Use-Case Overview
Marketing attribution is a method used by advertisers to determine the contribution of marketing tactics and subsequent ad interactions to sales or conversions.
There are various types of attribution models, including first-touch and last-touch attribution, which are single-touch attribution models. Single-touch attribution models assign 100% of the conversion credit to a single touchpoint in the customer journey. In first-touch attribution, the credit is assigned to the first touchpoint. While in last-touch attribution, the credit is assigned to the last touchpoint before the conversion. Attribution can also be shared across multiple touchpoints in the customer journey, where credit is distributed among the different touchpoints. This is called multi-touch attribution.
We suggest API callers first assess the viability of the Attribution Reporting API for their attribution model needs, although the API is scoped to a single-touch attribution model. From there, we suggest that they read the Shared Storage API and Private Aggregation APIs developer documents before reading this guide.
Implementation with Cookies
Ad techs implement various multi-touch attribution models using 3rd party cookies. Cookies can track users through different views and conversions.
- On ad impression, 3rd party cookies are retrieved by the ad tech. These cookies may contain user ID and other information that were previously collected from the user.
- Once there is a conversion, Ad techs will analyze the conversion path and other collected data to perform attribution analysis.
- Ad techs will generate the converting path using deterministic and probabilistic signals in order to create a multi-touch attribution report.
Privacy Sandbox Solution
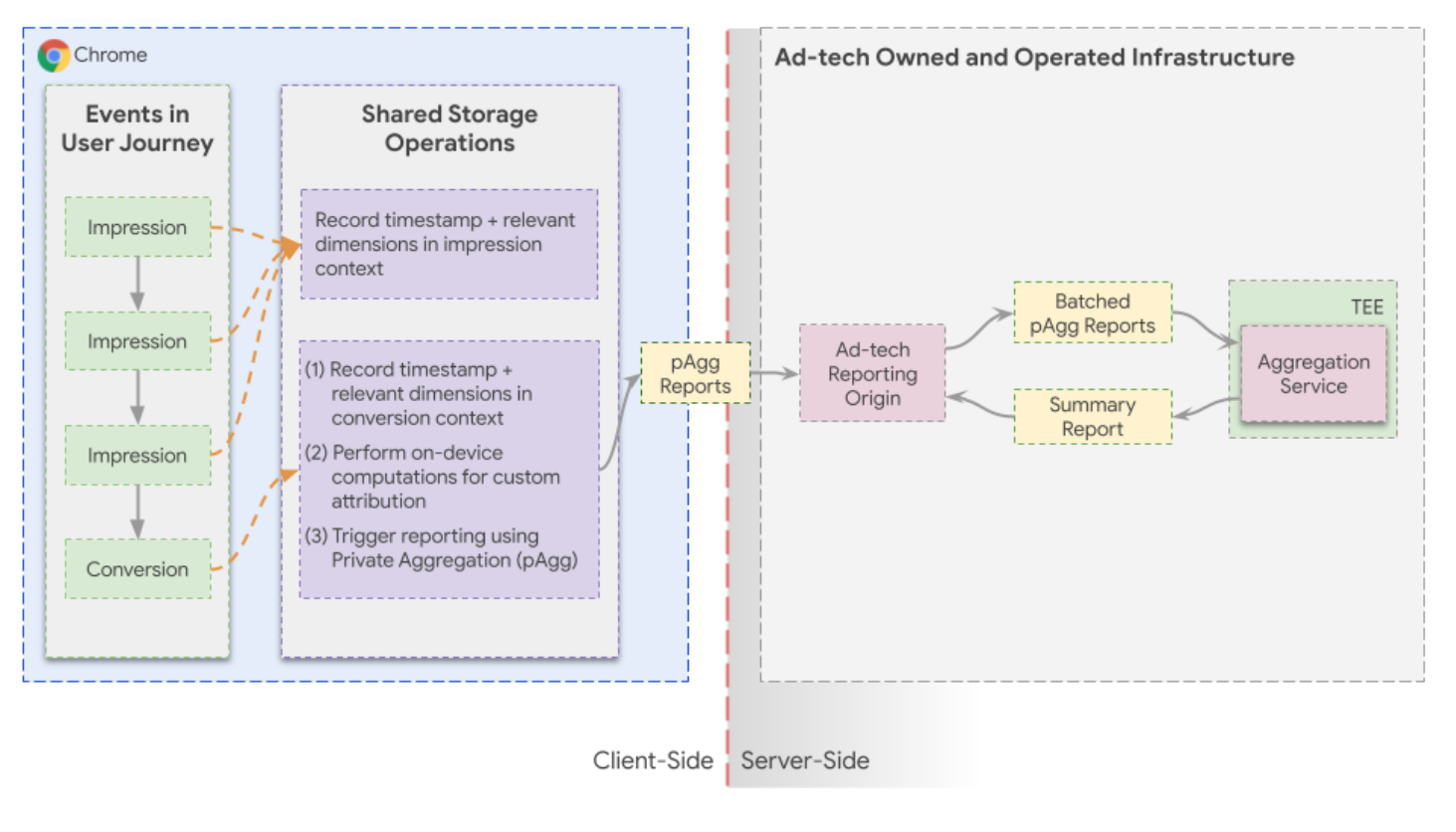
Shared Storage allows Ad techs unlimited writes with privacy preserving cross-site read access. Using the path and dimensions that are collected from the conversions, Ad techs can use different types of models to assign contributions for each ad impression.
Private Aggregation API is used to generate contributions and create reports for aggregation. This is a general purpose API that can be used in a wide array of contexts. Data is encapsulated into “aggregatable reports”, which are encrypted and can only be processed through the “Aggregation Service”. During processing, the service will add noise and impose a limit to how many times a report can be queried. Ad techs can use the Private Aggregation API to get an aggregated report on which path or journey a user has converted on.
To support multi-touch attribution, the Shared Storage and Private Aggregation APIs can be used for this use-case, as they enable the data capture and aggregated measurement of multiple touchpoints on a single browser.
Detailed Solution
To describe the solution in more detail, we will walk through an example user journey and note the relevant steps performed with Privacy Sandbox APIs.
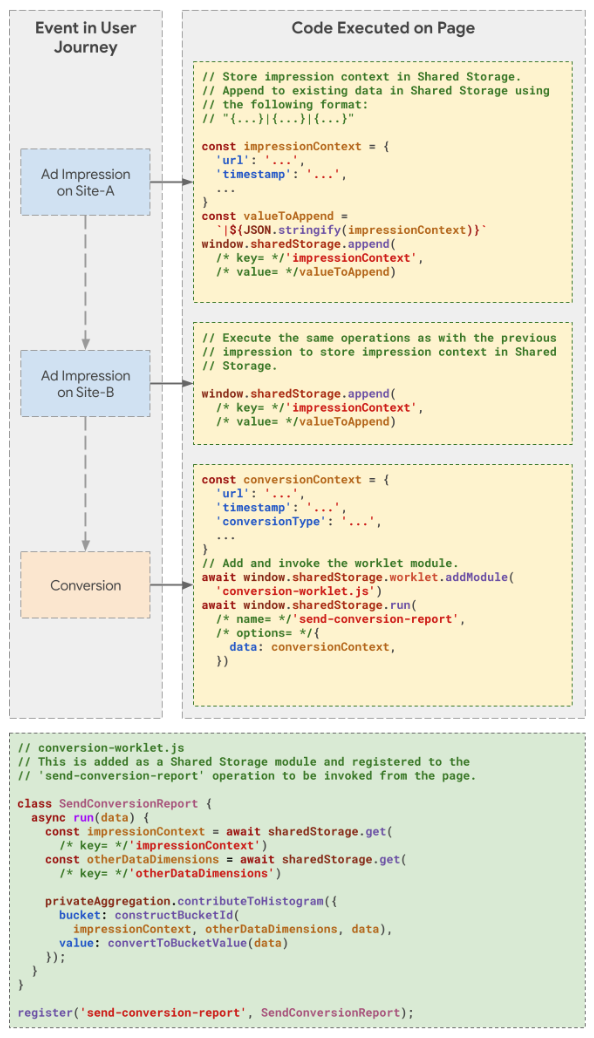
User sees an ad on
news.com→ Ad tech stores context from ad view in Shared Storage along with other dimensions for the user including the impression timestamp.User sees another ad on
shoes.com→ Ad tech stores context from ad view in Shared Storage as earlier.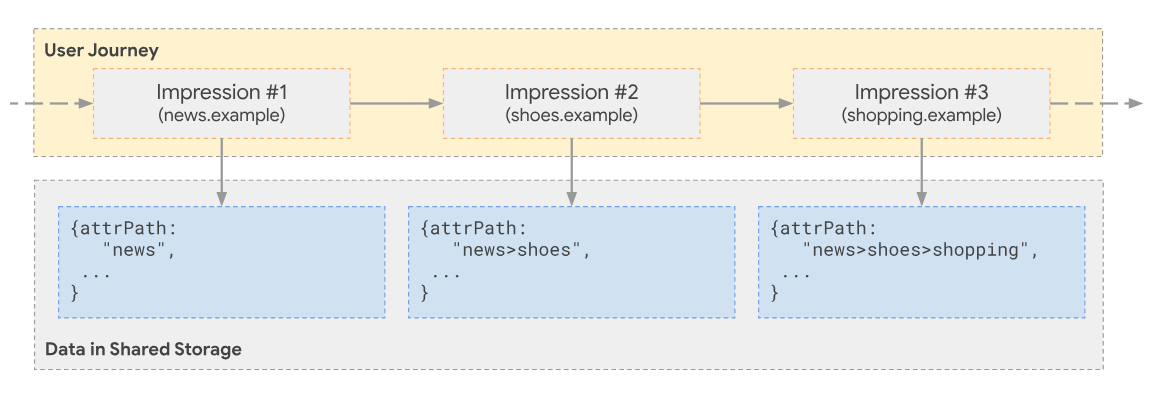
User converts by making a purchase on the advertiser’s site → Ad tech can reference the context stored in Shared Storage to generate a custom attribution report using the Private Aggregation API.
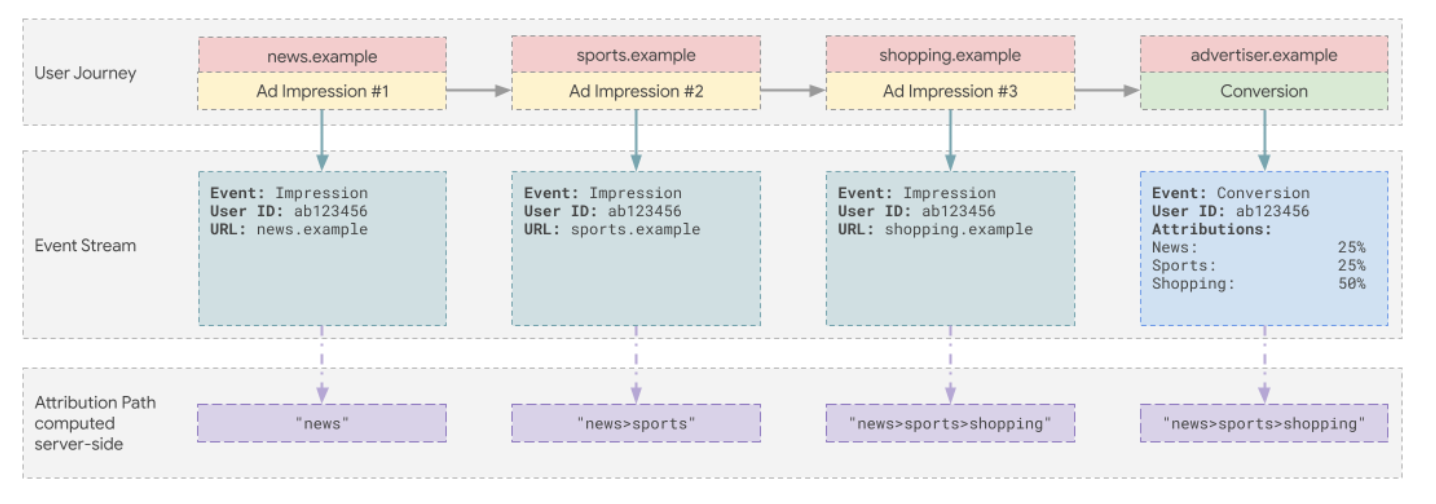
- The Ad tech will need to represent the attributed impressions in the 128-bit aggregation key (aka bucket). The Ad tech can choose to represent these impression touch points as paths or singular nodes.
- To use paths, the Ad tech can create a key containing all the touch points in the user’s conversion path. For example, if the user saw ads on
news.com,shoes.comandshopping.combefore converting, the key will encode the full path"news|shoes|shopping"in a single aggregate contribution. - Alternatively, to use nodes, the Ad tech can declare separate aggregate contributions for each impression touch point in the user’s conversion path. The Ad tech can reference the impression context in Shared Storage to distribute credit across the impressions, say 50% to the most recent impression and 25% for each of the next 2 most recent impressions.
- To use paths, the Ad tech can create a key containing all the touch points in the user’s conversion path. For example, if the user saw ads on
- In choosing between paths and nodes, Ad techs will need to consider the noise vs utility trade-off. For a fixed volume of impression and conversion activity, the more granular the aggregation buckets are, the higher the proportion of noise in the output.
- With paths, Ad techs should also decide how to treat multiple visits (i.e.
news→sports→news) and whether the sequence of visits is relevant. To measure multiple visits and the sequence of visits, Ad techs will need to use more granular buckets which will increase the proportion of noise. - Comparatively, using nodes will be less noisy as there are combinatorially fewer values to represent. Ad techs may also consider further reducing this cardinality by categorizing the websites visited.
- With paths, Ad techs should also decide how to treat multiple visits (i.e.
- The Ad tech will need to represent the attributed impressions in the 128-bit aggregation key (aka bucket). The Ad tech can choose to represent these impression touch points as paths or singular nodes.
Ad tech batches the received aggregatable reports and processes them with the Aggregation Service which returns a summary report.
Engage and share feedback
The Shared Storage proposal is under active discussion and subject to change in the future. If you try this API and have feedback, we'd love to hear it.
- GitHub: Read the proposal, reach whitepaper, raise questions and participate in discussion.
- Shared Storage API announcements: Join or view past announcements on our mailing list
- Developer support: Ask questions and join discussions on the Privacy Sandbox Developer Support repo.