Usługa agregacji generuje raporty podsumowujące szczegółowe dane o konwersjach i danych dotyczących zasięgu na podstawie nieprzetworzonych raportów podlegających agregacji. Jako dostawca technologii reklamowej możesz używać interfejsów Attribution Reporting API i Private Aggregation API, które są 2 głównymi punktami wejścia po stronie klienta, aby przekazywać raporty do usługi agregacji i otrzymywać w odpowiedzi raporty podsumowujące.
Na tej stronie zakładamy, że jesteś doświadczonym specjalistą ds. technologii reklamowych. Tutaj znajdziesz informacje o:
- Stan implementacji
- Kluczowe terminy i pojęcia
- Przypadki użycia agregacji
- Cały proces
- Przesyłanie zbiorcze raportów możliwych do zsumowania
- Elementy w chmurze
Stan wdrożenia
- Usługa agregacji jest teraz ogólnie dostępna.
- Usługa agregacji może być używana z interfejsem Attribution Reporting API i interfejsem Private Aggregation API w przypadku interfejsu Protected Audience API i interfejsu Shared Storage API.
Dostępność
| Proposal | Status |
|---|---|
| Cross Cloud Privacy Budget Service
Explainer |
Available |
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available |
| Aggregation Service site enrollment and multi-origin aggregation. Site enrollment includes mapping of a site to cloud accounts (AWS, or GCP). To aggregate multiple origins, they must be of the same site.
FAQs on GitHub Site aggregation API documentation |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Available |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
Explainer |
Available Mechanism to review the percentage of shared IDs recovered by an ad tech using budget recovery and suspend future recoveries for excessive recoveries planned for H1 2025 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer blog |
Available |
| Aggregation Service support for Aggregate Debug Reporting on Attribution Reporting API
Explainer |
Available |
Kluczowe terminy i pojęcia
Jeśli rozważasz użycie usługi agregacji w swoim procesie, poniższe terminy i pojęcia mogą pomóc Ci zrozumieć, co nowy proces agregacji może dać Twojemu zespołowi.
Słowniczek terminów
- Raporty zbiorcze
-
Raporty podlegające agregacji to zaszyfrowane raporty wysyłane z pojedynczych urządzeń użytkowników. Te raporty zawierają dane o zachowaniu użytkowników i konwersjach w różnych witrynach. Konwersje (czasami nazywane zdarzeniami wywołującymi atrybucję) i powiązane z nimi dane są definiowane przez reklamodawcę lub technologię reklamową. Każdy raport jest zaszyfrowany, aby uniemożliwić innym stronom dostęp do danych źródłowych.
- Uwzględnianie raportów zbiorczych
-
rozproszona księga znajdująca się w obu koordynatorach, która śledzi przypisany budżet prywatności i egzekwuje regułę „Bez duplikatów”. Jest to mechanizm ochrony prywatności, który działa w ramach koordynatorów i zapewnia, że żadne raporty nie są przekazywane przez usługę agregacji poza przydzielony budżet prywatności.
Więcej informacji o strategiach grupowania danych w związku z raportami podlegającymi agregacji
- Budżet rozliczeniowy raportu zbiorczego
-
Odwołania do budżetu, które zapewniają, że poszczególne raporty nie są przetwarzane więcej niż raz.
- Usługa do agregacji
-
Usługa obsługiwana przez firmę zajmującą się technologiami reklamowymi, która przetwarza raporty podlegające agregacji, aby utworzyć raport podsumowania.
Więcej informacji o usłudze agregacji znajdziesz w artykule i pełnej wersji warunków.
- Potwierdzenie
-
Mechanizm uwierzytelniania tożsamości oprogramowania, zwykle za pomocą funkcji szyfrowania skrótów lub podpisów. W przypadku propozycji usługi agregacji weryfikacja polega na sprawdzeniu, czy kod działający w usłudze agregacji obsługiwanej przez firmę zajmującą się technologią reklamową jest zgodny z kodem open source.
- Contribution Bonding
- Koordynator
-
Podmioty odpowiedzialne za zarządzanie kluczami i rachunkowość raportów podlegających agregacji. Koordynator prowadzi listę haszy zatwierdzonych konfiguracji usługi agregacji i konfiguruje dostęp do kluczy odszyfrowywania.
- Szum i skalowanie
-
szum statystyczny dodawany do raportów zbiorczych podczas procesu agregacji w celu zachowania prywatności i zapewnienia, że raporty końcowe zawierają anonimowe informacje pomiarowe.
Dowiedz się więcej o mechanizmie addytywnym generującym szum, który jest oparty na rozkładzie Laplace’a.
- Źródło raportu
-
Podmiot, który otrzymuje raporty podlegające agregacji, czyli Ty lub zespół ds. technologii reklamowej, który wywołał interfejs Attribution Reporting API. Raporty umożliwiające agregację są wysyłane z urządzeń użytkowników do znanego adresu URL powiązanego z miejscem pochodzenia raportu. Źródło raportowania jest wyznaczane podczas rejestracji.
- Shared ID
-
Obliczona wartość, która składa się z
shared_info,reporting_origin,destination_site(tylko w przypadku Attribution Reporting API),source_registration-time(tylko w przypadku Attribution Reporting API),scheduled_report_timeoraz wersji.Wiele raportów, które mają te same atrybuty w polu
shared_info, powinno mieć ten sam identyfikator współdzielony. Udostępnione identyfikatory odgrywają ważną rolę w raportowaniu w raportach agregowalnych. - Raport zbiorczy
-
Typ raportu interfejsów Attribution Reporting API i Private Aggregation API. Raport podsumowania zawiera zagregowane dane o użytkownikach i może zawierać szczegółowe dane o konwersjach z dodanym szumem. Raporty podsumowujące składają się z raportów zbiorczych. Zapewniają one większą elastyczność i bogatszy model danych niż raportowanie na poziomie zdarzenia, co jest szczególnie przydatne w przypadku niektórych zastosowań, np. wartości konwersji.
- Zaufane środowisko wykonawcze (TEE)
-
Bezpieczna konfiguracja sprzętu i oprogramowania komputera, która umożliwia podmiotom zewnętrznym sprawdzenie dokładnych wersji oprogramowania działającego na urządzeniu bez obawy przed ujawnieniem. Środowiska TEE umożliwiają podmiotom zewnętrznym sprawdzenie, czy oprogramowanie działa dokładnie tak, jak twierdzi deweloper, i nic więcej.
Aby dowiedzieć się więcej o zasadach TEE używanych w propozycjach dotyczących Piaskownicy prywatności, przeczytaj informacje o interfejsie Protected Audience API i informacje o usłudze agregacji danych.
Przypadki użycia agregacji
Zapoznaj się z tymi ścieżkami dla programistów dotyczącymi pomiaru reklam i odpowiednimi bibliotekami klienta pomiarów.
| Przypadek użycia | Punkt wejścia | Opis |
|---|---|---|
| Optymalizacja stawek | Attribution Reporting API (Chrome i Android) | Korzystaj z raportów zbiorczych, aby pozyskiwać sygnały konwersji na potrzeby optymalizacji stawek. |
| Pomiar na różnych platformach | Attribution Reporting API (Chrome i Android) | Korzystaj z możliwości pomiaru skuteczności w internecie i aplikacjach, aby mieć wgląd w wyniki w Chrome i na Androidzie. |
| Raporty o konwersjach | Attribution Reporting API (Chrome i Android) | tworzenie raportów o konwersjach zbiorczych dostosowanych do potrzeb kampanii klientów (w tym CTC i VTC); |
| Pomiar zasięgu kampanii | Shared Storage API i Private Aggregation API (Chrome) | Używaj zmiennych widoku reklamy w wielu witrynach do pomiaru zasięgu kampanii. |
| Raportowanie danych demograficznych | Shared Storage API i Private Aggregation API (Chrome) | Używaj danych o wyświetleniach reklam w wielu witrynach i danych demograficznych do pomiaru zasięgu według danych demograficznych. |
| Analiza ścieżki konwersji | Shared Storage API i Private Aggregation API (Chrome) | Przechowuj zmienne widoku reklamy w wielu witrynach i konwersji, aby przeprowadzać zbiorczą analizę ścieżki konwersji. |
| Wyniki marki i zwiększenie liczby konwersji | Shared Storage API i Private Aggregation API (Chrome) | Raportowanie dotyczące grup testowych i kontrolnych oraz informacji o głosowaniu na potrzeby pomiaru wzrostu skuteczności marki i przyrostu wartości. |
| Debugowanie aukcji | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych na potrzeby debugowania. |
| Rozkład stawek | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych, aby rejestrować rozkład wartości stawek w aukcjach. |
Cały proces
Poniższy diagram pokazuje działanie usługi agregacji. Skupimy się na pełnym procesie, od momentu otrzymania raportów z internetu i urządzeń mobilnych do momentu utworzenia raportu podsumowania w usłudze agregacji.
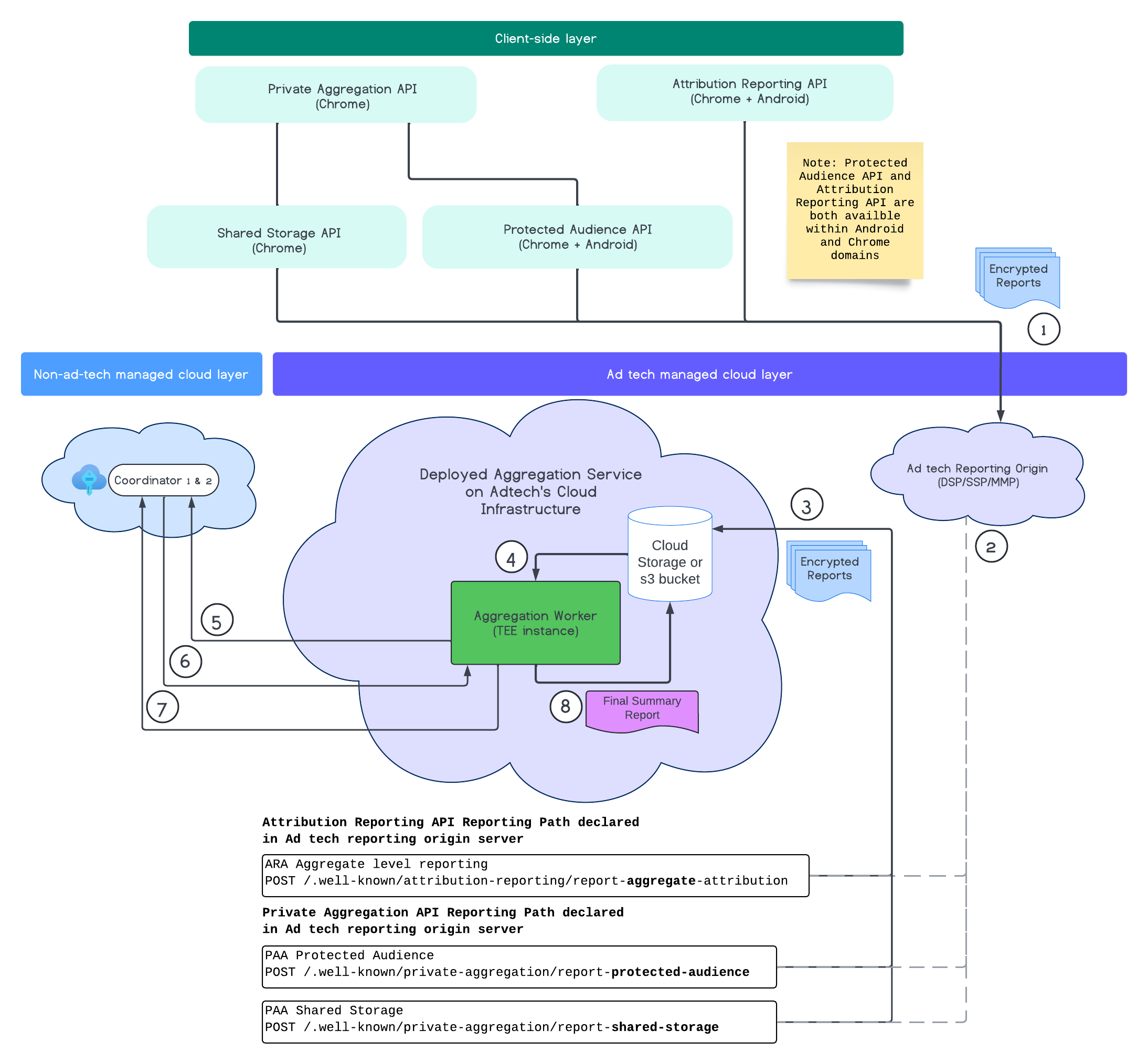
- Pobierz klucz publiczny, aby generować zaszyfrowane raporty.
- Zaszyfrowane raporty podlegające agregacji są wysyłane na serwery technologii reklamowych w celu zebrania, przekształcenia i zbiorowego przetwarzania.
- Serwer adtech grupowo wysyła raporty (w formacie avro) do usługi agregacji. (musisz to zrobić).
- Pracownik agregacji pobiera zagregowane raporty do odszyfrowania.
- Pracownik agregacji pobiera klucze odszyfrowywania od koordynatora.
- Proces agregacji odszyfrowuje raporty na potrzeby agregacji i dodawania szumu.
- Usługa księgowania raportów podlegających agregacji sprawdza, czy jest wystarczający budżet na ochronę prywatności, aby wygenerować raport podsumowania dla podanych raportów podlegających agregacji.
- Prześlij końcowy raport podsumowujący.
Diagram pokazuje ogólne relacje usługi agregacji z głównymi interfejsami API pomiaru klienta: Attribution Reporting API, Private Aggregation API i koordynatorami.
Proces rozpoczyna się od interfejsów API służących do pomiarów, takich jak Attribution Reporting API czy Private Aggregation API, które generują raporty z wielu instancji przeglądarki. Chrome pobiera klucz publiczny z usługi hostingu kluczy w koordynatorze, aby szyfrować raporty przed ich wysłaniem do źródła raportowania technologii reklamowych. Klucze publiczne są poddawane rotacji co 7 dni.
Źródło raportowania technologii reklamowych powinno być skonfigurowane tak, aby zbierać i konwertować przychodzące raporty do formatu avro oraz wysyłać je do usługi agregacji zgodnie z opisem w sekcji Strategie przetwarzania partii danych.
Gdy masz gotową partię, wysyłasz do usługi agregacji żądanie zbiorcze. Usługa agregacji pobiera klucze odszyfrowywania z usługi hostingu kluczy, odszyfrowuje raporty, a następnie agreguje je i zaciemnia, aby utworzyć raport podsumowujący. Pamiętaj, że zależy to od tego, czy masz wystarczający budżet na ochronę prywatności.
Usługa zbierania danych o technologiach reklamowych hostowana jest w chmurze dostawcy technologii reklamowych, gdzie są zbierane raporty, a usługa agregacji jest wdrażana w chmurze dostawcy technologii reklamowych.
grupowanie raportów zbiorczych.
Proces raportowania nie byłby kompletny bez pomocy wyznaczonego serwera źródłowego raportowania. To jest pochodzenie, które zostało przesłane w trakcie procesu rejestracji. Źródło raportów odpowiada za zbieranie, przekształcanie i grupowanie otrzymanych raportów podlegających agregacji oraz przygotowanie ich do wysłania do usługi agregacji w Google Cloud lub Amazon Web Services. Dowiedz się więcej o przygotowywaniu raportów możliwych do zsumowania.
Teraz, gdy znasz już ogólną koncepcję, możemy przyjrzeć się bliżej komponentom wdrożonym w Twojej usłudze agregacji.
Komponenty Cloud
Usługa agregacji składa się z kilku komponentów usług w chmurze. Do tworzenia i konfigurowania wszystkich niezbędnych komponentów usługi w chmurze używasz dostarczonych skryptów Terraform.
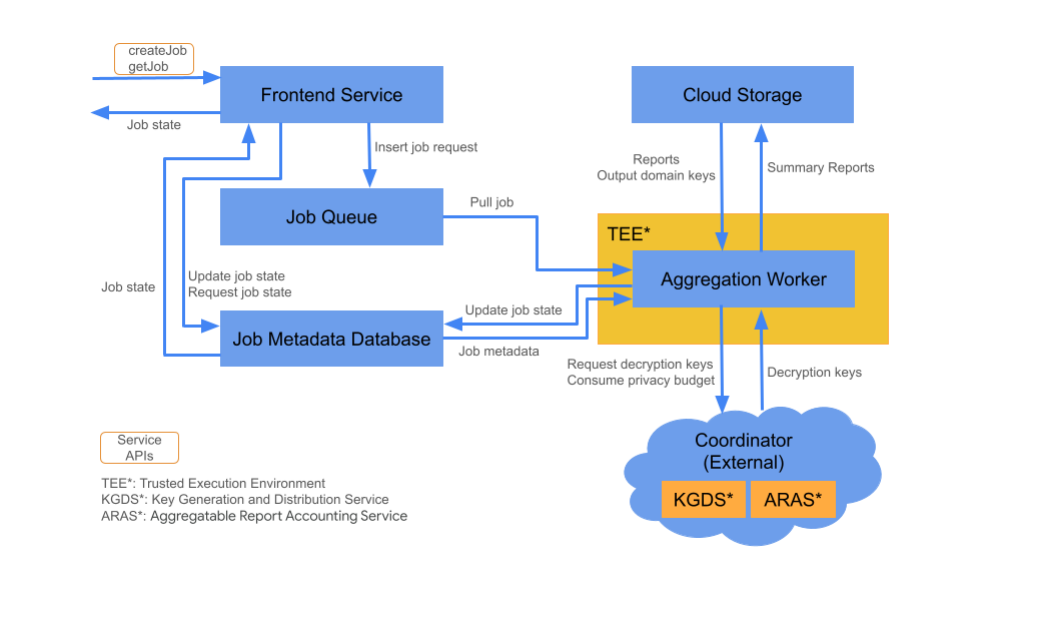
Usługa frontendu
Zarządzana usługa w chmurze: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
Usługa frontendu to bezserwerowa brama, która jest głównym punktem wejścia do wywołań interfejsu Aggregation API służących do tworzenia zadań i pobierania stanu zadań. Odpowiada on za otrzymywanie żądań od użytkowników usługi agregacji, sprawdzanie parametrów wejściowych i inicjowanie procesu planowania zadania agregacji.
Usługa frontendu ma 2 dostępne interfejsy API:
| Punkt końcowy | Opis |
|---|---|
createJob |
Ten interfejs API uruchamia zadanie usługi do agregacji. Aby uruchomić zadanie, musisz podać takie informacje, jak identyfikator zadania, szczegóły miejsca docelowego danych wejściowych, szczegóły miejsca docelowego danych wyjściowych i źródło raportowania. |
getJob |
Ten interfejs API zwraca stan zadania o określonym identyfikatorze. Zawiera informacje o stanie zadania, takie jak „Otrzymano”, „W toku” lub „Ukończono”. Jeśli zadanie zostało ukończone, zwraca też jego wynik, w tym komunikaty o błędach, które wystąpiły podczas jego wykonywania. |
Zapoznaj się z dokumentacją interfejsu API usługi do agregacji.
Kolejka zadań
Zarządzana usługa w chmurze: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services).
Kolejka zadań to kolejka wiadomości zawierająca żądania zadań dotyczące usługi agregacji. Usługa frontendu wstawia żądania zadań do kolejki, które są następnie wykorzystywane przez pracowników agregacji, którzy je przetwarzają.
Cloud Storage
Zarządzana usługa w chmurze: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services).
Pliki wejściowe i wyjściowe używane przez usługę agregacji, takie jak zaszyfrowane pliki raportów i raporty podsumowania wyjściowego, są przechowywane w chmurze.
Baza danych metadanych zadania
Zarządzana usługa w chmurze: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Baza danych metadanych zadań służy do przechowywania stanu zadań agregacji i śledzenia go. Zapisywanie metadanych, takich jak czas utworzenia, czas zgłoszenia, czas aktualizacji i stan (np. Otrzymano, W toku lub Gotowe). Instancje robocze agregacji aktualizują bazę danych metadanych zadań w miarę wykonywania zadań.
Zasób roboczy agregacji
Zarządzana usługa w chmurze: Compute Engine z Confidential space (Google Cloud) lub Amazon Web Services EC2 z Nitro Enclave (Amazon Web Services).
Pracownik agregacji przetwarza żądania zadań w kole zadań i odszyfrowuje zaszyfrowane dane wejściowe za pomocą kluczy pobieranych z usługi Key Generation and Distribution Service (KGDS) w koordynatorze. Aby zminimalizować opóźnienia w przetwarzaniu zadań, instancje robocze agregacji przechowują klucze odszyfrowywania w pamięci podręcznej przez 8 godzin i używają ich w ramach przetwarzanych zadań.
Procesy agregacji działają w środowisku Trusted Execution Environment (TEE). Worker obsługuje tylko jedno zadanie naraz. Możesz skonfigurować wiele instancji roboczych do przetwarzania zadań równolegle, ustawiając konfigurację automatycznego skalowania. Jeśli jest używane, autoskalowanie dynamicznie dostosowuje liczbę instancji roboczych do liczby wiadomości w kolejce zadań. Minimalną i maksymalną liczbę instancji roboczych do automatycznego skalowania możesz skonfigurować w pliku środowiska Terraform. Więcej informacji o autoskalowaniu znajdziesz w tych skryptach Terraform: Amazon Web Services lub Google Cloud.
Procesy robocze agregacji wywołują usługę księgowania raportów agregacji w celu księgowania raportów agregacji. Ta usługa zapewnia, że zadania są wykonywane tylko wtedy, gdy nie przekroczono limitu budżetu prywatności. (zobacz regułę „Brak duplikatów”). Jeśli budżet jest dostępny, na podstawie zbiorczych danych o wysokiej zmienności jest generowany raport podsumowujący. Dowiedz się więcej o rachunkowości w raportach możliwych do zsumowania.
Pracownicy agregacji aktualizują metadane zadań w bazie danych metadanych zadań. Te informacje obejmują kody zwrotu zadań i liczniki błędów raportów w przypadku częściowych błędów raportów. Użytkownicy mogą pobrać stan za pomocą interfejsu getJob job state retrieval API.
Szczegółowe informacje o usłudze agregacji znajdziesz w tym artykule.
Dalsze kroki
Po zapoznaniu się z najważniejszymi informacjami o usłudze agregacji możesz wdrożyć własny jej egzemplarz w Google Cloud lub Amazon Web Services. Aby dowiedzieć się więcej o działaniach związanych z usługą agregacji, zapoznaj się z sekcją „Pierwsze kroki” lub kliknij ten link.
Rozwiązywanie problemów
Szczegółowe opisy komunikatów o błędach, informacje o możliwych przyczynach ich występowania oraz dalsze kroki, które należy podjąć, aby je rozwiązać, znajdziesz w dokumentacji Częste kody błędów i sposoby ich rozwiązania.
Uzyskiwanie pomocy i przesyłanie opinii
- Aby zadać pytanie o usługę, przekazać opinię lub zgłosić prośbę o dodanie funkcji, utwórz zgłoszenie w naszym repozytorium GitHub.
- Jeśli podczas wdrażania, utrzymywania lub wykonywania zadań za pomocą usługi agregacji wystąpił błąd, możesz poprosić o pomoc techniczną, korzystając z tego formularza.
- Sprawdź panel stanu usługi Google Analytics, aby dowiedzieć się, czy wystąpiły znane problemy.