关于此文档
阅读本文档后,您将:
- 在生成摘要报告之前,了解要创建哪些策略。
- 了解 Noise Lab,此工具有助于了解各种噪声参数的影响,并让您能够快速探索和评估各种噪声管理策略。
欢迎分享反馈
尽管本文档总结了使用摘要报告的几条原则, 有多种噪声管理方法可能未得到体现 此处。欢迎您提出建议、添加内容和问题!
- 若要针对噪音管理策略提供公开反馈,请启用 API (epsilon) 的实用程序或隐私性,并在 使用 Noise Lab 进行模拟: 对此问题发表评论
- 提供有关 Noise Lab 的公开反馈(提出问题、报告 bug、 请求功能): 在此处创建新问题
- 如需就 API 的其他方面提供公开反馈,请执行以下操作: 在此处创建新问题
前期准备
- 请参阅 Attribution Reporting:摘要报告和 Attribution Reporting 完整的系统概览,了解相关介绍。
- 阅读了解噪声和了解汇总键,以充分利用本指南。
设计决策
核心设计原则
第三方 Cookie 与摘要报告的运作方式存在根本性差异。其中一个关键区别在于 向摘要报告中的衡量数据添加噪声。另一个是报告安排时间的方式。
访问信噪比较高的衡量摘要报告衡量数据 需求方平台 (DSP) 和广告衡量服务提供商都需要 与广告主合作制定噪声管理策略。要制定这些策略,DSP 和衡量服务提供商需要做出设计决策。这些决策围绕一个基本概念:
虽然分布噪声值是根据 2 个参数提取的,但实际上只取决于 2 个参数 ⏤epsilon 和贡献预算 ⏤ 您手头还有其他一些控制因素会影响 信噪比。
虽然我们期望一个迭代过程能做出最佳决策,但这些决策的每个变体都会 所导致的实现方式略有不同,因此,您必须在每次编写代码迭代(以及投放广告之前)做出这些决策。
决策:维度粒度
在 Noise Lab 中试用
- 进入高级模式。
- 在“参数”侧边栏中,找到“您的转化数据”。
- 观察默认参数。默认情况下,每日总计 TOTAL 可归因转化次数为 1000 次。平均每个区域大约有 40 个 (默认维度、默认数量 每个维度可能具有不同的值,即键策略 A)。请注意 输入的平均每日可归因转化次数为 40 每个存储分区。
- 点击“模拟”可使用默认参数运行模拟。
- 在“参数”侧边栏中,查找“维度”。重命名 地理位置更改为城市,然后将可能的不同值的数量更改为 50。
- 观察这会如何改变每日可归因的平均转化次数 每个存储分区的数量。现在它的音量要低得多了。这是因为,如果您提高 此维度中可能值的数量(不更改) 您可以增加存储分区的总数, 每个类别包含的转化事件数量。
- 点击“模拟”。
- 观察生成的模拟的噪声比:噪声比 现在高于上一次模拟。
根据核心设计原则,小摘要值很可能会 会比较大的汇总值更加嘈杂。因此,您的配置选择 会影响每个存储分区中最终归因的转化事件数量(否则 称为汇总键),而该数量会影响 最终输出摘要报告。
一项设计决策会影响归因的转化事件的数量 即维度粒度请参考以下示例 汇总键及其维度:
- 方法 1:采用一个包含粗略维度的关键结构:国家/地区 x 广告系列(或规模最大的广告系列) 汇总分区)x 产品类型(共 10 个可能的产品类型)
- 方法 2:采用一种具有精细尺寸的关键结构:城市 x 广告素材 ID x 产品(共 100 个可能的产品)
“城市”是一个比“国家/地区”更精细的维度;广告素材 ID 更为细化 而不是 Campaign;Product 比 Product type 更精细。因此, 方法 2 的每个存储分区的事件(转化)数量较少(= 键),而不是方法 1。鉴于添加到噪声的噪声 输出与存储分区中的事件数量无关,衡量数据 报告采用方法 2 时会产生更大的干扰。针对每个广告客户,尝试不同的 权衡密钥的设计,以便在 结果。
决策:关键结构
在 Noise Lab 中试用
在简单模式下,将使用默认键结构。在“高级”中 模式下,您可以尝试不同的关键结构。一些示例维度 包括也可以修改这些内容
- 进入高级模式。
- 在“参数”侧边栏中,查找“关键策略”。观察 默认策略(在工具中名为 A)使用一个精细的键 包含所有维度的结构:地理位置 x 广告系列 ID x 产品 类别。
- 点击“模拟”。
- 观察生成的模拟的噪声比。
- 将密钥策略更改为 B。这会显示额外的控件 供您配置密钥结构。
- 配置密钥结构,例如如下所示:
<ph type="x-smartling-placeholder">
- </ph>
- 密钥结构数量:2
- 关键结构 1 = 地理位置 x 产品类别。
- 关键结构 2 = 广告系列 ID x 产品类别。
- 点击“模拟”。
- 您会发现,对于每种衡量目标类型,您现在会获得两份摘要报告 (两个代表购买次数,两个代表购买价值),假设您使用的是 两种不同的键结构。观察它们的噪声比率。
- 您也可以尝试使用自己的自定义维度执行此操作。为此,请查看 选择要跟踪的数据:维度。请考虑移除该示例 以及使用“添加/删除/重置”选项创建您自己的 按钮。
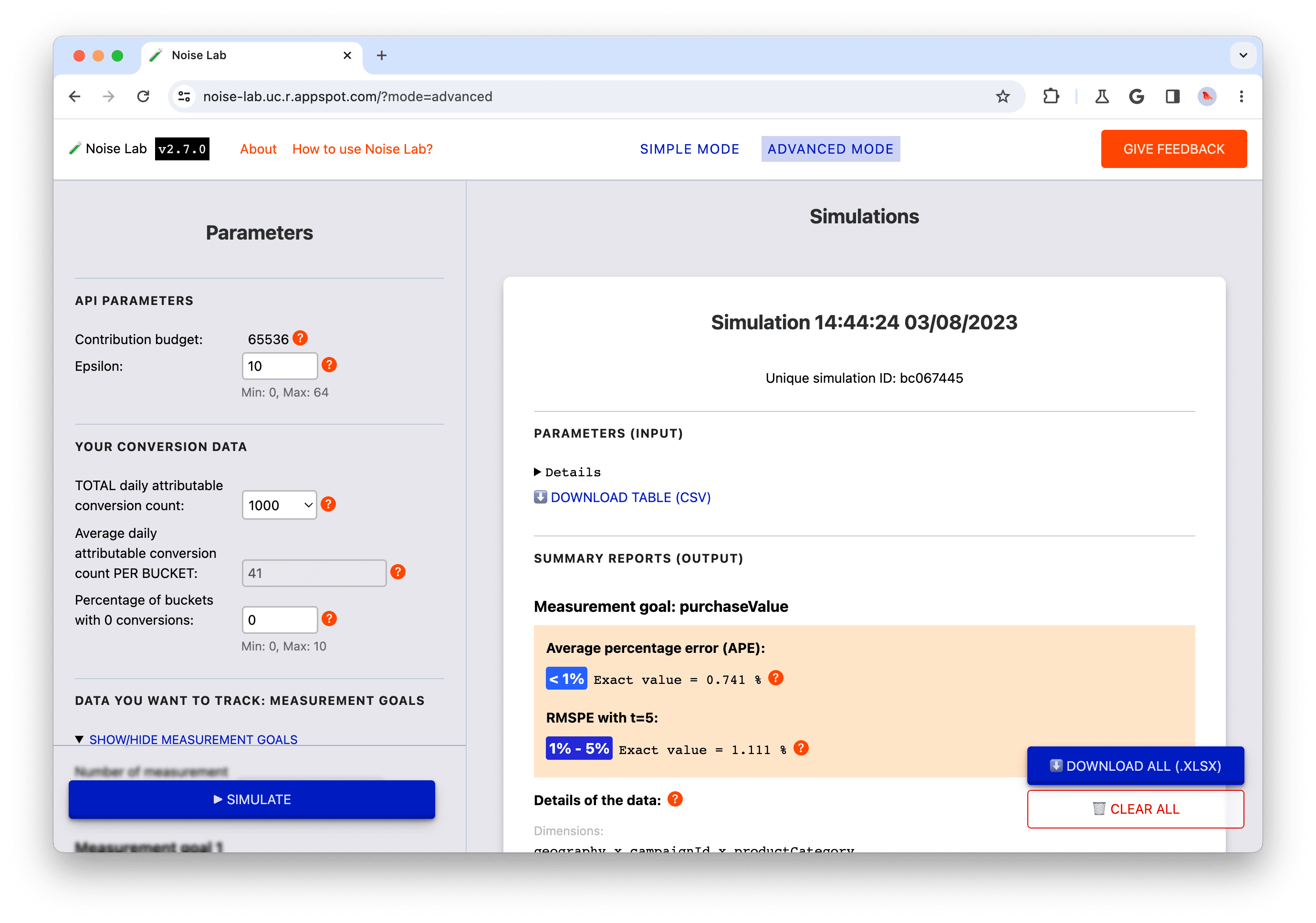
另一个会影响归因转化次数的设计决策 单个存储分区中的事件 关键结构 。请考虑以下汇总键示例:
- 一种包含所有维度的关键结构;我们把这个称为“关键策略 A”
- 两个关键结构,每个结构都有一部分维度;我们把它命名为 关键策略 B.
策略 A 更简单,但您可能需要汇总(求和)包含摘要报告的噪声摘要值,以获取某些数据洞见。通过对这些值求和,您也可以对噪声进行求和。 使用策略 B 时,摘要中显示的摘要值 报告或许已经为您提供了所需信息。也就是说,策略 B 可能会带来比策略 A 更高的信噪比。不过, 策略 A 也许已经可以接受噪声,因此,您还是可能会决定 策略 A 简洁。 如需了解详情,请参阅简要介绍这两种策略的详细示例。
密钥管理是一个深层次的主题。一些复杂的分析法 旨在改善信噪比。高级键 管理。
决策:批处理频率
在 Noise Lab 中试用
- 选择简单模式(或高级模式 - 这两种模式都会启用 处理数据的方式)
- 在“参数”侧边栏中,找到“汇总策略 >”批处理频率。这指的是 使用汇总服务处理的可汇总报告, 单个作业。
- 观察默认的批处理频率:默认情况下,每天批处理一次 只是模拟的频率
- 点击“模拟”。
- 观察生成的模拟的噪声比。
- 将批处理频率更改为每周一次。
- 观察生成的模拟的噪声比:噪声比 现在比之前的模拟结果更低(更好)。
另一个会影响归因转化次数的设计决策 您决定使用的批处理频率。通过 批处理频率是指处理可汇总报告的频率。
按计划更频繁地汇总(例如每小时)的报告将 包含的转化事件数少于同一报告包含的转化事件数,但频率较低 汇总时间表(例如每周)。因此,每小时报告中将包含更多噪声。``` 包含的转化事件数少于同一报告包含的转化事件数,但频率较低 汇总时间表(例如每周)。因此,每小时报告中的 在所有其他条件相同的情况下,信噪比低于每周报告。试验不同频率的报告要求,并评估每种频率的信噪比。
如需了解详情,请访问 批处理 以及汇总较长时间段内的数据。
决策:影响可归因转化的广告系列变量
在 Noise Lab 中试用
虽然这可能很难预测, 除季节性变化外,也可以尝试估算每天 归因于单接触点转化的 10 次方、100、100、 1,000 或 10,000。
- 进入高级模式。
- 在“参数”侧边栏中,找到“您的转化数据”。
- 观察默认参数。默认情况下,每日总计 TOTAL 可归因转化次数为 1000 次。平均每个区域大约有 40 个 (默认维度、默认数量 每个维度可能具有不同的值,即键策略 A)。请注意 输入的平均每日可归因转化次数为 40 每个存储分区。
- 点击“模拟”可使用默认参数运行模拟。
- 观察生成的模拟的噪声比。
- 现在,将每日可归因转化次数总计设置为 100。 您会发现这会降低平均每日可归因值 每个存储分区的转化次数。
- 点击“模拟”。
- 您会发现噪声比现在更高了:这是因为当您 每个类别的转化次数减少,应用更多噪声来维持 保护隐私。
二者的一个重要区别在于,一个转化操作可能获得的 与可能的已归因转化的总数进行比较。通过 后者才是最终影响摘要报告中的干扰因素。已归因 转化次数是广告系列总体转化数据的一部分 变量,例如广告预算和广告定位。例如,您应该会认为 与价值 1 万美元的广告相比,价值 1000 万美元的广告系列的归因转化次数增幅 其他条件均相同
要考虑的事项:
- 针对单一触摸、同一设备评估已归因的转化 归因模型,因为它们在摘要报告的范围内 通过 Attribution Reporting API 收集的。
- 同时考虑最坏情况数量和最佳情况数量 了解已归因的转化例如,在所有其他条件均相同的情况下 广告客户可能达到的最低和最高广告系列预算, 将这两种成效的可归因转化作为输入数据 模拟。
- 如果您正在考虑使用 Android Privacy Sandbox, 在计算时考虑跨平台归因的转化次数。
决策:使用缩放
在 Noise Lab 中试用
- 进入高级模式。
- 在“参数”侧边栏中,找到“汇总策略 >”扩缩。默认情况下,该值设置为“是”。
- 为了了解扩缩对噪声的积极影响 则首先将“缩放比例”设置为“否”。
- 点击“模拟”。
- 观察生成的模拟的噪声比。
- 将“扩缩”设置为“是”。请注意,Noise Lab 会自动计算 要在给定值范围(平均值和最大值)中使用的缩放系数, 您的场景的衡量目标。在真实系统或源试用中 设置,那么您可以自行实现缩放比例的计算。
- 点击“模拟”。
- 您会发现,在这一秒内,噪声比现在更低(更好) 模拟。这是因为您使用的是扩缩功能。
根据核心设计原则,添加的噪声为 是贡献预算的函数
因此,要提高信噪比,您可以决定将 调整在转化事件期间收集的价值,具体方法为根据 贡献预算(并在汇总后取消按比例调整)。使用缩放功能提高信噪比。
决策:衡量目标的数量,以及隐私保护预算分配
这涉及扩缩;请务必阅读使用 扩缩能力。
在 Noise Lab 中试用
衡量目标是在转化事件中收集的不同数据点。
- 进入高级模式。
- 在“参数”侧边栏中,查找要跟踪的数据: 衡量目标。默认情况下,您有两个衡量目标:购买 价值和购买次数
- 点击“模拟”可使用默认目标运行模拟。
- 点击“移除”。这将移除最后一个衡量目标(购买 数量)。
- 点击“模拟”。
- 您会发现,购买价值的噪声比现在较低 (更好)进行第二次模拟。这是因为 因此您只需一个衡量目标 捐赠预算。
- 点击“重置”。现在,您同样有两个衡量目标:购买 价值和购买次数请注意,Noise Lab 会自动计算 给定参数中要指定的范围(平均值和最大值), 衡量目标。默认情况下,Noise Lab 将 为各个衡量目标平均分配预算。
- 点击“模拟”。
- 观察生成的模拟的噪声比。请注意 模拟中显示的缩放比例。
- 现在,我们来自定义隐私预算分配, 信噪比。
- 调整为每个衡量目标指定的预算百分比。给定默认值 衡量目标 1(即购买价值)在转化价值方面的 比衡量目标 2 的范围更宽(0 到 1000 之间),即 购买次数(介于 1 到 1 之间,即始终等于 1)。由于 那么它需要“更多可扩缩的空间”:分配更多空间 为衡量目标 1 贡献的预算,而非为衡量目标 2 贡献预算, 可以更高效地进行扩容(请参阅“扩缩”),因此
- 为效果衡量目标 1 分配 70% 的预算。为效果衡量解决方案分配 30% 的功劳 目标 2。
- 点击“模拟”。
- 观察生成的模拟的噪声比。购买 值,现在噪声比明显低于(优于)之前的 模拟。在购买次数方面,它们大致没有变化。
- 不断调整各指标的预算分配比例。观察这会带来怎样的影响 噪声。
请注意,您可以使用 添加/删除/重置按钮。
如果您针对转化事件衡量一个数据点(衡量目标),例如 转化次数,则该数据点可获取所有贡献预算 (65536)。如果您为一个转化事件设置了多个衡量目标, 例如转化次数和购买价值,那么这些数据点 共享捐赠预算。也就是说,您有更多空间 值。
因此,您设定的衡量目标越多,信噪比越低。 (噪声较高)。
关于衡量目标的另一个决定是预算分配。如果您将捐赠预算平均分配给两个数据点,则每个数据点都会获得 预算为 65536/2 = 32768。这可能不是最佳选择,具体取决于 最大可能的值。例如,如果您要衡量 购买次数,上限为 1,购买价值为 最小值为 1 到 120, “更多空间”扩大广告资源的覆盖范围 捐赠预算。您会看到是否应优先考虑某些衡量目标 以及噪声带来的影响。
决策:离群值管理
在 Noise Lab 中试用
衡量目标是在转化事件中收集的不同数据点。
- 进入高级模式。
- 在“参数”侧边栏中,找到“汇总策略 >”扩缩。
- 确保“扩缩”设置为“是”。请注意,Noise Lab 根据 v2 中的 为衡量目标指定的范围(平均值和最大值)。
- 假设有史以来金额最大的购买金额为 2, 000 美元,但 多数购买行为的支出在 10 美元到 120 美元之间首先,我们来看看会出现什么情况 如果我们使用字面值扩展方法(不推荐):输入 $2000 作为 purchaseValue 的最大价值。
- 点击“模拟”。
- 您会发现噪声比率较高。这是因为 系数目前的计算依据是 2000 美元,但事实上 购买价值明显低于该金额。
- 现在,我们来使用更实用的扩缩方法。更改最大值 最高 120 美元
- 点击“模拟”。
- 您会发现,在第二次模拟中,噪声比较低(更好)。
要实施缩放,您通常需要根据 指定转化事件的可能价值上限 (点击此处了解详情)。
不过,应避免使用字面量最大值来计算该缩放比例, 因为这会加大你的信噪比取而代之的是,移除离群值 请使用切实可行的最大值。
离群值管理是一个深层次的主题。一些复杂的分析法 旨在改善信噪比。相关说明见 高级离群值管理。
后续步骤
现在,您已经为自己的用例评估了各种噪声管理策略, 您就可以开始试验摘要报告了 衡量数据。查看有关试用此 API 的指南和提示。
附录
Noise Lab 快速导览
Noise Lab 助您快速上手 评估和比较噪声管理策略。该模型可用于:
- 了解可能影响噪声的主要参数,以及 会造成的影响。
- 模拟噪声对以下输出测量数据的影响: 做出不同的设计决策微调设计参数,直至达到 适合您的应用场景的信噪比。
- 请就摘要报告的实用性提供反馈: 使用 Epsilon 值和噪声参数值,但哪个值不适合?在哪里 有哪些?
可以将其视为一个准备步骤。Noise Lab 生成衡量数据以模拟摘要报告输出结果 输入。它不会保留或共享任何数据。
Noise Lab 有两种不同的模式:
- 简单模式:了解您拥有的控件的基础知识
- 高级模式:测试不同的噪音管理策略并评估 哪种方式可为您的使用场景提供最佳的信噪比。
点击顶部菜单中的按钮即可在两者之间切换 模式(如以下屏幕截图中的第 1 条所示)。
简单模式
- 在“简单”模式下,您可以控制“参数”(位于左侧) 或 2.如下面的屏幕截图所示),看看它们对噪声的影响。
- 每个参数都有一个提示(“?”按钮)。点击这些图标即可查看 对每个参数的说明(第 3 条,如下面的屏幕截图所示)
- 要开始模拟,请点击然后观察输出内容 (#4. 在下面的屏幕截图中)
- 在“输出”部分,您可以看到各种详细信息。部分 元素旁边会显示 `?`。请花点时间点击每个 `?`, 对各种信息的说明
- 在“输出”部分,点击“详细信息”切换开关 如果您想查看该表格的展开版本(第 5 条,如下面的屏幕截图所示)
- 在输出部分的每个数据表下方,有一个选项 下载该表格以供离线使用。此外,在底部 有一个用于下载所有数据表格的选项(#6. 如下面的屏幕截图所示)
- 测试“参数”部分中的参数的不同设置
然后点击“模拟”,看看对输出结果有什么影响:
<ph type="x-smartling-placeholder">
</ph> 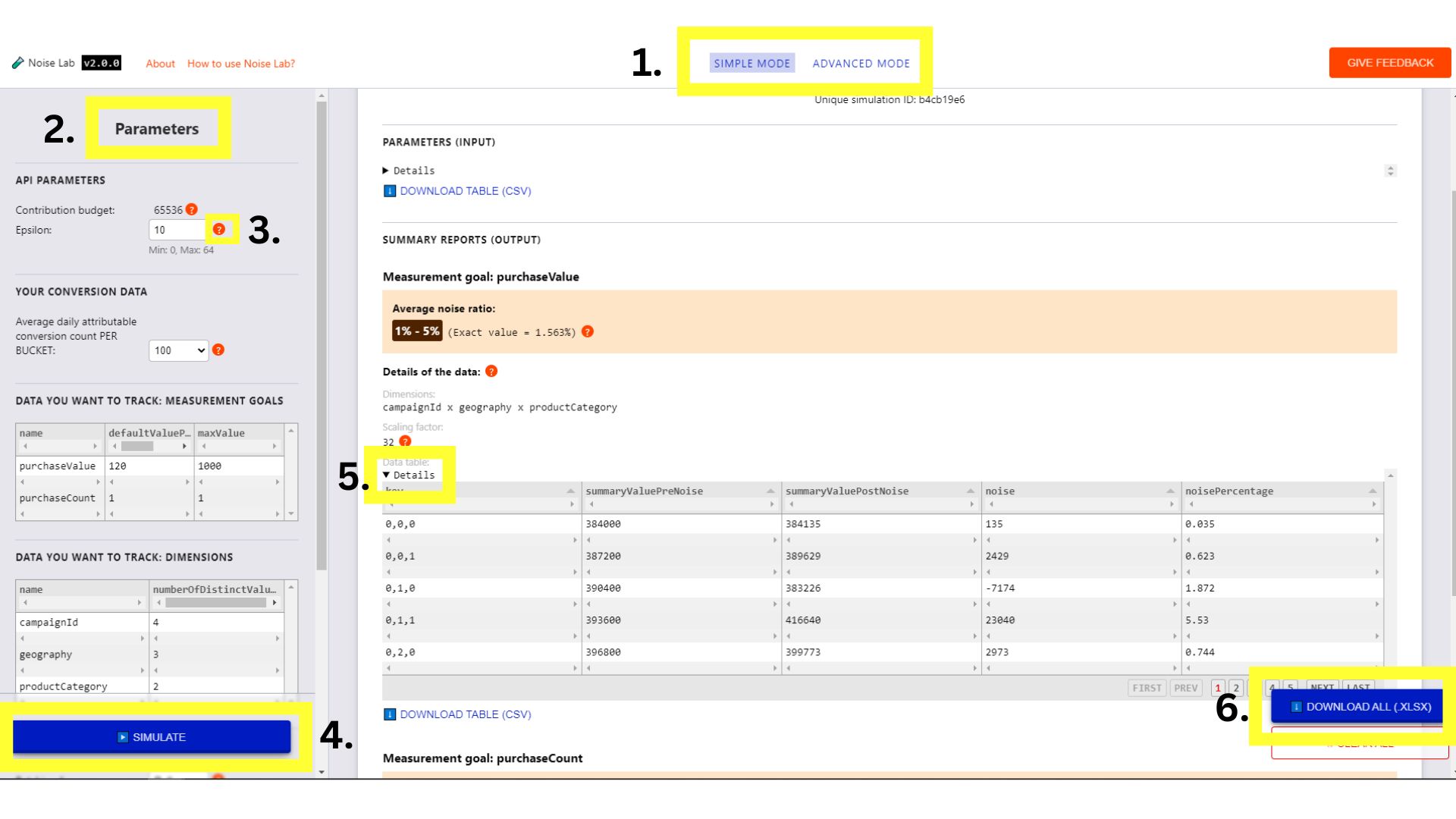
适用于简单模式的 Noise Lab 界面。
高级模式
- 在高级模式下,您可以更好地控制参数。您 可以添加自定义衡量目标和维度(屏幕截图中的第 1 条和第 2 条) 见下文)
- 在“参数”部分进一步向下滚动,然后查看
策略选项。这可用于测试不同的密钥结构
(#3. 在下面的屏幕截图中)
<ph type="x-smartling-placeholder">
- </ph>
- 如需测试不同的按键结构,请将按键策略切换到“B”
- 输入您要使用的不同按键结构的数量 (默认设置为“2”)
- 点击“Generate Key Structures”
- 您会看到用于指定键结构的选项,只需点击 要为每个键结构添加的键旁边的复选框
- 点击“模拟”即可查看输出。
<ph type="x-smartling-placeholder">
</ph> 。 <ph type="x-smartling-placeholder">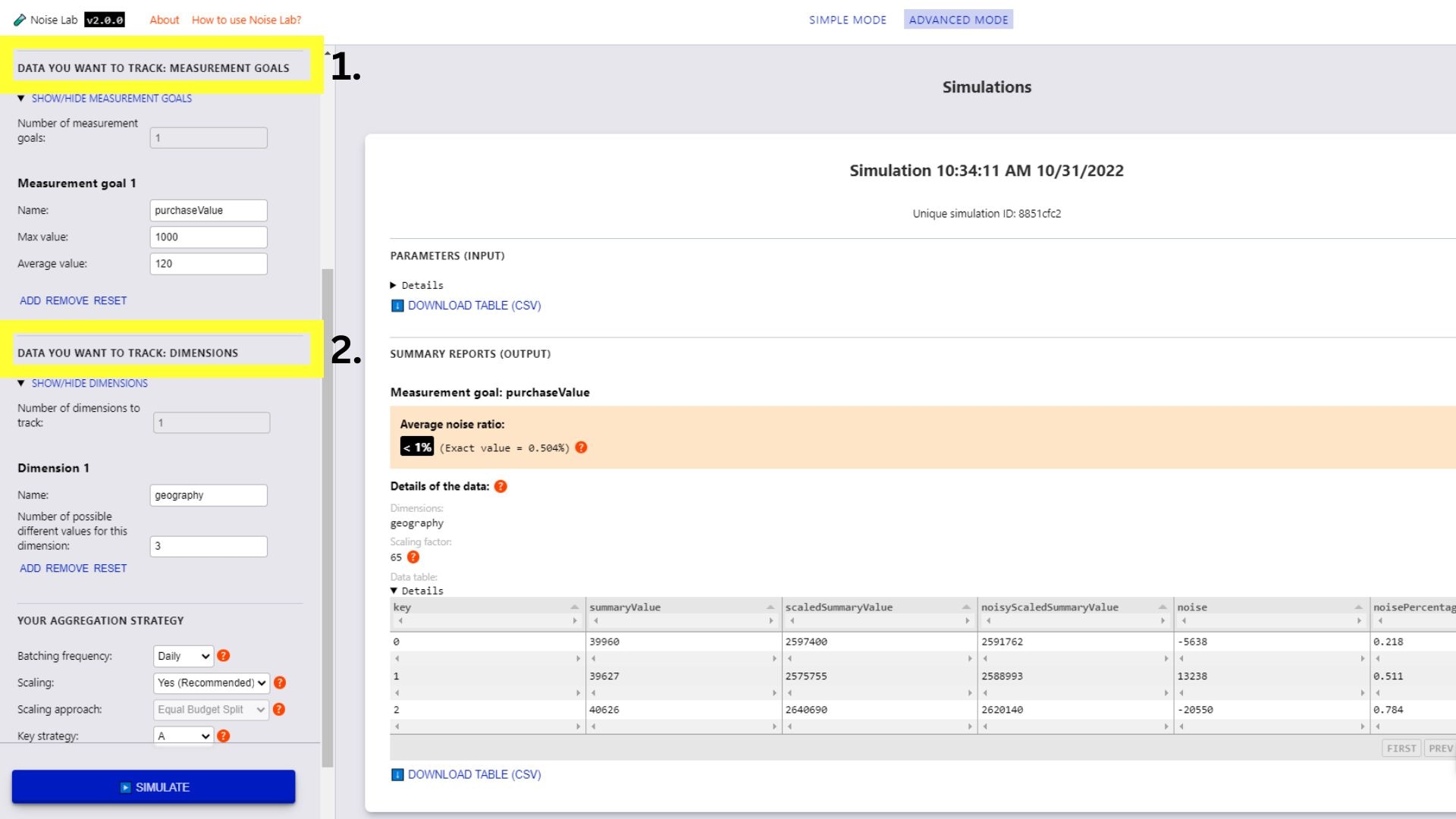
高级模式的 Noise Lab 界面。 </ph> 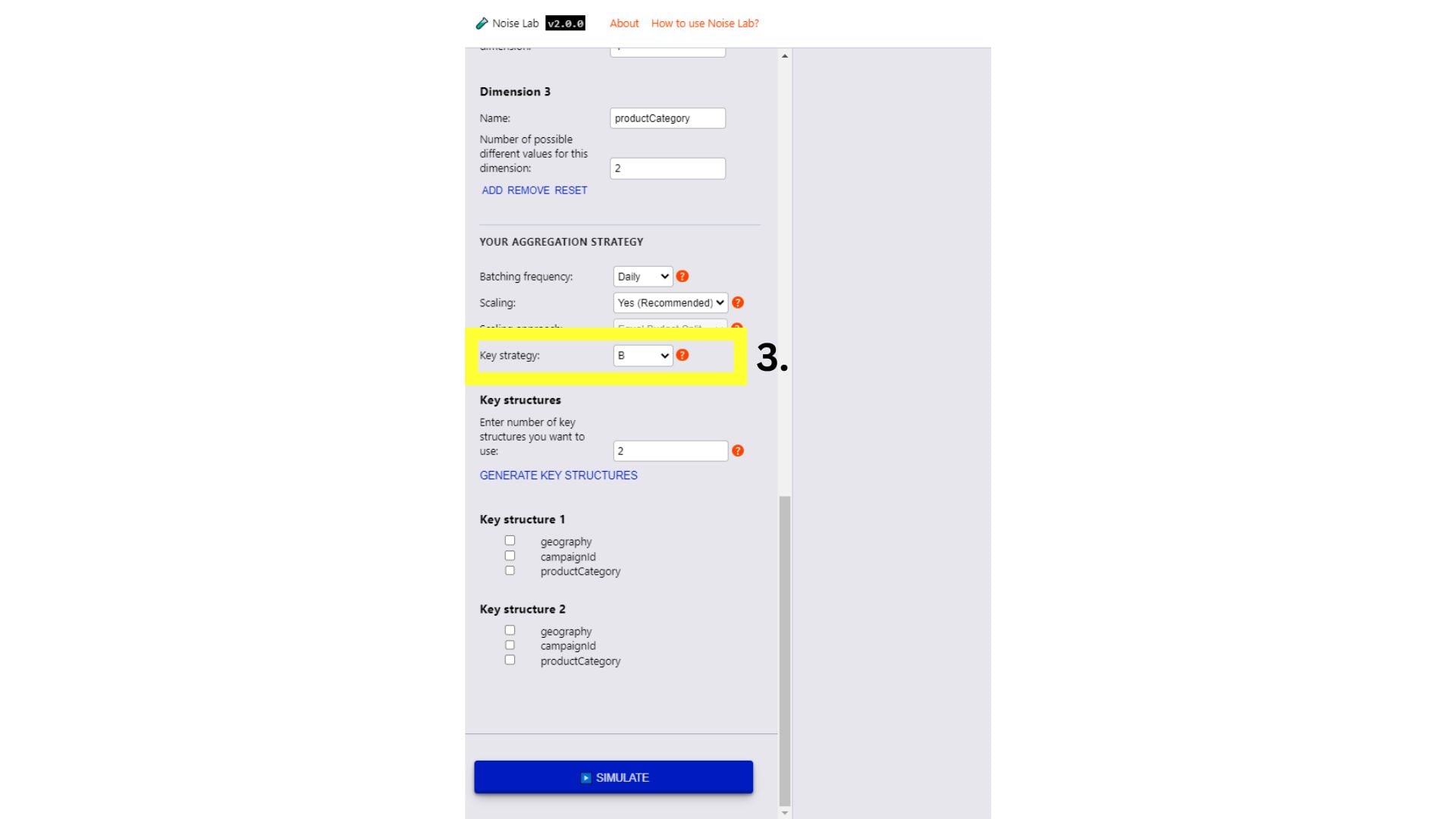
高级模式的 Noise Lab 界面。
噪声指标
核心概念
系统会添加噪声,以保护个人用户隐私。
如果噪声值较高,则表示区段/键稀疏, 包含由数量有限的敏感事件贡献的内容。大功告成 让人们能够“隐藏在人群中”或 换句话说,就是为这些有限的个人以更精细的方式 添加噪声。
如果噪声值较低,则表明数据设置是按照 已经允许个人“隐藏在人群中”。这意味着 存储分区包含足够数量事件的贡献 保护个人用户的隐私。
该陈述同时适用于平均百分比误差 (APE) 和 RMSRE_T(具有阈值时的均方根相对误差)。
APE(平均百分比误差)
APE 是噪声与信号的比率,即真实的摘要值。p> APE 值越低,信噪比越高。
公式
对于给定的摘要报告,APE 的计算方式如下:
<ph type="x-smartling-placeholder">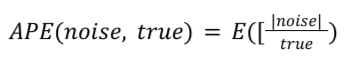
True 是真实汇总值。APE 是每个周期内的噪声的平均值 真实摘要值,根据摘要报告中所有条目计算得出的平均值。 在 Noise Lab 中,该值将乘以 100 得到一个百分比。
优缺点
大小较小的存储分区对 APE 的最终值有不成比例的影响。在评估噪声时,可能会有误导性。因此,我们又添加了一个指标 RMSRE_T,旨在减轻 APE 的这一限制。有关详情,请查看示例。
代码
查看源代码 。
RMSRE_T(具有阈值的均方根相对误差)
RMSRE_T(设定了阈值的均方根相对误差)是另一种噪声衡量指标。
如何解读 RMSRE_T
RMSRE_T 值越低,信噪比越高。
例如,如果您的用例可接受的噪声比为 20%,而 RMSRE_T 为 0.2,那么您就可以确信噪声水平在可接受的范围内。
公式
对于给定的摘要报告,RMSRE_T 的计算方式如下:
<ph type="x-smartling-placeholder">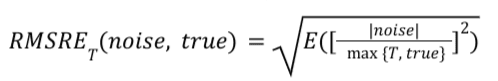
优缺点
RMSRE_T 的理解比 APE 稍微复杂一些。不过,它具有一些优势,因此在某些情况下比 APE 更适合分析摘要报告中的噪声:
- RMSRE_T 更稳定。“T”是一个阈值。“T”用于在 RMSRE_T 计算中为转化次数减少、因范围较小而对噪声更敏感的桶使用更低的权重。如果设置为 T,则指标在转化次数很少的区间内不会出现峰值。如果 T 等于 5,则对于转化次数为 0 的存储分区,最小为 1 的噪声值将不会显示为大于 1。由于 T 等于 5,因此上限将为 0.2,相当于 1/5。通过为对噪声更敏感的较小分桶分配更少的权重,此指标更稳定,因此可以更轻松地比较两个模拟。
- RMSRE_T 可轻松汇总。了解多个存储分区的 RMSRE_T 及其真实计数,可让您计算其总和的 RMSRE_T。这样,您还可以针对这些组合值针对 RMSRE_T 进行优化。
虽然 APE 可以进行聚合,但公式相当复杂,因为它涉及拉普拉斯噪声总和的绝对值。这使得 APE 更难优化。
代码
查看源代码以进行 RMSRE_T 计算。
示例
包含三个类别的摘要报告:
- bucket_1 = 噪声:10,trueSummaryValue:100
- bucket_2 = 噪声:20,trueSummaryValue:100
- bucket_3 = 噪声:20,trueSummaryValue:200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
包含三个类别的摘要报告:
- bucket_1 = 噪声:10,trueSummaryValue:100
- bucket_2 = 噪声:20,trueSummaryValue:100
- bucket_3 = 噪声:20,trueSummaryValue:20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
包含三个类别的摘要报告:
- bucket_1 = 噪声:10,trueSummaryValue:100
- bucket_2 = 噪声:20,trueSummaryValue:100
- bucket_3 = 噪声:20,trueSummaryValue:0
APE = (0.1 + 0.2 + 无穷大) / 3 = 无穷大
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
高级密钥管理
一家需求方平台或广告衡量公司可能拥有数以千计的全球广告 客户,涵盖多个行业、多种货币,以及购买价格 潜力。也就是说,在每个网页上创建和管理一个汇总键, 这很可能是非常不切实际的此外,它还将 选择可汇总的最高值和 在这数以千计的全球广告客户中,限制噪声带来的影响。相反, 我们来考虑以下几种情形:
关键策略 A
该广告技术提供商决定为自己的所有服务创建和管理一个密钥, 广告客户。对于所有广告客户和所有币种, 购买量各不相同,有的从低高端的购买到大批量的低端购买,不一而足 购买。这将生成以下键:
| 键(多种货币) | |
|---|---|
| 最大可汇总值 | 5000000 |
| 购买价值范围 | [120 - 5000000] |
关键策略 B
该广告技术提供商决定在其 广告客户。他们决定按货币来分隔键。在所有 但购买量不尽相同 从高端到高额、低端购买按币种进行分隔 他们创建了 2 个密钥:
| 键 1(美元) | 键 2 (¥) | |
|---|---|---|
| 最大可汇总值 | $40000 | 5000000 日元 |
| 购买价值范围 | [120 - 40,000] | [15,000 - 5,000,000] |
与关键策略 A 相比,关键策略 B 的结果噪声更少,因为 货币值在各个货币之间不均匀分布。例如: 考虑一下以 ¥ 计价的购买交易与以 ¥ 计价的购买交易如何混杂 USD 会改变基础数据和产生的噪声输出。
关键策略 C
该广告技术提供商决定在 广告客户,并按“币种 x 广告客户”来划分这些客户 行业:
| 键 1 (美元 x 高端珠宝广告客户) |
键 2 (¥ x 高端珠宝广告客户) |
键 3 (美元 x 服装零售商广告客户) |
键 4 (¥ x 服装零售商广告客户) |
|
|---|---|---|---|---|
| 最大可汇总值 | $40000 | 5000000 日元 | $500 | 65,000 日元 |
| 购买价值范围 | [10,000 - 40,000] | [1250000 - 5000000] | [120 - 500 人] | [15,000 - 65,000] |
与关键策略 B 相比,关键策略 C 的结果噪声更少,因为 广告客户的购买价值在各个广告客户之间并不均匀分布。对于 以高端珠宝购买与购买相结合的方式, 会改变底层数据并产生噪声输出。
考虑创建共享最大汇总值和共享调节系数 以找出多个广告客户的共同点,以减少 输出。例如,您可以在下方尝试不同的策略 您的广告客户:
- 一项策略,按币种(美元、元、加元等)
- 一项策略按广告客户所在行业(保险、汽车、 零售等)
- 一项策略,按相似的购买价值范围 ([100]、 [1000]、[10000] 等)
围绕广告客户的共性、要点和 相应代码更易于管理,而信噪比 。针对不同的广告客户尝试不同的策略 找出最大限度提高噪声带来的影响的转折点(与代码相比)的共性 管理。
高级离群值管理
我们以两个广告客户的情景为例:
- 广告客户 A:
- 广告客户 A 网站上所有产品的购买价格 可能介于 [120 美元 - 1,000 美元] 之间,区间为 880 美元。
- 购买价格在 880 美元范围内平均分配 并且没有离群值超出购买价格中位数两个标准差之外的离群值。
- 广告客户 B:
- 广告客户 B 网站上所有产品的购买价格 可能介于 [120 美元 - 1,000 美元] 之间,区间为 880 美元。
- 购买价格严重偏向于 120 到 500 美元这一区间 其中只有 5% 的购买交易发生在 500 美元至 1,000 美元的范围内。
由于存在 捐赠预算要求 以及对最终结果应用噪声的方法,那么默认情况下,广告客户 B 的输出会比 广告客户 A,因为广告客户 B 的离群值更有可能影响 底层计算。
使用特定的密钥设置可以缓解此问题。测试关键策略 这有助于管理离群数据,以及更均匀地分配购买价值 。
对于广告客户 B,您可以创建两个单独的密钥以捕获两个不同的 购买价值范围。在此示例中,广告技术平台注意到离群值 高于 500 美元的购买价值。请尝试为 此广告客户:
- 键结构 1 :仅用于捕获 介于 120 美元到 500 美元之间(约占总交易量的 95%)。
- 键结构 2:仅适用于 500 美元以上的购买交易的键 (约占总交易量的 5%)。
实施这一关键策略应该能够更好地管理广告客户 B 的干扰数据, 帮助从摘要报告中最大限度地为他们提供实用信息。由于新的 范围,键 A 和键 B 的数据分布现在应更加均匀 与上一个键对应的各个键之间的距离。这会导致 相较于前一个键,每个键的输出对噪声的影响更小。