Concetti chiave dell'API Private Aggregation
A chi è rivolto questo documento?
L'API Private Aggregation consente la raccolta di dati aggregati dai worklet con accesso ai dati cross-site. I concetti condivisi qui sono importanti per gli sviluppatori che creano funzioni di generazione di report all'interno dell'API Shared Storage e Protected Audience.
- Se sei uno sviluppatore che crea un sistema di generazione di report per la misurazione tra siti.
- Se sei un professionista del marketing, un data scientist o un altro utilizzatore di report di riepilogo, comprendere questi meccanismi ti aiuterà a prendere decisioni di progettazione per recuperare un report di riepilogo ottimizzato.
Termini chiave
Prima di leggere questo documento, ti consigliamo di acquisire familiarità con i termini e i concetti chiave. Ognuno di questi termini verrà descritto in dettaglio qui.
- Una chiave di aggregazione (detta anche bucket) è una raccolta predeterminata di punti dati. Ad esempio, potresti voler raccogliere un bucket di dati sulla posizione in cui il browser riporta il nome del paese. Una chiave di aggregazione può contenere più di una dimensione (ad esempio, il paese e l'ID del widget dei contenuti).
- Un valore aggregabile è un singolo punto dati raccolto in una chiave di aggregazione. Se vuoi misurare il numero di utenti
in Francia che hanno visto i tuoi contenuti,
Franceè una dimensione nella chiave di aggregazione eviewCountdi1è il valore aggregabile. - I report aggregabili vengono generati e criptati in un browser. Per l'API Private Aggregation, contiene i dati relativi a un singolo evento.
- Il servizio di aggregazione elabora i dati dei report aggregabili per creare un report di riepilogo.
- Un report di riepilogo è l'output finale del servizio di aggregazione e contiene dati utente aggregati con rumore e dati sulle conversioni dettagliati.
- Un worklet è un componente di infrastruttura che consente di eseguire funzioni JavaScript specifiche e di restituire le informazioni all'utente che ha effettuato la richiesta. All'interno di un worklet puoi eseguire JavaScript, ma non puoi interagire o comunicare con la pagina esterna.
Flusso di lavoro di aggregazione privata
Quando chiami l'API Private Aggregation con una chiave di aggregazione e un valore aggregabile, il browser genera un report aggregabile. I report vengono inviati al tuo server, che li raggruppa. I report raggruppati vengono successivamente elaborati dal servizio di aggregazione e viene generato un report di riepilogo.
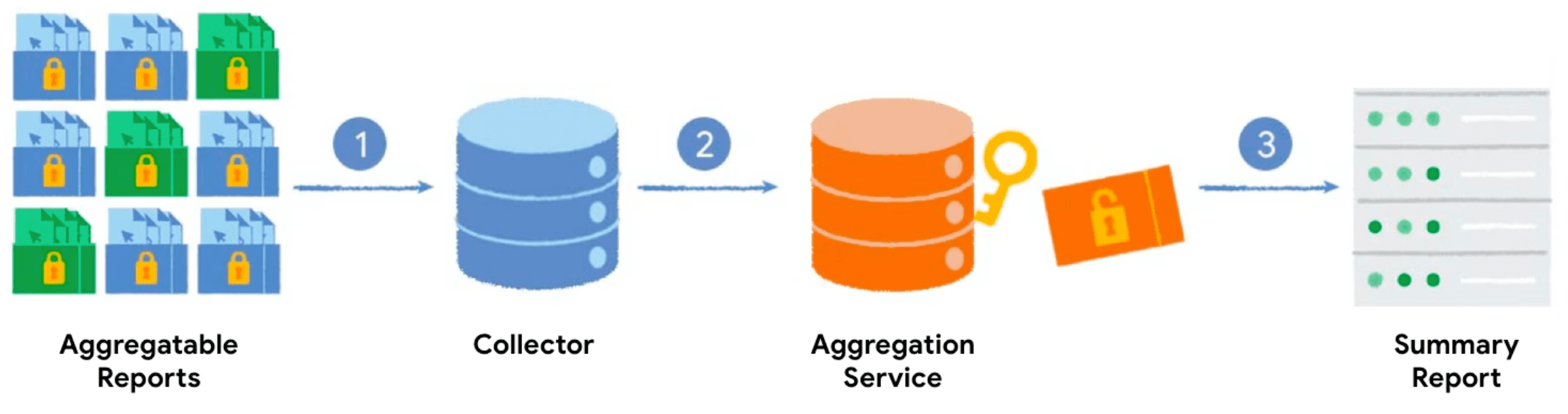
- Quando chiami l'API Private Aggregation, il client (browser) genera e invia il report aggregabile al tuo server per la raccolta.
- Il server raccoglie i report dai client e li raggruppa per inviarli al servizio di aggregazione.
- Una volta raccolti report sufficienti, li raggruppi e li invii al servizio di aggregazione, in esecuzione in un ambiente di esecuzione attendibile, per generare un report di riepilogo.
Il flusso di lavoro descritto in questa sezione è simile all'API Attribution Reporting. Tuttavia, i report sull'attribuzione associano i dati raccolti da un evento impressione e da un evento conversione, che si verificano in momenti diversi. L'aggregazione privata misura un singolo evento cross-site.
Chiave di aggregazione
Una chiave di aggregazione ("chiave" per breve) rappresenta il bucket in cui verranno accumulati i valori aggregabili. È possibile codificare una o più dimensioni nella chiave. Una dimensione rappresenta un aspetto su cui vuoi ottenere maggiori informazioni, ad esempio la fascia d'età degli utenti o il numero di impressioni di una campagna pubblicitaria.
Ad esempio, potresti avere un widget incorporato in più siti e voler analizzare il paese degli utenti che lo hanno visto. Vuoi rispondere a domande come "Quanti degli utenti che hanno visto il mio widget provengono dal paese X?" Per generare report su questa domanda, puoi impostare una chiave di aggregazione che codifichi due dimensioni: ID widget e ID paese.
La chiave fornita all'API Private Aggregation è un valore BigInt, costituito da più dimensioni. In questo esempio, le dimensioni sono
l'ID widget e l'ID paese. Supponiamo che l'ID widget possa essere costituito da un massimo di 4 cifre, ad esempio 1234, e che ogni paese sia associato a un numero in ordine alfabetico, ad esempio l'Afghanistan è 1, la Francia è 61 e lo Zimbabwe è 195.
Pertanto, la chiave aggregabile sarà lunga 7 cifre, dove i primi 4 caratteri sono riservati per WidgetID e gli ultimi 3 caratteri sono riservati per CountryID.
Supponiamo che la chiave rappresenti il conteggio degli utenti in Francia (ID paese 061)
che hanno visualizzato l'ID widget 3276. La chiave di aggregazione è 3276061.
| Chiave di aggregazione | |
| ID widget | ID paese |
| 3276 | 061 |
La chiave di aggregazione può essere generata anche con un meccanismo di hashing, ad esempio
SHA-256. Ad esempio, la stringa
{"WidgetId":3276,"CountryID":67} può essere sottoposta ad hashing e poi convertita in un valore
BigInt di
42943797454801331377966796057547478208888578253058197330928948081739249096287n.
Se il valore dell'hash ha più di 128 bit, puoi troncarlo per assicurarti che non superi il valore massimo consentito del bucket di 2^128−1.
All'interno di un worklet di archiviazione condivisa, puoi accedere ai moduli crypto e TextEncoder che possono aiutarti a generare un hash. Per scoprire di più sulla generazione di un hash, consulta
SubtleCrypto.digest() su
MDN.
L'esempio seguente descrive come generare una chiave del bucket da un valore sottoposto ad hashing:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Valore aggregabile
I valori aggregabili vengono sommati per chiave in molti utenti per generare informazioni aggregate sotto forma di valori di riepilogo nei report di riepilogo.
Ora torna alla domanda di esempio posta in precedenza: "Quanti degli utenti che hanno visto il mio widget provengono dalla Francia?" La risposta a questa domanda sarà simile a "Circa 4881 utenti che hanno visto il mio ID widget 3276 provengono dalla Francia". Il valore aggregabile è 1 per ogni utente e "4881 utenti" è il valore aggregato, ovvero la somma di tutti i valori aggregabili per quella chiave di aggregazione.
| Chiave di aggregazione | Valore aggregabile | |
| ID widget | ID paese | Numero di visualizzazioni |
| 3276 | 061 | 1 |
Per questo esempio, incrementiamo il valore di 1 per ogni utente che vede il widget. In pratica, il valore aggregabile può essere scalato per migliorare il rapporto segnale-ruido.
Budget per i contributi
Ogni chiamata all'API Private Aggregation è chiamata contributo. Per proteggere la privacy degli utenti, il numero di contributi che possono essere raccolti da un singolo utente è limitato.
Quando sommi tutti i valori aggregabili in tutte le chiavi di aggregazione, la somma deve essere inferiore al budget di contributo. Il budget è definito in base all'origine del worklet, al giorno ed è distinto per l'API Protected Audience e i worklet dello spazio di archiviazione condiviso. Per il giorno viene utilizzata una finestra dinamica di circa 24 ore. Se un nuovo report aggregabile causerebbe il superamento del budget, il report non viene creato.
Il budget di contributo è rappresentato dal parametro L1 ed è impostato su 216 (65.536) ogni dieci minuti al giorno con un backstop di 220 (1.048.576). Per scoprire di più su questi parametri, consulta la spiegazione.
Il valore del budget dei contributi è arbitrario, ma il rumore viene scalato in base a questo valore. Puoi utilizzare questo budget per massimizzare il rapporto segnale/rumore sui valori di riepilogo (discututo ulteriormente nella sezione Rumore e scalabilità).
Per scoprire di più sui budget dei contributi, consulta la spiegazione. Per ulteriori indicazioni, consulta anche la sezione Budget per i contributi.
Limite di contributi per report
A seconda dell'utente che effettua la chiamata, il limite di contributo può variare. Al momento, i report generati per i chiamanti dell'API Shared Storage sono limitati a 20 contributi per report. I chiamanti dell'API Protected Audience, invece, hanno un limite di 100 contributi per report. Questi limiti sono stati scelti per bilanciare il numero di contributi che possono essere incorporati con le dimensioni del payload.
Per lo spazio di archiviazione condiviso, i contributi effettuati all'interno di un'unica operazione run() o selectURL() vengono raggruppati in un unico report. Per Protected Audience, i contributi effettuati da una singola origine all'interno di un'asta vengono raggruppati.
Contributi con spaziatura interna
I contributi vengono ulteriormente modificati con una funzionalità di spaziatura interna. L'operazione di padding del payload protegge le informazioni sul numero effettivo di contributi incorporati nel report aggregabile. Il padding aumenta il payload con contributi null
(ovvero con valore 0) per raggiungere una lunghezza fissa.
Report aggregabili
Una volta che l'utente richiama l'API Private Aggregation, il browser genera report aggregabili da elaborare in un secondo momento dal servizio di aggregazione per generare report di riepilogo. Un
report aggregabile è in formato JSON e contiene un elenco criptato di
contributi, ciascuno dei quali è una coppia {aggregation key, aggregatable value}.
I report aggregabili vengono inviati con un ritardo casuale massimo di un'ora.
I contributi sono criptati e non leggibili al di fuori del servizio di aggregazione. Il servizio di aggregazione decripta i report e genera un report di riepilogo. La chiave di crittografia per il browser e la chiave di decrittografia per il servizio di aggregazione vengono emesse dal coordinatore, che funge da servizio di gestione delle chiavi. Il coordinatore mantiene un elenco di hash binari dell'immagine del servizio per verificare che chi chiama sia autorizzato a ricevere la chiave di decrittografia.
Un esempio di report aggregabile con la modalità di debug attivata:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
I report aggregabili possono essere esaminati dalla paginachrome://private-aggregation-internals:

Per scopi di test, il pulsante "Invia report selezionati" può essere utilizzato per inviare immediatamente il report al server.
Raccogliere e raggruppare i report aggregabili
Il browser invia i report aggregabili all'origine del worklet contenente la chiamata all'API Private Aggregation utilizzando il percorso noto elencato:
- Per Shared Storage:
/.well-known/private-aggregation/report-shared-storage - Per Protected Audience:
/.well-known/private-aggregation/report-protected-audience
In questi endpoint, dovrai utilizzare un server che agisce come raccoglitore e riceve i report aggregabili inviati dai client.
Il server deve quindi raggruppare i report e inviarli al servizio di aggregazione. Crea batch in base alle informazioni disponibili nel payload non criptato del report aggregabile, ad esempio il campo shared_info. Idealmente,
i batch devono contenere almeno 100 report.
Puoi decidere di eseguire il batch su base giornaliera o settimanale. Questa strategia è flessibile e puoi modificarla per eventi specifici in cui prevedi un volume maggiore, ad esempio i giorni dell'anno in cui sono previste più impressioni. I batch devono includere report della stessa versione dell'API, della stessa origine report e con lo stesso orario di pianificazione dei report.
Filtrare gli ID
L'API Private Aggregation e il servizio di aggregazione consentono di utilizzare gli ID filtro per elaborare le misurazioni a un livello più granulare, ad esempio per campagna pubblicitaria, anziché elaborare i risultati in query più grandi.

Per iniziare a utilizzare questa funzionalità oggi stesso, ecco alcuni passaggi approssimativi da applicare alla tua implementazione attuale.
Procedura per lo spazio di archiviazione condiviso
Se utilizzi l'API Shared Storage nel tuo flusso:
Definisci dove dichiarare ed eseguire il nuovo modulo di archiviazione condiviso. Nell'esempio seguente, abbiamo denominato il file del modulo
filtering-worklet.js, registrato infiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();Tieni presente che
filteringIdMaxBytesè configurabile per report e, se non impostato, il valore predefinito è 1. Questo valore predefinito serve a evitare un aumento non necessario delle dimensioni del payload e, di conseguenza, dei costi di archiviazione ed elaborazione. Scopri di più nella spiegazione dei contributi flessibili.Nel file utilizzato sopra, in questo caso
filtering-worklet.js, quando passi un contributo aprivateAggregation.contributeToHistogram(...)all'interno del worklet Spazio di archiviazione condiviso, puoi specificare un ID filtro.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);I report aggregabili verranno inviati all'endpoint
/.well-known/private-aggregation/report-shared-storageche hai definito. Vai alla guida per i filtri degli ID per scoprire le modifiche necessarie ai parametri dei job del servizio di aggregazione.
Una volta completata l'aggregazione e inviata al servizio di aggregazione di cui è stato eseguito il deployment, i risultati filtrati dovrebbero essere riportati nel report di riepilogo finale.
Procedura Protected Audience
Se utilizzi l'API Protected Audience nel tuo flusso:
Nell'attuale implementazione di Protected Audience, puoi impostare quanto segue per collegarti all'aggregazione privata. A differenza dello spazio di archiviazione condiviso, non è ancora possibile configurare le dimensioni massime dell'ID filtro. Per impostazione predefinita, la dimensione massima dell'ID filtro è 1 byte e verrà impostata su
0n. Tieni presente che questi valori verranno impostati nelle [funzioni di generazione di report di Protected Audience](Funzioni di generazione di report di Protected Audience, ad esempioreportResult()ogenerateBid().const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);I report aggregabili verranno inviati all'endpoint
/.well-known/private-aggregation/report-protected-audienceche hai definito. Una volta completata l'aggregazione e inviata al servizio di aggregazione di cui è stato eseguito il deployment, i risultati filtrati dovrebbero essere riportati nel report di riepilogo finale. Sono disponibili le seguenti spiegazioni per l'API Attribution Reporting e l'API Private Aggregation, oltre alla proposta iniziale.
Per una descrizione più dettagliata, consulta la nostra guida ai filtri degli ID nel servizio di aggregazione o le sezioni dell'API Attribution Reporting.
Servizio di aggregazione
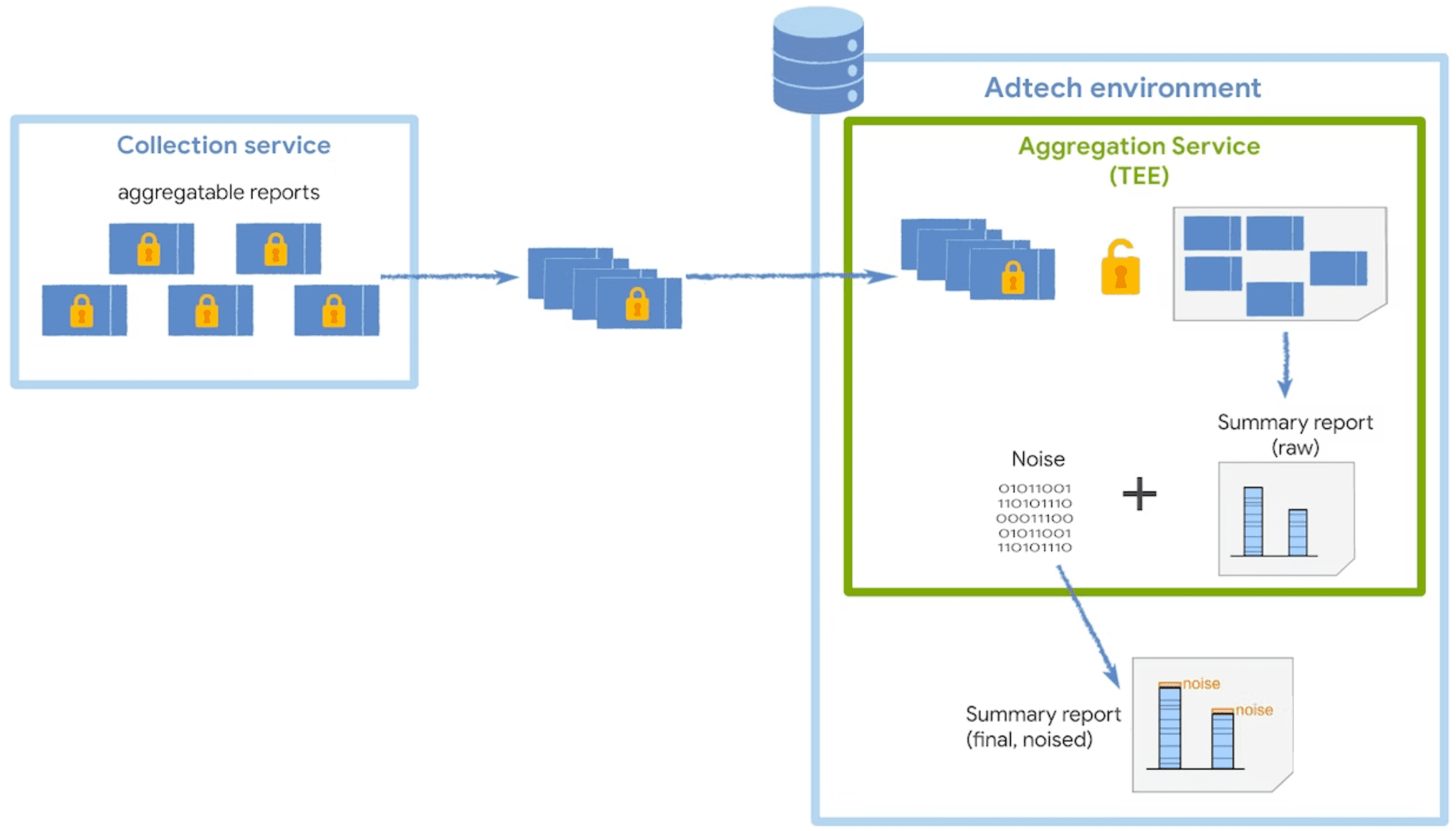
Il servizio di aggregazione riceve dal raccoglitore i report aggregabili criptati e genera report di riepilogo. Per ulteriori strategie su come raggruppare i report aggregabili nel tuo collector, consulta la nostra guida alle richieste batch.
Il servizio viene eseguito in un ambiente di esecuzione attendibile (TEE), che fornisce un livello di garanzia per l'integrità e la riservatezza dei dati e l'integrità del codice. Per saperne di più su come vengono utilizzati i coordinatori insieme ai TEE, scopri di più sul loro ruolo e scopo.
Report di riepilogo
I report di riepilogo ti consentono di visualizzare i dati raccolti con l'aggiunta di rumore. Puoi richiedere report di riepilogo per un determinato insieme di chiavi.
Un report di riepilogo contiene un insieme di coppie chiave-valore in stile dizionario JSON. Ogni coppia contiene:
bucket: la chiave di aggregazione come stringa di numeri binari. Se la chiave di aggregazione utilizzata è "123", il bucket è "1111011".value: il valore di riepilogo per un determinato obiettivo di misurazione, sommato da tutti i report aggregabili disponibili con l'aggiunta del rumore.
Ad esempio:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Rumore e scalabilità
Per preservare la privacy degli utenti, il servizio di aggregazione aggiunge rumore una volta a ogni valore di riepilogo ogni volta che viene richiesto un report di riepilogo. I valori del rumore vengono ricavati in modo casuale da una distribuzione di probabilità di Laplace. Anche se non hai il controllo diretto sui modi in cui viene aggiunto il rumore, puoi influire sull'impatto del rumore sui dati di misurazione.
La distribuzione del rumore è la stessa indipendentemente dalla somma di tutti i valori aggregabili. Pertanto, più elevati sono i valori aggregabili, minore è l'impatto del rumore.
Ad esempio, supponiamo che la distribuzione del rumore abbia una deviazione standard di 100 e sia centrata su zero. Se il valore del report aggregabile raccolto (o "valore aggregabile") è solo 200, la deviazione standard del rumore sarà pari al 50% del valore aggregato. Tuttavia, se il valore aggregabile è 20.000,la deviazione standard del rumore sarà pari solo allo 0, 5% del valore aggregato. Pertanto, il valore aggregabile di 20.000 avrebbe un rapporto segnale/rumore molto più elevato.
Pertanto, moltiplicare il valore aggregabile per un fattore di scala può contribuire a ridurre il rumore. Il fattore di scala rappresenta il grado di scalatura di un determinato valore aggregabile.

L'aumento dei valori scegliendo un fattore di scala più elevato riduce il rumore relativo. Tuttavia, questo fa sì che anche la somma di tutti i contributi in tutti i bucket raggiunga più velocemente il limite di budget dei contributi. La riduzione dei valori tramite la scelta di una costante del fattore di scala più piccola aumenta il rumore relativo, ma riduce il rischio di raggiungere il limite del budget.
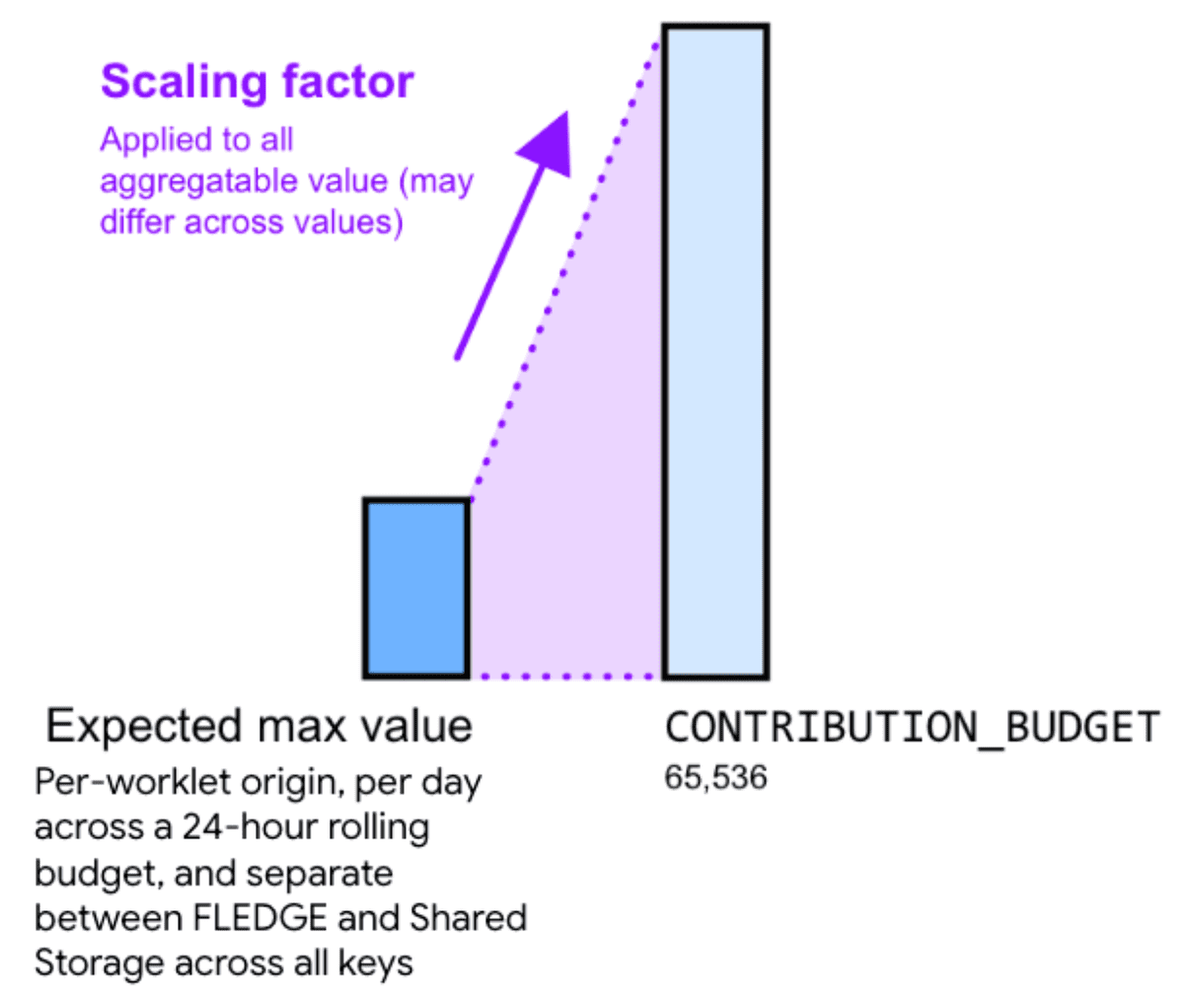
Per calcolare un fattore di scala appropriato, dividi il budget dei contributi per la somma massima dei valori aggregabili in tutte le chiavi.
Per saperne di più, consulta la documentazione sul budget dei contributi.
Coinvolgere e condividere feedback
L'API Private Aggregation è in discussione attiva ed è soggetta a modifiche in futuro. Se provi questa API e hai un feedback, ci farebbe piacere ricevere il tuo parere.
- GitHub: leggi l'explainer, poni domande e partecipa alla discussione.
- Assistenza per gli sviluppatori: fai domande e partecipa alle discussioni nel repository Privacy Sandbox Developer Support.
- Partecipa al gruppo API Shared Storage e al gruppo API Protected Audience per ricevere gli ultimi annunci relativi all'aggregazione privata.