집계 가능한 보고서에서 노이즈를 처리하고, 이러한 요인을 반영하고, 그 영향을 줄이는 방법을 알아보세요.
시작하기 전에
계속하기 전에 노이즈의 정의와 영향을 자세히 알아보려면 요약 보고서의 노이즈 이해하기를 참고하세요.
소음 제어
집계 가능한 보고서에 추가되는 노이즈를 직접 제어할 수는 없지만, 영향을 최소화하기 위해 취할 수 있는 몇 가지 조치가 있습니다. 다음 섹션에서는 이러한 전략을 설명합니다.
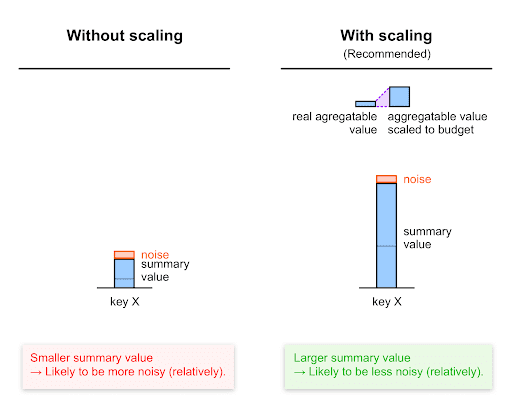
참여 예산에 맞게 확장
노이즈 이해에서 설명한 것처럼 각 키의 요약 값에 적용된 노이즈는 0~65,536 척도 (0~CONTRIBUTION_BUDGET)를 기반으로 합니다.

따라서 노이즈와 비교하여 신호를 최대화하려면 집계 가능한 값으로 설정하기 전에 각 값을 확장해야 합니다. 즉, 기여 예산을 초과하지 않으면서 각 값에 특정 요소인 조정 계수를 곱해야 합니다.
배율 계산
배율은 주어진 집계 가능한 값을 조정할 정도를 나타냅니다. 이 값은 기여 예산을 특정 키의 집계 가능한 최대 값으로 나눈 값이어야 합니다.
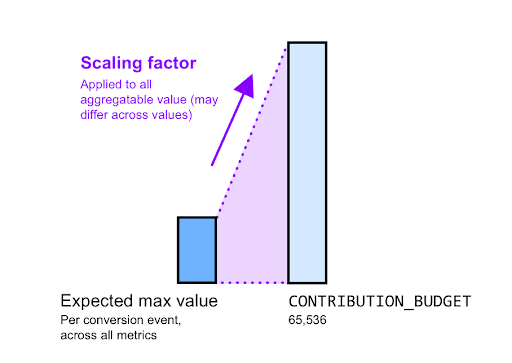
예를 들어 광고주가 총 구매 가치를 알고 싶어 한다고 가정해 보겠습니다. 이때 무시하기로 결정한 몇 가지 이상점을 제외하고 모든 개별 구매의 최대 예상 구매 가치는 $2,000라는 것을 알고 있습니다.
- 배율 조정 계수를 계산합니다.
<ph type="x-smartling-placeholder">
- </ph>
- 신호 대 잡음비를 최대화하려면 이 값을 65,536 (기여 예산)으로 조정해야 합니다.
- 결과적으로 약 32x 배율이 65,536 / 2,000이 됩니다. 실제로는 이 계수를 반올림하거나 줄일 수 있습니다.
- 집계 전에 값을 확대합니다. 구매가 1, 000원할 때마다 추적되는 측정항목을 32씩 증가시킵니다. 예를 들어 구매 금액이 120,000원인 경우 집계 가능한 값으로 120*32 = 3,840을 설정합니다.
- 집계 후 값을 축소합니다. 여러 사용자로부터 합산된 구매 가치가 포함된 요약 보고서를 받으면 집계 전에 사용한 배율을 사용하여 요약 값을 축소합니다. 이 예에서는 32의 사전 집계 배율을 사용했으므로 요약 보고서에 수신된 요약 값을 32로 나누어야 합니다. 따라서 요약 보고서에 있는 특정 키의 요약 구매 가치가 76,800이면 요약 구매 가치 (노이즈 포함)는 76,800/32 = $2,400입니다.
예산 분할
여러 측정 목표(예: 구매 횟수, 구매 가치)가 있는 경우 이러한 목표 간에 예산을 분할할 수 있습니다.
이 경우 배율은 특정 집계 가능한 값의 예상 최댓값에 따라 집계 가능한 값마다 달라집니다.
자세한 내용은 집계 키 이해를 참고하세요.
예를 들어 구매 횟수와 구매 가치를 모두 추적하고 있고 예산을 균등하게 할당한다고 가정해 보겠습니다.
측정 유형 및 소스당 65,536 / 2 = 32,768이 할당될 수 있습니다.
- 구매 수:
<ph type="x-smartling-placeholder">
- </ph>
- 하나의 구매만 추적하고 있으므로 특정 전환 1회의 최대 구매 횟수는 1회입니다.
- 따라서 구매 수의 배율을 32,768 / 1 = 32,768로 설정하기로 합니다.
- 구매 가치:
<ph type="x-smartling-placeholder">
- </ph>
- 개별 구매의 최대 예상 구매 가치가 2,000달러라고 가정해 보겠습니다.
- 따라서 구매 가치의 배율을 32,768 / 2,000 = 16.384 또는 약 16으로 설정하기로 합니다.
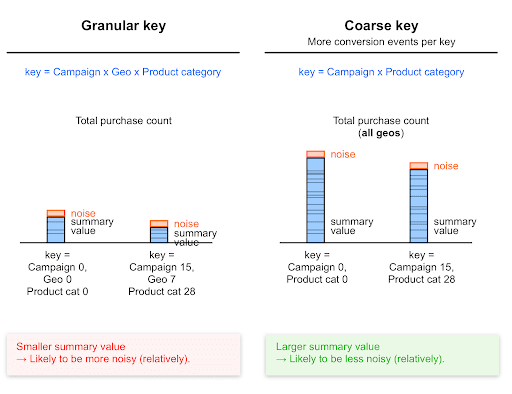
더 넓은 집계 키로 신호 대 잡음비 개선
대략적인 키는 세분화된 키보다 더 많은 전환 이벤트를 포착하므로 일반적으로 대략적인 키는 요약 값이 더 높습니다.
요약 값이 클수록 낮은 값보다 노이즈의 영향을 덜 받습니다. 노이즈가 이 값에 비해 상대적으로 낮을 가능성이 높습니다.
대략적인 키로 수집된 값은 보다 세분화된 키로 수집된 값보다 노이즈가 비교적 적을 수 있습니다.
예
다른 모든 조건이 동일하게 유지되고, 전 세계적으로 구매 가치를 추적하는 키(모든 국가에서 합산)를 사용하면 국가 수준에서 전환을 추적하는 키보다 요약 구매 가치가 더 높아지고 요약 전환수도 더 높아집니다.
따라서 특정 국가의 총 구매 가치에 미치는 상대적인 노이즈가 모든 국가의 총 구매 가치에 미치는 상대적인 노이즈보다 높습니다.
마찬가지로 신발의 총 구매 가치는 신발을 포함한 모든 상품의 총 구매 가치보다 낮습니다.
따라서 신발의 총 구매 가치에 미치는 상대적인 노이즈는 모든 상품의 총 구매 가치에 미치는 상대적인 노이즈보다 높습니다.
요약 값 (롤업)을 합산하면 노이즈도 합산됩니다.
상위 수준의 데이터에 액세스하기 위해 요약 보고서의 요약 값을 합산하면 이러한 요약 값의 노이즈도 합산합니다.
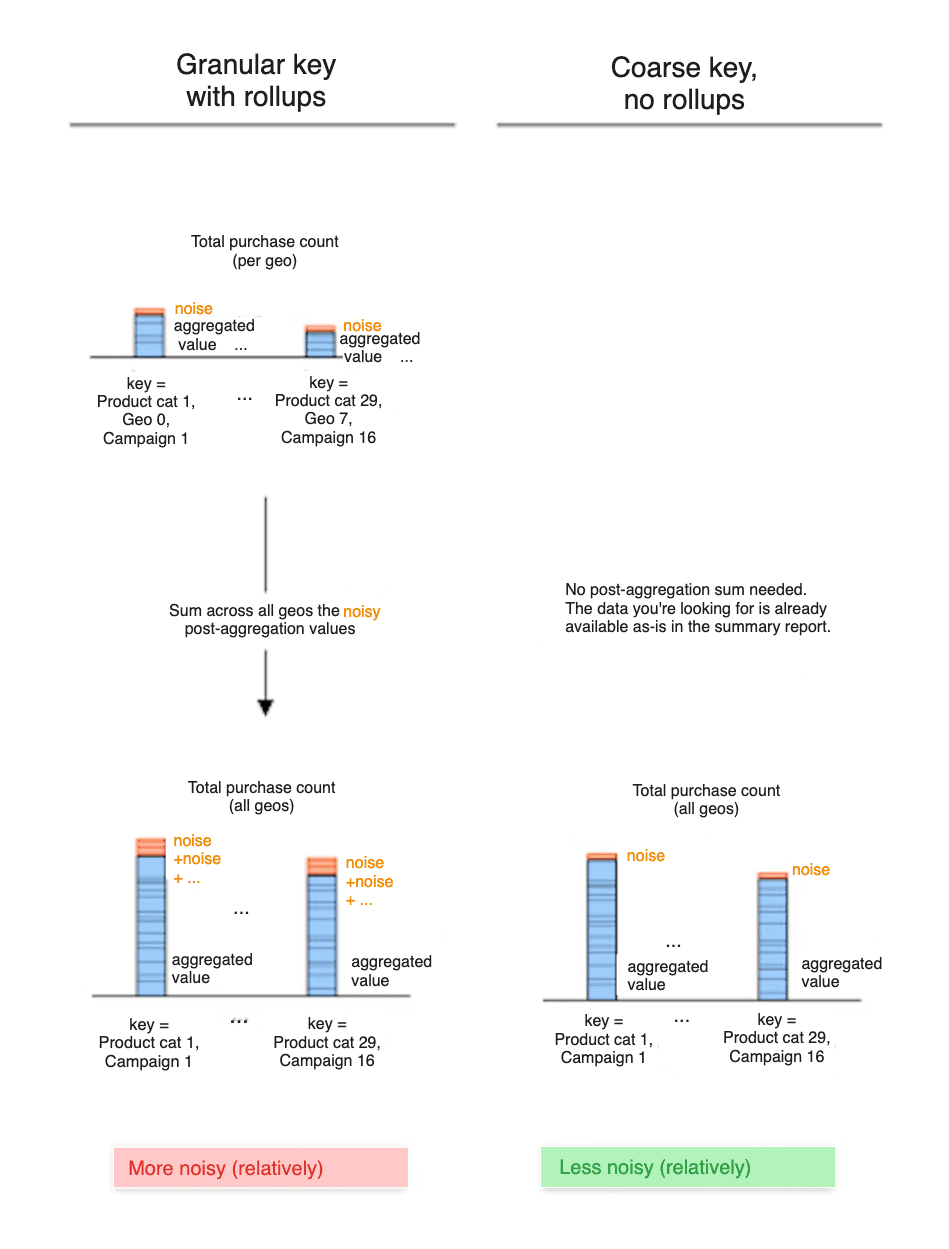
두 가지 접근 방식을 살펴보겠습니다. - 접근 방식 A: 키에 지역 ID를 포함합니다. 요약 보고서에는 지역 ID 수준의 키가 표시되며, 각 키는 특정 지역 ID 수준에서 요약 구매 가치와 연결됩니다. - 접근 방법 B: 키에 지역 ID를 포함하지 않습니다. 요약 보고서에는 모든 지역 ID / 위치의 요약 구매 가치가 직접 표시됩니다.
국가 수준 구매 가치에 액세스하는 방법은 다음과 같습니다. - 접근 방식 A에서는 지역 ID 수준 요약 값과 노이즈도 합산합니다. 이로 인해 최종 지역 ID 수준 구매 가치에 더 많은 노이즈가 추가될 수 있습니다. - 접근 방식 B에서는 요약 보고서에 노출된 데이터를 직접 살펴봅니다. 노이즈가 해당 데이터에 한 번만 추가되었습니다.
따라서 특정 지역 ID의 구매 요약 값은 접근 방식 A에서 더 노이즈가 클 수 있습니다.
마찬가지로 키에 우편번호 수준 측정기준을 포함하면 지역 수준 측정기준과 함께 대략적인 키를 사용하는 것보다 노이즈가 더 많은 결과가 발생할 수 있습니다.
더 오랜 기간에 걸쳐 집계하면 신호 대 잡음비가 증가
요약 보고서 요청 빈도가 낮다는 것은 각 요약 값이 보고서를 더 자주 요청한 경우보다 높을 가능성이 크다는 의미입니다. 장기간에 걸쳐 더 많은 전환이 발생할 가능성이 큼
앞서 언급했듯이 요약 값이 높을수록 상대적 노이즈가 낮아질 가능성이 높습니다. 따라서 요약 보고서 요청 빈도가 줄면 신호 대 잡음 비율이 높아집니다.
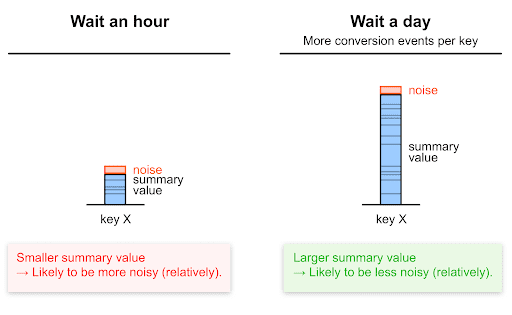
다음 예를 참고하세요.
- 24시간 동안 시간별 요약 보고서를 요청한 다음 각 시간별 보고서의 요약 값을 합산하여 일별 데이터에 액세스하는 경우 노이즈가 24번 추가됩니다.
- 일일 요약 보고서 하나에 노이즈는 한 번만 추가됩니다.
높은 엡실론, 낮은 노이즈
엡실론 값이 높을수록 노이즈가 낮아지고 개인 정보 보호 기능이 낮아집니다.
필터링 및 중복 삭제 활용
여러 키 간에 예산을 할당할 때 특정 이벤트가 발생할 수 있는 횟수를 이해하는 것이 중요합니다. 예를 들어 광고주는 클릭당 한 번의 구매에만 관심이 있지만 '제품 페이지 조회'를 최대 3회까지는 관심이 있을 수 있습니다. 전환 이러한 사용 사례를 지원하려면 생성되는 보고서 수와 집계되는 전환을 제어할 수 있는 다음 API 기능을 활용할 수도 있습니다.
- 필터링. 필터링에 대해 자세히 알아보기
- 중복 삭제. 중복 삭제에 대해 자세히 알아보기
엡실론 실험
광고 기술은 엡실론을 0보다 크고 64 이하의 값으로 설정할 수 있습니다. 이 범위는 유연한 테스트를 허용합니다. 엡실론 값이 낮을수록 개인 정보 보호 기능이 강화됩니다. 엡실론=10으로 시작하는 것이 좋습니다.
실험할 추천
다음 조치를 취하는 것이 좋습니다. - 엡실론 = 10으로 시작합니다. - 이로 인해 중요한 유틸리티 문제가 발생하는 경우 엡실론을 점진적으로 늘립니다. - 데이터 사용성과 관련된 특정 변곡점에 대한 의견을 공유해 주세요.
Engage and share feedback
You can participate and experiment with this API.
- Read about aggregatable reports and the aggregation service, ask questions, and suggest feedback.
- Read the Attribution reporting guides.
- Ask questions and join discussions on the Privacy Sandbox Developer Support repo.
다음 단계
- 캠페인 변수, 일괄 처리 빈도, 측정기준 세부사항과 같이 보고에 영향을 주는 요소에 대한 자세한 내용은 요약 보고서 설계 결정 실험을 참고하세요 .
- 노이즈 실험실을 사용해 보세요.