回報這個問題,您可以設定匯總鍵,用於編碼兩個維度:小工具 ID 和國家/地區 ID。
提供給 Private Aggregation API 的鍵是 BigInt,其中包含多個維度。在本範例中,維度是小工具 ID 和國家/地區 ID。假設小工具 ID 最多可為 4 位數,例如 1234,且每個國家/地區都會依照字母順序對應至數字,例如阿富汗是 1、法國是 61、辛巴威是 195。因此,可匯總的索引鍵長度為 7 位數,其中前 4 個字元保留給 WidgetID,最後 3 個字元保留給 CountryID。
假設這個鍵代表看過小工具 ID 3276 的法國使用者人數 (國家/地區 ID 061),匯總鍵則為 3276061。
| 匯總鍵 | |
| 小工具 ID | 國家/地區 ID |
| 3276 | 061 |
您也可以使用雜湊機制 (例如 SHA-256) 產生匯總鍵。例如,字串 {"WidgetId":3276,"CountryID":67} 可以經過雜湊處理,然後轉換為 42943797454801331377966796057547478208888578253058197330928948081739249096287n 的 BigInt 值。如果雜湊值超過 128 位元,您可以截斷雜湊值,確保不會超過 2^128−1 的最大值。
在共用儲存空間工作區中,您可以存取 crypto 和 TextEncoder 模組,協助您產生雜湊。如要進一步瞭解如何產生雜湊,請參閱 MDN 上的 SubtleCrypto.digest()。
以下範例說明如何根據雜湊值產生值區索引鍵:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
可匯總的值
系統會將許多使用者的每個鍵加總為一組,並在摘要報表中以摘要值的形式產生綜合洞察資料。
我們現在回到先前提出的問題示例:「有多少使用者看過我的小工具,且來自法國?」這個問題的答案會是類似「約 4881 位使用者看過我的小工具 ID 3276,他們來自法國」的內容。每位使用者的可匯總值為 1,而「4881 位使用者」是匯總值,也就是該匯總鍵的所有可匯總值總和。
| 匯總鍵 | 可匯總的值 | |
| 小工具 ID | 國家/地區 ID | 觀看次數 |
| 3276 | 061 | 1 |
在這個範例中,我們會針對每位看到小工具的使用者,將值增加 1。實際上,您可以調整可匯總的值,以改善信號雜訊比。
貢獻預算
每個 Private Aggregation API 呼叫都稱為貢獻。為保護使用者隱私,我們限制了可向個人收集的貢獻數量。
當您將所有匯總鍵的所有可匯總值加總時,總和必須小於貢獻預算。預算範圍為每個 worklet 來源、每天,且 Protected Audience API 和 Shared Storage worklet 各自獨立。系統會使用大約過去 24 小時的滾動視窗來計算當天的數據。如果新匯總報表會導致超出預算,系統就不會建立報表。
貢獻預算由參數 L1 代表,並設為每天每 10 分鐘 216 (65,536),且有 220 (1,048,576) 的備用值。請參閱說明文件,進一步瞭解這些參數。
貢獻預算的值為任意值,但雜訊會依此調整。您可以使用這個預算,在摘要值上盡量提高信號雜訊比 (詳見「雜訊和縮放」一節)。
如要進一步瞭解貢獻預算,請參閱說明。此外,請參閱「貢獻預算」一文,瞭解更多指引。
每份報表的貢獻數量上限
貢獻限制可能因呼叫端而異。目前,系統為 Shared Storage API 呼叫端產生的報表,每份報表最多可包含 20 個貢獻。另一方面,Protected Audience API 呼叫端的每份報表最多可包含 100 個貢獻。這些限制的目的在於平衡可嵌入的貢獻數量與酬載大小。
在共用儲存空間中,單一 run() 或 selectURL() 作業內的貢獻會批次匯入一份報表。在 Protected Audience 中,單一來源在競價中做出的貢獻會一起分批處理。
含邊框間距的貢獻
貢獻內容會進一步透過邊框功能進行修改。填充酬載的行為可保護可匯總報表中嵌入的貢獻真實數量資訊。填充會使用 null 貢獻內容 (即值為 0) 來擴充酬載,以達到固定長度。
可匯總報表
使用者叫用 Private Aggregation API 後,瀏覽器會產生可匯總的報表,以便由匯總服務稍後處理,產生摘要報表。可匯總的報表採用 JSON 格式,並包含加密的貢獻清單,每個清單都是 {aggregation key, aggregatable value} 組合。可匯總報表會在隨機延遲最多一小時後傳送。
貢獻內容已加密,在匯總服務以外的環境中無法讀取。匯總服務會解密報表並產生摘要報表。瀏覽器的加密金鑰和匯總服務的解密金鑰,是由協調器 (做為金鑰管理服務) 發出。協調器會保留服務映像檔的二進位雜湊清單,以驗證呼叫端是否有權接收解密金鑰。
啟用偵錯模式的可匯總報表範例:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
您可以透過 chrome://private-aggregation-internals 頁面檢查可匯總報表:

為了進行測試,「傳送所選報表」按鈕可用於立即將報表傳送至伺服器。
收集及批次匯總報表
瀏覽器會使用列出的已知路徑,將可匯總的報表傳送至包含對 Private Aggregation API 呼叫的 worklet 來源:
- 共用儲存空間:
/.well-known/private-aggregation/report-shared-storage - 適用於受保護的目標對象:
/.well-known/private-aggregation/report-protected-audience
在這些端點中,您需要運作伺服器 (做為收集器),以便接收用戶端傳送的可匯總報表。
接著,伺服器應將報表匯出,並將匯總資料傳送至匯總服務。根據可匯總報表中未加密的酬載 (例如 shared_info 欄位) 中提供的資訊建立批次。在理想情況下,每個批次應包含 100 份以上的報表。
您可以每天或每週執行批次作業。這項策略相當靈活,您可以針對預期有更多流量 (例如預期有更多曝光的特定日子) 變更批次處理策略。批次應包含相同 API 版本、報表來源和排程報表時間的報表。
篩選 ID
私人匯總 API 和匯總服務可使用篩選 ID,以更精細的層級 (例如個別廣告活動) 處理評估結果,而非處理較大查詢的結果。

如要立即開始使用這項功能,請參考下列大致步驟,將這項功能套用至目前的實作項目。
共用儲存空間步驟
如果您在流程中使用 Shared Storage API:
定義要宣告及執行新共用儲存空間模組的位置。在以下範例中,我們將模組檔案命名為
filtering-worklet.js,並註冊在filtering-example下。(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();請注意,
filteringIdMaxBytes可依報表設定,如果未設定,則預設為 1。這個預設值可避免不必要地增加酬載大小,進而增加儲存和處理成本。詳情請參閱彈性出資說明。在您上述使用的檔案 (本例為
filtering-worklet.js) 中,當您在共用儲存空間工作區中將貢獻內容傳遞至privateAggregation.contributeToHistogram(...)時,可以指定篩選 ID。// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);系統會將可匯總報表傳送至您定義的端點
/.well-known/private-aggregation/report-shared-storage。請繼續參閱篩選 ID 指南,瞭解匯總服務工作參數中需要進行的變更。
批次處理完成並傳送至已部署的匯總服務後,篩選結果應會顯示在最終摘要報表中。
Protected Audience 步驟
如果您在流程中使用 Protected Audience API:
在目前的 Protected Audience 導入作業中,您可以設定下列項目,以連結至 Private Aggregation。與共用儲存空間不同的是,您目前無法設定篩選 ID 的大小上限。根據預設,篩選 ID 的大小上限為 1 個位元組,並會設為
0n。請注意,這些值會在Protected Audience 回報功能中設定 (例如reportResult()或generateBid())。const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);系統會將可匯總報表傳送至您定義的端點
/.well-known/private-aggregation/report-protected-audience。批次處理完成並傳送至已部署的匯總服務後,篩選結果應會顯示在最終摘要報表中。以下是 Attribution Reporting API 和 Private Aggregation API 的說明,以及初始提案。
請繼續參閱匯總服務的ID 篩選指南,或前往Attribution Reporting API 專區,進一步瞭解相關資訊。
匯總服務
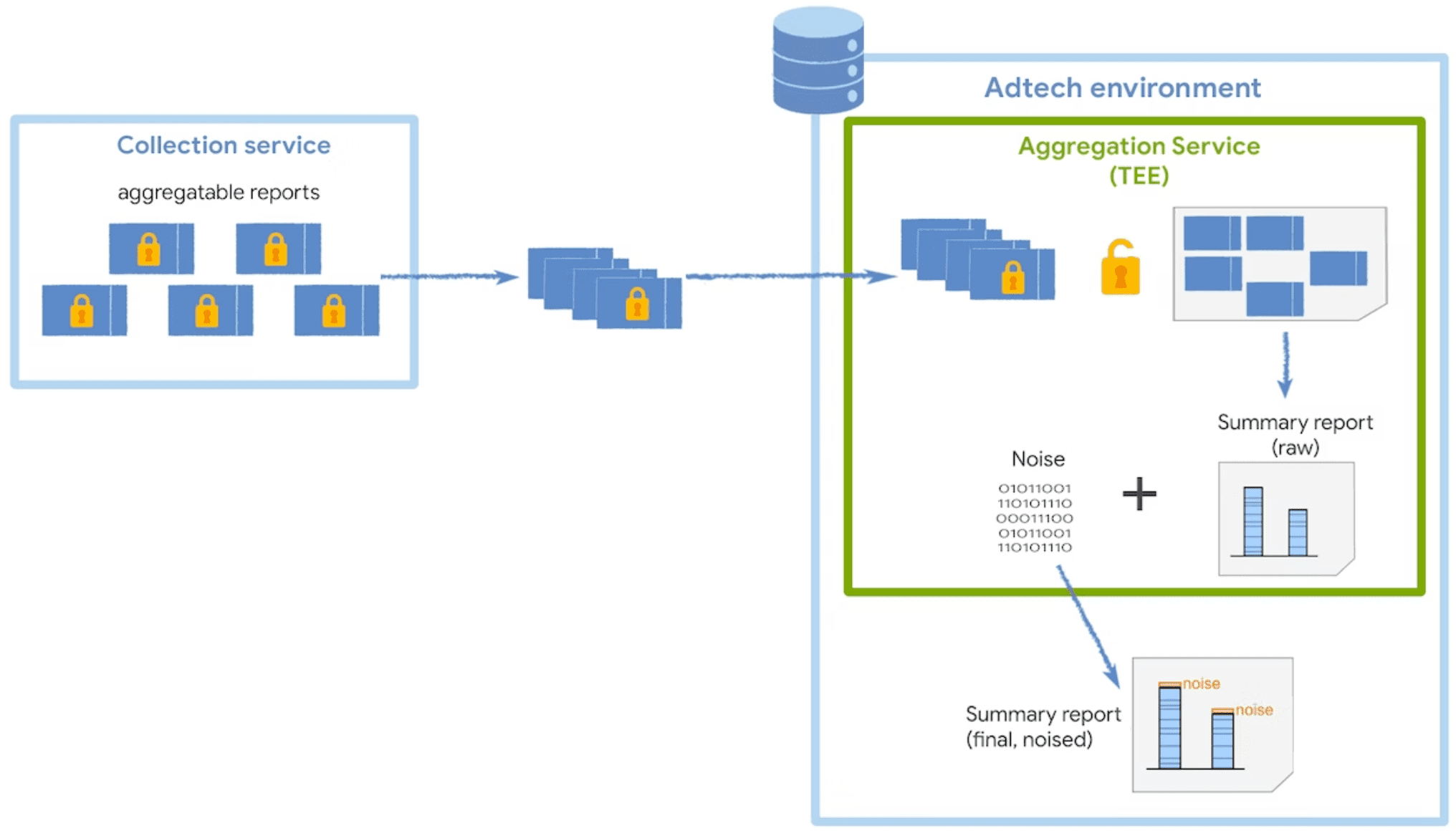
匯總服務會接收收集器傳送的加密可匯總報表,並產生摘要報表。如要進一步瞭解如何在收集器中批次匯出可匯總的報表,請參閱批次指南。
這項服務會在受信任的執行環境 (TEE) 中執行,可確保資料完整性、資料機密性和程式碼完整性。如要進一步瞭解協調器如何與 TEE 搭配使用,請參閱有關協調器的角色和用途的詳細說明。
摘要報表
摘要報表可讓您查看收集到的資料,以及其中的雜訊。您可以針對特定一組金鑰要求摘要報表。
摘要報表包含 JSON 字典樣式的鍵/值組合。每個組合都包含:
bucket:匯總鍵,以二進位數字串表示。如果使用的匯總鍵是「123」,則值域為「1111011」。value:特定評估目標的摘要值,是從所有可匯總的報表中匯總而來,並加入雜訊。
例如:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
雜訊和縮放
為保護使用者隱私,匯總服務會在每次要求摘要報表時,為每個摘要值新增一次雜訊。雜訊值是隨機從 Laplace 機率分布中抽取。雖然您無法直接控制噪音的加入方式,但可以影響噪音對測量資料的影響。
無論所有可匯總值的總和為何,雜訊分布都相同。因此,可匯總的值越多,雜訊造成的影響就越小。
舉例來說,假設雜訊分佈的標準差為 100,且以零為中心。如果收集到的可匯總報表值 (或「可匯總值」) 只有 200,雜訊的標準差會是匯總值的 50%。不過,如果可匯總的值為 20,000,雜訊的標準差只會是匯總值的 0.5%。因此,可匯集的值 20,000 會有更高的訊號雜訊比。
因此,將可匯總的值乘上縮放比例係數,有助於減少雜訊。比例因數代表您要將特定可匯總值擴大多少倍。

選擇較大的縮放因數來縮放值,可減少相對雜訊。不過,這也會導致所有分桶的所有貢獻總和更快達到貢獻預算上限。選擇較小的縮放因子常數來縮小值,雖然會增加相對雜訊,但可降低達到預算限制的風險。
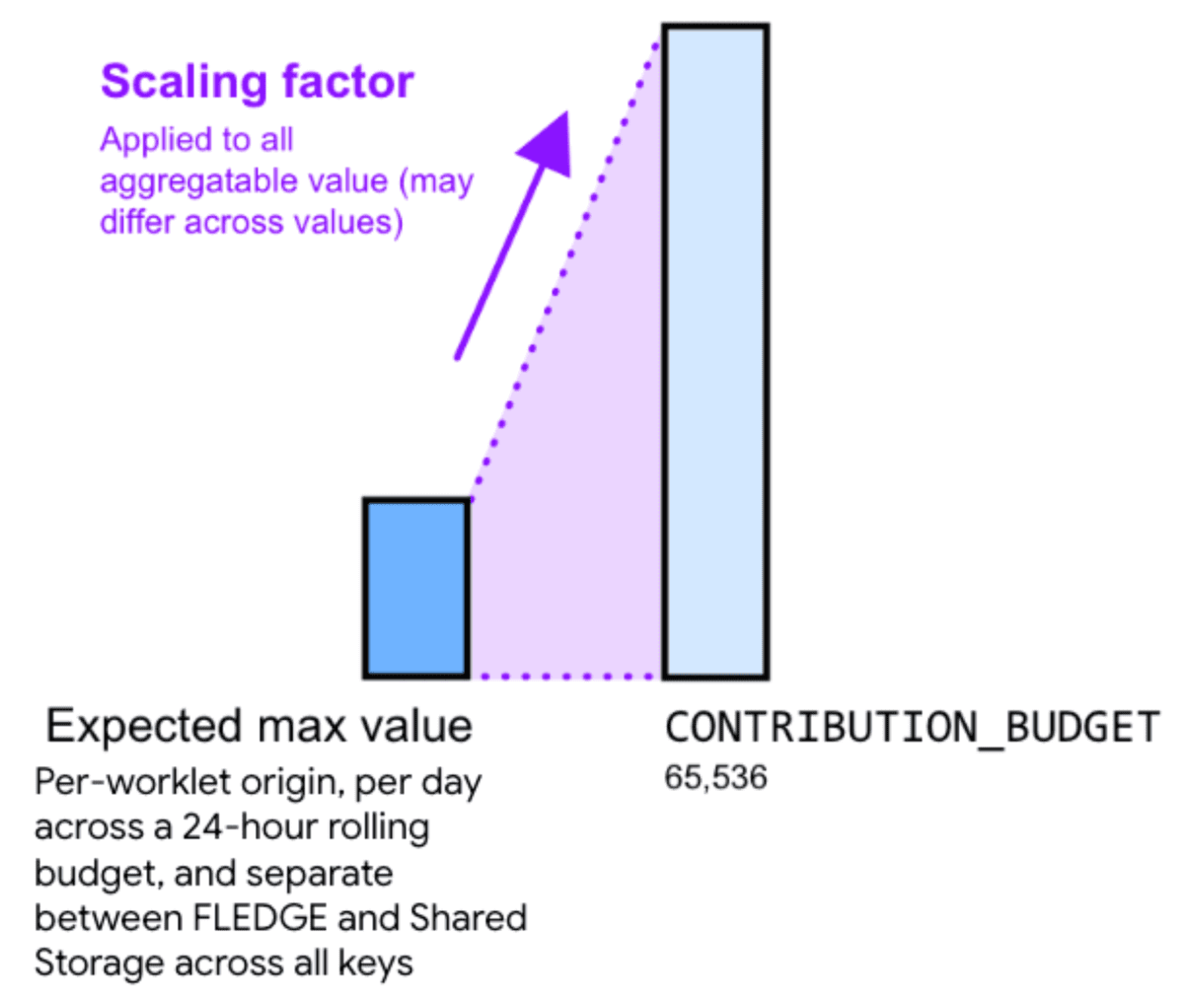
如要計算適當的縮放因子,請將貢獻預算除以所有鍵可匯總值的最大總和。
詳情請參閱貢獻預算說明文件。
互動並分享意見回饋
我們目前正積極討論 Private Aggregation API,因此未來可能會有所變動。如果您試用這個 API 後有任何意見,歡迎與我們分享。
- GitHub:閱讀說明文章,提出問題並參與討論。
- 開發人員支援:在 Privacy Sandbox 開發人員支援存放區中提問及參與討論。
- 加入 Shared Storage API 群組和 Protected Audience API 群組,瞭解與 Private Aggregation 相關的最新公告。