Scopri come lavorare con, tenere conto e ridurre l'impatto del rumore nei report aggregabili.
Prima di iniziare
Prima di procedere, per una comprensione approfondita di cos'è il rumore e del suo impatto, consulta Comprendere il rumore nei report di riepilogo.
Controlli per il rumore
Sebbene non sia possibile controllare direttamente il rumore aggiunto ai report aggregabili, esistono alcune misure che puoi adottare per ridurre al minimo gli effetti. Le seguenti sezioni spiegano queste strategie.
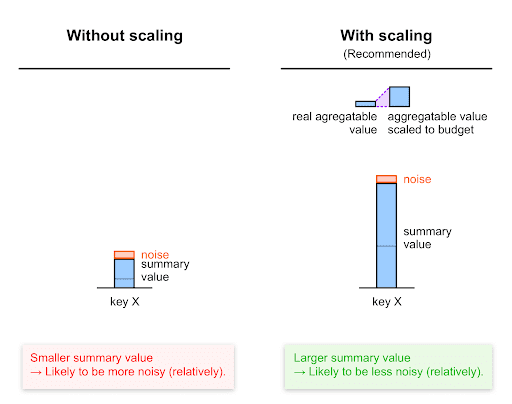
Fai lo scale up fino al budget per il contributo
Come spiegato nella sezione Comprensione del rumore, il rumore applicato al valore di riepilogo per ogni chiave si basa sulla scala da 0 a 65.536 (0-CONTRIBUTION_BUDGET).

Di conseguenza, per massimizzare l'indicatore in relazione al rumore, devi fare lo scale up di ciascun valore prima di impostarlo come valore aggregabile, ovvero moltiplicare ogni valore per un determinato fattore, il fattore di scalabilità, assicurandoti che rimanga entro il budget di contributo.
Calcolo di un fattore di scala
Il fattore di scalabilità rappresenta quanto vuoi scalare un dato valore aggregabile. Il suo valore deve essere il budget per il contributo diviso per il valore massimo aggregabile per una determinata chiave.
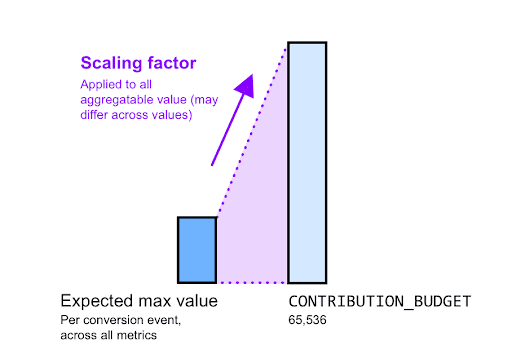
Ad esempio, supponiamo che gli inserzionisti vogliano conoscere il valore di acquisto totale. Sai che il valore massimo di acquisto previsto per ogni acquisto individuale è di 2000 €, ad eccezione di alcuni valori anomali che decidi di ignorare:
- Calcola il fattore di scala:
- .
- Per massimizzare il rapporto tra indicatori e rumore, devi scalare questo valore impostandolo su 65.536 (budget di contributo).
- Ne consegue un fattore di scalabilità di 65.536 / 2000 pari a circa 32x. In pratica, puoi arrotondare questo fattore per eccesso o per difetto.
- Fai lo scale up dei valori prima dell'aggregazione. Per ogni $1 di acquisto, incrementa la metrica monitorata di 32. Ad esempio, per un acquisto di 120$, imposta un valore aggregabile di 120*32 = 3840.
- Fai lo scale down dei valori dopo l'aggregazione. Una volta ricevuto il report di riepilogo contenente il valore di acquisto sommato per più utenti, riduci il valore di riepilogo utilizzando il fattore di scala utilizzato prima dell'aggregazione. Nel nostro esempio, abbiamo utilizzato un fattore di scala pari a 32 per la pre-aggregazione. Pertanto, dobbiamo dividere il valore di riepilogo ricevuto nel report di riepilogo per 32. Pertanto, se il valore di acquisto di riepilogo per una determinata chiave nel report di riepilogo è 76.800, il valore di acquisto di riepilogo (con rumore) è 76.800/32 = 2400 $.
Suddividi il budget
Se hai diversi obiettivi di misurazione, ad esempio conteggio degli acquisti e valore di acquisto, ti consigliamo di suddividere il budget tra questi obiettivi.
In questo caso, i fattori di scalabilità saranno diversi per i diversi valori aggregabili, a seconda del valore massimo previsto di un dato valore aggregabile.
Leggi ulteriori informazioni nella sezione Informazioni sulle chiavi di aggregazione.
Ad esempio, supponiamo che tu stia monitorando sia il numero di acquisti sia il valore di acquisto e che tu decida di allocare il budget in modo uniforme.
65.536 / 2 = 32.768 possono essere assegnati per tipo di misurazione e per sorgente.
- Numero di acquisti:
- Stai monitorando un solo acquisto, pertanto il numero massimo di acquisti per una determinata conversione è 1.
- Pertanto, decidi di impostare il fattore di scala per il conteggio degli acquisti su 32.768 / 1 = 32.768.
- Valore di acquisto:
- Supponiamo che il valore di acquisto massimo previsto per qualsiasi acquisto individuale sia di 2000 €.
- Pertanto, decidi di impostare il fattore di scala per il valore di acquisto su 32.768 / 2000 = 16,384 o circa 16.
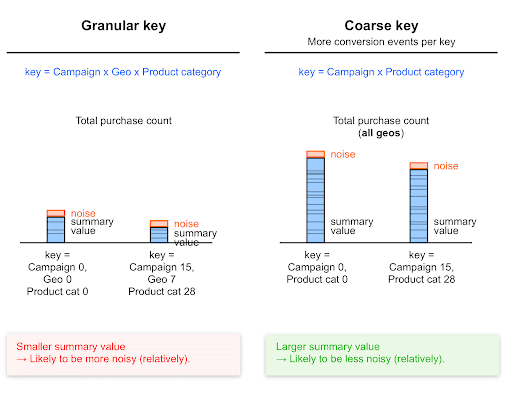
Le chiavi di aggregazione più grosse migliorano il rapporto tra segnale e rumore
Poiché le chiavi generiche rilevano più eventi di conversione rispetto a quelle granulari, di solito generano valori di riepilogo più elevati.
I valori di riepilogo più alti sono meno influenzati dal rumore rispetto ai valori più bassi. il rumore su questi valori è probabilmente più basso rispetto a questo valore.
È probabile che i valori raccolti con chiavi più generiche siano relativamente meno rumorosi rispetto a quelli raccolti con chiavi più granulari.
Esempio
A parità di condizioni, una chiave che monitora il valore di acquisto a livello globale (sommato in tutti i paesi) genererà un valore di acquisto riepilogativo più alto (e un conteggio delle conversioni riepilogativo più alto) rispetto a una chiave che monitora le conversioni a livello di paese.
Di conseguenza, il rumore relativo sul valore di acquisto totale per un paese specifico sarà più elevato rispetto al rumore relativo sul valore di acquisto totale per tutti i paesi.
Analogamente, se rimane uguale, il valore totale di acquisto delle scarpe è inferiore al valore di acquisto totale di tutti gli articoli (scarpe incluse).
Di conseguenza, il rumore relativo sul valore di acquisto totale delle scarpe sarà più elevato rispetto al rumore relativo sul valore di acquisto totale per tutti gli articoli.
La somma dei valori di riepilogo (rollup) ne somma anche il rumore
Sommando i valori di riepilogo dei report di riepilogo per accedere a dati di livello superiore, somma anche il rumore di questi valori di riepilogo.
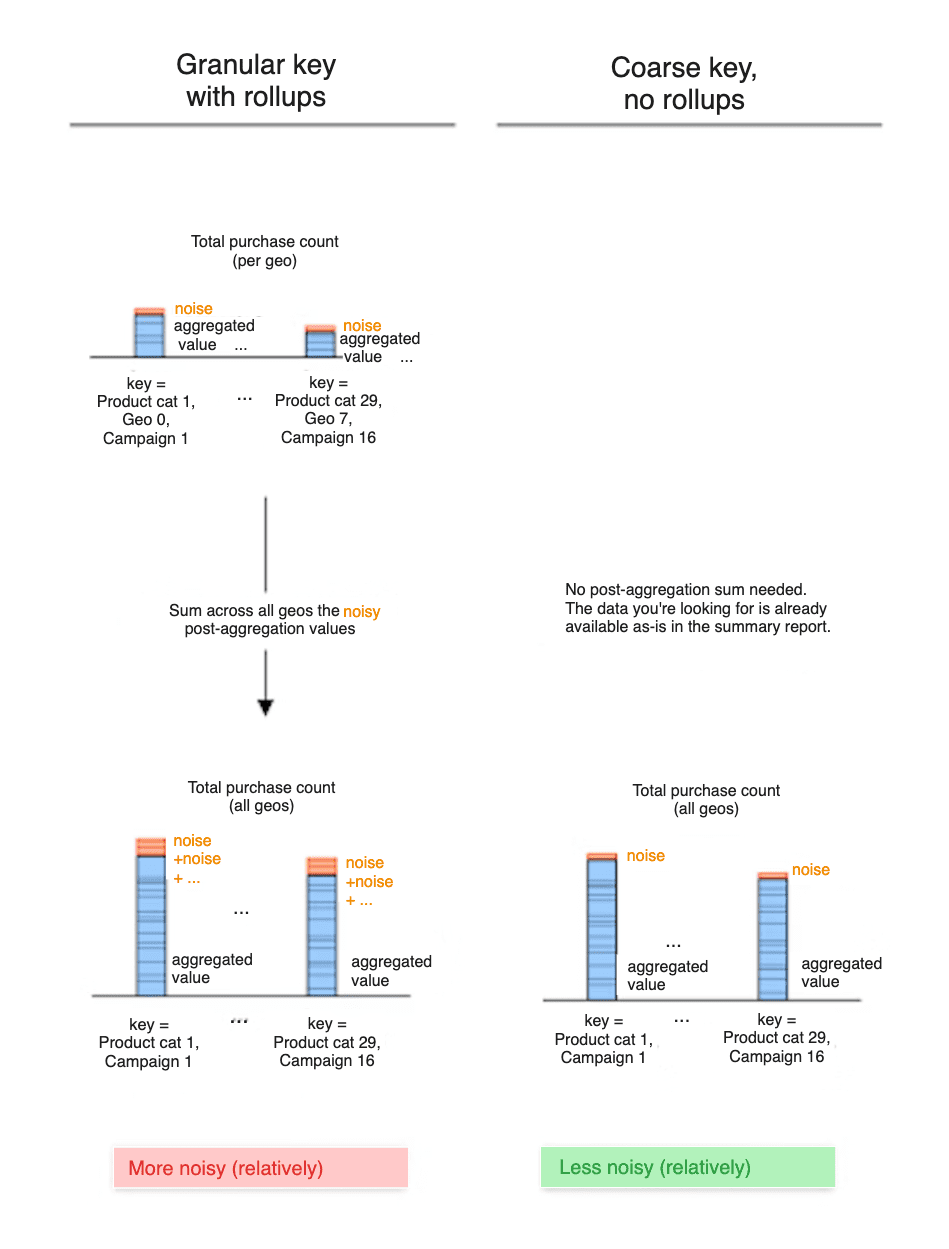
Esaminiamo due diversi approcci: - Approccio A: includi un ID area geografica nelle chiavi. I report di riepilogo espongono le chiavi a livello di ID geografico, ciascuna associata al valore di acquisto di riepilogo a un livello di ID geografico specifico. - Approccio B: non includi l'ID area geografica nelle chiavi. I report di riepilogo mostrano direttamente il valore di acquisto di riepilogo per tutti gli ID / località geografica.
Per accedere al valore di acquisto a livello di paese: - Con l'approccio A, si sommano i valori di riepilogo a livello di ID geografico e, di conseguenza, anche il loro rumore. È probabile che questo causi l'aggiunta di più rumore al valore di acquisto finale a livello di ID geografico. - Con l'approccio B, si esamina direttamente i dati esposti nei report di riepilogo. Il rumore è stato aggiunto una sola volta a quei dati.
Di conseguenza, è probabile che il valore di acquisto riepilogativo per un determinato ID geografico sia più rumoroso con l'approccio A.
Analogamente, è probabile che l'inclusione di una dimensione a livello di codice postale nelle chiavi generi risultati più rumorosi rispetto all'utilizzo di chiavi più generiche con una dimensione a livello di regione.
L'aggregazione in periodi di tempo più lunghi aumenta il rapporto tra indicatori e rumore
Richiedere report di riepilogo con minore frequenza significa che ciascun valore di riepilogo sarà probabilmente superiore rispetto a quando richiedi i report più spesso. è probabile che si verifichino più conversioni in periodi di tempo più lunghi.
Come accennato in precedenza, più alto è il valore di riepilogo, più basso è probabilmente il rumore relativo. Di conseguenza, la richiesta di report di riepilogo con minore frequenza determina un rapporto segnale/rumore più elevato (migliore).
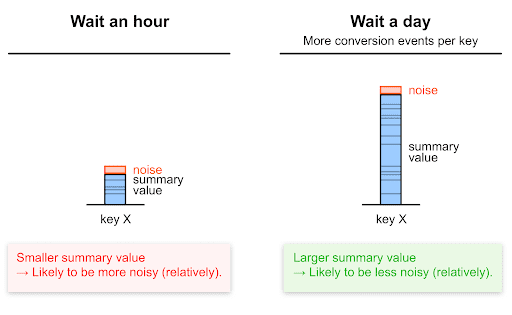
Ecco un esempio per illustrare:
- Se richiedi report di riepilogo orari per 24 ore e poi somma il valore di riepilogo di ogni report orario per accedere ai dati a livello di giorno, il rumore viene aggiunto 24 volte.
- In un report di riepilogo giornaliero, il rumore viene aggiunto solo una volta.
Epsilon maggiore, rumore minore
Più alto è il valore epsilon, più basso è il rumore e minore è la protezione della privacy.
Come utilizzare filtri e deduplicazione
Una parte importante dell'allocazione del budget tra chiavi diverse è capire quante volte può verificarsi un determinato evento. Ad esempio, un inserzionista potrebbe essere interessato a un solo acquisto per ogni clic, ma a un massimo di 3 "visualizzazione di pagina del prodotto". conversioni. Per supportare questi casi d'uso, ti consigliamo inoltre di utilizzare le seguenti funzionalità dell'API che ti consentono di controllare quanti report vengono generati e quali conversioni vengono conteggiate:
- Filtri. Scopri di più sui filtri.
- Deduplicazione. Scopri di più sulla deduplicazione.
Sperimentazione con epsilon
I tecnici pubblicitari possono impostare l'epsilon su un valore maggiore di 0 e fino a 64 inclusi. Questo intervallo consente test flessibili. Valori più bassi di epsilon garantiscono una maggiore protezione della privacy. Ti consigliamo di iniziare con epsilon=10.
Consigli per l'esperimento
Ti consigliamo quanto segue: - Inizia con epsilon = 10. - Nel caso in cui ciò causi notevoli problemi di utilità, aumenta l'epsilon in modo incrementale. - Condividi il tuo feedback su punti di svolta specifici che potresti riscontrare in merito all'usabilità dei dati.
Interagisci e condividi il tuo feedback
Puoi partecipare e sperimentare con questa API.
- Scopri di più sui report aggregabili e sul servizio di aggregazione, fai domande e suggerisci feedback.
- Leggi le guide ai report sull'attribuzione.
- Fai domande e partecipa alle discussioni nel repository dell'assistenza per gli sviluppatori Privacy Sandbox.
Passaggi successivi
- Per ulteriori informazioni sui fattori che influenzano i report, ad esempio variabili di campagna, frequenza dei batch e granularità delle dimensioni, consulta Sperimentare le decisioni di progettazione dei report di riepilogo .
- Prova Noise Lab.