Der Aggregationsdienst generiert Zusammenfassungsberichte mit detaillierten Conversion-Daten und Reichweitenmessungen aus Rohdaten, die aggregiert werden können. Als Anbieter von Anzeigentechnologien können Sie die Attribution Reporting API und die Private Aggregation API verwenden, die beiden wichtigsten Einstiegspunkte für die Aggregation auf der Clientseite, um Berichte an den Aggregationsdienst weiterzuleiten und als Antwort einen Zusammenfassungsbericht zu erhalten.
Auf dieser Seite wird davon ausgegangen, dass Sie mit Anzeigentechnologien vertraut sind. Sie enthält folgende Themen:
- Implementierungsstatus
- Wichtige Begriffe und Konzepte
- Anwendungsfälle für die Aggregation
- End-to-End-Ablauf
- Batchverarbeitung von aggregierten Berichten
- Cloud-Komponenten
Implementierungsstatus
- Der Aggregationsdienst ist jetzt allgemein verfügbar.
- Der Aggregationsdienst kann mit der Attribution Reporting API und der Private Aggregation API für die Protected Audience API und die Shared Storage API verwendet werden.
Verfügbarkeit
| Vorschlag | Status |
|---|---|
| Cloudübergreifender Dienst für den Datenschutzbudget |
Verfügbar |
| Unterstützung des Aggregationsdiensts für Amazon Web Services (AWS) über die Attribution Reporting API und die Private Aggregation API
Erläuterung |
Verfügbar |
| Unterstützung des Aggregationsdiensts für Google Cloud über die Attribution Reporting API und die Private Aggregation API Erläuterung |
Verfügbar |
| Websiteregistrierung für den Aggregationsdienst und Multi-Origin-Aggregation Die Websiteregistrierung umfasst die Zuordnung einer Website zu Cloud-Konten (AWS oder GCP). Wenn Sie mehrere Ursprünge zusammenfassen möchten, müssen sie von derselben Website stammen.
Häufig gestellte Fragen auf GitHub Site Aggregation API-Dokumentation |
Verfügbar |
| Der Epsilonwert des Aggregationsdienstes wird auf einen Bereich von bis zu 64 festgelegt, um Tests und Feedback zu verschiedenen Parametern zu ermöglichen.
ARA-Epsilon-Feedback geben Feedback zur PAA-Epsilon-Funktion geben |
Verfügbar Wir informieren das Ökosystem rechtzeitig, bevor die Werte für den Epsilonbereich aktualisiert werden. |
| Flexiblere Beitragsfilterung für Abfrage des Aggregationsdienstes
Erläuterung |
Verfügbar |
| Verfahren zur Budgetwiederherstellung nach Notfallsituationen (Fehler, Fehlkonfigurationen usw.)
Erläuterung |
Verfügbar Möglichkeit, den Prozentsatz der gemeinsamen IDs zu prüfen, die mithilfe der Budgetwiederherstellung von einer Anzeigentechnologie wiederhergestellt wurden, und zukünftige Wiederherstellungen bei übermäßigen Wiederherstellungen für das erste Halbjahr 2025 zu sperren |
| Accenture als einer der Koordinatoren bei AWS
Entwicklerblog |
Verfügbar |
| Unabhängige Partei, die als einer der Koordinatoren bei Google Cloud tätig ist
Entwicklerblog |
Verfügbar |
| Unterstützung des Aggregationsdienstes für zusammengefasste Debug-Berichte in der Attribution Reporting API
Erläuterung |
Verfügbar |
Wichtige Begriffe und Konzepte
Wenn Sie den Aggregationsdienst für Ihren Workflow in Betracht ziehen, können Ihnen die folgenden Begriffe und Konzepte einen Einblick in die Vorteile dieses neuen Aggregationsflusses für Ihr Team geben.
Glossar
- Aggregierbare Berichte
-
Aggregierbare Berichte sind verschlüsselte Berichte, die von einzelnen Nutzergeräten gesendet werden. Diese Berichte enthalten Daten zum seitenübergreifenden Nutzerverhalten und zu Conversions. Conversions (manchmal auch Attributionstrigger-Ereignisse genannt) und zugehörige Messwerte werden vom Werbetreibenden oder der Anzeigentechnologie definiert. Jeder Bericht wird verschlüsselt, um zu verhindern, dass Dritte auf die zugrunde liegenden Daten zugreifen.
- Berichtserfassung, die sich zusammenfassen lässt
-
A distributed ledger, located in both coordinators, that tracks the allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures no reports pass through the Aggregation Service beyond the allocated privacy budget.
Read more on how batching strategies relate to aggregatable reports.
- Budget für Berichtsabrechnung, das zusammengefasst werden kann
-
References to the budget that ensures individual reports are not processed more than once.
- Zusammenfassungsdienst
-
An ad tech-operated service that processes aggregatable reports to create a summary report.
Read more about the Aggregation Service backstory in our explainer and the full terms list.
- Bestätigung
-
A mechanism to authenticate software identity, usually with cryptographic hashes or signatures. For the aggregation service proposal, attestation matches the code running in your ad tech-operated aggregation service with the open source code.
- Beitragsbindung
- Koordinator
-
Entities responsible for key management and aggregatable report accounting. A Coordinator maintains a list of hashes of approved aggregation service configurations and configures access to decryption keys.
- Rauschen und Skalierung
-
Statistical noise that is added to summary reports during the aggregation process to preserve privacy and ensure the final reports provide anonymized measurement information.
Read more about additive noise mechanism, which is drawn from Laplace distribution.
- Meldequelle
-
The entity that receives aggregatable reports—in other words, you or an ad tech that called the Attribution Reporting API. Aggregatable reports are sent from user devices to a well-known URL associated with the reporting origin. The reporting origin is designated during enrollment.
- Gemeinsame ID
-
A computed value that consists of
shared_info,reporting_origin,destination_site(for Attribution Reporting API only),source_registration-time(for Attribution Reporting API only),scheduled_report_time, and version.Multiple reports that share the same attributes in the
shared_infofield should have the same shared ID. Shared IDs play an important role within Aggregatable Report Accounting. - Zusammenfassender Bericht
-
Ein Berichtstyp für die Attribution Reporting API und die Private Aggregation API. Ein Zusammenfassungsbericht enthält aggregierte Nutzerdaten und kann detaillierte Conversion-Daten mit Rauschen enthalten. Zusammenfassende Berichte bestehen aus zusammengefassten Berichten. Sie bieten mehr Flexibilität und ein umfangreicheres Datenmodell als Berichte auf Ereignisebene, insbesondere für einige Anwendungsfälle wie Conversion-Werte.
- Vertrauenswürdige Ausführungsumgebung (TEE)
-
A secure configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the machine without fear of exposure. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less.
To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer.
Anwendungsfälle für Aggregation
Im Folgenden finden Sie Beispiele für die Anzeigenmessung und die zugehörigen Clientbibliotheken.
| Anwendungsfall | Einstiegspunkt | Beschreibung |
|---|---|---|
| Gebotsoptimierung | Attribution Reporting API (Chrome und Android) | Verwenden Sie zusammengefasste Berichte, um Conversion-Signale zur Gebotsoptimierung zu verarbeiten. |
| Plattformübergreifende Analyse | Attribution Reporting API (Chrome und Android) | Mit den web- und appübergreifenden Analysefunktionen erhalten Sie einen Überblick über die Leistung in Chrome und Android. |
| Conversion-Berichte | Attribution Reporting API (Chrome und Android) | Erstellen Sie zusammengefasste Conversion-Berichte, die auf die Kampagnenanforderungen der Kunden zugeschnitten sind (einschließlich CTCs und VTCs). |
| Messung der Kampagnenreichweite | Shared Storage API und Private Aggregation API (Chrome) | Verwenden Sie websiteübergreifende Variablen für Anzeigenaufrufe, um die Kampagnenreichweite zu messen. |
| Berichte zu demografischen Merkmalen | Shared Storage API und Private Aggregation API (Chrome) | Verwenden Sie standortübergreifende Anzeigenaufrufe und demografische Informationen, um die Reichweite nach demografischen Merkmalen zu messen. |
| Conversion-Pfad-Analyse | Shared Storage API und Private Aggregation API (Chrome) | Speichern Sie websiteübergreifende Anzeigenaufrufe und Conversion-Variablen, um eine zusammengefasste Conversion-Pfadanalyse durchzuführen. |
| Anzeigenwirkung auf die Markenbekanntheit und Conversion-Steigerung | Shared Storage API und Private Aggregation API (Chrome) | Berichte zu Test-/Kontrollgruppen und Umfrageinformationen zur Messung der Anzeigenwirkung auf die Markenbekanntheit und der Steigerung von Conversions. |
| Auktionsfehlerbehebung | Protected Audience API und Private Aggregation API (Chrome) | Verwenden Sie zusammengefasste Berichte für die Fehlerbehebung. |
| Verteilung von Geboten | Protected Audience API und Private Aggregation API (Chrome) | Mit zusammengefassten Berichten können Sie die Verteilung der Gebotswerte für Auktionen erfassen. |
End-to-End-Ablauf
Das folgende Diagramm zeigt den Aggregationsdienst in Aktion. Wir konzentrieren uns auf den End-to-End-Vorgang, vom Empfang der Berichte von Web- und Mobilgeräten bis zum Erstellen des Zusammenfassungsberichts im Aggregationsdienst.
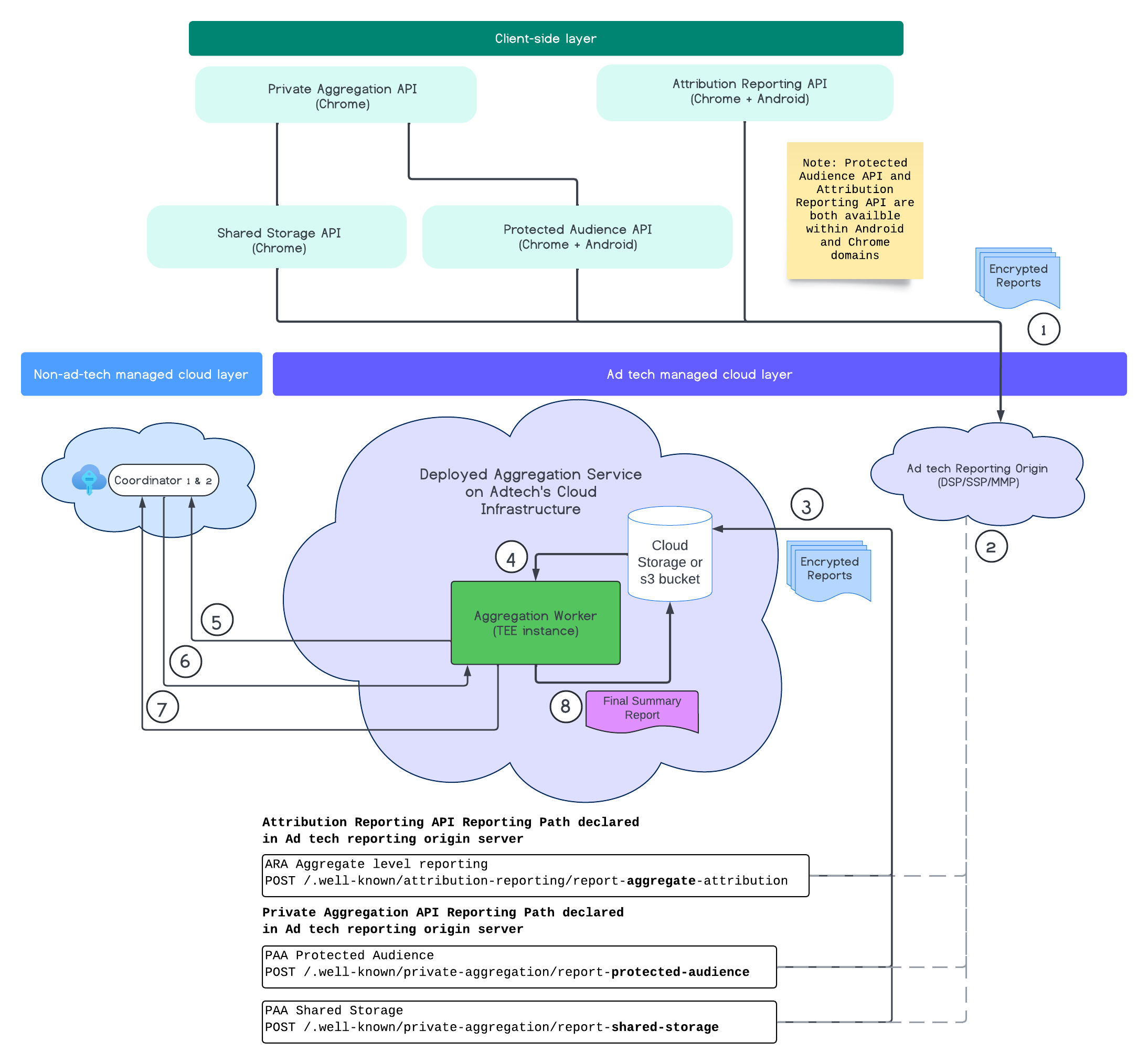
- Rufen Sie den öffentlichen Schlüssel ab, um verschlüsselte Berichte zu generieren.
- Verschlüsselte aggregierbare Berichte werden an AdTech-Server gesendet, um dort erfasst, transformiert und in Batches zusammengefasst zu werden.
- Der Ad Tech-Server fasst Berichte (im Avro-Format) zusammen und sendet sie an den Aggregationsdienst. (Dieser Schritt ist obligatorisch.)
- Ein Aggregation Worker ruft die zusammengefassten Berichte zum Entschlüsseln ab.
- Der Aggregation Worker ruft Entschlüsselungsschlüssel von einem Koordinator ab.
- Der Aggregation Worker entschlüsselt die Berichte für die Aggregation und die Zufallszahlengenerierung.
- Der Dienst zur Abrechnung aggregierbarer Berichte prüft, ob genügend Datenschutzbudget vorhanden ist, um einen zusammengefassten Bericht für die angegebenen aggregierbaren Berichte zu generieren.
- Reichen Sie einen abschließenden Zusammenfassungsbericht ein.
Das Diagramm zeigt die allgemeinen Beziehungen zwischen dem Aggregationsdienst und den wichtigsten APIs für die Kundenmessung: der Attribution Reporting API, der Private Aggregation API und den Koordinatoren.
Der Ablauf beginnt mit Analyse-APIs wie der Attribution Reporting API oder der Private Aggregation API, die Berichte aus mehreren Browserinstanzen generieren. Chrome ruft den öffentlichen Schlüssel vom Schlüssel-Hostingdienst im Koordinator ab, um die Berichte zu verschlüsseln, bevor sie an den Ursprung Ihrer Berichterstellung für Anzeigentechnologien gesendet werden. Öffentliche Schlüssel werden alle sieben Tage rotiert.
Die Quelle für Berichte Ihrer Anzeigentechnologie sollte so konfiguriert sein, dass eingehende Berichte erfasst und in das Avro-Format konvertiert und wie in den Batching-Strategien beschrieben an Ihren Aggregationsdienst gesendet werden.
Wenn Sie einen Batch haben, senden Sie eine Batchanfrage an den Aggregationsdienst. Der Aggregationsdienst ruft Entschlüsselungsschlüssel vom Schlüssel-Hostingdienst ab, entschlüsselt die Berichte und aggregiert und anonymisiert sie, um einen zusammengefassten Bericht zu erstellen. Beachten Sie, dass dies davon abhängt, ob genügend Datenschutzbudget für die Erstellung vorhanden ist.
Sie hosten den Endpunkt für die Berichtsabsender von Anzeigentechnologien, an dem die Berichte erfasst werden, und der Aggregationsdienst wird in Ihrer Ad Tech-Cloud bereitgestellt.
Batchverarbeitung von Berichten, die zusammengefasst werden können
Der Berichtsablauf wäre ohne den dafür vorgesehenen Ursprungsserver für Berichte nicht vollständig. Dies ist die Quelle, die Sie im Registrierungsprozess angegeben haben. Der Berichtsoriginator ist dafür verantwortlich, die empfangenen aggregierbaren Berichte zu erfassen, zu transformieren und zu bündeln und sie für den Versand an Ihren Aggregationsdienst in Google Cloud oder Amazon Web Services vorzubereiten. Weitere Informationen zum Erstellen von Berichten, die zusammengefasst werden können
Nachdem Sie nun das allgemeine Konzept kennen, können wir uns die Komponenten genauer ansehen, die in Ihrem Aggregationsdienst bereitgestellt werden.
Cloud-Komponenten
Der Aggregationsdienst besteht aus mehreren Cloud-Dienstkomponenten. Sie verwenden die bereitgestellten Terraform-Scripts, um alle erforderlichen Cloud-Dienstkomponenten bereitzustellen und zu konfigurieren.
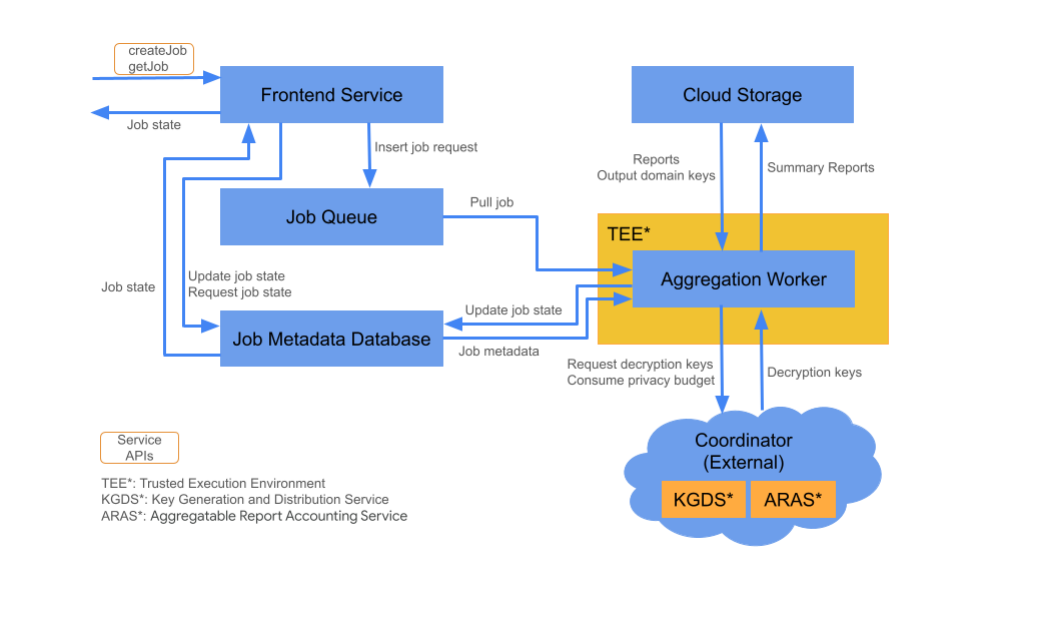
Frontend-Dienst
Verwalteter Cloud-Dienst:Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
Der Frontend-Dienst ist ein serverloses Gateway, das der primäre Einstiegspunkt für Aggregation API-Aufrufe zum Erstellen von Jobs und Abrufen des Jobstatus ist. Er ist für den Empfang von Anfragen von Nutzern des Aggregationsdiensts, die Validierung von Eingabeparametern und die Initiierung des Aggregationsjobs verantwortlich.
Der Frontend-Dienst bietet zwei APIs:
| Endpunkt | Beschreibung |
|---|---|
createJob |
Diese API löst einen Job des Aggregationsdiensts aus. Zum Auslösen des Jobs sind unter anderem Informationen wie Job-ID, Details zum Eingabespeicher, Details zum Ausgabespeicher und der Berichtsorigin erforderlich. |
getJob |
Diese API gibt den Status des Jobs mit einer bestimmten Job-ID zurück. Sie enthält Informationen zum Status des Jobs, z. B. „Empfangen“, „In Bearbeitung“ oder „Abgeschlossen“. Wenn der Job abgeschlossen ist, wird auch das Jobergebnis zurückgegeben, einschließlich aller Fehlermeldungen, die während der Jobausführung aufgetreten sind. |
Weitere Informationen finden Sie in der Aggregation Service API-Dokumentation.
Jobwarteschlange
Verwalteter Cloud-Dienst:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
Die Jobwarteschlange ist eine Nachrichtenwarteschlange mit Jobanfragen für den Aggregationsdienst. Der Frontend-Dienst fügt Jobanfragen in die Warteschlange ein, die dann von Aggregation Workers verarbeitet werden.
Cloud-Speicher
Verwalteter Cloud-Dienst:Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Eingabe- und Ausgabedateien, die vom Aggregationsdienst verwendet werden, z. B. verschlüsselte Berichtsdateien und Ausgabezusammenfassungsberichte, werden im Cloud-Speicher aufbewahrt.
Datenbank mit Job-Metadaten
Verwalteter Cloud-Dienst:Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
In der Datenbank für Jobmetadaten wird der Status von Aggregationsjobs gespeichert und verfolgt. Es werden Metadaten wie Erstellungszeit, angeforderte Zeit, aktualisierte Zeit und Status wie „Empfangen“, „In Bearbeitung“ oder „Abgeschlossen“ erfasst. Aggregation Worker aktualisieren die Datenbank mit Jobmetadaten während der Ausführung von Jobs.
Aggregation Worker
Verwalteter Cloud-Dienst:Compute Engine mit vertraulichem Bereich (Google Cloud) / Amazon Web Services EC2 mit Nitro Enclave (Amazon Web Services)
Ein Aggregation Worker verarbeitet Jobanfragen in der Jobqueue und entschlüsselt die verschlüsselten Eingaben mit Schlüsseln, die er vom Key Generation and Distribution Service (KGDS) in Koordinatoren abholt. Um die Latenz bei der Jobverarbeitung zu minimieren, speichern Aggregation Worker Entschlüsselungsschlüssel für einen Zeitraum von 8 Stunden im Cache und verwenden sie für alle Jobs, die sie verarbeiten.
Aggregation Workers werden in einer Trusted Execution Environment (TEE) ausgeführt. Ein Worker verarbeitet jeweils nur einen Job. Sie können mehrere Worker konfigurieren, um Jobs parallel zu verarbeiten, indem Sie die Autoscaling-Konfiguration festlegen. Bei Verwendung passt die automatische Skalierung die Anzahl der Worker dynamisch an die Anzahl der Nachrichten in der Jobwarteschlange an. Sie können die Mindest- und Höchstanzahl der Worker für das Autoscaling über die Terraform-Umgebungsdatei konfigurieren. Weitere Informationen zum Autoscaling finden Sie in diesen Terraform-Scripts: Amazon Web Services oder Google Cloud.
Aggregation Workers rufen den Dienst zur Berichtserfassung auf, um Berichte zu aggregieren. Mit diesem Dienst wird sichergestellt, dass Jobs nur ausgeführt werden, wenn das Datenschutzbudgetlimit nicht überschritten wurde. (Siehe Regel „Keine Duplikate“.) Wenn das Budget verfügbar ist, wird ein Zusammenfassungsbericht mit den fehlerhaften Aggregaten erstellt. Weitere Informationen zur Berichtserfassung
Aggregation Workers aktualisieren Jobmetadaten in der Jobmetadatendatenbank. Dazu gehören Jobrückgabecodes und Berichtsfehlerzähler bei teilweisen Berichtsfehlern. Nutzer können den Status mithilfe der getJob API zum Abrufen des Jobstatus abrufen.
Eine ausführlichere Beschreibung des Aggregationsdienstes finden Sie hier.
Nächste Schritte
Nachdem Sie sich mit den wichtigsten Funktionen des Aggregationsdiensts vertraut gemacht haben, können Sie jetzt Ihre eigene Instanz des Aggregationsdiensts über Google Cloud oder Amazon Web Services bereitstellen. Weitere Informationen finden Sie im Abschnitt „Einstieg“ oder unter Aggregationsdienst verwenden.
Fehlerbehebung
Im Dokument Gängige Fehlercodes und Abhilfemaßnahmen finden Sie detaillierte Beschreibungen von Fehlermeldungen, mögliche Ursachen für den Fehler und die nächsten Schritte zur Abhilfe.
Support anfordern und Feedback geben
- Wenn du Fragen zu Produkten, Feedback oder Feature-Anfragen hast, erstelle bitte ein Problem in unserem GitHub-Repository.
- Wenn beim Bereitstellen, Verwalten oder Ausführen von Jobs mit dem Aggregations-Dienst ein Fehler auftritt, können Sie über dieses Formular technischen Support anfordern.
- Prüfen Sie das öffentliche Status-Dashboard auf bekannte Probleme.