Private Aggregation API의 주요 개념
이 문서의 대상
Private Aggregation API를 사용하면 크로스 사이트 데이터에 액세스할 수 있는 워크렛에서 집계 데이터를 수집할 수 있습니다. 여기에 공유된 개념은 Shared Storage 및 Protected Audience API 내에서 보고 기능을 빌드하는 개발자에게 중요합니다.
- 교차 사이트 측정을 위한 보고 시스템을 빌드하는 개발자인 경우
- 마케터, 데이터 과학자 또는 기타 요약 보고서 소비자인 경우 이러한 메커니즘을 이해하면 최적화된 요약 보고서를 검색하기 위한 설계 결정을 내리는 데 도움이 됩니다.
핵심 용어
이 문서를 읽기 전에 핵심 용어와 개념을 숙지하면 도움이 됩니다. 이러한 각 용어는 여기에서 자세히 설명합니다.
- 집계 키 (버킷이라고도 함)는 사전 결정된 데이터 포인트 모음입니다. 예를 들어 브라우저가 국가 이름을 보고하는 위치 데이터 버킷을 수집할 수 있습니다. 집계 키에는 두 개 이상의 측정기준 (예: 콘텐츠 위젯의 국가 및 ID)이 포함될 수 있습니다.
- 집계 가능한 값은 집계 키로 수집된 개별 데이터 포인트입니다. 프랑스에서 내 콘텐츠를 본 사용자 수를 측정하려면
France가 집계 키의 측정기준이고1의viewCount가 집계 가능한 값입니다. - 집계 가능한 보고서는 브라우저 내에서 생성되고 암호화됩니다. Private Aggregation API의 경우 단일 이벤트에 관한 데이터가 포함됩니다.
- 집계 서비스는 집계 가능한 보고서의 데이터를 처리하여 요약 보고서를 만듭니다.
- 요약 보고서는 집계 서비스의 최종 출력물로, 노이즈가 있는 집계된 사용자 데이터와 세부적인 변환 데이터를 포함합니다.
- 워크렛은 특정 JavaScript 함수를 실행하고 요청자에게 정보를 다시 반환할 수 있는 인프라입니다. 워크렛 내에서는 JavaScript를 실행할 수 있지만 외부 페이지와 상호작용하거나 통신할 수는 없습니다.
Private Aggregation 워크플로
집계 키와 집계 가능한 값을 사용하여 Private Aggregation API를 호출하면 브라우저에서 집계 가능한 보고서를 생성합니다. 보고서는 보고서를 일괄 처리하는 서버로 전송됩니다. 일괄 처리된 보고서는 나중에 집계 서비스에서 처리되고 요약 보고서가 생성됩니다.
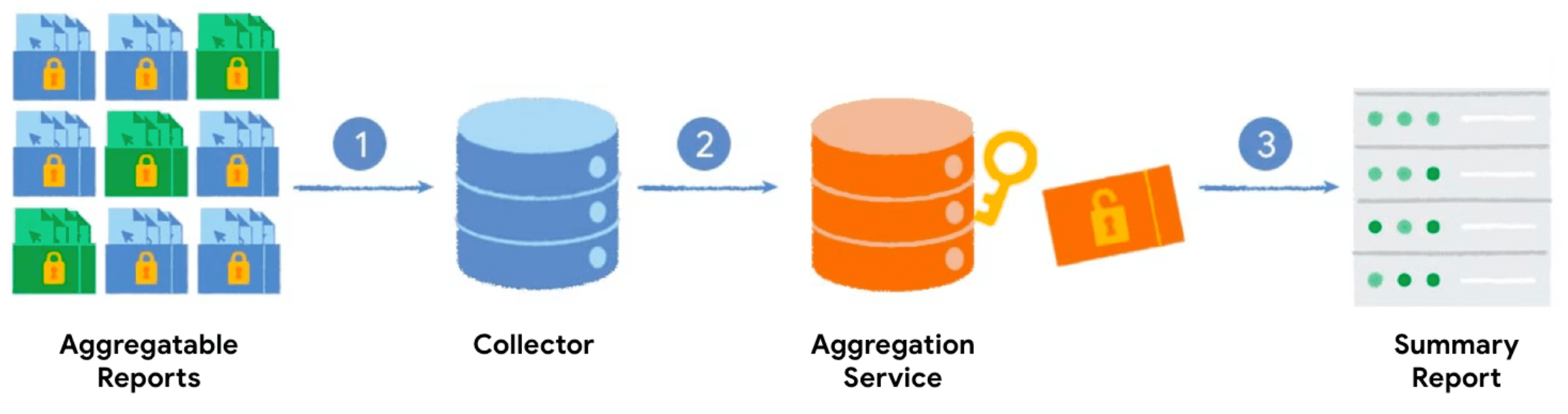
- Private Aggregation API를 호출하면 클라이언트 (브라우저)가 집계 가능한 보고서를 생성하여 수집할 수 있도록 서버로 전송합니다.
- 서버는 클라이언트로부터 보고서를 수집하고 집계 서비스로 전송하기 위해 일괄 처리합니다.
- 충분한 보고서를 수집하면 신뢰할 수 있는 실행 환경에서 실행되는 집계 서비스로 일괄 전송하여 요약 보고서를 생성합니다.
이 섹션에 설명된 워크플로는 Attribution Reporting API와 유사합니다. 하지만 기여도 보고에서는 서로 다른 시점에 발생하는 노출 이벤트와 전환 이벤트에서 수집된 데이터를 연결합니다. 비공개 집계는 단일 교차 사이트 이벤트를 측정합니다.
집계 키
집계 키(줄여서 '키')는 집계 가능한 값이 누적되는 버킷을 나타냅니다. 하나 이상의 측정기준을 키에 인코딩할 수 있습니다. 측정기준은 사용자 연령대 또는 광고 캠페인의 노출수와 같이 자세히 알아보고자 하는 측면을 나타냅니다.
예를 들어 여러 사이트에 삽입된 위젯이 있고 이 위젯을 본 사용자의 국가를 분석하려고 할 수 있습니다. '내 위젯을 본 사용자 중 X 국가 출신은 몇 명인가요?'와 같은 질문에 답변하려고 합니다. 이 질문에 대해 보고하려면 위젯 ID 및 국가 ID라는 두 측정기준을 인코딩하는 집계 키를 설정하면 됩니다.
Private Aggregation API에 제공되는 키는 여러 측정기준으로 구성된 BigInt입니다. 이 예에서 측정기준은 위젯 ID와 국가 ID입니다. 위젯 ID는 최대 4자리(예: 1234)까지 가능하고 각 국가는 알파벳순으로 숫자에 매핑된다고 가정해 보겠습니다(예: 아프가니스탄은 1, 프랑스는 61, 잠비아는 195).
따라서 집계 가능한 키는 길이가 7자리이며, 여기서 처음 4자리는 WidgetID용으로 예약되고 마지막 3자리는 CountryID용으로 예약됩니다.
키가 위젯 ID 3276를 본 프랑스 (국가 ID 061) 사용자 수를 나타낸다고 가정해 보겠습니다. 집계 키는 3276061입니다.
| 집계 키 | |
| 위젯 ID | 국가 ID |
| 3276 | 061 |
집계 키는 SHA-256과 같은 해싱 메커니즘으로 생성할 수도 있습니다. 예를 들어 문자열 {"WidgetId":3276,"CountryID":67}를 해싱한 후 42943797454801331377966796057547478208888578253058197330928948081739249096287n의 BigInt 값으로 변환할 수 있습니다.
해시 값이 128비트가 넘는 경우 허용되는 최대 버킷 값인 2^128−1을 초과하지 않도록 잘라낼 수 있습니다.
공유 저장소 워크렛 내에서 해시를 생성하는 데 도움이 되는 crypto 및 TextEncoder 모듈에 액세스할 수 있습니다. 해시 생성에 관한 자세한 내용은 MDN의 SubtleCrypto.digest()를 참고하세요.
다음 예에서는 해싱된 값에서 버킷 키를 생성하는 방법을 설명합니다.
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
집계 가능한 값
집계 가능한 값은 여러 사용자의 키별로 합산되어 요약 보고서에서 요약 값 형식으로 집계된 통계를 생성합니다.
이제 앞에서 던진 질문 예시인 '내 위젯을 본 사용자 중 프랑스 사용자가 몇 명인가요?'로 돌아갑니다. 이 질문에 대한 답변은 '내 위젯 ID 3276을 본 사용자 중 약 4,881명이 프랑스 사용자입니다.'와 같이 표시됩니다. 집계 가능한 값은 사용자마다 1이고 '4881 사용자'는 해당 집계 키의 모든 집계 가능한 값의 합계인 집계된 값입니다.
| 집계 키 | 집계 가능한 값 | |
| 위젯 ID | 국가 ID | 조회수 |
| 3276 | 061 | 1 |
이 예에서는 위젯을 보는 사용자마다 값을 1씩 증가시킵니다. 실제로 집계 가능한 값은 신호 대 노이즈 비율을 개선하도록 확장할 수 있습니다.
기여도 예산
Private Aggregation API를 호출할 때마다 참여가 발생합니다. 사용자 개인 정보를 보호하기 위해 개인으로부터 수집할 수 있는 참여 횟수가 제한됩니다.
모든 집계 키에서 집계 가능한 모든 값을 합산하면 합계가 기여도 예산보다 작아야 합니다. 예산은 워크렛 출처별, 일별로 범위가 지정되며 Protected Audience API와 Shared Storage 워크렛에 대해 별도로 설정됩니다. 하루 동안 대략 지난 24시간의 롤링 창이 사용됩니다. 집계 가능한 새 보고서로 인해 예산이 초과될 경우 보고서가 생성되지 않습니다.
참여 예산은 매개변수 L1로 표시되며, 백스톱이 220 (1,048,576)인 상태에서 하루 10분당 216 (65,536)으로 설정됩니다. 이러한 매개변수에 대한 자세한 내용은 설명을 참고하세요.
기여 예산의 값은 임의이지만 노이즈는 이에 맞게 조정됩니다. 이 예산을 사용하여 요약 값의 신호 대 노이즈 비율을 극대화할 수 있습니다(노이즈 및 크기 조정 섹션에서 자세히 설명).
기여 예산에 대해 자세히 알아보려면 설명을 참고하세요. 자세한 내용은 기여도 예산을 참고하세요.
보고서당 기여도 제한
호출자에 따라 기부 한도가 다를 수 있습니다. 현재 Shared Storage API 호출자에 대해 생성된 보고서는 보고서당 참여도가 20개로 제한됩니다. 반면 Protected Audience API 호출자는 보고서당 100개의 참여로 제한됩니다. 이러한 제한은 삽입할 수 있는 참여 횟수와 페이로드 크기의 균형을 맞추기 위해 선택되었습니다.
공유 저장소의 경우 단일 run() 또는 selectURL() 작업 내에서 이루어진 참여는 하나의 보고서로 일괄 처리됩니다. Protected Audience의 경우 입찰 내 단일 출처에서 제공한 기여도가 함께 일괄 처리됩니다.
패딩이 있는 참여
패딩 기능으로 기여도를 추가로 수정합니다. 페이로드를 패딩하면 집계 가능한 보고서에 삽입된 실제 참여자 수에 관한 정보가 보호됩니다. 패딩은 고정 길이에 도달하기 위해 null 기여(값이 0임)로 페이로드를 보강합니다.
집계 가능한 보고서
사용자가 Private Aggregation API를 호출하면 브라우저는 집계 서비스에서 나중에 처리하여 요약 보고서를 생성할 집계 가능한 보고서를 생성합니다. 집계 가능한 보고서는 JSON 형식이며 각 항목이 {aggregation key, aggregatable value} 쌍인 암호화된 참여 목록을 포함합니다.
집계 가능한 보고서는 최대 1시간의 무작위 지연을 적용하여 전송됩니다.
참여는 암호화되며 집계 서비스 외부에서는 읽을 수 없습니다. 집계 서비스는 보고서를 복호화하고 요약 보고서를 생성합니다. 브라우저의 암호화 키와 집계 서비스의 복호화 키는 키 관리 서비스 역할을 하는 코디네이터에서 발급합니다. 코디네이터는 호출자가 복호화 키를 수신할 수 있는지 확인하기 위해 서비스 이미지의 바이너리 해시 목록을 유지합니다.
디버그 모드가 사용 설정된 집계 가능한 보고서의 예는 다음과 같습니다.
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
집계 가능한 보고서는 chrome://private-aggregation-internals 페이지에서 확인할 수 있습니다.

테스트 목적으로 '선택한 보고서 보내기' 버튼을 사용하여 보고서를 서버로 즉시 전송할 수 있습니다.
집계 가능한 보고서 수집 및 일괄 처리
브라우저는 나열된 잘 알려진 경로를 사용하여 집계 가능한 보고서를 Private Aggregation API 호출이 포함된 워크렛의 출처로 전송합니다.
- 공유 저장소:
/.well-known/private-aggregation/report-shared-storage - Protected Audience의 경우:
/.well-known/private-aggregation/report-protected-audience
이러한 엔드포인트에서는 클라이언트에서 전송된 집계 가능한 보고서를 수신하는 수집기 역할을 하는 서버를 운영해야 합니다.
그런 다음 서버는 보고서를 일괄 처리하여 집계 서비스로 전송해야 합니다. 집계 가능한 보고서의 암호화되지 않은 페이로드(예: shared_info 필드)에 있는 정보를 기반으로 배치를 만듭니다. 배치에 배치당 100개 이상의 보고서가 포함되는 것이 이상적입니다.
매일 또는 매주 일괄 처리할 수 있습니다. 이 전략은 유연하며 볼륨이 더 많을 것으로 예상되는 특정 이벤트(예: 노출수가 더 많을 것으로 예상되는 연중 날짜)에 대한 일괄 처리 전략을 변경할 수 있습니다. 일괄 처리에는 동일한 API 버전, 보고 출처, 보고서 시간 예약의 보고서가 포함되어야 합니다.
ID 필터링
비공개 집계 API 및 집계 서비스를 사용하면 ID를 필터링하여 대규모 쿼리의 결과를 처리하는 대신 광고 캠페인별과 같이 더 세부적인 수준에서 측정값을 처리할 수 있습니다.

지금 바로 이 기능을 사용하려면 다음 단계에 따라 현재 구현에 적용해 보세요.
공유 저장소 단계
흐름에서 Shared Storage API를 사용하는 경우:
새 공유 저장소 모듈을 선언하고 실행할 위치를 정의합니다. 다음 예에서는 모듈 파일의 이름을
filtering-worklet.js로 지정했으며filtering-example에 등록했습니다.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();filteringIdMaxBytes는 보고서별로 구성할 수 있으며 설정하지 않으면 기본값은 1입니다. 이 기본값은 페이로드 크기와 스토리지 및 처리 비용이 불필요하게 증가하는 것을 방지하기 위한 것입니다. 자세한 내용은 유연한 기여 설명을 참고하세요.위에서 사용한 파일(이 경우
filtering-worklet.js)에서 공유 저장소 워크렛 내에서privateAggregation.contributeToHistogram(...)에 참여를 전달할 때 필터링 ID를 지정할 수 있습니다.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);집계 가능한 보고서는 엔드포인트
/.well-known/private-aggregation/report-shared-storage를 정의한 위치로 전송됩니다. ID 필터링 가이드로 이동하여 집계 서비스 작업 매개변수에 필요한 변경사항을 알아보세요.
일괄 처리가 완료되고 배포된 집계 서비스로 전송되면 필터링된 결과가 최종 요약 보고서에 반영됩니다.
Protected Audience 단계
Protected Audience API를 플로우에서 사용하는 경우:
현재 구현된 Protected Audience 내에서 다음을 설정하여 비공개 집계에 연결할 수 있습니다. 공유 저장소와 달리 필터링 ID의 최대 크기는 아직 구성할 수 없습니다. 기본적으로 필터링 ID 최대 크기는 1바이트이며
0n로 설정됩니다. 이는 Protected Audience 보고 함수 (예:reportResult()또는generateBid())에서 설정됩니다.const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);집계 가능한 보고서는 엔드포인트
/.well-known/private-aggregation/report-protected-audience를 정의한 위치로 전송됩니다. 일괄 처리가 완료되고 배포된 집계 서비스로 전송되면 필터링된 결과가 최종 요약 보고서에 반영됩니다. Attribution Reporting API 및 Private Aggregation API에 관한 다음 설명과 초기 제안서를 확인하세요.
집계 서비스에서 ID 필터링 가이드를 계속 진행하거나 Attribution Reporting API 섹션으로 이동하여 자세한 내용을 확인하세요.
Aggregation Service
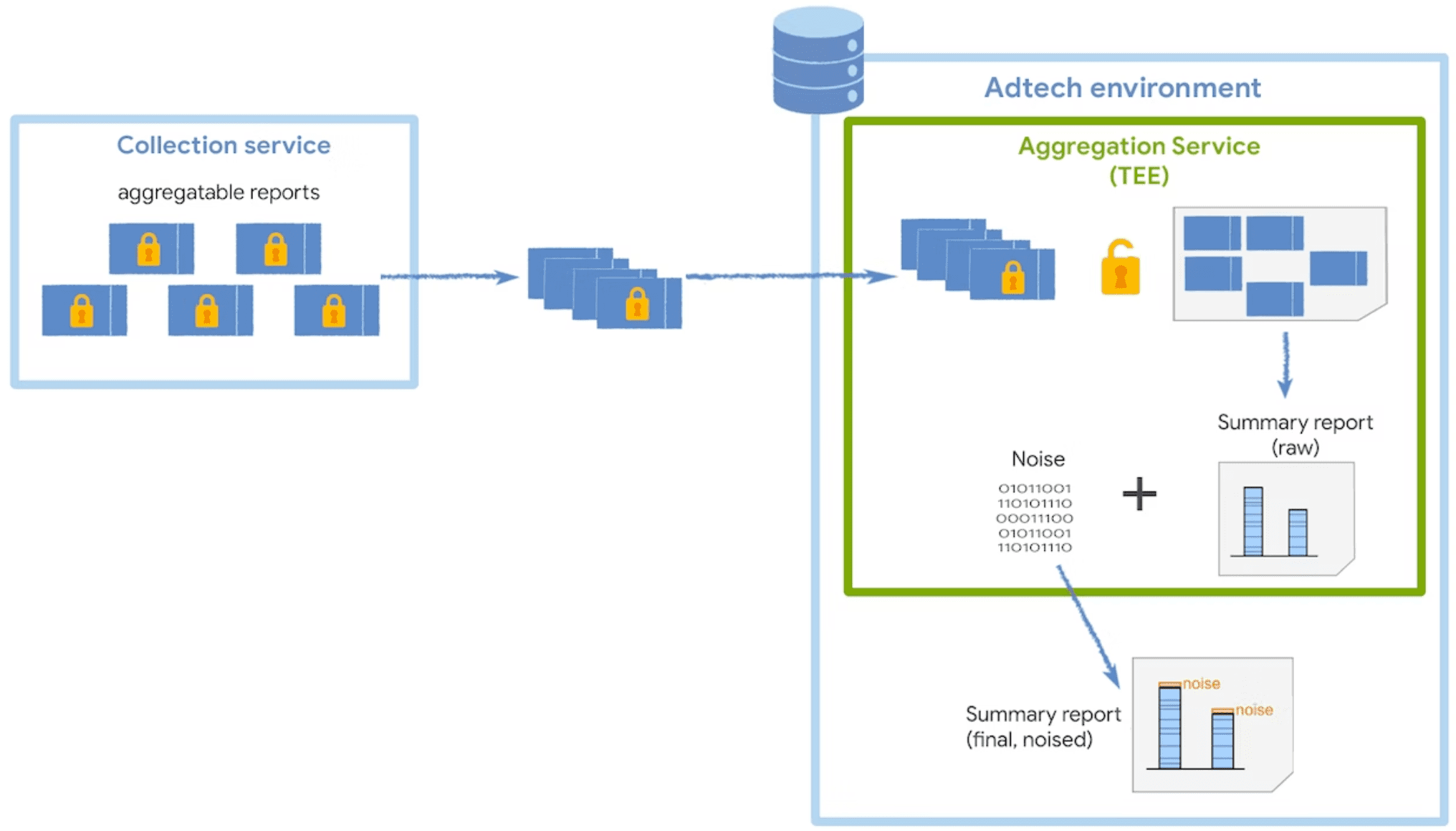
집계 서비스는 수집기에서 암호화된 집계 가능한 보고서를 수신하고 요약 보고서를 생성합니다. 수집기에서 집계 가능한 보고서를 일괄 처리하는 방법에 관한 추가 전략은 일괄 처리 가이드를 참고하세요.
이 서비스는 데이터 무결성, 데이터 기밀성, 코드 무결성에 일정 수준의 보장을 제공하는 신뢰할 수 있는 실행 환경 (TEE)에서 실행됩니다. 코디네이터가 TEE와 함께 사용되는 방식을 자세히 알아보려면 역할 및 목적을 참고하세요.
요약 보고서
요약 보고서를 사용하면 수집한 데이터에 노이즈를 추가하여 확인할 수 있습니다. 지정된 키 집합에 대한 요약 보고서를 요청할 수 있습니다.
요약 보고서에는 JSON 사전 스타일의 키-값 쌍 집합이 포함됩니다. 각 쌍에는 다음이 포함됩니다.
bucket: 집계 키(이진수 문자열)입니다. 사용된 집계 키가 '123'이면 버킷은 '1111011'입니다.value: 가용한 모든 집계 가능한 보고서에서 합산된 특정 측정 목표의 요약 값으로, 노이즈가 추가됩니다.
예를 들면 다음과 같습니다.
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
노이즈 및 확장
사용자 개인 정보를 보호하기 위해 집계 서비스는 요약 보고서가 요청될 때마다 각 요약 값에 노이즈를 한 번 추가합니다. 노이즈 값은 라플라스 확률 분포에서 무작위로 가져옵니다. 노이즈가 추가되는 방식은 직접 제어할 수 없지만 노이즈가 측정 데이터에 미치는 영향은 조절할 수 있습니다.
노이즈 분포는 모든 집계 가능한 값의 합계와 관계없이 동일합니다. 따라서 집계 가능한 값이 클수록 노이즈가 미치는 영향이 줄어듭니다.
예를 들어 노이즈 분포의 표준 편차가 100이고 0을 중심으로 한다고 가정해 보겠습니다. 수집된 집계 가능한 보고서 값 (또는 '집계 가능한 값')이 200개뿐이라면 노이즈의 표준 편차는 집계된 값의 50% 가 됩니다. 하지만 집계 가능한 값이 20,000이면 노이즈의 표준 편차는 집계된 값의 0.5% 에 불과합니다. 따라서 집계 가능한 값 20,000은 신호 대 노이즈 비율이 훨씬 더 높습니다.
따라서 집계 가능한 값에 배율을 곱하면 노이즈를 줄이는 데 도움이 될 수 있습니다. 배율은 집계 가능한 특정 값을 얼마나 확장할지 나타냅니다.

더 큰 배율을 선택하여 값을 확장하면 상대적 노이즈가 줄어듭니다. 하지만 이렇게 하면 모든 버킷의 모든 기부 금액의 합계가 기부 예산 한도에 더 빨리 도달하게 됩니다. 더 작은 크기 배율 상수를 선택하여 값을 축소하면 상대적 노이즈가 증가하지만 예산 한도에 도달할 위험은 줄어듭니다.
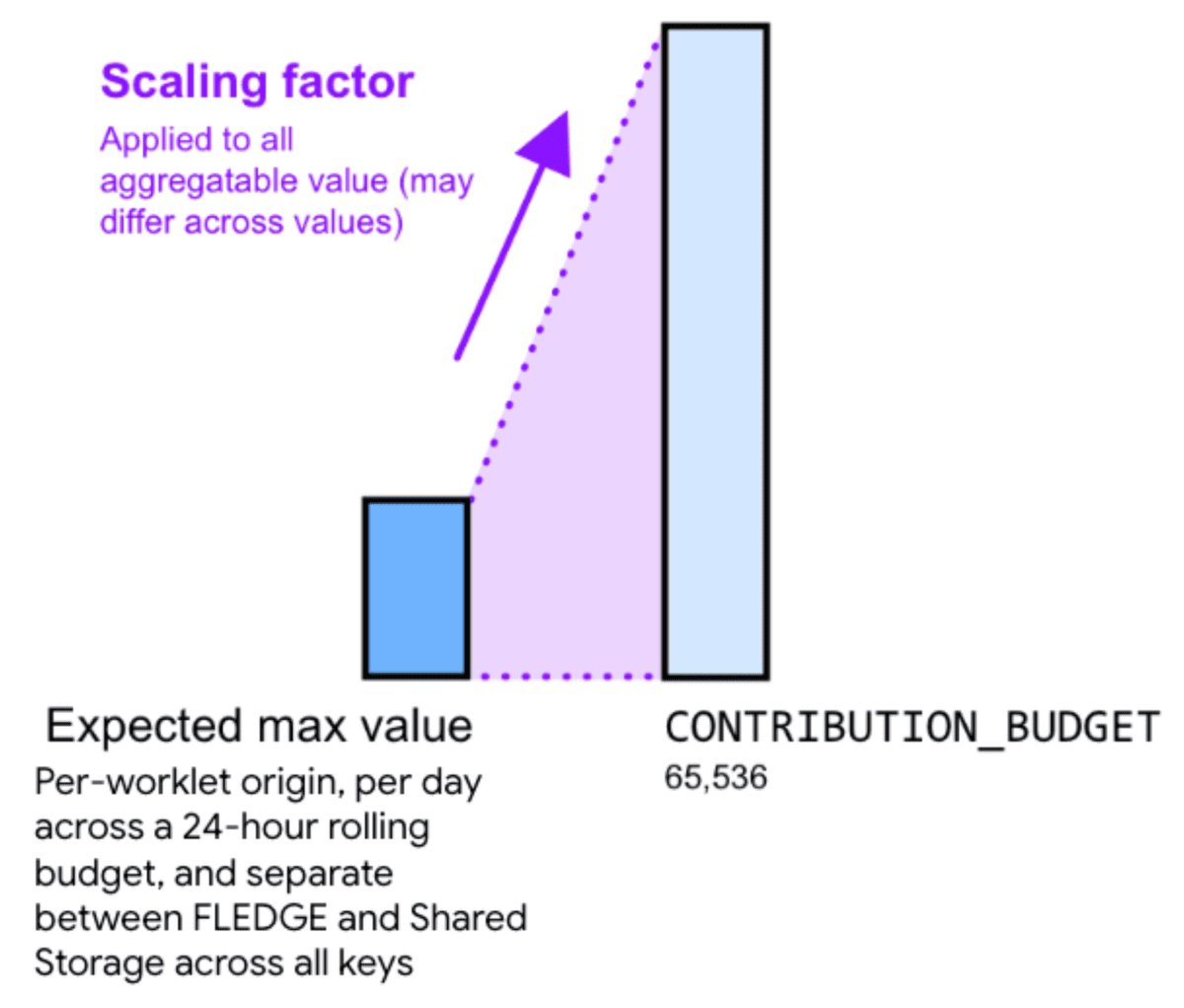
적절한 크기 조정 계수를 계산하려면 기여도 예산을 모든 키에서 집계 가능한 값의 최대 합계로 나눕니다.
자세한 내용은 기여도 예산 문서를 참고하세요.
참여 및 의견 공유
Private Aggregation API는 현재 논의 중이며 향후 변경될 수 있습니다. 이 API를 사용해 보고 의견이 있으시면 알려주세요.
- GitHub: 설명서를 읽고 질문을 하고 토론에 참여하세요.
- 개발자 지원: 개인 정보 보호 샌드박스 개발자 지원 저장소에서 질문을 게시하고 토론에 참여하세요.
- Shared Storage API 그룹 및 Protected Audience API 그룹에 가입하여 비공개 집계와 관련된 최신 공지사항을 확인하세요.